一、什么是进程
进程(Process)是正在运行的程序,是操作系统进行资源分配的基本单位。程序是存储在硬盘或内存的一段二进制序列,是静态的,而进程是动态的。每个进程都由自己的地址空间、代码段、数据段以及分配给它的其它系统资源(如文件描述符、网络连接等)。
二、创建子进程
在 Linux 中,我们可以使用 system() 函数执行 Shell 指令的函数。
/*** @brief 使用标准库函数system()执行Linux的命令* * @param __command 就是要执行的Linux命令* @return int 运行成功返回0,失败则返回错误编号*/
int system(const char *__command);
在 Linux 中,我们可以使用 fork() 函数创建一个子线程。使用 fork() 函数创建子进程时,会将父进程的资源原原本本复制一份给子进程。
/*** @brief 创建一个子进程* * @return __pid_t 在父进程中返回的是创建的子进程的进程ID,在子进程中返回的是0*/
__pid_t fork(void);
该函数返回一个 __pid_t 类型的进程 ID,它进程 ID 其实是一个 int 类型的值。
#define __STD_TYPE typedef
#define __PID_T_TYPE __S32_TYPE
#define __S32_TYPE int
__STD_TYPE __PID_T_TYPE __pid_t; /* Type of process identifications. */
typedef __pid_t pid_t;
创建一个子进程之后,我们可以使用 getpid() 函数来获取该子进程的进程 ID。
/*** @brief 获取进程的进程ID* * @return __pid_t 进程的进程ID,错误返回-1*/
__pid_t getpid(void);
我们还可以通过 getppid() 函数来获取其父进程的进程 ID。
/*** @brief 获取其父进程的进程ID* * @return __pid_t 父进程的进程ID*/
__pid_t getppid(void);
这里,我们新建一个 main.c 文件。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>int main(void)
{// 调用fork()函数之前,代码都在父进程中运行printf("parent process (%d) is executing.\n", getpid());// 使用fork()函数创建子进程// 该函数在父进程中返回的是创建的子进程的进程ID,在子进程中返回的是0pid_t pid = fork();// 从fork()函数之后,所有的代码都是在父子进程中各自执行一次printf("%d\n", pid);if (pid < 0){printf("child process creation failed!\n");return -1;}else if (pid == 0){// 这里的代码是在子进程中执行的printf("child process (%d) is executing, and its parent process ID is %d\n", getpid(), getppid());}else{// 这里的代码是在父进程中执行的printf("parent process (%d) is executing, and it created a child process with ID %d\n", getpid(), pid);}return 0;
}
新建一个 Makefile 文件,它的内容如下:
CC := gcc# $@ 表示目标文件名称 $^ 表示所有的依赖文件
main: main.o- ${CC} $^ -o $@- rm ./$^- ./$@
在终端中输入 make 运行。
make
三、进程树
在终端中,我们可以输出 pstree -p 命令查看进程数。
pstree -p
