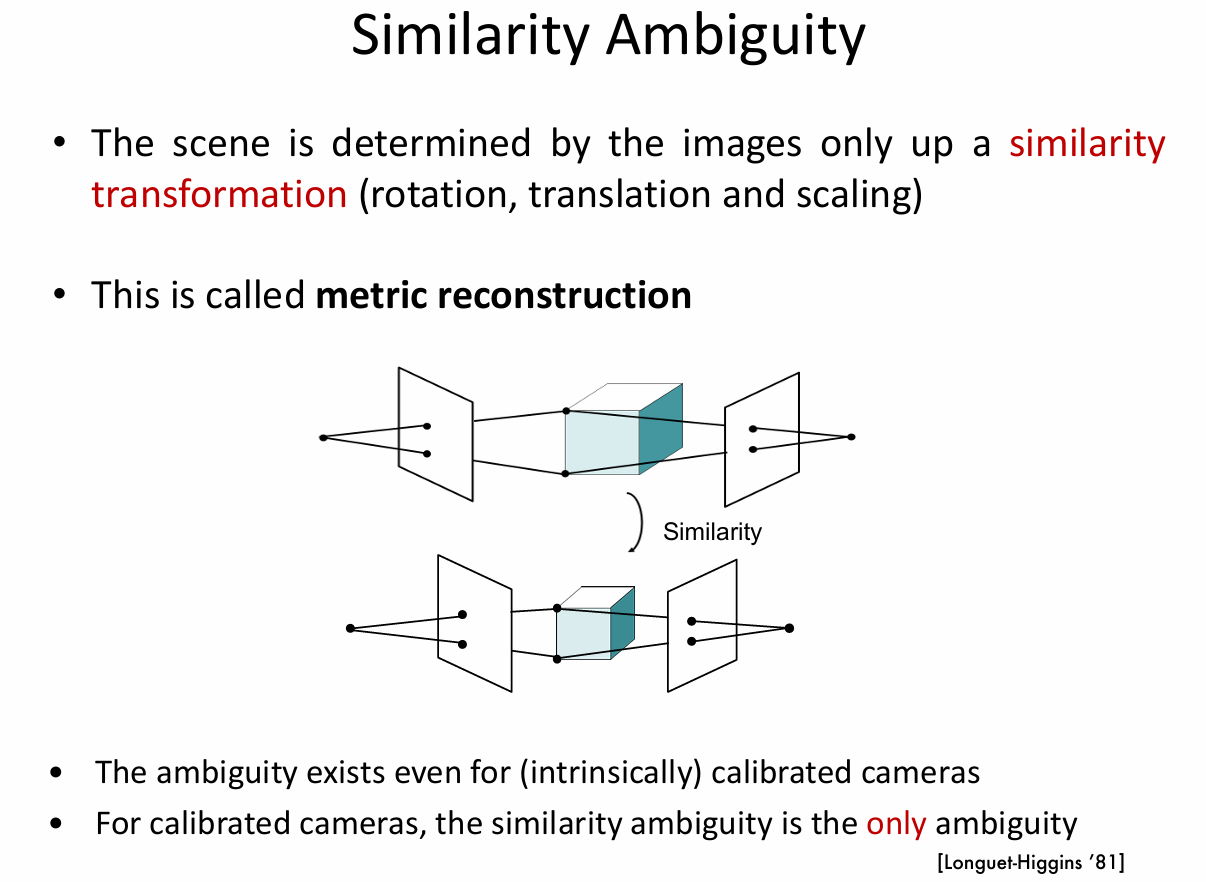
引言:让 AI 学会"思考"的新突破
在近年来的人工智能浪潮中,大型语言模型(LLM)如 ChatGPT 已经能回答各种问题,但它们在复杂推理方面仍有不足。所谓复杂推理,比如解决奥数难题、编写复杂代码或进行多步逻辑推导,这些都相当于让 AI "动脑筋"思考多步。以前的 AI 往往容易在这些任务中出错。DeepSeek-R1 的出现标志着一个重要突破:研究者找到了一种新方法,让 AI 通过强化学习反复试错,逐渐学会像人一样多步推理问题更棒的是,DeepSeek-R1 是完全开源的,这意味着任何人都可以使用它,不用依赖收费的商用 AI 服务。下面我们将用通俗的语言介绍 DeepSeek-R1 的核心理念、它是如何训练的,以及它能带来什么应用价值。
核心理念:用强化学习培养 AI 的"逻辑思维"
DeepSeek-R1 的核心思想是模拟人类解题的过程来训练 AI。想象我们教一个学生解数学题:一开始学生并不知道怎么下手,但通过不断尝试、犯错、再纠正,他的解题思路会越来越清晰。DeepSeek-R1 的训练就类似这样,只不过这里学生是 AI,老师不是人,而是奖励和惩罚机制。研究者让模型尝试回答各种复杂问题,然后用程序自动检查答案对不对,对正确的过程给予奖励,错误的则不给奖励。在成千上万次这样的训练循环后,模型会倾向于采用能得高分的推理策略,慢慢地就学会了复杂问题的解法。这种训练方法被称为强化学习(Reinforcement Learning),因为模型通过"强化"成功的尝试来学习。DeepSeek-R1 特别之处在于:它在训练初期没有人工示范,完全靠自己摸索。研究者先让一个基础模型(DeepSeek-V3-Base)直接进入强化学习,就像让 AI 小孩自己玩谜题,结果这个模型(称为 DeepSeek-R1-Zero)居然自己悟出了很多强大的解题技巧!比如,它学会了反思自己的答案、尝试不同思路等,这些都是人类优秀解题时会用的策略。可以说,经过强化学习,"小孩"已经变成了有创造力的"数学家",只是有时候表达还不太通顺。
但是,仅靠自我摸索的 R1-Zero 也有明显的问题:它给出的答案有时很难读懂,甚至会中英混杂,或者回答偏离人们习惯的表达方式。这就好比一个钻研技术的极客,思路很厉害但是说话让人抓不住重点。为了解决这个问题,研究者对模型进行了两次额外的指导调整:第一次是喂给它一些"冷启动"例子,相当于给模型打好基础,让它知道回答时基本的礼仪和清晰度。第二次是在强化学习之后,研究者收集了模型在训练中表现优秀的解题示例,再混合一些人工整理的题目,重新训练模型一次。