Whisper 是一种通用的语音识别模型。它基于各种音频的大型数据集进行训练,也是一种多任务模型,可以执行多语言语音识别、语音翻译和语言识别。
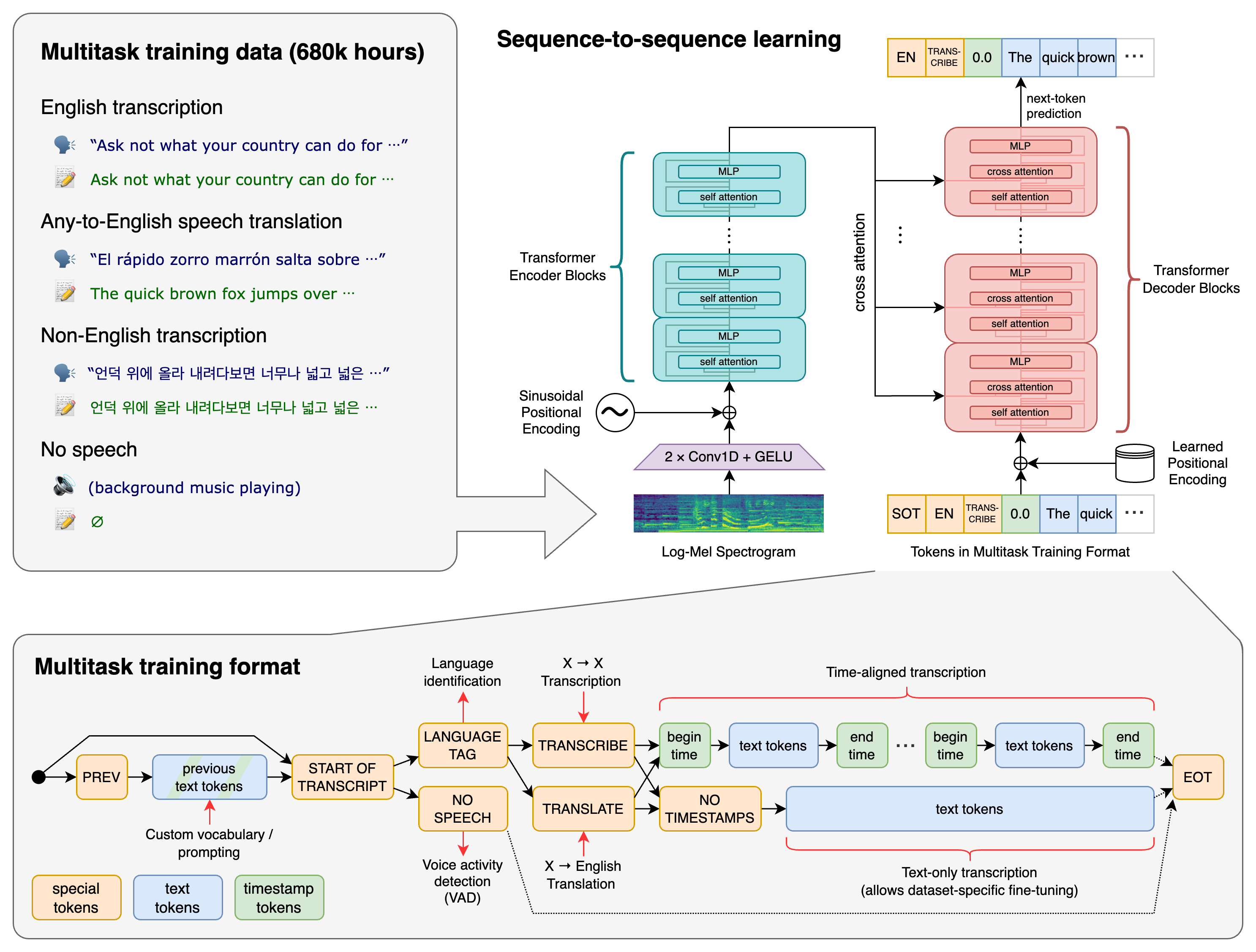
Transformer 序列到序列模型针对各种语音处理任务进行训练,包括多语言语音识别、语音翻译、口语识别和语音活动检测。这些任务共同表示为解码器要预测的令牌序列,从而允许单个模型替换传统语音处理管道的许多阶段。多任务训练格式使用一组特殊标记,用作任务说明符或分类目标。
py依赖项
fastapi~=0.112.1
uvicorn~=0.30.6
openai-whisper @ git+https://github.com/openai/whisper.git@v20231117
setuptools-rust==1.9.0
numpy==1.26.4
OpenCC==1.1.9
whisper~=1.1.10
torch~=2.4.0
它还需要在系统上安装命令行工具 ffmpeg,大多数包管理器都可以使用该工具:
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg# on Arch Linux
sudo pacman -S ffmpeg# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg# on Windows using Chocolatey (https://chocolatey.org/)
choco install ffmpeg# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpeg
如不需要借助工具安装,那么可以在官网直接下载安装包,解压后设置bin路径到环境变量中,具体可参考Win10 ffmpeg安装
whisper 模型库
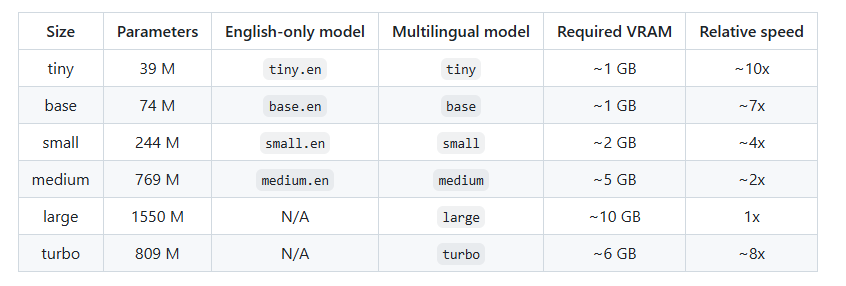
用于纯英语应用程序的 .en 模型往往性能更好,尤其是对于 tiny.en 和 base.en 模型。我们观察到,small.en 和 medium.en 模型的差异变得不那么显著。此外,turbo 模型是 large-v3 的优化版本,可提供更快的转录速度,同时将准确性的下降降至最低。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import socketimport uvicorn
from fastapi import FastAPI, File, UploadFile, HTTPException
from fastapi.responses import JSONResponse
from tempfile import TemporaryDirectory
import whisper
import torch
import os
import logging# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')from typing import List# 检查是否有NVIDIA GPU可用
torch.cuda.is_available()
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# 加载Whisper模型
