作者:望宸
大模型性能的持续提升,进一步挖掘了 RAG 的潜力,突破“检索-拼贴”的原始范式。

详见下方“RAG 的定义、优势和常见架构”
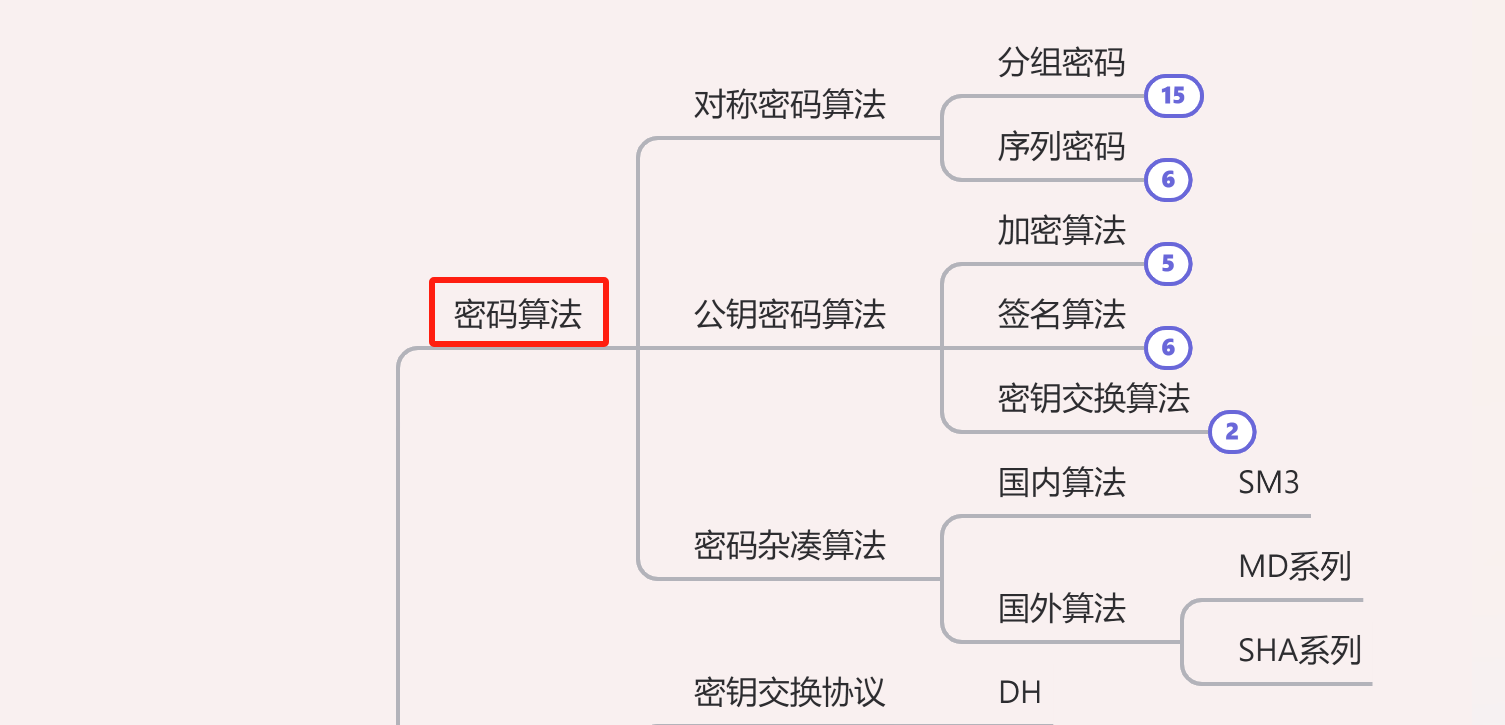
这张图近期在国外社区传播比较多,结构化的描述了 RAG 的主流架构。RAG 用于提升大模型的生成效果,使得大模型更加智能,而持续提升的大模型语义和逻辑推理能力,又能更加精准的识别和应用专业知识库。本文将梳理 RAG 的基本信息,旨在获得更加清晰的理解。
目录:
- 为什么需要 RAG
- RAG 的定义、优势和常见架构
- 还有哪些方式,可以提升大模型的生成结果
- RAG 实践
为什么需要 RAG?
