DeepSeek-R1本地部署配置要求
Github地址:https://github.com/deepseek-ai/DeepSeek-R1?tab=readme-ov-file
| 模型规模 | 最低 GPU 显存 | 推荐 GPU 型号 | 纯 CPU 内存需求 | 适用场景 |
|---|---|---|---|---|
| 1.5B | 4GB | RTX 3050 | 8GB | 个人学习 |
| 7B、8B | 16GB | RTX 4090 | 32GB | 小型项目 |
| 14B | 24GB | A5000 x2 | 64GB | 专业应用 |
| 32B | 48GB | A100 40GB x2 | 128GB | 企业级服务 |
| 70B | 80GB | A100 80GB x4 | 256GB | 高性能计算 |
| 671B | 640GB+ | H100 集群 | 不可行 | 超算/云计算 |
扩展:

上面代表的是什么含义,首先我们知道671B的模型才是基础模型,其余的1.5B、7B、8B等都是蒸馏模型,因此Qwen代表是通义千问模型蒸馏的,Llama是通过Llama模型蒸馏的
DeepSeek-R1 + LMStudio本地部署
1.本次使用的操作系统,以及环境配置
操作系统:windows11
CPU: i7-11800H
内存:16GB
GPU:RTX3050ti 4G显存
2.安装LM Studio
官方网址:LM Studio - Discover, download, and run local LLMs