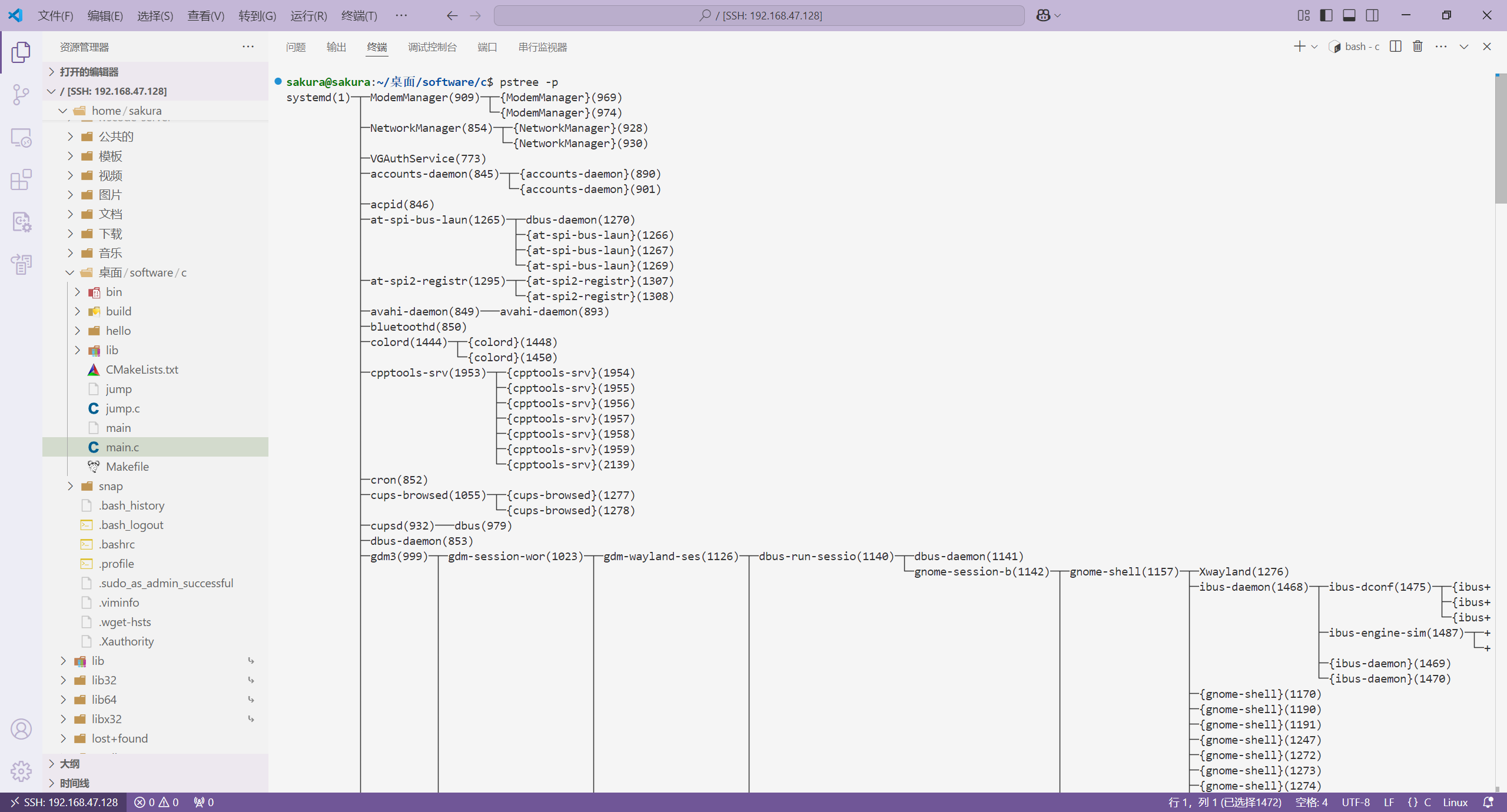
通过查看进程树,我们可以发现,所有的进程的祖先都是 1 号进程(systmd)。systmd 进程它是由内核创建的,负责初始化系统,启动其它所有用户空间的服务和进程。
如果我们在终端中输入 ps -ef 命令查看,我们可以发现有些行带有 [],有些没有。这是因为带有 [] 是 内核线程,内核线程在内核空间执行,不占用任何用户空间资源,它们在技术上是线程,而在许多独立方面表现的像进程,因此也会被 ps 命令检索到。第一个内核线程的 pid 为 2,它是所有其它内核线程的祖先。
四、程序的跳转
fork() 函数是用于创建一个子进程,该子进程几乎是父进程的副本,而有时我们希望子进程去执行另外的程序,exec 函数族就提供了一个在进程中启动另一个程序执行的方法。它可以根据指定的文件名或目录名找到可执行文件,并用它来取代原调用进程的数据段、代码段和堆栈段,在执行完之后,原调用进程的内容除了进程号外,其他全部被新程序的内容替换了。另外,这里的可执行文件既可以是二进制文件,也可以是 Linux 下任何可执行脚本文件。execv() 根据指定的文件名或目录名找到可执行文件,并用它来代替当前进程的执行映像。也就是说,exec 调用并没有生成新进程,一个进程一旦调用 exec 函数,它本身就 “死亡” 了,系统把代码段替换成新程序的代码,放弃原有的数据段和堆栈段,并为新程序分配新的数据段与堆栈段,唯一保留的就是进程的 ID。也就是说,对系统而言,还是同一个进程,不过执行的已经是另外一个程序了。
/*** @brief 程序跳转* * @param __path 执行程序的路径* @param __argv 传入的参数,对应执行程序main()函数的第二个参数* @param __envp 传递的环境变量* @return int 成功没有返回值,失败返回-1*/
int execve(const char *__path, char *const __argv[], char *const __envp[]);
该函数的第二个参数是一个字符串数组,它的第一个元素固定是程序的名称,即执行程序的路径,后面的参数是执行程序需要的参数(一般是通过命令行传入的),最后一个参数一定是 NULL,否则可能会出一些莫名其妙的错误。
该函数的第三个参数同样是一个字符串数组,它是要传递的环境变量,参数的格式为:key=value。如果我们传入的执行程序的路径是一个绝对路径的话,那我们可以不使用这个参数,传入一个 NULL 即可。
这里,我们在与 main.c 文件同级的目录下新建一个 jump.c 文件,用来存放跳转后的程序代码。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>int main(int argc, char const *argv[])
{if (argc < 2){printf("parameter number is not match!\n");return -1;}printf("jump succeeded, the process d is %d\n", getpid());printf("parent process id is %d after jump\n", getppid());printf("name is %s after jump\n", argv[1]);return 0;
}
这里,我们先使用 gcc 编译,生成跳转程序的可执行程序。
gcc jump.c -o jump
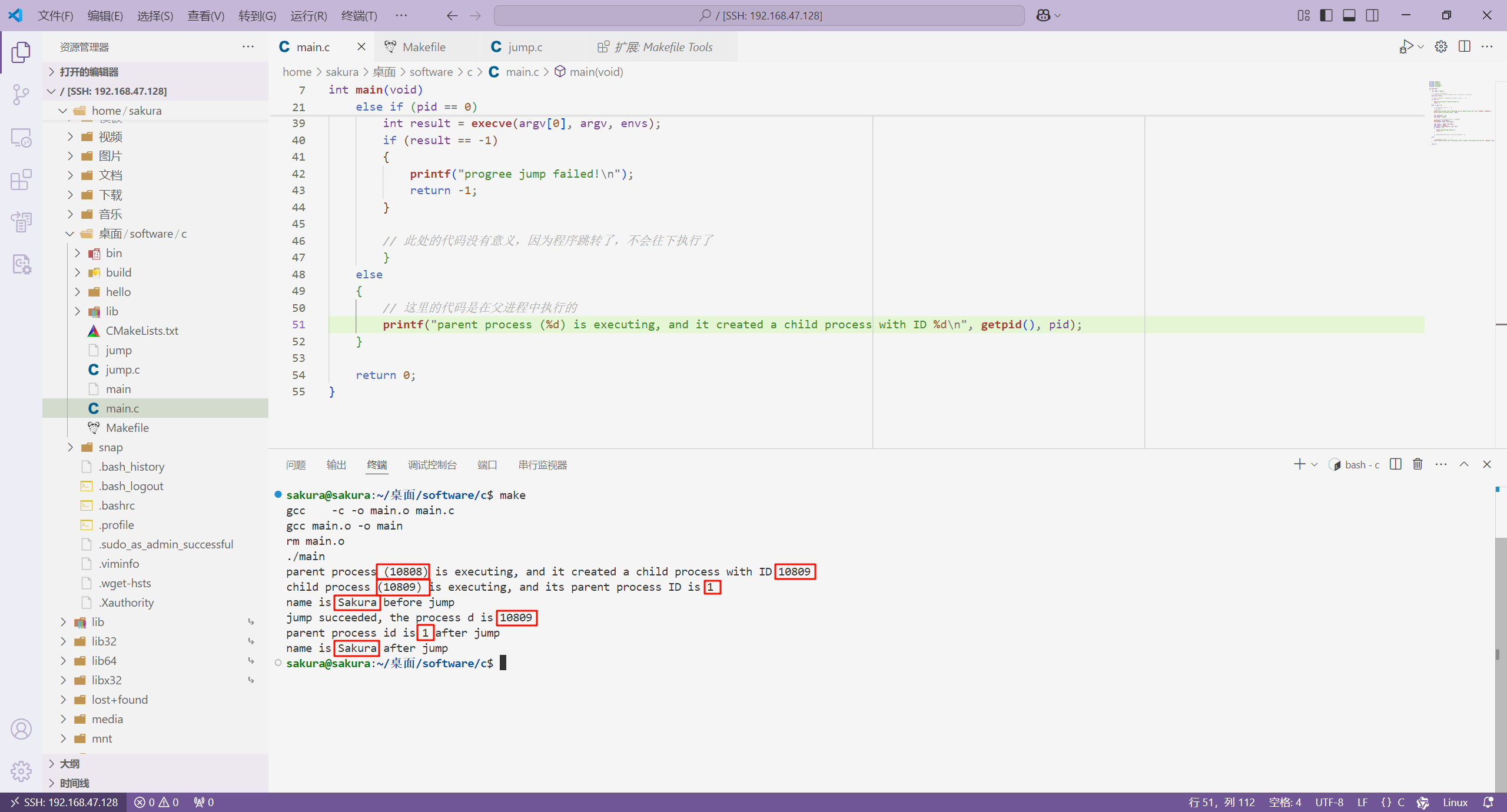
然后,我们修改 main.c 文件的内容,在 main() 函数中创建一个子进程,然后执行 execv() 函数进行跳转。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <string.h>int main(void)
