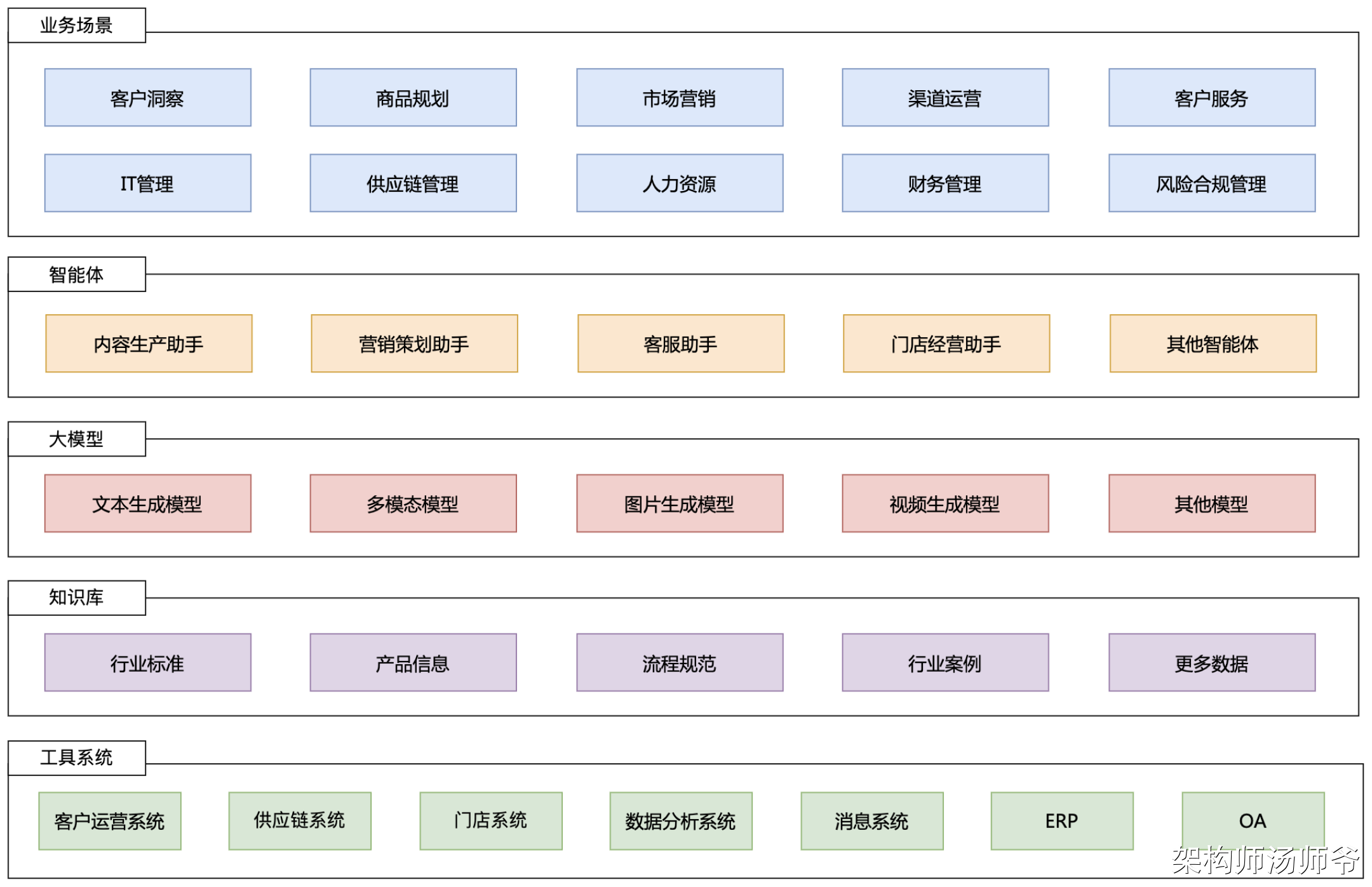
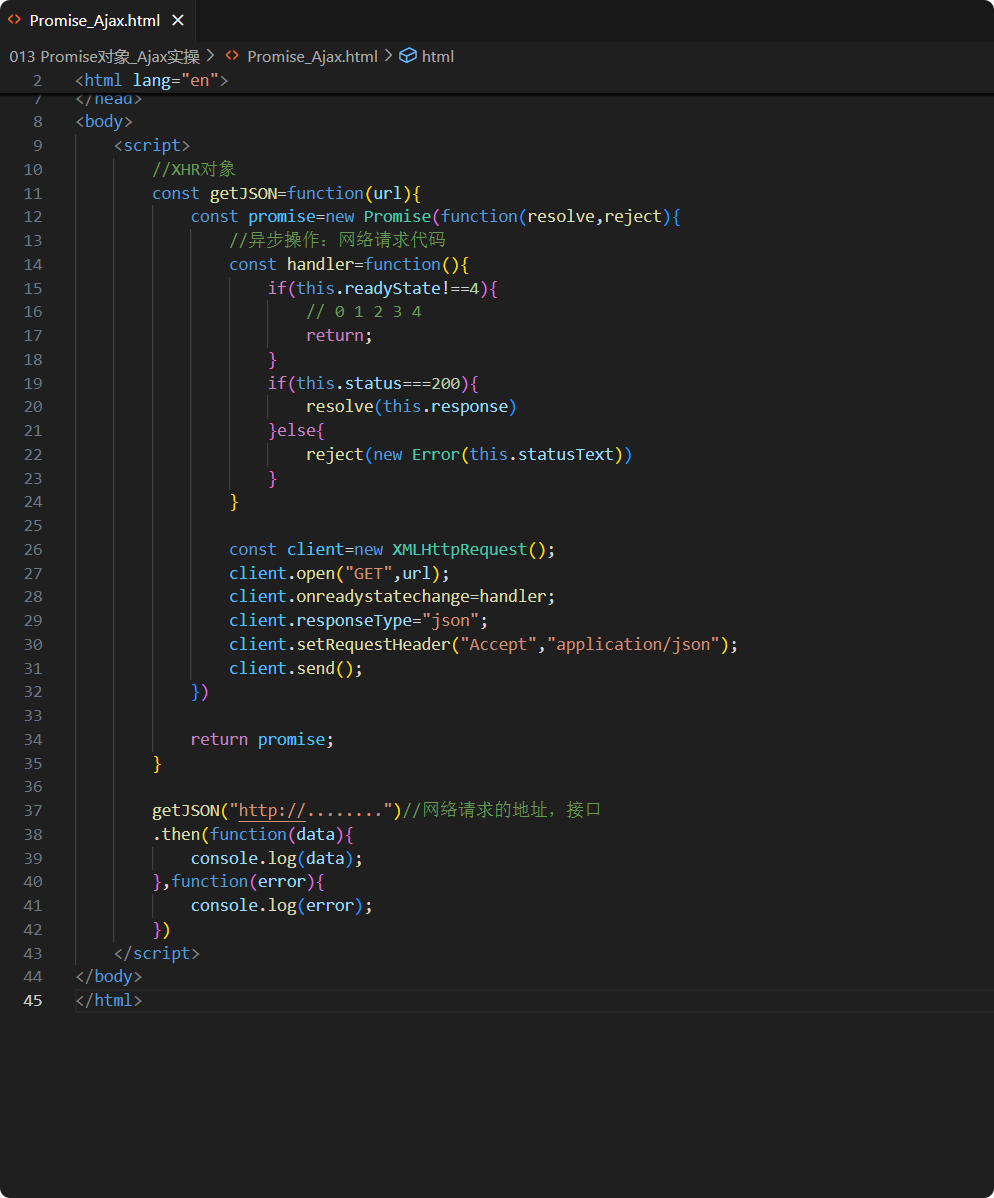
一、跳表原理
1.1、什么是跳表
跳跃表是一种随机化的数据结构,在查找、插入和删除这些字典操作上,其效率可比拟于平衡二叉树(如红黑树),大多数操作只需要O(log n)平均时间,但它的代码以及原理更简单。跳跃表的定义如下:
“Skip lists are data structures that use probabilistic balancing rather than strictly enforced balancing. As a result, the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.”