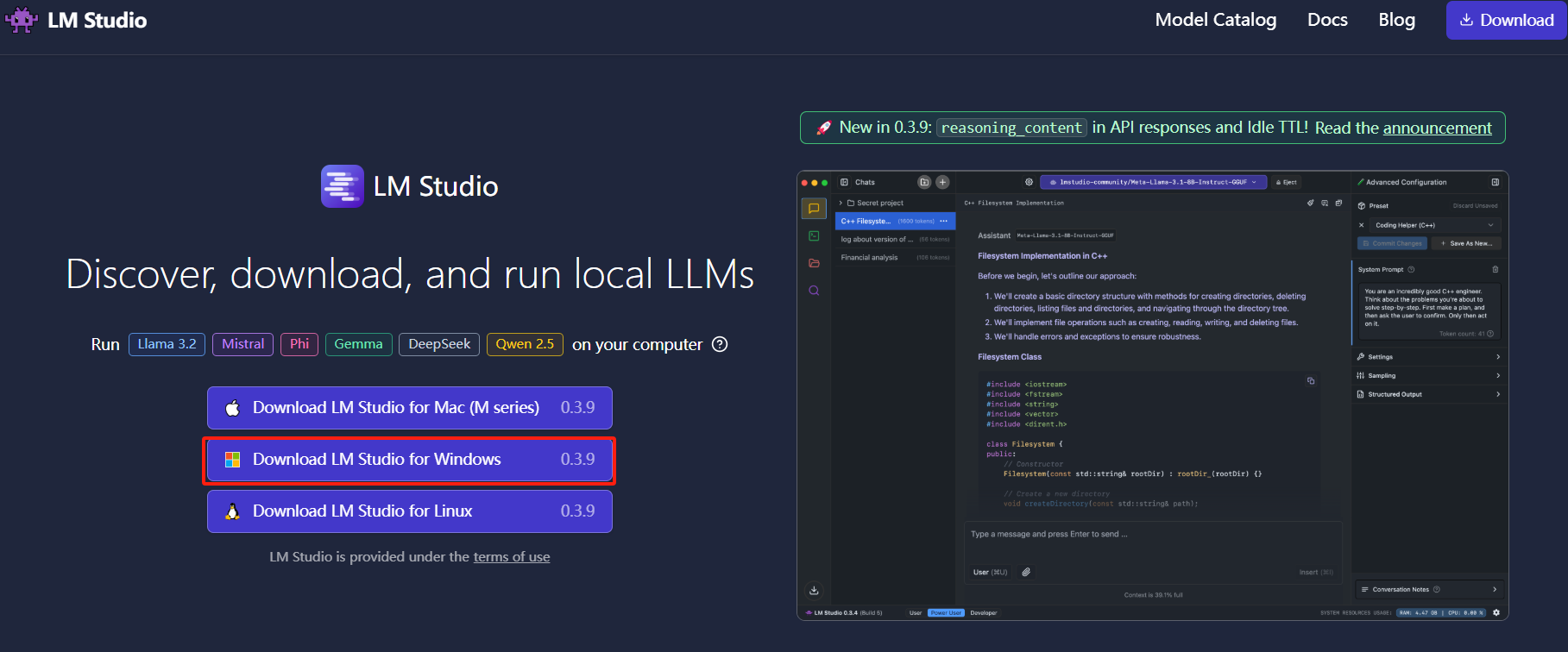
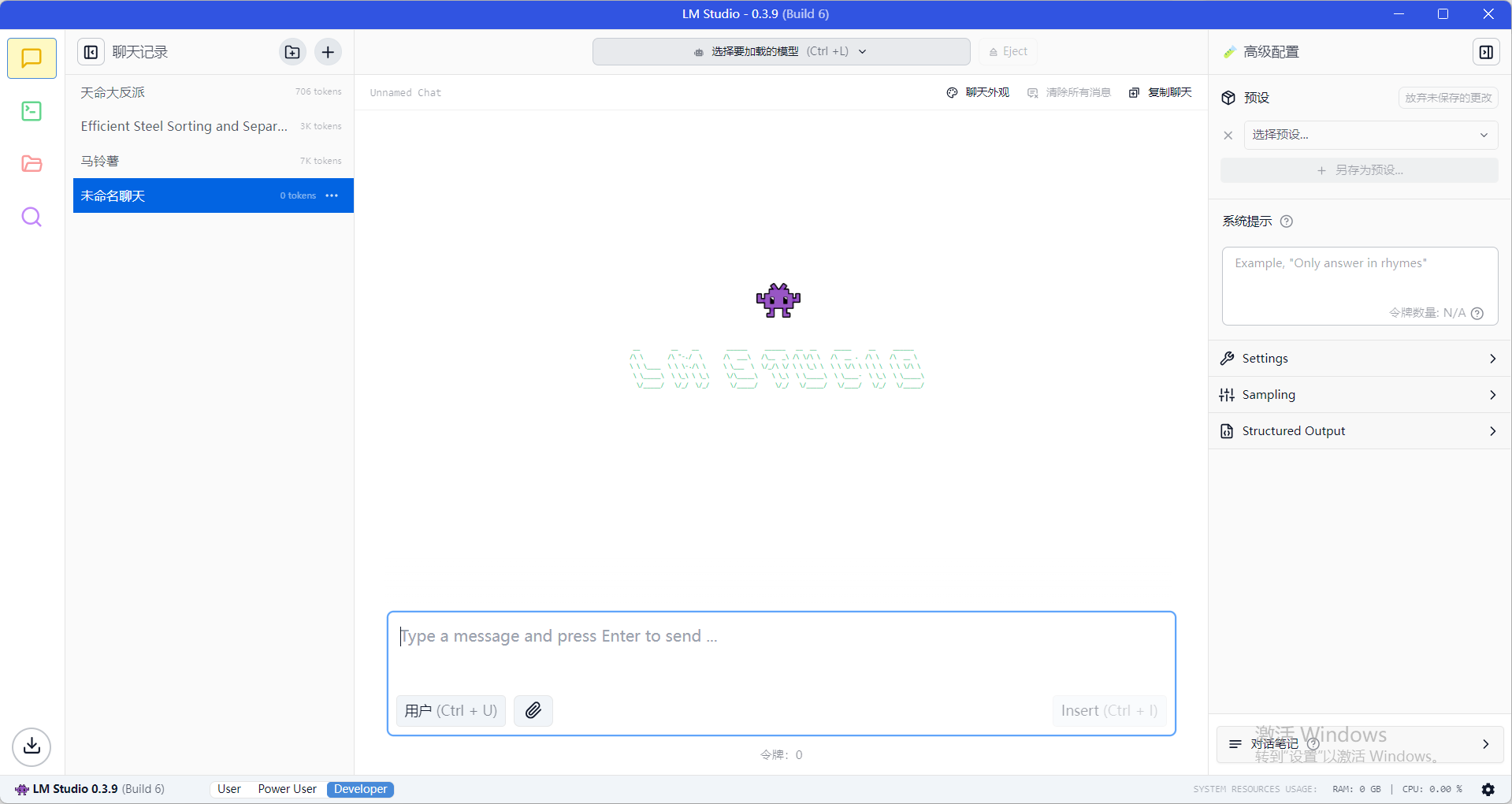
3.安装deepseek R1 8b模型
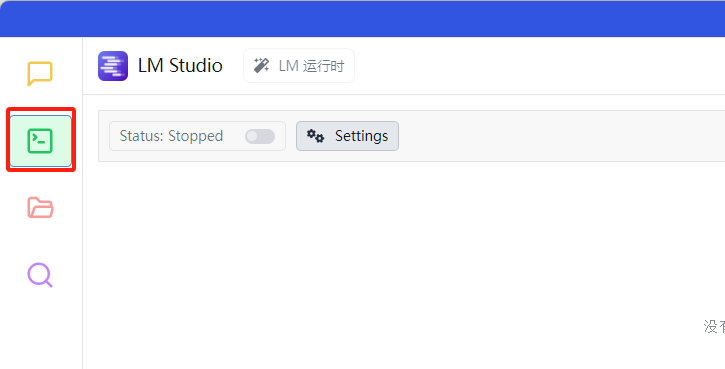
1)首先进入开发者模式
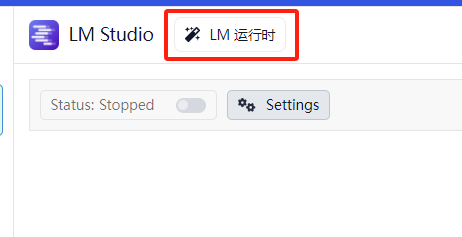
2)点击这里,进入配置项页面
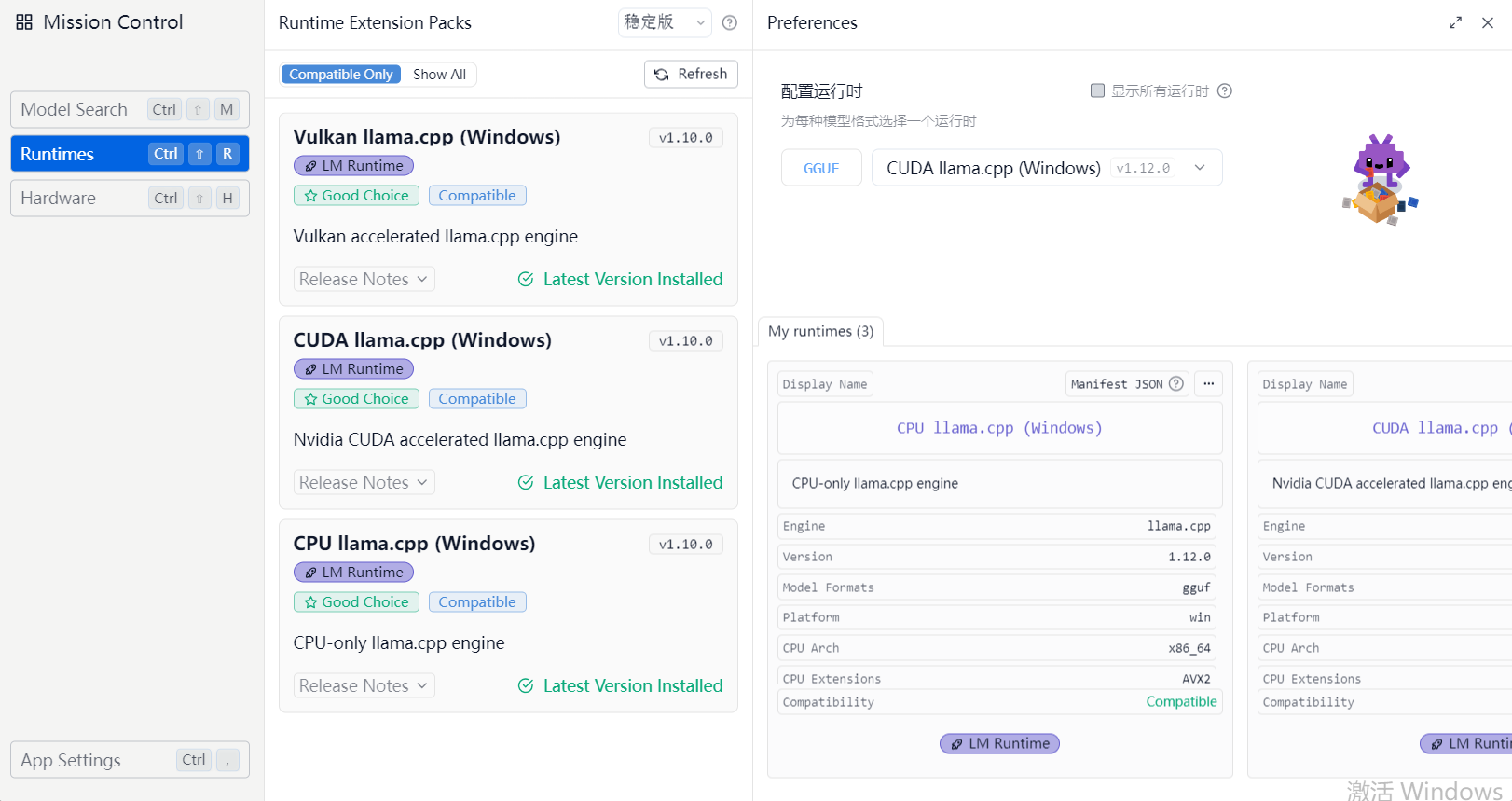