这一步就像老师看到学生自己总结了一些很好的解题方法,帮他整理成笔记巩固学习。经过这两轮调整,模型的表达流畅了,知识面也更广了。这时再让模型进行最后一轮强化学习,让它面对各种类型的问题训练,相当于毕业前的全面模拟考试。最终诞生的 DeepSeek-R1 模型,既有缜密的推理能力,又能用清晰自然的语言给出答案。
总结起来,DeepSeek-R1的训练流程可以用以下步骤概括:
- 预热训练:先用一些人工整理的问答对,教模型基本的回答规范(确保它回答不牛头不对马嘴)。
- 自我尝试:不给示范,直接让模型挑战各种推理难题,通过试错积累经验(强化学习阶段)。
- 优例精炼:收集模型在尝试中表现好的范例答案,再训练模型一次,让它学会用更好的表述和思路回答。
- 综合考核:最后,再让模型在混合了所有类型问题的环境下强化学习一次,确保它在各方面表现均衡、稳健。
通过这样的流程,DeepSeek-R1就像一个经历了自学、纠错、再学习、再实战的学生,最终成长为解题高手。
能力与表现:媲美顶尖 AI 的开源模型
DeepSeek-R1 经过上述训练,达到了令人惊艳的水平:在许多困难测试上,它的表现几乎追上了目前最强的闭源 AI 模型 OpenAI-o1。例如:
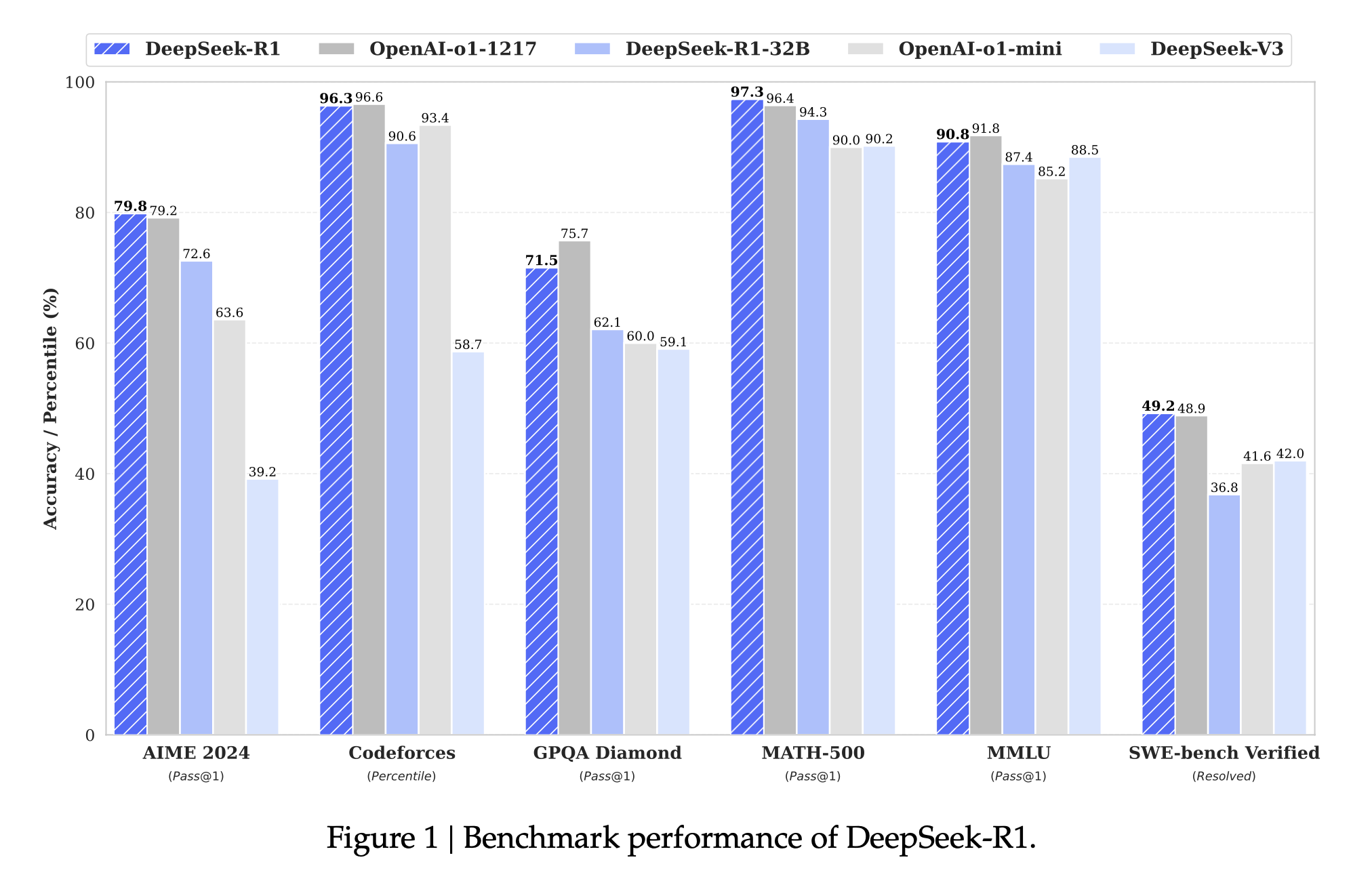
- 在数学考试中,DeepSeek-R1 的得分与 OpenAI 的顶级模型几乎持平。针对美国高中数学竞赛(AIME)的测试,R1 答对了 79.8% 的问题,而 OpenAI-o1 答对了 79.2%—两者几乎一样好。这说明 R1 已经能够解决非常复杂的数学题,而这往往被视为 AI 难以企及的挑战。更夸张的是,在一份包含 500 道高难度数学题的测验中,R1 的准确率高达 97.3%,和 OpenAI-o1 的 96.4% 相当。可以想象,这样的成绩甚至超过了很多人类参赛者。
- 在编程方面,DeepSeek-R1 表现出接近资深程序员的水准。研究者让它参加编程竞赛平台 Codeforces 的挑战,结果 R1 的积分相当于超过 96% 的人类选手!OpenAI-o1 也很强,但 R1 略胜一筹。这意味着 R1 不仅会写简单代码,还能解决竞赛级别的算法难题,能够当作编程助手来使用。