model = whisper.load_model("base", device=DEVICE)app = FastAPI()def get_ip_address():"""查询本机ip地址"""s = Nonetry:s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)s.connect(('8.8.8.8', 80))ip = s.getsockname()[0]return ipexcept Exception as e:logging.error(f"获取ip 异常 {e}")ip = "127.0.0.1"finally:if s is not None:s.close()return ip@app.post("/whisper/")
async def handler(files: List[UploadFile] = File(...)):if not files:raise HTTPException(status_code=400, detail="No files were provided")# 对于每个文件,存储结果在一个字典列表中results = []# 使用TemporaryDirectory创建临时目录with TemporaryDirectory() as temp_dir:for file in files:# 在临时目录中创建一个临时文件temp_file_path = os.path.join(temp_dir, file.filename)with open(temp_file_path, "wb") as temp_file:# 将用户上传的文件写入临时文件temp_file.write(file.file.read())temp_file.flush() # 确保所有数据写入磁盘# 确保文件在转录前已关闭result = model.transcribe(temp_file_path)# 存储该文件的结果对象results.append({'filename': file.filename,'transcript': result['text'],})# 返回包含结果的JSON响应return JSONResponse(content={'results': results})if __name__ == '__main__':uvicorn.run(app=app, host=get_ip_address(), port=8080)
输出结果:
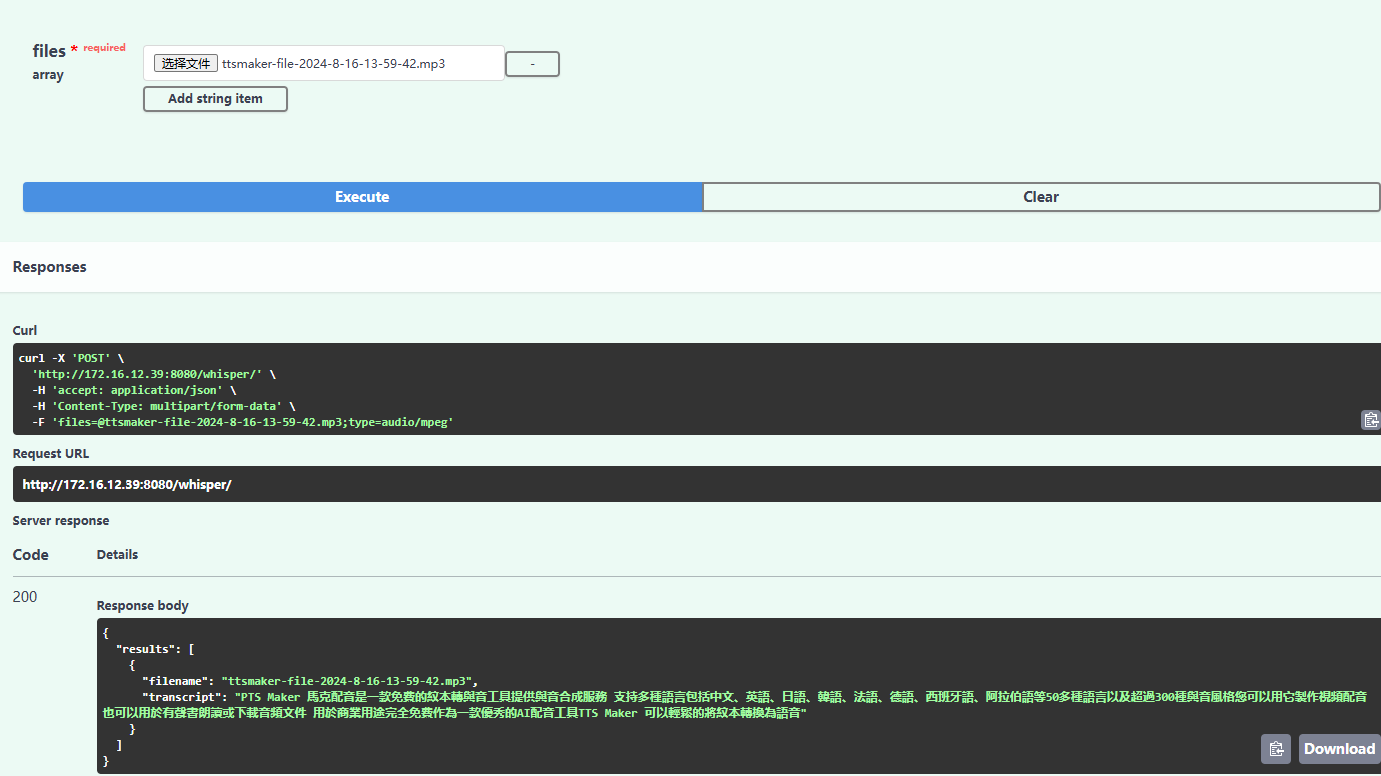
可以看到是中文繁体的,如需要转为简体,则需要借助OpenCC
from opencc import OpenCC
open_cc = OpenCC("t2s")
simple_zh = open_cc.convert("PTS Maker 馬克配音是一款免費的紋本轉與音工具提供與音合成服務 支持多種語言包括中文、英語、日語、韓語、法語、德語、西班牙語、阿拉伯語等50多種語言以及超過300種與音風格您可以用它製作視頻配音 也可以用於有聲書朗讀或下載音頻文件 用於商業用途完全免費作為一款優秀的AI配音工具TTS Maker 可以輕鬆的將紋本轉換為語音")
print(simple_zh)
输出结果:
PTS Maker 马克配音是一款免费的纹本转与音工具提供与音合成服务 支持多种语言包括中文、英语、日语、韩语、法语、德语、西班牙语、阿拉伯语等50多种语言以及超过300种与音风格您可以用它制作视频配音 也可以用于有声书朗读或下载音频文件 用于商业用途完全免费作为一款优秀的AI配音工具TTS Maker 可以轻松的将纹本转换为语音
完整代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import socketimport uvicorn