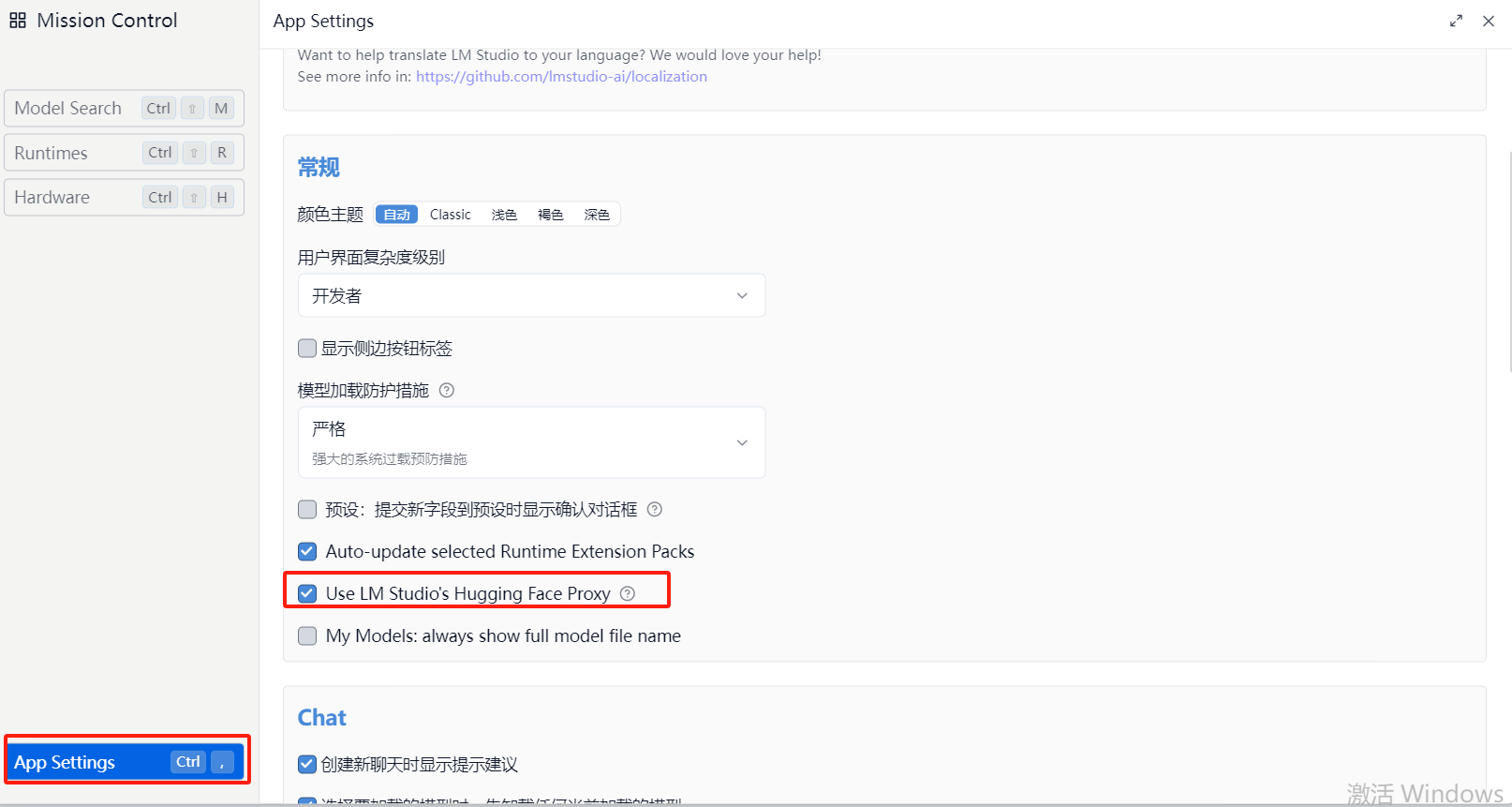
3)点击左下角,App Setting ,打开代理选项,可以进入https://huggingface.co(外网),也可以通过镜像网站https://hf-mirror.com进入
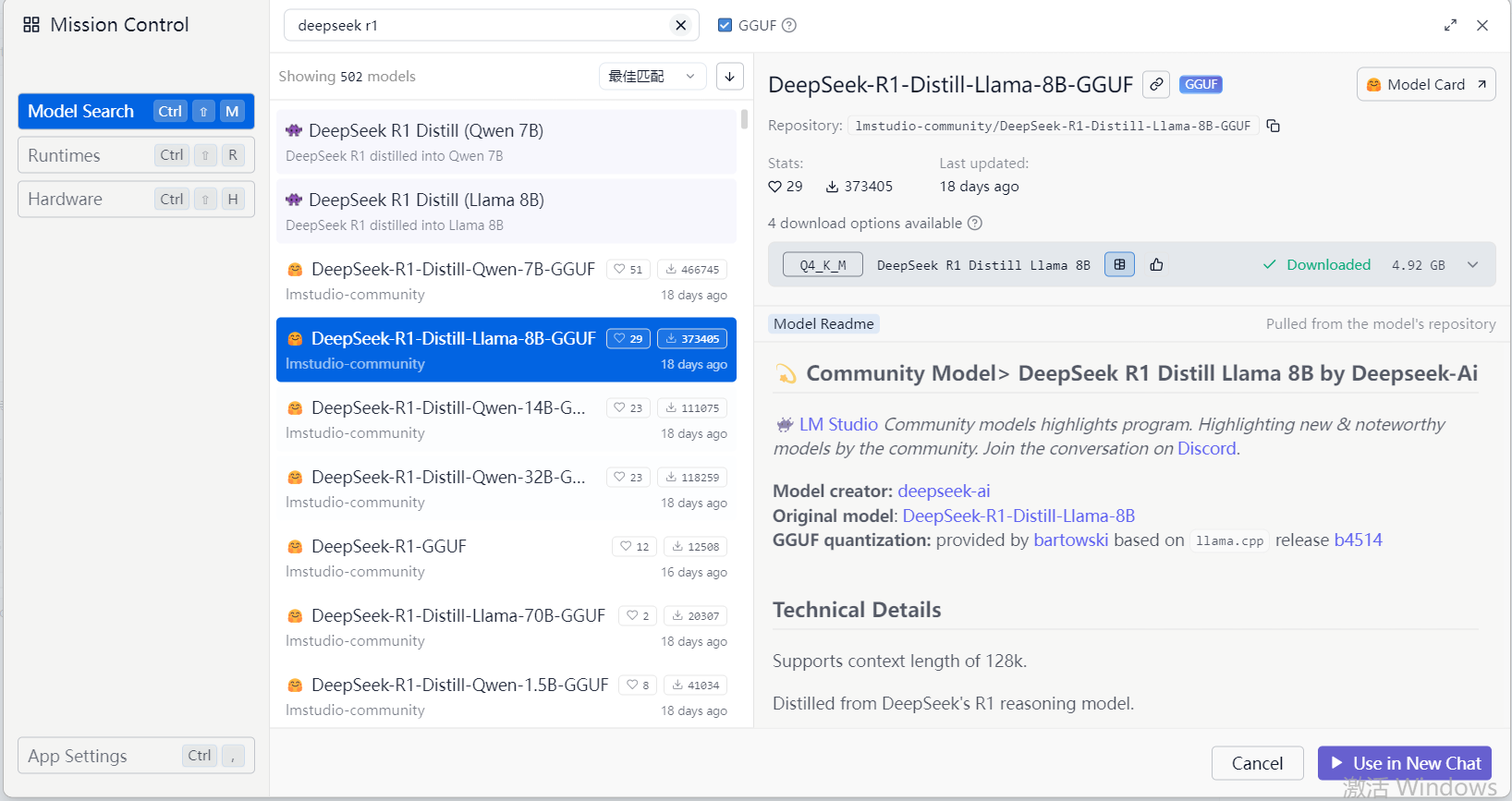
4)点击左上角,Model Search 