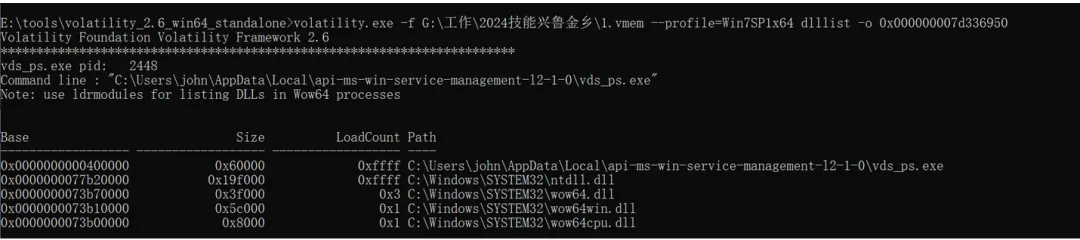
新年还没过,推理大模型就开始了卷了,除夕当天Qwen就发布了重磅的Qwen2.5 Max推理模型,
一、Qwen2.5 Max
2025年1月28日,qwen团队发布了Qwen2.5 Max,总体来说,还是很不错的。下面是摘抄他们发表的信息:

We evaluate Qwen2.5-Max alongside leading models, whether proprietary or open-weight, across a range of benchmarks that are of significant interest to the community. These include MMLU-Pro, which tests knowledge through college-level problems, LiveCodeBench, which assesses coding capabilities, LiveBench, which comprehensively tests the general capabilities, and Arena-Hard, which approximates human preferences. Our findings include the performance scores for both base models and instruct models.
我们在社区引起的一系列基准中评估了QWEN2.5-MAX以及主要模型,无论是专有还是开放权重。其中包括MMLU-PRO,它通过大学级别的问题来测试知识,LiveCodebench评估了编码功能,LiveBench,它全面测试了一般能力和竞技场,近似人类的偏好。我们的发现包括基本模型和指导模型的性能得分。
We begin by directly comparing the performance of the instruct models, which can serve for downstream applications such as chat and coding. We present the performance results of Qwen2.5-Max alongside leading state-of-the-art models, including DeepSeek V3, GPT-4o, and Claude-3.5-Sonnet.
我们首先直接比较指令模型的性能,该模型可以用于下游应用程序,例如聊天和编码。我们介绍了QWEN2.5-MAX的性能结果以及领先的最先进模型,包括DeepSeek V3,GPT-4O和Claude-3.5-Sonnet。


来源:
QWEN2.5-MAX:探索大型Moe模型的智能| QWEN --- Qwen2.5-Max: Exploring the Intelligence of Large-scale MoE Model | Qwen
二、使用体验
经过几天的使用体验,发现在速度上和代码能力上都是很强的,不过没有给推理过程,但是也不影响他的强大。接下来讲一下他的使用体验。
1、功能模块
现在可用的就是Artifacts(编程预览)、ImageGeneration(图像生成),在开发的web Search(联网搜索)和Video Generation(视频生成)。

2、Qwen2.5 Max测试
(1)推理对比(DeepSeek R1)
问题一:你认为人类历史上最伟大的四个字是什么?只需要答案不需要解释
Qwen2.5 Max的回答:

DeepSeek R1的回答:

这两个回答,我更喜欢DeepSeek的,更加贴近中国的思想,Qwen就更加普适化,怎么说都没错的感觉了。
问题二:你认为人类历史上最伟大的四个字是什么?只需要答案不需要解释


这样看来,DeepSeek更像文科,Qwen更像理科的思维
问题三:整理并使用知识图谱分析从中学到大学的数学变化和学习逻辑
Qwen回答的挺理科生的,分点答,而且制作的知识图谱也还可以,还给出一个启示,思考的还是挺面面俱到的



对比DeepSeek反而只输出了知识图谱,格式还是一般般:

看了一下,原来是思考的过程被上下文影响了,这也反映了它还是很强的上下文关联能力

我们新开一个对话,看看,这次使用的词语更加专业化了,分析的都很学术化,而且都能够整理抽取出来核心内容,还是挺像一个学术型的人一样。



问题4:川普当选总统,你用一个四川的口吻写一封英语的祝贺信给他,顺便翻译一下给我看
Qwen还是一如既往的一步一个脚印,按部就班的写出来,不过还是挺有趣的,属于优秀的水平。


我们看看DeepSeek,首先还是思考还是挺正常的流程,但是看看答案不过对比起来Qwen,更有趣,更搞笑。


总结:综合起来看,Qwen更像一个优秀的孩子,水平一直都不错,是隔壁家的孩子,而DeepSeek更像一个活泼的优秀孩子,有点调皮。
(2)编程测试
其实我之前用DeepSeek进行开发过,虽然给出了结果,但是每次添加的需求,好像会把以前的串联起来,最后的代码有点怪。直接来看Qwen吧,就是最近需要做一个抽签系统,首先我把需求给它:
1、第一轮,给出的答案是网页的代码是分开的

2、第二轮,我叫他整合为一个文件,直接输出,没有半点思考

效果如下:

导入的姓名是让Qwen生成100个,它给我111个,是不是想要点赞啊。

3、第三轮第四轮都是优化代码,而且这次上下文关联的很强,都是在当前代码上修改,不会出现变成一个新的页面


下面是最后抽奖的效果对比,左边是第一版,右边是最终版:


虽然是还有点小问题,但是问题不大。
总结:Qwen2.5 Max在测试的网页上可用性非常强,展示了一个程序员的应有素质。
3、图片生成
图片生成对中文不太友好,没有通义和豆包生成的中文字准确,而且把少年闰土化成欧美风,我发现其他的也是欧美风,估计在训练的时候使用的是国外的数据集。


4、最后想说的
Qwen这次发布的Qwen2.5 Max是非常棒的,能够做到很多事情都是能够独立思考,就像前面连续问了无关的题目,再问整理数学知识的,会按照自己的想法进行,但是DeepSeek会有点关联去思考,但是独立来问的话,丰富性还是DeepSeek R1的好。另外他的编程还是很放心的,能够把需求做到有求必应,还能做到在原有的基础上改进,是很强的表现了,甚至比Cursor的好。如果DeepSeek R1还是网络繁忙,我会主要使用Qwen2.5 Max,后续他还会出联网搜索和视频生成,不过生图这些功能会考虑成熟的像豆包通义这些。