译文:跳跃表使用概率平衡,而不是强制平衡,因此,对于插入和删除结点比传统上的平衡树算法更为简洁高效。
1.2、理想跳表
在理想情况下:
- 最底层元素是一个单链表
- 从最底层往上,每一层的元素个数是之前一层的1/2
二、跳表redis实现
Base:redis version: 5.0.8
2.1、redis跳表原理和数据结构

2.2、Redis跳表代码
2.2.1、Redis跳表数据结构
#跳表节点
typedef struct zskiplistNode {sds ele;double score;struct zskiplistNode *backward;#跳表表示level的数据struct zskiplistLevel {struct zskiplistNode *forward;unsigned long span;} level[];
} zskiplistNode;#跳表 list结构
typedef struct zskiplist {struct zskiplistNode *header, *tail;unsigned long length;int level;
} zskiplist;#zset 结构
typedef struct zset {dict *dict;zskiplist *zsl;
} zset;
2.2.2、跳表执行流程
#zset 添加/更新操作入口
int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore) {/* Turn options into simple to check vars. */int incr = (*flags & ZADD_INCR) != 0;int nx = (*flags & ZADD_NX) != 0;int xx = (*flags & ZADD_XX) != 0;*flags = 0; /* We'll return our response flags. */double curscore;/* NaN as input is an error regardless of all the other parameters. */if (isnan(score)) {*flags = ZADD_NAN;return 0;}/* Update the sorted set according to its encoding. */if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {unsigned char *eptr;if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {/* NX? Return, same element already exists. */if (nx) {*flags |= ZADD_NOP;return 1;}/* Prepare the score for the increment if needed. */if (incr) {score += curscore;if (isnan(score)) {*flags |= ZADD_NAN;return 0;}if (newscore) *newscore = score;}/* Remove and re-insert when score changed. */if (score != curscore) {zobj->ptr = zzlDelete(zobj->ptr,eptr);zobj->ptr = zzlInsert(zobj->ptr,ele,score);*flags |= ZADD_UPDATED;}return 1;} else if (!xx) {/* Optimize: check if the element is too large or the list* becomes too long *before* executing zzlInsert. */zobj->ptr = zzlInsert(zobj->ptr,ele,score);if (zzlLength(zobj->ptr) > server.zset_max_ziplist_entries ||sdslen(ele) > server.zset_max_ziplist_value)zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);if (newscore) *newscore = score;*flags |= ZADD_ADDED;return 1;} else {*flags |= ZADD_NOP;return 1;}} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {#当前zset编码是 skipListzset *zs = zobj->ptr;zskiplistNode *znode;dictEntry *de;#根据 ele从dict中获取元素,如果获取到直接更新该节点value,如果获取不到就插入de = dictFind(zs->dict,ele);if (de != NULL) {/* NX? Return, same element already exists. */if (nx) {*flags |= ZADD_NOP;return 1;}curscore = *(double*)dictGetVal(de);/* Prepare the score for the increment if needed. */if (incr) {score += curscore;if (isnan(score)) {*flags |= ZADD_NAN;return 0;}if (newscore) *newscore = score;}/* Remove and re-insert when score changes. */if (score != curscore) {//更新znode节点znode = zslUpdateScore(zs->zsl,curscore,ele,score);/* Note that we did not removed the original element from* the hash table representing the sorted set, so we just* update the score. */dictGetVal(de) = &znode->score; /* Update score ptr. */*flags |= ZADD_UPDATED;}return 1;} else if (!xx) {ele = sdsdup(ele);//插入新的节点znode = zslInsert(zs->zsl,score,ele);serverAssert(dictAdd(zs->dict,ele,&znode->score) == DICT_OK);*flags |= ZADD_ADDED;if (newscore) *newscore = score;return 1;} else {*flags |= ZADD_NOP;return 1;}} else {serverPanic("Unknown sorted set encoding");}return 0; /* Never reached. */
}
插入新的节点流程