就可以搜索模型,安装模型了(这里安装的是DeepSeek-R1-Distill-Llama-8B-GGUF)
大概4.5GB,安装时间会比较长
3.LM Studio + DeepSeek R1 8B模型使用技巧
1)选择要加载的模型

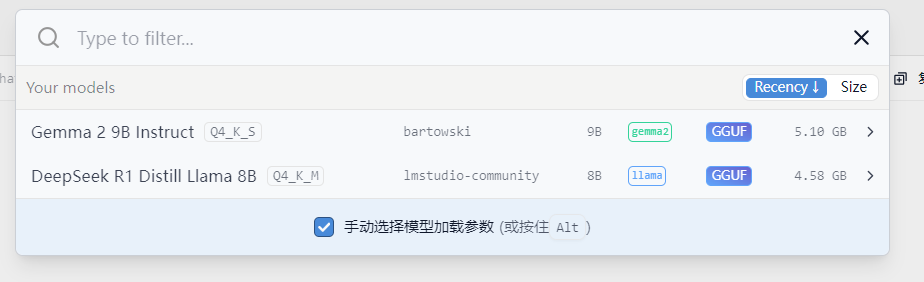
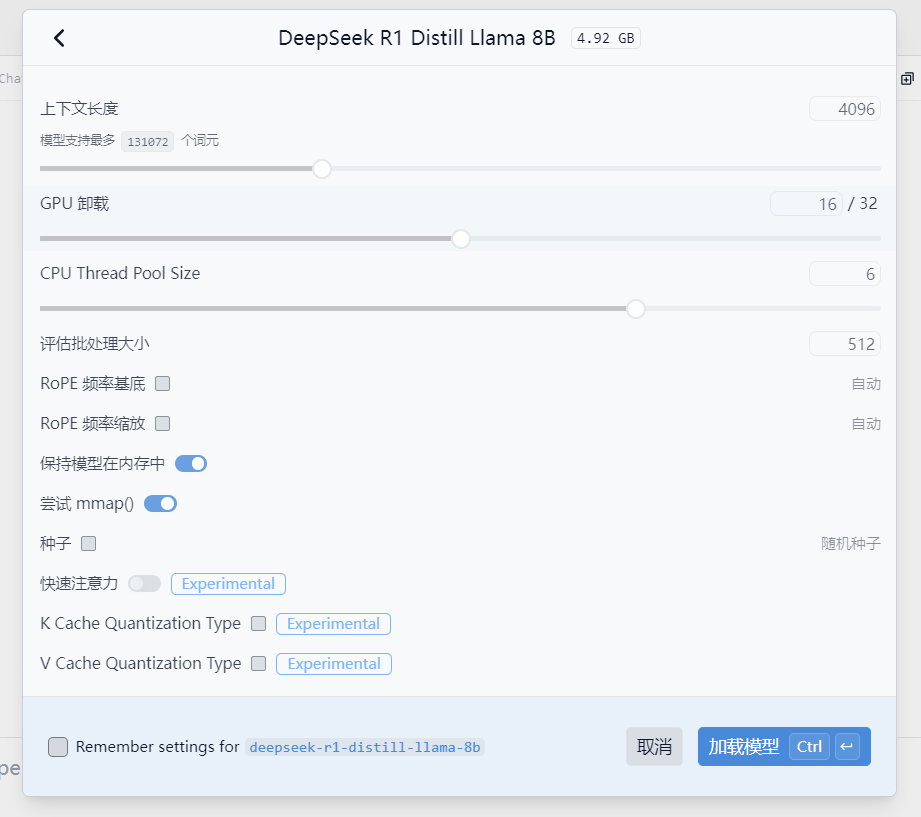
2)配置模型参数,是十分关键的
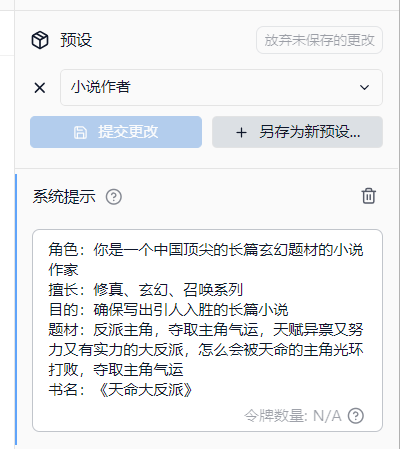