早期,大模型在进行训练的时候,由于训楼集是固定的,在面对时效性强、领域专精或长尾问题时表现不佳。例如提问生物医学领域的学术问题,或者让大模型对今年结束的体育赛事进行总结,都会出现比较严重的幻觉,或者直接给出“我的知识更新截止到xxxx年xx月,无法访问或检索之后的数据。”
RAG 的核心思想是将检索系统与生成模型相结合,通过动态检索外部知识库来增强模型的生成能力。这一架构突破了传统模型的静态知识限制,拓展了模型开启了“生成+检索”协同工作的新范式。
RAG 的定义、优势和常见架构?
RAG(Retrieval-Augmented Generation)在 2020 年发表的《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》 [ 1] 的论文中,首次作了详细介绍。
由于外部的知识库是精挑细选的,使得知识库本身的语料质量相对较高,且因有专人维护,大幅提升了生成效果。例如国内的知网、国家法律法规数据库、万方数据库等,国外的有维基百科、ArXiv、Google Scholar 等。
RAG 带来诸多优势,包括无需重新训练模型,即可更新知识库;生成结果可追溯至检索到的具体文档片段;相比使用语料库去微调(Fine-tuning)大模型,RAG 的部署和维护成本更低。我们将其优势总结如下:

RAG 的常见架构:
- Naive RAG: 最基础的 RAG 架构,通过检索相关文档片段并将其作为上下文输入到生成模型中来生成响应。就像你去图书馆找书,先随便找几本相关的,然后读一读,再写个总结。
- Retrieve-and-rerank: 这种架构首先检索相关的文档片段,然后对这些片段进行重新排序,以选择最相关的片段作为上下文输入到生成模型中。就像你在图书馆先找一堆书,然后仔细看看哪些书最相关,再用这些书来写总结。
- Multimodal RAG: 这种架构处理多模态数据(如文本、图像等),通过多模态嵌入模型将不同类型的输入转换为统一的表示形式,然后进行检索和生成。这次你不仅找书,还找图片、视频等各种资料,把它们都变成可以比较的东西,再找最相关的来用。
- Graph RAG: 这种架构利用图数据库存储和检索信息,通过图结构来捕捉数据之间的关系,从而生成更相关的响应。你用一种特别的方式组织你的资料,比如思维导图,这样更容易找到最相关的信息。
- Hybrid RAG: 这种架构结合了多种检索和生成技术,旨在提高系统的灵活性和性能。你用各种方法找资料,比如图书馆、网络搜索等,然后综合起来用。
- Agentic RAG (Router): 这种架构使用代理(agent)来路由查询到不同的检索和生成模块,根据查询的类型和需求选择最优的处理路径。你有一个小助手,它帮你决定去哪里找资料,比如是去图书馆还是上网搜。
- Agentic RAG (Multi-Agent RAG): 这种架构使用多个代理协同工作,每个代理负责特定的任务或数据源,共同完成复杂的检索和生成任务。你有一群小助手,每个小助手负责不同的任务,比如有的去找书,有的去上网搜,最后大家一起合作完成任务。