{char *name = "Sakura";// 使用fork()函数创建子进程// 该函数在父进程中返回的是创建的子进程的进程ID,在子进程中返回的是0pid_t pid = fork();// 从fork()函数之后,所有的代码都是在父子进程中各自执行一次if (pid < 0){printf("child process creation failed!\n");return -1;}else if (pid == 0){// 这里的代码是在子进程中执行的// 子进程跳转前printf("child process (%d) is executing, and its parent process ID is %d\n", getpid(), getppid());printf("name is %s before jump\n", name);// 执行跳转char path[1024] = {0};char temp[] = "/jump";// 返回当前工作目录的绝对路径到一个字符数组中getcwd(path, sizeof(path));strncat(path, temp, strlen(temp));char *argv[] = {path, name, NULL};char *envs[] = {NULL};int result = execve(argv[0], argv, envs);if (result == -1){printf("progree jump failed!\n");return -1;}// 此处的代码没有意义,因为程序跳转了,不会往下执行了}else{// 这里的代码是在父进程中执行的printf("parent process (%d) is executing, and it created a child process with ID %d\n", getpid(), pid);}return 0;
}
在终端中输入 make 运行。
五、僵尸进程与孤儿进程
在 Linux 中,父进程除了可以启动子进程外,还需要负责回收子进程的状态。如果子进程结束后父进程没有正常回收,那么子进程就会编程一个 僵尸进程,即程序执行完成,但是进程没有完全结束,其内核中的 PCB 结构体没有释放。
如果父进程在结束之前没有等待子进程结束,且父进程先于子进程结束,那么子进程就会变成 孤儿进程,即父进程已经结束或终止,而它仍在运行的进程。一旦一个进程成为孤儿进程,它的父进程会重新挂载在它的祖先进程上。
在上面的例子中,父进程在子进程结束前就结束了,那么子进程的回收工作就交给了父进程的父进程的父进程(省略若干了父进程)完成。
孤儿进程会被其祖先进程自动领养。此时的子进程因为和终端切断了联系,所以很难在进行标准输入使其停止了,所以写代码的时候一定要注意避免出现孤儿进程。
在 Linux 中,我们可以使用 waitpid() 函数让父进程等待子进程运行结束。
/*** @brief 等待特定的子进程结束* * @param __pid 进程ID* @param __stat_loc 整数指针,返回子进程返回的状态码* @param __options 选项* @return __pid_t 成功等待子进程结束的进程ID*/
__pid_t waitpid(__pid_t __pid, int *__stat_loc, int __options);
在 waitpid() 函数中,如果 __pid < -1,则会等待进程组 ID 等于 gpid 的所有进程终止。如果 _pid == -1,则会等待任何子进程结束,并返回最先终止的那个子进程的进程 ID(儿孙都算)。如果 __pid == 0,则会等待同一进程组中任何子进程终止,但不包括组领导进程(只算儿子)。如果 __pid > 0,则仅等待指定进程 ID 的子进程终止。
在 waitpid() 函数中,我们还可以设置它的选项,选项的值是以下常量之一或者多个的按位或运算的结果。
WNOHANG:如果没有子进程终止,也立即返回,用于查看子进程状态而非等待。WUNTRACED:收到子进程处于收到信号停止的状态,则也会返回。WCONTINUED:如果通过发送 SIGCONT 信号恢复了一个以停止的子进程,则也会返回。