from fastapi import FastAPI, File, UploadFile, HTTPException
from fastapi.responses import JSONResponse
from tempfile import TemporaryDirectory
import whisper
import torch
import os
import logging
from opencc import OpenCC# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')from typing import List# 检查是否有NVIDIA GPU可用
torch.cuda.is_available()
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# 加载Whisper模型
model = whisper.load_model("base", device=DEVICE)app = FastAPI()
open_cc = OpenCC("t2s")def get_ip_address():"""查询本机ip地址"""s = Nonetry:s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)s.connect(('8.8.8.8', 80))ip = s.getsockname()[0]return ipexcept Exception as e:logging.error(f"获取ip 异常 {e}")ip = "127.0.0.1"finally:if s is not None:s.close()return ip@app.post("/whisper/")
async def handler(files: List[UploadFile] = File(...)):if not files:raise HTTPException(status_code=400, detail="No files were provided")# 对于每个文件,存储结果在一个字典列表中results = []# 使用TemporaryDirectory创建临时目录with TemporaryDirectory() as temp_dir:for file in files:# 在临时目录中创建一个临时文件temp_file_path = os.path.join(temp_dir, file.filename)with open(temp_file_path, "wb") as temp_file:# 将用户上传的文件写入临时文件temp_file.write(file.file.read())temp_file.flush() # 确保所有数据写入磁盘# 确保文件在转录前已关闭result = model.transcribe(temp_file_path)# 存储该文件的结果对象results.append({'filename': file.filename,'transcript': open_cc.convert(result['text']),})# 返回包含结果的JSON响应return JSONResponse(content={'results': results})if __name__ == '__main__':uvicorn.run(app=app, host=get_ip_address(), port=8080)swagger-ui 地址为主机ip:8080/docs