还有哪些方式,可以提升大模型的生成结果
提示词
提示词是最原始、最直观的与大语言模型的交互方式,是一种指令或引导信息。例如一年前我们和大模型交互,往往会先为大模型设定一个角色。“假设你是一位健身教练,帮我准备一周的健身食谱”。
但随着大模型生成能力的增强,可以省略一些比较机械的指令,例如直接跨过角色设定和大模型进行交互。但提示词的设计依旧关键,他已经泛化为我们和大模型之间的“提问技巧”,例如“帮我提炼这篇论文的核心内容,并以大学生能理解的语言进行解释”。
微调
微调是指在预训练模型(如 BERT、GPT)的基础上,使用特定任务的数据继续训练,调整模型参数,使其适应新任务(如法律文件输出、医疗文本分类)。微调的技术方案众多,沿着性价比(资源投入vs.生成效果)的演进路线在迭代。主流的微调方案有:
- 全量微调: 深度适配模型参数,用特定数据重新训练大模型,让它更擅长某个领域,例如法学大模型、医学大模型等,但是训练成本高。适用于法律合同生成、医学诊断等容错性要求较高的领域。
- Lora 微调: LoRA(Low-Rank Adaptation,低秩自适应),是性价比更高的大模型微调技术,通过低秩矩阵分解,仅训练少量新增参数来适配下游任务,同时冻结预训练模型原有的参数,训练成本低,但是生成效果可能不如全量微调。适用于写作、图片生成领域微调风格化等场景。
举个例子来理解两者的区别,全量微调是对大学 4 年的美学课程进行全面学习,Lora 微调则是针对国风画进行专攻。此外,还有 Adapter、BitFit 等微调方式,实现大模型从“全量改造”到“精准手术”的演进,追求效率和结果的平衡。
蒸馏
蒸馏是一种模型压缩技术,通过让小型模型(学生模型)模仿大型复杂模型(教师模型)的“知识”,使得小模型能在保持较高性能的同时显著减少计算资源需求。

联网搜索技术
早期基模推理能力不够理想时,且互联网的数据治理不高,若接入联网搜索技术,会加大模型的幻觉。但随着基模推理性能不断增强,幻觉逐步减少,大模型们逐步都提供了联网搜索能力,以强化大模型在效性强、长尾问题时的表现。

除了这些偏上层的优化方案,还有很多大模型底层的技术优化方案,包括监督微调(SFT)、强化学习(RLHF)、纯强化学习(RL)、混合专家系统(MoE)、稀疏注意力机制等,这些能从根上优化大模型的推理能力。
RAG 实践
这里设计一个降本的场景来体验 RAG+网关+向量数据库的实践,该实践曾用于 Higress 的编程挑战赛 [ 2] 。
大模型 API 服务定价分为每百万输入 tokens X 元(缓存命中)/ Y 元(缓存未命中),X 远低于 Y,以通义系列微例,X 仅为 Y 的 40%,若能设计较好的缓存命中逻辑,不仅能降低响应延时,还将能缩减大模型 API 的调用成本。
Higress 的插件市场提供了 AI Proxy 的 WASM 插件,支持对接 LLM 提供商实现 RAG 能力。例如,导入一份烤箱使用说明书,作为外部知识库,使用阿里云的 Lindorm、Tair 或其他向量检索服务提供的向量检索能力对 LLM 结果进行向量召回,最终生成内容。插件的工作流程图如下:
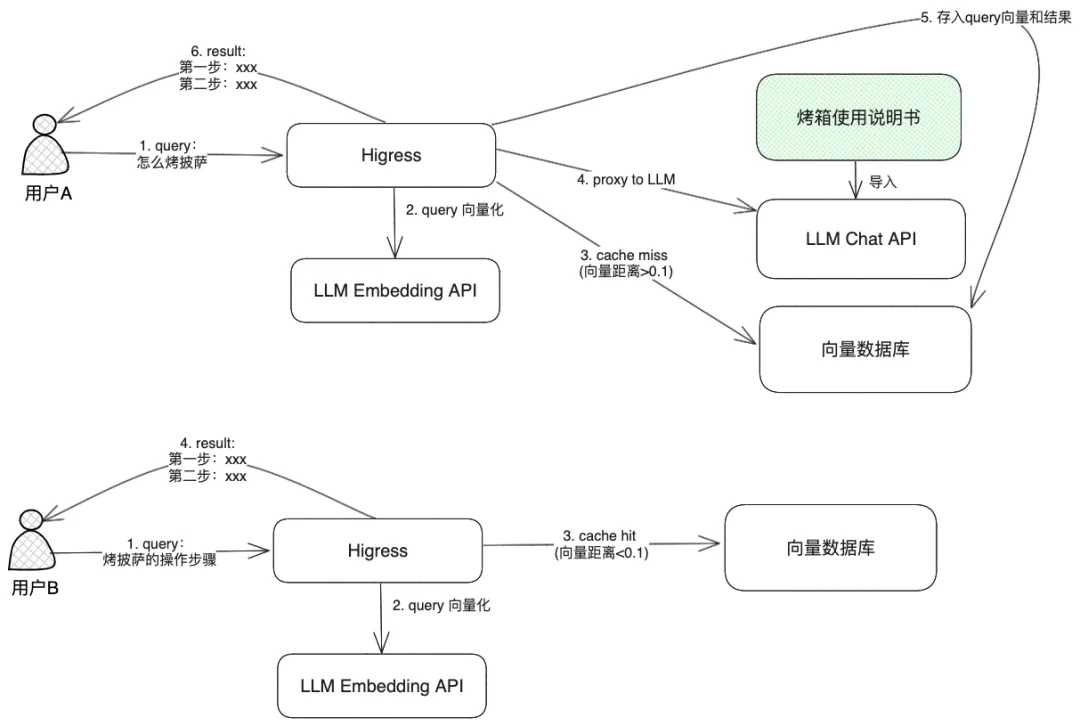
缓存优化思路
需要有较高的缓存命中率,命中缓存后,可以不用向 LLM API 发送请求,下面列举几种情况:
情况一:单轮缓存
以下面的 case 为例,第二个请求应该使用第一个请求 LLM 返回的结果,而不应该再去请求 LLM API:
-
case 1
- 什么是 Higress
- 介绍一下 Higress
-
case 2
- Wasm 插件是怎么实现的
- Wasm 插件的实现原理
-
case 3
- 可以动态修改 Higress 的 Wasm 插件逻辑,不影响网关流量吗
- Higress 的 Wasm 插件逻辑支持热更新吗
情况二:多轮缓存
以下面的 case 举例,第一组多轮对话的 A1 可以用于第二组多轮对话的 A2,第一组多轮对话的 A2 可以用于第二组多轮对话的 A1:
-
第一组对话
- Q1: Higress 可以替换 Nginx Ingress 吗?
- A1: xxxxxx
- Q2: Spring Cloud Gateway 呢?
- A2: xxxxxx
-
第二组对话
- Q1: Higress 可以替换 Spring Cloud Gateway 吗?
- A1: xxxxxx
- Q2: Nginx Ingress 呢?
- A2: xxxxxx
结果准确率要求
对于不应该命中缓存的请求,不应该返回缓存中的结果,而应该去请求 LLM API 返回结果,下面列举几种情况:
情况一:两个问题相似度低
以下面的 case 举例,第二个请求不应该返回第一个请求的结果:
-
case 1
a. 什么是 Higress
b. 给我一些 Higress 用户的落地案例
-
case 2
a. Wasm 插件是怎么实现的
b. Higress 有多少个 WASM 插件
情况二:不正确的多轮缓存
以下面的 case 举例,第一组多轮对话最后的结果,不能用于第二组多轮对话的结果:
-
第一组对话
- Q1: 可以动态修改 Higress 的 Wasm 插件逻辑吗?
- A1: xxxxxx
- Q2: 怎么操作呢?
- A2: xxxxxx
-
第二组对话
- Q1: 可以动态修改 Higress 的路由配置吗?
- A1: xxxxxx
- Q2: 怎么操作呢?
- A2: xxxxxx
情况三:避免返回无关内容
仍然以基于 Higress 内容的 RAG 场景为例,下面的问题应该统一返回“抱歉,我无法回复此问题”,例如:
- 你叫什么名字
- 今天天气怎么样
更多信息可参考《如何从网关层降低 AI 的调用成本》。
[1]《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》
https://arxiv.org/abs/2005.11401v4
[2] Higress 的编程挑战赛
https://tianchi.aliyun.com/competition/entrance/532192/information