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;unsigned int rank[ZSKIPLIST_MAXLEVEL];int i, level;serverAssert(!isnan(score));#初始化遍历初始值#rank 数组收集每层level从header到小于score的最后一个节点的span值#update 数组收集每层level 小于score的最后一个节点x = zsl->header;for (i = zsl->level-1; i >= 0; i--) {/* store rank that is crossed to reach the insert position */#rank[level-]的初始值为0 ,是因为 当前是计算的第一个元素,需要从header.level[i]中取出来rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];while (x->level[i].forward &&(x->level[i].forward->score < score ||(x->level[i].forward->score == score &&sdscmp(x->level[i].forward->ele,ele) < 0))){rank[i] += x->level[i].span;x = x->level[i].forward;}update[i] = x;}/* we assume the element is not already inside, since we allow duplicated* scores, reinserting the same element should never happen since the* caller of zslInsert() should test in the hash table if the element is* already inside or not. */#生成当前新节点的level值,如果当前值大于当前list的level值,需要初始化[当前level,level)之间的level元素level = zslRandomLevel();if (level > zsl->level) {for (i = zsl->level; i < level; i++) {rank[i] = 0;update[i] = zsl->header;update[i]->level[i].span = zsl->length;}zsl->level = level;}#构造新节点的元素x = zslCreateNode(level,score,ele);//从下到上,修改每层小雨score的最后一个元素 ,与当前元素level[i]的链接关系以及span数值for (i = 0; i < level; i++) {x->level[i].forward = update[i]->level[i].forward;update[i]->level[i].forward = x;/* update span covered by update[i] as x is inserted here */x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);update[i]->level[i].span = (rank[0] - rank[i]) + 1;}/* increment span for untouched levels */#修改每一层小于score的最后一个元素的span值,在这里再执行一次是因为当前节点的level如果小于list的level,则大于当前节点level到list level之间的level的span值还没有被处理,而这些数值只是单纯的增加1for (i = level; i < zsl->level; i++) {update[i]->level[i].span++;}#修改向后遍历指针x->backward = (update[0] == zsl->header) ? NULL : update[0];if (x->level[0].forward)x->level[0].forward->backward = x;elsezsl->tail = x;#修改当前list 元素个数zsl->length++;return x;
}
跳表level函数:
#define ZSKIPLIST_P 0.25
#define ZSKIPLIST_MAXLEVEL 64 /* Should be enough for 2^64 elements */
int zslRandomLevel(void) {int level = 1;while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))level += 1;return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
redis中规定,level最多只能有64层
三、跳表java实现
3.1、数据结构
java实现时去掉了dict结构,主要演示node的插入
@Data
public class ZSkipListNode {private String ele;private double score;private ZSkipListNode backward;private ZSkipListLevel[] level;public ZSkipListNode(String ele, double score) {this.ele = ele;this.score = score;this.level = new ZSkipListLevel[ZSkipList.MAX_LEVEL];for(int j = 0;j< ZSkipList.MAX_LEVEL;j++){level[j] = new ZSkipListLevel();}}@Overridepublic String toString() {return "ZSkipListNode{}";}
}@Data
public class ZSkipListLevel {private ZSkipListNode forword;private long span;@Overridepublic String toString() {return "ZSkipListLevel{}";}
}@Data
public class ZSkipList {public static final int MAX_LEVEL = 32;public static final double LEVEL_FACTOR = 0.25;private ZSkipListNode header;private ZSkipListNode tail;private long length;private int level;public ZSkipList() {this.level = 1;this.length = 0;this.header = new ZSkipListNode(null,0);for(int j = 0;j<MAX_LEVEL;j++){this.getHeader().getLevel()[j].setForword(null);this.getHeader().getLevel()[j].setSpan(0);}this.getHeader().setBackward(null);this.setTail(null);}}
3.2、insert和delete方法实现
@Data
public class ZSkipList {public static final int MAX_LEVEL = 32;public static final double LEVEL_FACTOR = 0.25;private ZSkipListNode header;private ZSkipListNode tail;private long length;private int level;public ZSkipList() {this.level = 1;this.length = 0;this.header = new ZSkipListNode(null,0);for(int j = 0;j<MAX_LEVEL;j++){this.getHeader().getLevel()[j].setForword(null);this.getHeader().getLevel()[j].setSpan(0);}this.getHeader().setBackward(null);this.setTail(null);}public ZSkipListNode insert(double score, String ele) {long[] rank = new long[MAX_LEVEL];ZSkipListNode[] update = new ZSkipListNode[MAX_LEVEL];ZSkipListNode h = this.getHeader();for(int i=getLevel()-1;i>=0;i--){rank[i] = i == getLevel()-1 ? 0 : rank[i+1];while (h.getLevel()[i].getForword()!