- 在常识问答和知识测验上,DeepSeek-R1 同样表现亮眼。在一个涵盖历史、文学、科学等各种领域知识的 MMLU 考试中,R1 的得分接近 91%,几乎和 OpenAI-o1 不相上下。要知道,这种考试涉及广博的知识和理解能力,R1 展现出接近人类专家的水平。此外,OpenAI 发布的一项新测验 SimpleQA(考查模型回答简单常识问题的准确性),R1 也击败了它的前辈模型 DeepSeek-V3,证明它不仅会推理,连知识问答也更胜一筹。
简单来说,DeepSeek-R1 已经在数学、逻辑和代码这"三座大山"上站到了开源模型的顶峰,甚至与目前最先进的闭源模型平起平坐。这对于开源社区和普通用户意义重大:以前这些顶尖能力只存在于少数公司的保密模型中,而现在一个免费开放的模型就能实现。
应用价值:开放且高效的 AI 智囊
DeepSeek-R1 的成功带来了多方面的应用价值:
-
教育与学习:由于具备极强的解题和推理能力,R1 可以用来当智能教师或辅导。比如,它可以详细解答奥数题步骤,提供证明思路;对于编程学习者,它能讲解代码难点、帮助找出程序错误。重要的是,R1 善于给出逐步推理过程而不仅仅是答案,这对学习者理解知识非常有帮助。
-
科研助理:在科学研究中常常需要推理和计算。R1 已经能解决很多大学甚至研究生水平的题目(论文中提到它通过强化学习,能解答研究生级别的数学问答)。因此,科研人员可以把 R1 当作一个"头脑风暴"助手,询问它复杂的问题,看看它给出的思路和答案是否有借鉴价值。虽然不一定每次都完全正确,但它提供的新角度可能启发人类思考。
-
代码开发:R1 在代码竞赛上表现出色,这意味着它可以作为编程助手 AI 部署在开发者工具中。它可以帮助自动生成代码片段、优化算法,或者根据错误信息提示调试方向。对于企业而言,用一个开源的高能力模型集成到自己的开发流程,比调用昂贵的外部 API 更经济可控。
-
开放研究推动:最大的价值还在于开放性。DeepSeek-R1 的模型权重和代码都已开源。这就像一家顶尖厨师公开了独门菜谱,全球的 AI 研究者和爱好者都能细细研究它的训练细节,尝试改进或衍生新的模型。这将加速整个领域的进步。举个例子,R1 的成功让大家看到,原来不靠人工反馈,纯粹用 AI 自己强化学习也能达到很高水平。这可能引发更多类似研究,甚至应用到其他类型的 AI 模型上(如机器人决策等)。
-
成本优势:商业 API 如 OpenAI 的服务价格高昂,而 DeepSeek-R1 作为开源模型,使用成本几乎为零,只需有足够的算力就能运行。即使算上运行开销,据报道 DeepSeek 团队提供的同款云服务价格也远低于 OpenAI,例如处理同样文本量,R1 的费用只是 OpenAI 的几十分之一。这对中小企业和个人开发者来说非常有吸引力,可以以低成本获取顶尖 AI 能力。
