做下游分类任务,如何处理一句话的输入
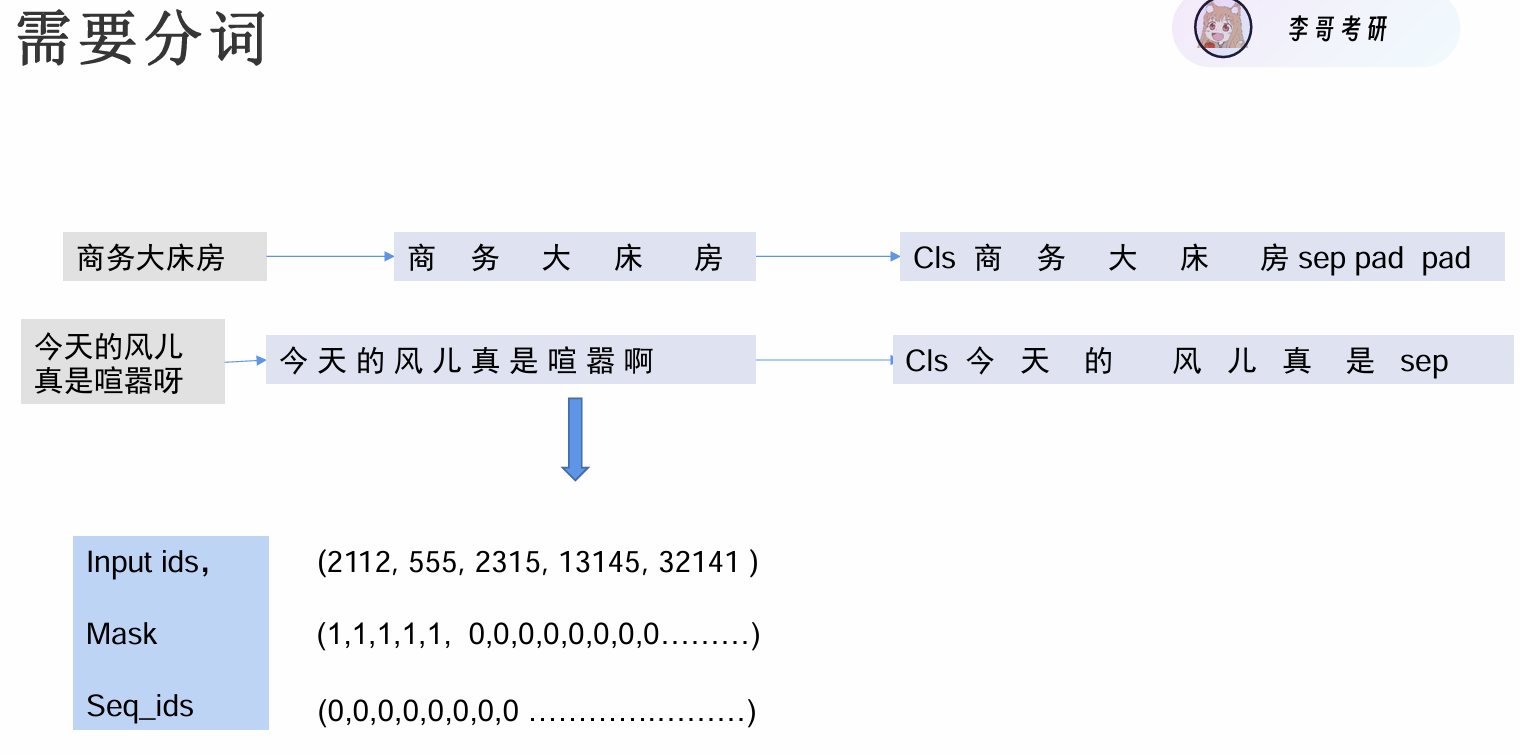
- input_dis:输入哪些字 21128个汉字里编码
- mask:输入的话有多长. 模型输入固定,不够的话用padding补上
- Seq_ids:句子编码 segment
BERT输入
- token embedding 字编码(21128, 768)
- segment embedding 句子编码(2, 768)
- position embedding不用给 自动知道下标 最长长度不是句子长度,而是模型长度(512, 768)
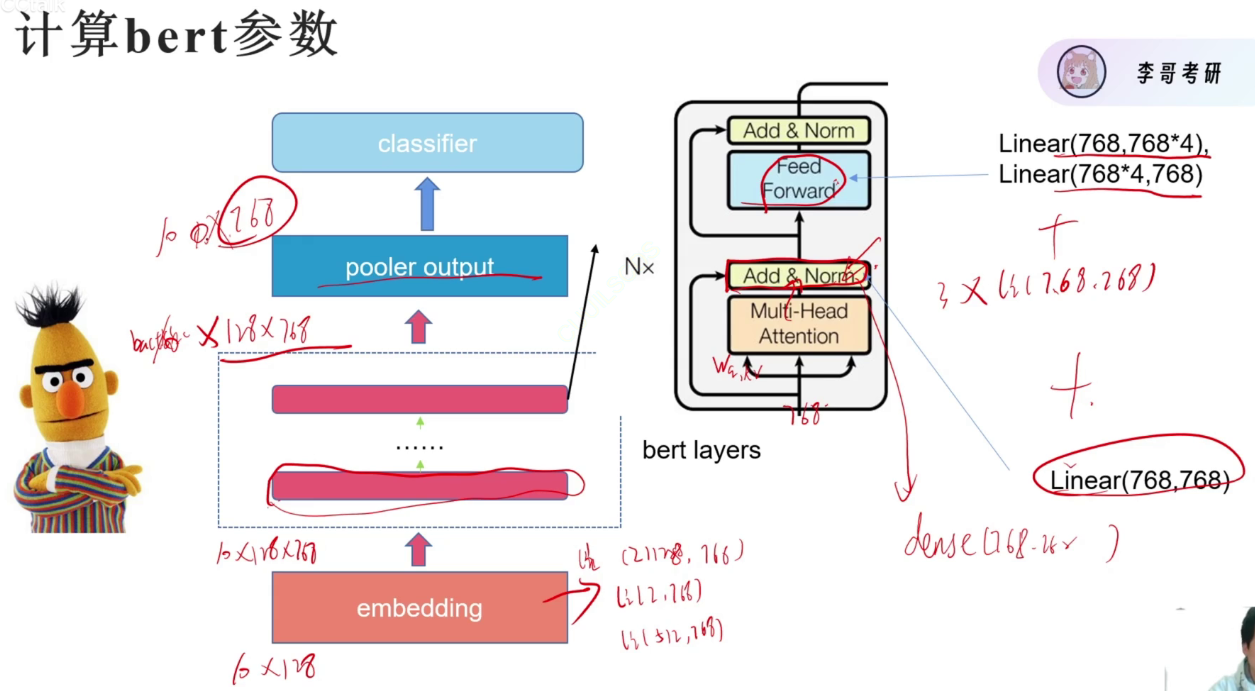
bert layer层每层都是一个self-attention
hidden_size=768规定embedding到768维
data
# data负责产生两个dataloader
from torch.utils.data import DataLoader, Dataset
from sklearn.model_selection import train_test_split #给X,Y 和分割比例, 分割出来一个训练集和验证机的X, Y
import torchdef read_file(path):data = []label = []with open(path, "r", encoding="utf-8") as f:for i, line in enumerate(f):if i == 0:continueif i > 200 and i< 7500:continueline = line.strip("\n") #去掉\nline = line.split(",", 1) #把这句话,按照,分割, 1表示分割次数data.append(line[1])label.append(line[0])print("读了%d的数据"%len(data))return data, label# file = "../jiudian.txt"
# read_file(file)
class jdDataset(Dataset):def __init__(self, data, label):self.X = dataself.Y = torch.LongTensor([int(i) for i in label])def __getitem__(self, item):return self.X[item], self.Y[item]def __len__(self):return len(self.Y)def get_data_loader(path, batchsize, val_size=0.2): #读入数据,分割数据。data, label = read_file(path)train_x, val_x, train_y, val_y = train_test_split(data, label, test_size=val_size, shuffle=True, stratify=label)train_set = jdDataset(train_x, train_y)val_set = jdDataset(val_x, val_y)train_loader = DataLoader(train_set, batchsize, shuffle=True)val_loader = DataLoader(val_set, batchsize, shuffle=True)return train_loader, val_loaderif __name__ == "__main__":get_data_loader("../jiudian.txt", 2)
