我是在24年的五月份开始使用DeepSeek, 当时最吸引我的地方是: 1M Token 1 元
我们只讨论一件事情: 作为开发者/重度使用者 我们需要什么样的基座大模型?
性价比当然是我作为开发者最关注的事情, 成本是非常敏感的问题, 甚至可以说是除了产品方向之外最重要的事情.
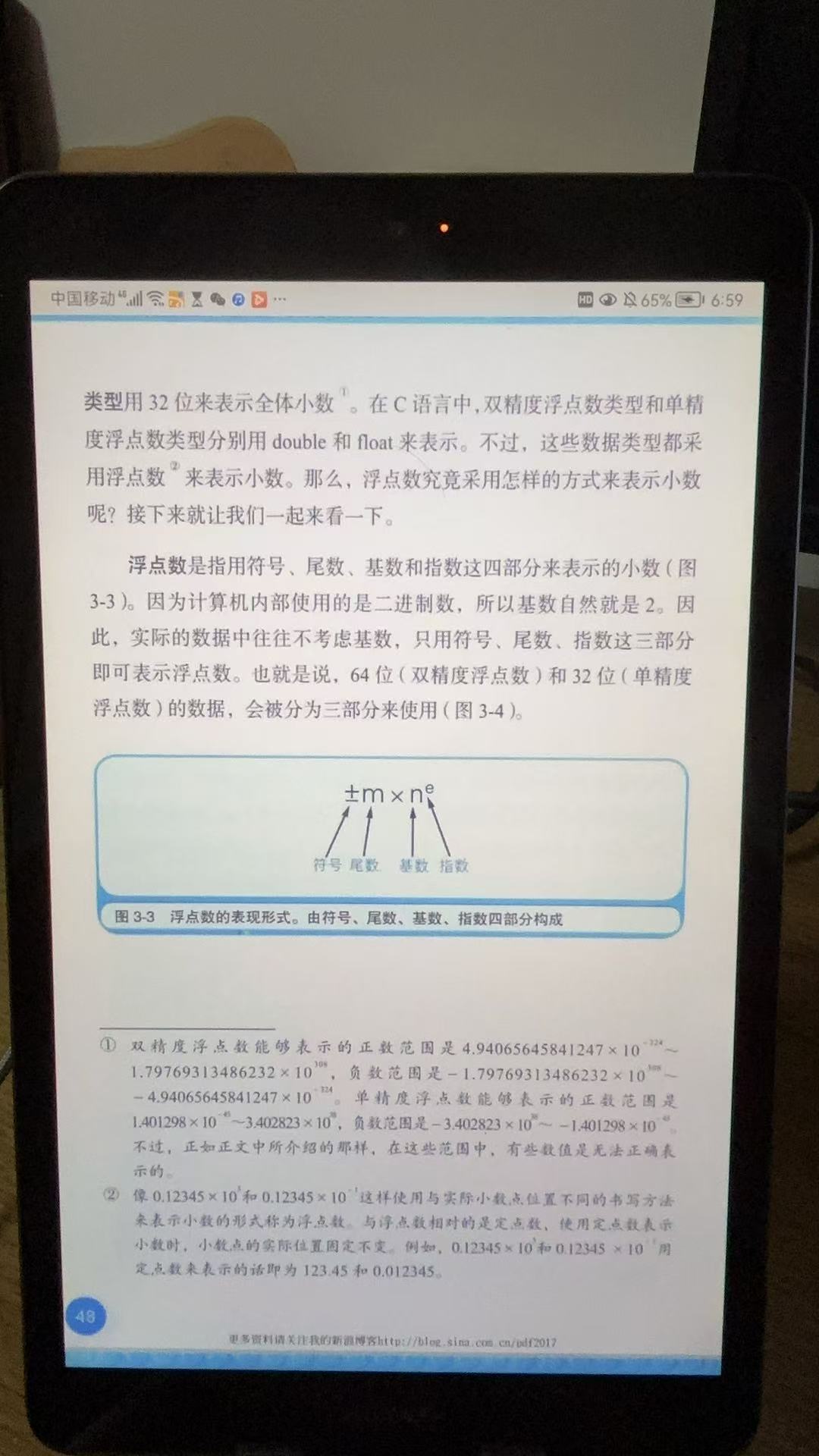
当时在讨论性价比之前我们要讨论什么是性能, 也就是说大模型的性能体现是什么?