=null&& (h.getLevel()[i].getForword().getScore()<score|| (h.getLevel()[i].getForword().getScore() == score && valCmp(h.getLevel()[i].getForword().getEle(),ele)<0))){rank[i]+= h.getLevel()[i].getSpan();h = h.getLevel()[i].getForword();}update[i] = h;}int level = zslRandomLevel();if(level>getLevel()){for(int l = getLevel();l<level;l++){update[l] = getHeader();update[l].getLevel()[l].setSpan(getLength());rank[l]= 0;}}ZSkipListNode cur = new ZSkipListNode(ele,score);for(int i = 0;i<level;i++){cur.getLevel()[i].setForword(update[i].getLevel()[i].getForword());update[i].getLevel()[i].setForword(cur);cur.getLevel()[i].setSpan(update[i].getLevel()[i].getSpan()-(rank[0]-rank[i]));update[i].getLevel()[i].setSpan(rank[0]-rank[i]+1);}for (int i = level;i<this.getLevel()-1; i++){update[i].getLevel()[i].setSpan(update[i].getLevel()[i].getSpan()+1);}cur.setBackward(update[0] == getHeader() ? null : update[0]);if(cur.getLevel()[0].getForword()!=null){cur.getLevel()[0].getForword().setBackward(cur);}else {this.setTail(cur);}if(level>getLevel()){this.setLevel(level);}this.setLength(this.getLength()+1);return cur;}/*** 删除成功 返回1 ,删除失败,或者没有找到返回0* 删除元素* 并修改剩下的level中的 span信息* @return*/public int delete(ZSkipListNode node,ZSkipListNode[] update){for(int i=0;i<getLevel();i++){ZSkipListLevel level =update[i].getLevel()[i];if(level.getForword() == node){level.setSpan(level.getSpan()+node.getLevel()[i].getSpan()-1);level.setForword(node.getLevel()[i].getForword());}else {level.setSpan(level.getSpan()-1);}}/*** 修改返回指针*/if(node.getLevel()[0].getForword()==null){this.setTail(node.getBackward());}else {node.getLevel()[0].getForword().setBackward(node.getBackward());}/*** 修改level*/while (getLevel()>0 && getHeader().getLevel()[getLevel()-1].getForword()==null){setLevel(getLevel()-1);}setLength(getLength()-1);return 1;}/*** int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node)* @param score* @param ele* @return*/public int deleteWithScore(double score,String ele){ZSkipListNode[] update = new ZSkipListNode[MAX_LEVEL];ZSkipListNode h = getHeader();ZSkipListNode x = null;for(int i= getLevel()-1;i>=0;i--){while (h.getLevel()[i].getForword() != null&& (h.getLevel()[i].getForword().getScore() < score|| (h.getLevel()[i].getForword().getScore() == score && valCmp(h.getLevel()[i].getForword().getEle(), ele) < 0))) {h = h.getLevel()[i].getForword();}update[i]=h;}x = h.getLevel()[0].getForword();if(x!=null && x.getScore() == score && valCmp(x.getEle(),ele) == 0){return delete(x,update);}return 0;}private int zslRandomLevel() {int level = 1;Random random = new Random();while(random.nextInt(20)<20*LEVEL_FACTOR){level+=1;}return level<MAX_LEVEL ? level : MAX_LEVEL;}public int valCmp(String t, String target) {return t.compareTo(target);}public static void main(String[] args) {ZSkipList list = new ZSkipList();Map<String,Integer> eleMap = new HashMap<>();Random random = new Random();int max = 0;for (int i = 0;i<10;i++){int score =1+random.nextInt(20);max +=score;String ele = "a"+i;list.insert(max,ele);eleMap.put(ele,max);}printZsl(list);/*** 删除元素测试*/for (Map.Entry<String,Integer> entry : eleMap.entrySet()){list.deleteWithScore(entry.getValue(),entry.getKey());System.out.printf("delete,ele:"+entry.getKey()+",score:"+entry.getValue());printZsl(list);}}public static void printZsl(ZSkipList list){ZSkipListNode header = list.getHeader();System.out.println("---------------------------------------");for(int i = list.getLevel()-1;i>=0;i--){System.out.println("level = "+i);ZSkipListNode h = header.getLevel()[i].getForword();while (h!=null){System.out.printf("[node:"+h.getEle()+":"+h.getScore()+",span:"+h.getLevel()[i].getSpan()+"]-");h = h.getLevel()[i].getForword();}System.out.println();}System.out.println("---------------------------------------");}@Overridepublic String toString() {return "ZSkipList{";}
}