3)配置右侧的提示词,也是十分重要的,能够帮助模型快速的理解任务
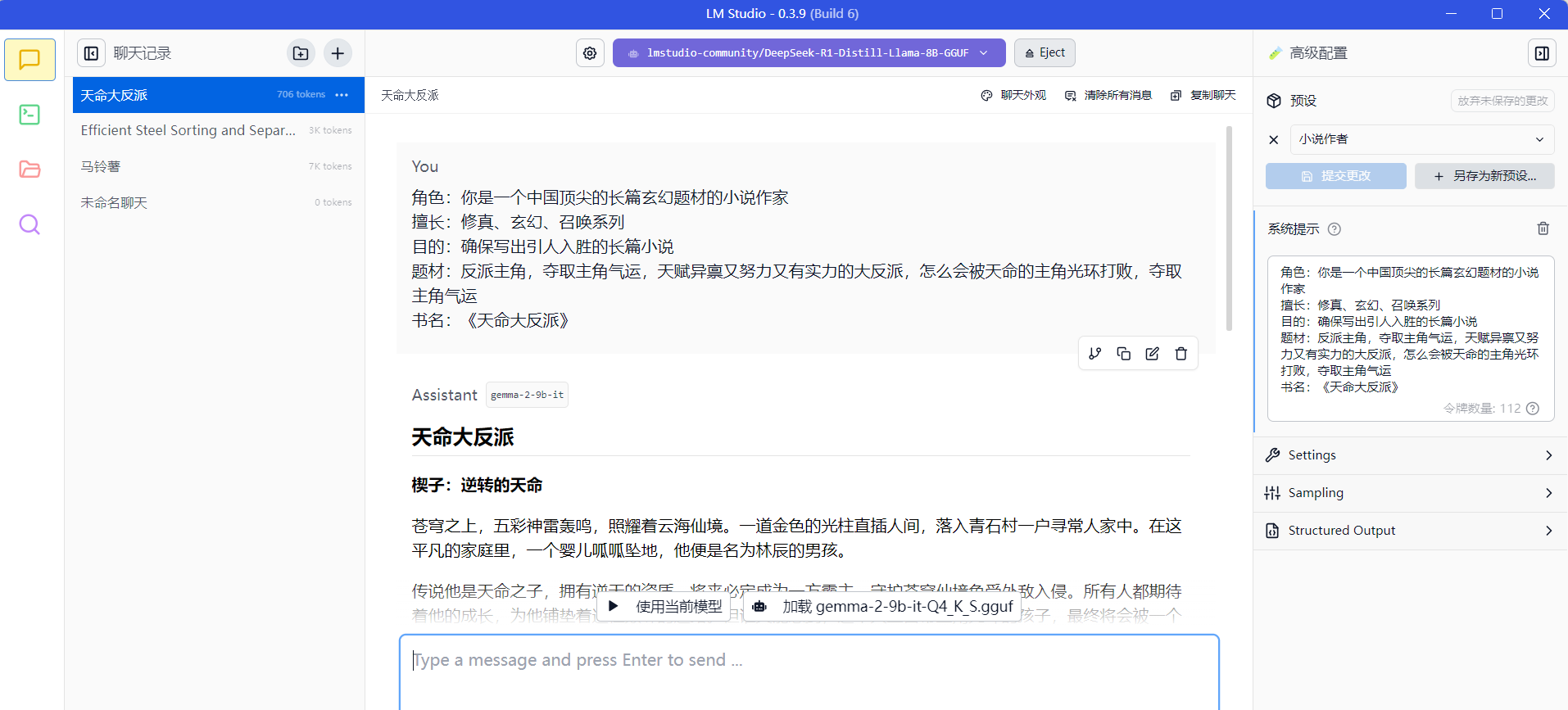
4)然后就可以开始使用了







![洛谷题单指南-线段树的进阶用法-P5445 [APIO2019] 路灯](https://img2024.cnblogs.com/blog/3330618/202502/3330618-20250206161041496-777296653.png)