笔者认为对于开发者来说, 重要性从高到底分别是:
- 生成质量: 创造性, 可靠性, 事实一致性, 指令遵从能力
- 上下文窗口, 知识新鲜度, 多模态能力
- Context Cache, 推理速度, 并发度, 微调支持, 多语言, function-call, json-output
除此之外, 我们可以用其他的工程方法来进行某些方面的补充:
- RAG, Web-Search: 增强事实依据/知识新鲜度/领域知识
- Workflow: 补充多模态, 增强生成质量
但是我们要注意到, 这些工程方法都是有代价的:
- 塞入更多的上下文会带来更慢的推理速度, 更高的价格
- 多个模型协作看起来很美好, 但是太慢了, 5S就是用户能够接受的极限.
为什么是DeepSeek-R1?
根本原因是推理模型带来了极佳的生成质量, 这种生成质量相较于之前的大模型直接生成有着直接的提高.
在此之前, CoT并不是什么秘密, 但是CoT太局限了, 对于某些特定领域效果很好, 但是很难辐射到所有领域.
这部分我们不妨来看看SillyTarven的最玩家都在干嘛来提升模型的效果? 手动设计细致的CoT来增加生成长度, 借此来获取更好的生成效果.
但是推理模型天生就带着一套90分的CoT, 再加上DeepSeek-V3本就十分出色的基座模型. 效果自然十分出色.
另外: 价格. 太便宜了, 这个价格仅仅是o1的零头.
Open Source
我们必须要说从DeepSeek-V1 -> DeepSeek-R1, DeepSeek一直走在开源的前沿, 但是在这里还有额外提Qwen, 我认为Qwen/DeepSeek/llama是现在这个时间点的开源三雄.
顶尖开源模型的性能能够追赶上闭源模型
这件事情的影响要比现在想象的要更大, 这意味着云服务商/推理服务提供商迎来了一个绝好的机会, 也就是占据模型推理的市场, 在此之前这部分一直被OpenAI/Claude占据着, 现在有机会吃掉一部分市场, 而不是再做代理. 这对有着强推理技术的厂商, 大优!
后续的云厂商大概率会为开源模型提供一条特殊通路, 也就是现在的硅基流动的商业模式. 这对于开发者是极大的利好.
训练成本
DeepSeekV3的训练成本控制非常出色, 论文中写是5.60M美元的成本.
这意味着: 大模型训练可能不是只有无限资金流的玩家才能烧的起.
我认为这对于提振整个行业的技术信心是极好的!
而且, 相较于Llama的高成本, DeepSeek的开源对于拓展开源世界的边界也有大好处.
这件事情的影响会在2025年越来越显现出来.
那些要死去的
我认为现在的AI六小龙都不会好过
产品没有想象力, 基座模型的研发又不能称之为顶尖, 成本控制又不够极致
三者折合下来, 我认为他们必须加快转型的速度. DeepSeek实际上是为他们开启了倒计时.
- 推出有想象力的产品
- 拿出顶尖生成质量的模型
- 出色的成本控制
这三者必须满足其二, 我认为才有机会. 我不认为靠融资能够再活3年.
闭源市场是一个赢家通吃的市场: 即最优秀的模型会吃掉最大的蛋糕.
开源市场会迎来云厂商的黄金时代: 即出色的模型能力和价格可以兼得
那么, 那些模型能力出色, 但是价格昂贵的模型们呢?
会死掉, 而且是悄无声息的死掉.
30年的互联网只证明一年事情: 赢得用户 或者 帮助用户赢得用户
前者是直接面向用户, 后者指代的事面向用户的产品开发部门.
靠B端, G端, 可以活着, 但是那意味着彻底失去想象力
总结
- 开源模型会迎来黄金时期, 希望如此, 希望如此
- 闭源模型必须推出领先一个等级的新模型, 而且必须要有一定的价格控制
- Infra as Service会成为非常重要的补充模式
- 模型能力与模型价格兼备的选项会越来越多, 绝对利好开发者, 利好应用侧发力