waitpid() 函数会在成功等待子进程停止时返回 pid,如果没等到并且没有设置 WUNTRACED ,则会一直等。如果没等到但设置 WUNTRACED 则会返回 0。如果出错,则返回 -1。
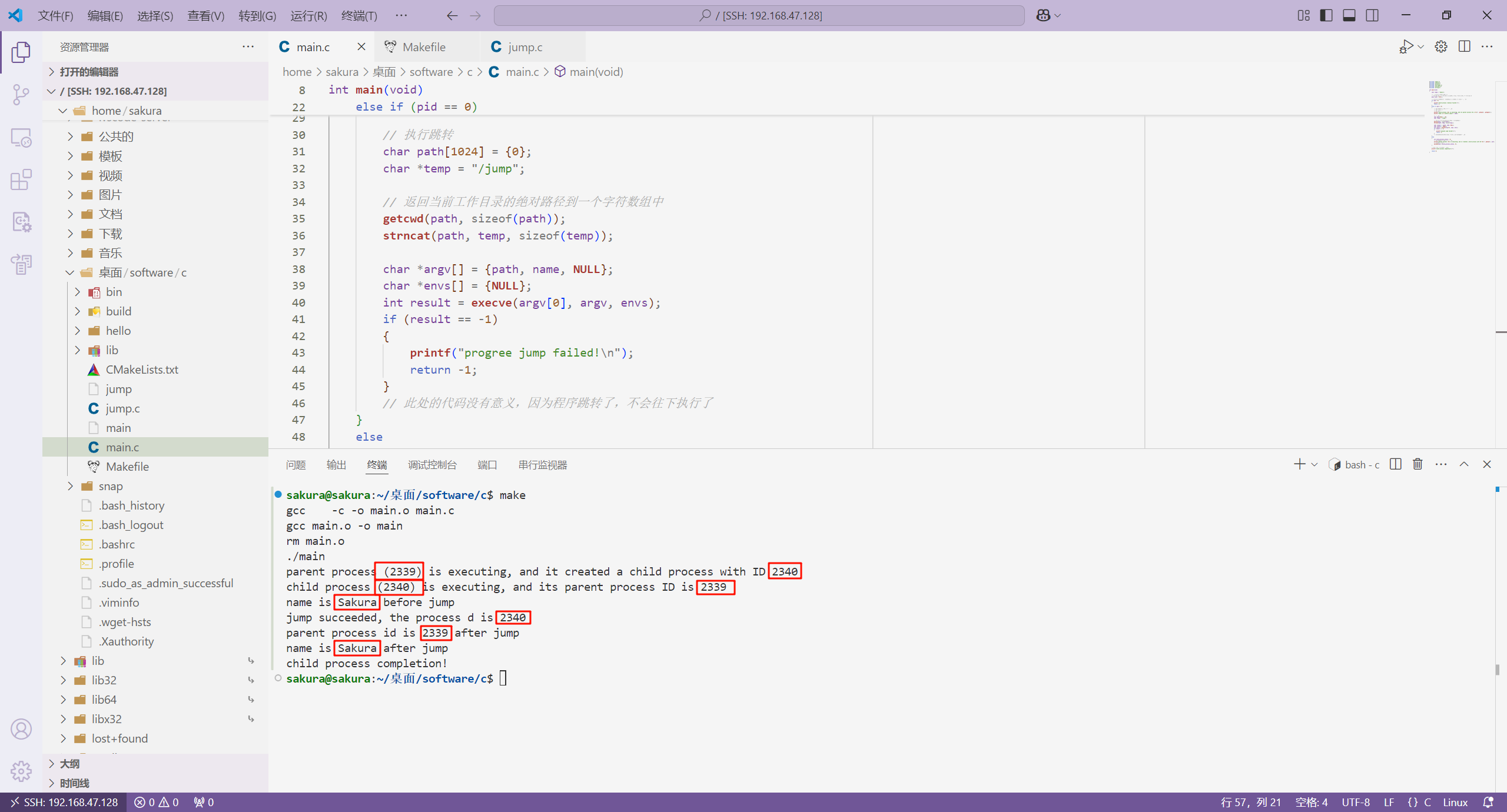
我们修改上面的 main.c 文件,在父进程中使用 waitpid() 函数等待子进程结束。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <string.h>int main(void)
{char *name = "Sakura";// 使用fork()函数创建子进程// 该函数在父进程中返回的是创建的子进程的进程ID,在子进程中返回的是0pid_t pid = fork();// 从fork()函数之后,所有的代码都是在父子进程中各自执行一次if (pid < 0){printf("child process creation failed!\n");return -1;}else if (pid == 0){// 这里的代码是在子进程中执行的// 子进程跳转前printf("child process (%d) is executing, and its parent process ID is %d\n", getpid(), getppid());printf("name is %s before jump\n", name);// 执行跳转char path[1024] = {0};char *temp = "/jump";// 返回当前工作目录的绝对路径到一个字符数组中getcwd(path, sizeof(path));strncat(path, temp, sizeof(temp));char *argv[] = {path, name, NULL};char *envs[] = {NULL};int result = execve(argv[0], argv, envs);if (result == -1){printf("progree jump failed!\n");return -1;}// 此处的代码没有意义,因为程序跳转了,不会往下执行了}else{int child_process_status = 0;// 这里的代码是在父进程中执行的printf("parent process (%d) is executing, and it created a child process with ID %d\n", getpid(), pid);// 等待子进程终止waitpid(pid, &child_process_status, 0);}// 子进程跳转完,不会执行这里printf("child process completion!\n");return 0;
}
在终端中输入 make 运行。
六、守护进程
守护线程 是在操作系统后台运行的一种特殊类型的进程,它独立于前台用户界面,不与任何终端设备直接关联。这些进程通常在系统启动时启动,并持续运行直到系统关闭,或者它们完成其任务并自行终止。守护进程通常用于服务请求、管理系统或执行周期性任务。
我们可以通过如下步骤来创建守护进程。
- 创建子进程并结束父进程:在 UNIX 和类 UNIX 系统中,进程是通过复制(使用 fock() 函数)创建的。守护进程需要在后台独立运行。
- 设置会话 ID:我们使用
setsid()函数创建一个新会话,并使调用它的进程成为新会话的领导者。这样做的目的是让守护进程摆脱原来的控制终端。这样,守护进程就不会接收到终端发出的任何信号,例如挂断信号(SIGHUP),从未保证其运行不受前台用户操作的影响。 - 第二次调用 fork() 函数:这使得守护进程不是会话领导,没有获取控制终端的能力,避免意外获取控制终端。
- 更改工作目录:我们需要使用
chdir()函数将进程的工作目录更改到根目录(/),主要是为了避免守护进程继续占用其启动时的文件系统。这对于可移动的或网络挂载的文件系统尤其重要,确保这些文件系统下不需要时可以被卸载。 - 重设文件权限掩码:调用