总之,DeepSeek-R1 让高阶的 AI 推理能力变得更普惠。以前只有少数科技巨头的模型才能解决的难题,现在开源社区也有了平起平坐的作品。这为教育、科研、工业等各领域引入智能助手创造了条件。人们可以更放心地使用并改造这样一个开放模型,在保护隐私、定制功能方面也更灵活。
相关研究进展:AI 学会思考的道路
DeepSeek-R1 并非横空出世,而是站在许多前人研究的肩膀上,同时也引领着新的趋势。通俗地看,AI 学会复杂推理主要经历了几个阶段:
-
Chain-of-Thought 方法:早些时候,研究者发现,让模型在得到最终答案前先输出一串思考过程(即 Chain-of-Thought,推理链)能大幅提高正确率。这有点像让模型"想出声"。谷歌等公司的实验表明,大模型其实有潜力进行多步推理,只要我们提示它把中间步骤写出来。OpenAI 的代号 o1 模型进一步发展了这个思路,延长推理步骤显著提升了数学、逻辑题的表现。这可以说是 AI 学会"分步骤思考"的开端。DeepSeek-R1 在训练中大量运用了这点:模型的强化学习奖励不仅看最后答案对不对,也看中间推理是否合理。因此 R1 生成回答时,会自动包含详细的步骤推演,从而保证思路清晰可靠。
-
人类反馈与对齐:为了让 AI 回答更符合人意,强化学习 + 人类反馈 (RLHF) 成为主流方案。比如 InstructGPT 和 ChatGPT 背后,都有人类参与打分,告诉模型哪些回答更好。Anthropic 的 Claude 模型也引入了"人工宪法"来约束模型行为。然而,人来评判终究效率低、成本高。近期的趋势是让 AI 来自我反馈。DeepSeek-R1 就大量采用了这种 AI 判别 AI 的方法:用预先训练的模型或规则来评价另一个模型的输出。当 R1 自己练习解题时,一个检查程序充当裁判打分,这样就省去了人工批改。另外,R1 在最后的训练中,也加入了模型判断的"偏好信号",比如让另一个 AI 检查 R1 的回答是否礼貌、不乱说。这种 AI 自我对齐的技术(有点像 AI 自己给自己立规矩)也是未来的大趋势。
-
逐步验证与工具:让 AI 自己检查自己是另一个思路。例如,有研究给模型配了一个"小助手"或"计算器"来验证它每一步推理是否正确,如果不对就返回修改。这类似人类在解题时每一步都检验,但对于通用 AI 来说实现很难。DeepSeek-R1 的研究团队也尝试了这种逐步验证的方法,在数学题上用一个验证模块检查模型每一步推导。尽管概念很好,但他们发现实际效果一般,因为很难给所有类型的问题设计统一的检查机制。因此这种方法目前还是在特定领域有效,比如数学证明、代码测试等。