Model
import torch
import torch.nn as nn
from transformers import BertModel, BertTokenizer, BertConfigclass myBertModel(nn.Module):def __init__(self, bert_path, num_class, device):super(myBertModel, self).__init__()self.bert = BertModel.from_pretrained(bert_path)# config = BertConfig.from_pretrained(bert_path)# self.bert = BertModel(config)self.device = deviceself.cls_head = nn.Linear(768, num_class) #分类头self.tokenizer = BertTokenizer.from_pretrained(bert_path)def forward(self, text):input = self.tokenizer(text, return_tensors="pt", truncation=True, padding="max_length", max_length=128)input_ids = input["input_ids"].to(self.device) #以字典形式存放token_type_ids = input['token_type_ids'].to(self.device)attention_mask = input['attention_mask'].to(self.device)sequence_out, pooler_out = self.bert(input_ids=input_ids,token_type_ids=token_type_ids,attention_mask=attention_mask,return_dict=False) #return_dictpred = self.cls_head(pooler_out)return predif __name__ == "__main__":model = myBertModel("../bert-base-chinese", 2)pred = model("今天天气真好")
在 Python 中,if __name__ == "__main__": 这部分代码起着重要作用。
__name__ 变量:
每个 Python 模块都有一个内置的 __name__ 变量。
当一个 Python 文件作为主程序直接运行时,该文件中 __name__ 的值会被设置为 "__main__"。
当一个 Python 文件被作为模块导入到其他文件中时,该文件中 __name__ 的值为模块名(即该文件的文件名,不包含 .py 后缀)。
if __name__ == "__main\a__": 的作用:
它可以用来区分该模块是被直接运行还是被导入。在 if __name__ == "__main__": 块中的代码只有在该模块作为主程序直接运行时才会被执行,而当该模块被导入到其他模块中时,这部分代码不会被执行。
import random
import torch
import torch.nn as nn
import numpy as np