umask(0)确保守护进程创建的文件不受继承的 umask 值的影响,守护进程可以更精确地控制其创建的文件和目录的权限。 - 关闭文件描述符:守护进程通常不需要标准输入、输出和错误文件描述符,因为它们不与终端交互。关闭这些不需要的文件描述符可以避免资源泄露,提高守护进程的安全性和效率。
- 处理信号:虽然守护进程和终端断开,但它仍然有可能接收到其它进程或内核发来的
SIGHUP信号,守护进程不应该因为它而终止。SIGTERM信号是终止信号,用于请求守护进程优雅地终止。通过命令行执行kill {pid}命令可以发送SIGTERM信号,接收到这个信号之后,守护进程终止子进程,并清理回收资源,最后退出。 - 执行具体任务:这一步是守护进程地的核心,它开始执行行为其设计的特定功能。
七、进程间通信
进程之间的内存都是隔离的,如果要在多个进程之间进行信息交换,常用的方式如下:
- 套接字通信(Unix Domain Socket IPC)
- 管道(有名管道、无名管道)
- 共享内存
- 消息队列
- 信号量
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <error.h>int main(void)
{int num = 0;// 使用fork()函数创建子进程// 该函数在父进程中返回的是创建的子进程的进程ID,在子进程中返回的是0pid_t pid = fork();// 从fork()函数之后,所有的代码都是在父子进程中各自执行一次if (pid < 0){// printf("child process creation failed!\n");// 打印错误perror("child process creation failed!");return -1;}else if (pid == 0){// 这里的代码是在子进程中执行的num = 1;printf("child proces number is %d.\n", num);}else{int child_process_status = 0;// 等待子进程终止waitpid(pid, &child_process_status, 0);// 这里的代码是在父进程中执行的printf("parent process number is %d.\n", num);}return 0;
}
在终端中输入 make 运行。
7.1、使用匿名管道实现进程间通信
匿名管道是位于内核的一块缓冲区,用于进程间通信。但两个进程之间通过一个管道只能实现单向通信。管道的读写端徐通通过打开的文件描述符来传递,因此要通信的两个进程必须从它们的公共祖先那里继承管道的文件描述符(调用 fork() 函数之前创建管道)。
创建匿名管道 的系统调用为 pipe()。
/*** @brief 在内核空间创建管道* * @param __pipedes 用于返回指向管道两端的描述符,__pipedes[0]指向管道的读端,__pipedes[1]指向管道的写端* @return int 成功返回0,失败返回-1,并且__pipedes不会改变*/
int pipe(int __pipedes[2]);
创建匿名管道之后,我们可以使用 write() 函数 将数据写入管道。
/*** @brief 写入数据* * @param __fd 管道的写端的文件描述符* @param __buf 要写入的数据* @param __n 要写入数据的字节数* @return ssize_t 成功返回实际写入的字节数。当有错误发生时则返回-1,错误代码存入errno中*/
ssize_t write(int __fd, const void *__buf, size_t __n);
写入数据之后,我们调用 read() 函数 从管道中读取数据。
/*** @brief 读取数据* * @param __fd 管道的读端的文件描述符* @param __buf 保存读取数据的缓冲区* @param __nbytes 要读取的数据大小* @return ssize_t 成功读取返回一个大于0的值*/
ssize_t read(int __fd, void *__buf, size_t __nbytes);