未来,结合更多工具(比如让 AI 调用计算器、定理证明器)或许能进一步提高 AI 推理的可靠性。DeepSeek 团队也开发了 DeepSeek-Prover 等工具类系统用于证明题,让 AI 借助符号证明程序来求解。这些探索表明,让 AI 学会合理调用工具、或者在内部结合搜索算法,将会是增强推理能力的重要方向。
-
自我游戏与探索:AlphaGo 通过与自己对弈学会了围棋大师级水平,给 AI 领域很大启发。类似地,如果让语言模型不断和自己"对话"或"对抗",是否能变得更聪明?有研究尝试让两个模型互相出题、互相检查,从而逼迫彼此进步。这有点像让 AI 组成学习小组。DeepSeek-R1 虽然没有明说用两个模型对练,但它本质上是让模型在跟环境(题目和奖励机制)的博弈中成长。这种自我博弈式的训练理念在 AI 推动 AGI(通用智能)的道路上可能会越来越常见。因为它减少了对人类指导的依赖,AI 可以在虚拟环境中自主进化。OpenAI、DeepMind 等也在探索类似思路,将强化学习应用于语言模型,让它们自己发现解决问题的新策略。
总而言之,DeepSeek-R1 凝聚了 AI 自主学习和复杂推理研究的一次飞跃成果。它既受益于前人的方法(如推理链、强化学习原理),又大胆地证明了纯强化学习也能训练出强大的语言模型。对于普通人来说,这样的进步意味着未来的 AI 助手会越来越聪明,不仅能听懂我们的问题,还能真正帮我们推理出答案,解决一些连人类都需要冥思苦想的问题。而且这些 AI 将更开放可及,我们可以在自己的电脑上跑一个"爱思考"的 AI 助手,帮助学习、编程、创作甚至科研。DeepSeek-R1 只是一个开始,随着社区对它的研究和改进,我们有理由期待下一个更强的 "R2" 出现,让人工智能向着真正懂思考、会推理的方向迈进一大步。正如这项研究展示的:"让 AI 自己学会思考",终将不再只是梦想。
参考文献:
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning



![题解 [ARC127C] Binary Strings](https://cdn.luogu.com.cn/upload/image_hosting/1bmpfrpo.png)
![[图形绘制/流程图] Mermaid : 开源的低代码图形绘制语言、协议及工具](https://blog-static.cnblogs.com/files/johnnyzen/cnblogs-qq-group-qrcode.gif?t=1679679148)