import osfrom model_utils.data import get_data_loader
from model_utils.model import myBertModel
from model_utils.train import train_valdef seed_everything(seed):torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)torch.backends.cudnn.benchmark = Falsetorch.backends.cudnn.deterministic = Truerandom.seed(seed)np.random.seed(seed)os.environ['PYTHONHASHSEED'] = str(seed)
#################################################################
seed_everything(0)
###############################################lr = 0.0001
batchsize = 16
loss = nn.CrossEntropyLoss()
bert_path = "bert-base-chinese"
num_class = 2
data_path = "jiudian.txt"
max_acc= 0.6
device = "cuda" if torch.cuda.is_available() else "cpu"
model = myBertModel(bert_path, num_class, device).to(device)optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=0.00001)train_loader, val_loader = get_data_loader(data_path, batchsize)epochs = 5 #
save_path = "model_save/best_model.pth"scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=20, eta_min=1e-9) #改变学习率
val_epoch = 1para = {"model": model,"train_loader": train_loader,"val_loader": val_loader,"scheduler" :scheduler,"optimizer": optimizer,"loss": loss,"epoch": epochs,"device": device,"save_path": save_path,"max_acc": max_acc,"val_epoch": val_epoch #训练多少轮验证一次
}train_val(para)




![洛谷题单指南-线段树的进阶用法-P5445 [APIO2019] 路灯](https://img2024.cnblogs.com/blog/3330618/202502/3330618-20250206161041496-777296653.png)
![[LLM] ZeRO-DP技术简析](https://img2024.cnblogs.com/blog/1077980/202502/1077980-20250207124128680-1240450708.png)