在操作完管道之后,我们需要使用 close() 函数 关闭管道。
/*** @brief 关闭文件描述符* * @param __fd 管道的文件描述符* @return int 0 成功,-1 失败*/
int close(int __fd);
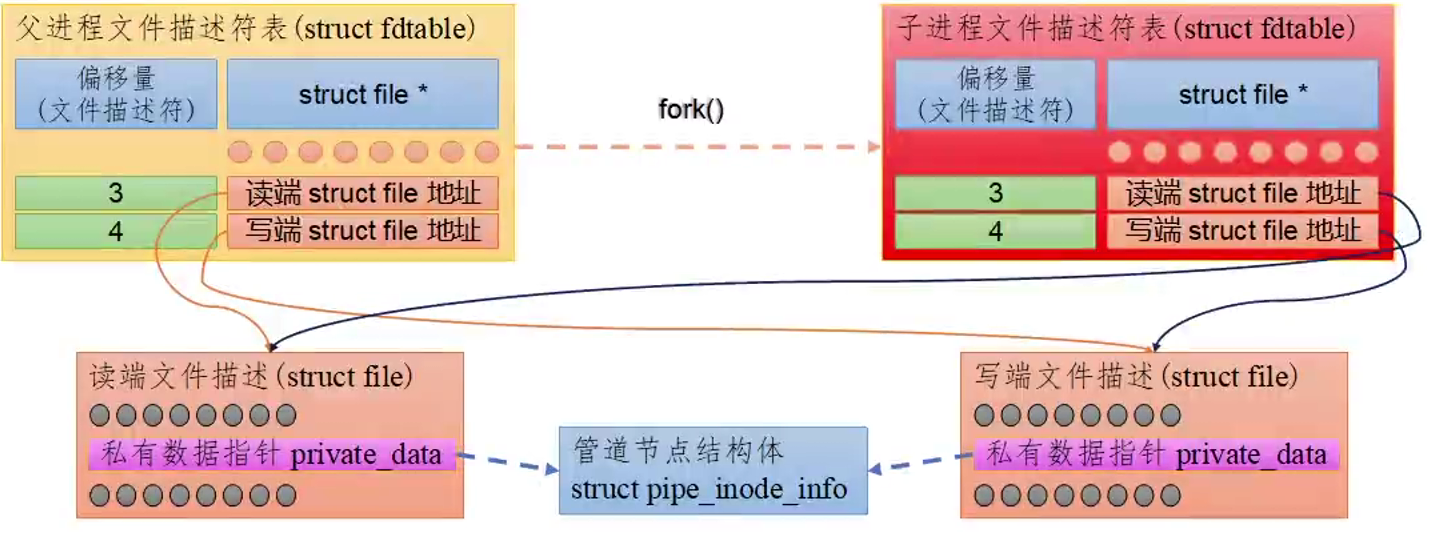
当我们开启管道时,父进程会创建两个 struct file 结构体用于管道的读写操作,并为二者各自分配一个文件描述符。它们的 private_data 属性指向同一个 struct pipe inode_info 的结构体,由后者管理对于管道缓冲区的读写。通过 fork() 创建一个子进程,后者会继承文件描述符,指向相同的 struct file 结构体。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <string.h>int main(void)
{int pipefd[2];// 创建管道if (pipe(pipefd) == -1){perror("create pipe failed!");exit(EXIT_FAILURE);}// 使用fork()函数创建子进程// 该函数在父进程中返回的是创建的子进程的进程ID,在子进程中返回的是0pid_t pid = fork();// 从fork()函数之后,所有的代码都是在父子进程中各自执行一次if (pid < 0){// printf("child process creation failed!\n");// 打印错误perror("child process creation failed!");exit(EXIT_FAILURE);}else if (pid == 0){// 这里的代码是在子进程中执行的char data[100] = {0};char ch = 0;int i = 0;sleep(1);printf("child process read pipe!\n");// 关闭管道的写端close(pipefd[1]);while (read(pipefd[0], &ch, 1) > 0){data[i++] = ch;// 留两位,倒数第二位写入换行符,倒数第一位是字符串结束符if (i >= sizeof(data) - 2){perror("read buffer overflow");break;}}data[i++] = '\n';data[i] = '\0';write(STDOUT_FILENO, data, strlen(data));// 关闭管道的读端close(pipefd[0]);exit(EXIT_SUCCESS);}else{// 这里的代码是在父进程中执行的// 父进程写入数据管道,供给子进程读char data[] = "hello world!";printf("parent process write pipe!\n");// 关闭管道的读端close(pipefd[0]);// 将数据写入到管道中write(pipefd[1], data, strlen(data));// 关闭管道的写端close(pipefd[1]);// 等待子进程终止waitpid(pid, NULL, 0);exit(EXIT_SUCCESS);}return 0;
}
在终端中输入 make 运行。
7.2、使用有名管道实现进程间通信
匿名管道只能在有父子关系的进程间使用,在某些场景下并不能满足要求。与匿名管道相对的是有名管道,它可以用于任何进程之间的通信。在 Linux 中,有名管道成为 FIFO,即 First In First Out,先进先出队列。
FIFO 和 Pipe 一样,提供了双向进程间通信的渠道。但需要注意的是,无论是有名管道还是匿名管道,同一条管道只应用与单向通信,否则可能出现通信混乱的问题(进程读到自己发的数据)。
我们可以通过 mkfifo() 函数 创建有名管道。
/*** @brief 创建有名管道* * @param __path 有名管道绑定的文件路径* @param __mode 有名管道绑定文件的权限* @return int 0 成功创建有名管道, -1 创建有名管道失败*/
int mkfifo(const char *__path, __mode_t __mode);
最后,我们需要调用 unlink() 函数释放管道。
/*** @brief 释放管道* * @param __name 有名管道绑定的文件路径* @return int 0 成功释放有名管道, -1 释放有名管道失败*/
int unlink(const char *__name);
这里,我们新建一个 write_fifo.c 文件,用来向管道中写入数据。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <errno.h>int main(void)
{int fd = 0;char pipe_path[] = "myfifo";char data[] = "hello world!";if (mkfifo(pipe_path, 0664) != 0){perror("create fifo failed!");// 文件已存在,错误编号是17if (errno != 17){exit(EXIT_FAILURE);}}// 对有名管道的特殊文件创建文件描述符if ((fd = open(pipe_path, O_WRONLY)) == -1){perror("open file failed!");exit(EXIT_FAILURE);}// 写道管道中write(fd, data, strlen(data));printf("write fifo finsh, process complete!\n");close(fd);// 释放管道,清除对应的特殊文件if (unlink(pipe_path) == -1){perror("release fifo failed!");}return 0;
}
这里,我们再建一个 read_fifo.c 文件,用来从管道中读取数据。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>int main(void)
{int fd = 0;char pipe_path[] = "myfifo";ssize_t i = 0;// 有名管道在另一个程序中写入管道时已经创建了,不需要重复创建// 对有名管道的特殊文件创建文件描述符if ((fd = open(pipe_path, O_RDONLY)) == -1){perror("open file failed!");exit(EXIT_FAILURE);}// 从管道中读取数据char data[128] = {0};ssize_t length = read(fd, data, sizeof(data));data[length++] = '\n';data[length] = '\0';// 写出到终端write(STDOUT_FILENO, data, length);printf("read data finsh, process complete!");close(fd);return 0;
}
然后,我们在终端中通过 gcc 编译文件,生成对应的可运行文件。
gcc write_fifo.c -o write_fifo
gcc read_fifo.c -o read_fifo
然后,我们再开一个终端窗口,在两个终端窗口中先后运行生成的可执行程序。
第一个终端窗口。
./write_fifo
第二个终端窗口。
./read_fifo
7.3、使用共享内存实现进程间通信
我们可以使用 shm_open() 函数开辟一块内存共享对象。然后,我们可以像使用文件描述符一样使用这块共享内存对象来实现进程间通信。
/*** @brief 创建一个共享内存对象*
* @param __path 共享内存对象绑定的文件路径* @param __oflag 打开模式* @param __mode 共享内存对象绑定文件的权限* @return int 成功创建返回文件描述符,创建失败返回-1*/
int shm_open(const char *__name, int __oflag, mode_t __mode);
参数 __path 是 共享内存对象的名称,可以直接写一个文件名称,该文件会保存在 /dev/shm 路径下。共享内存对象的名称必须是唯一的,以便不同进程可以定位同一个共享内存断。如果使用文件路径,则必须以 / 开头,以 \0 结尾,中间可以包含若干字符,但不能有 /。
参数 __oflg 用来 指定打开模式,可以是以下模式。
O_RDONLY:以只读方式打开文件。O_WRONLY:以只写方式打开文件。O_RDWR:以读写方式打开文件。O_CREAT:如果文件不存在,则创建一个新文件。O_APPEND:将所有写入操作追加到文件的末尾。O_TRUNC:如果文件存在并且以写入模式打开,则截断文件长度为 0。O_EXCL:当与 O_CREAT 一起使用时,只有当文件不存在时才创建新文件,如果共享内存对象已经存在,则返回错误。
在创建完共享内存对象之后,我们需要调用 truncate() 或 ftruncate() 函数将共享内存的文件缩放到指定大小。如果文件被缩小,截断部分的数据丢失,如果文件空间被放大,扩展的部分均为 \0 字符。缩放前后文件的偏移量不会更改。
/*** @brief 将文件缩放到指定大小* * @param __file 文件名* @param __length 指定长度的字节* @return int 成功返回0,失败返回-1*/
int truncate64(const char *__file, __off64_t __length);
define truncate truncate64/*** @brief 将文件缩放到指定大小* * @param __fd 文件描述符* @param __length 指定长度的字节* @return int 成功返回0,失败返回-1*/
int ftruncate(int __fd, __off_t __length);
不同的是,truncate() 函数需要指定文件名,而 ftruncate() 函数需要提供文件描述符。ftruncate() 函数缩放的文件描述符可以是通过 shm_open() 开启的内存对象,而 truncate() 缩放的文件必须是文件系统已存在文件,如文件不存在或没有权限则会失败。
在缩放共享内存的文件大小之后,我们还需要调用 mmap() 函数进行内存映射。mmap() 系统调用可以将一组设备或者文件映射到内存地址。我们在内存地址中寻址就相当与在读取这个文件指定地址的数据。父进程在创建一个内存共享对象并将其映射到内存区后,子进程可以正常读写该内存区,并且父进程也能看到更改。
/*** @brief 将文件映射到内存区域* * @param __addr 指向期望映射的内存地址的指针,通常设为NULL,让系统选择合适的地址* @param __len 要映射的内存区域的长度,以字节为单位* @param __prot 内存映射区域的保护标志* @param __flags 映射选项标志* @param __fd 文件描述符吗,用于指定要设置的文件或设备,如果是匿名设备,则传入无效的文件描述符* @param __offset 从文件开头的偏移量,映射开始的位置* @return void* 成功,返回映射的起始地址,失败则返回(void *)-1*/
void *mmap(void *__addr, size_t __len, int __prot, int __flags, int __fd, __off_t __offset);
参数 __prot 是 内存映射区域的保护标志,可以是以下标志的组合。
PORT_READ:允许读取映射区域。PORT_WRITE:允许写入映射区域。PORT_EXEC:允许执行映射区域。PORT_NONE:页面不可访问。
参数 __flags 是 映射选项标志,可以是以下标志。
MAP_SHARED:映射区域是共享的,对映射区域的修改会影响文件和其它映射到同一区域的进程。MAP_PRIVATE:映射区域是私有的,对映射区域的修改不会影响原始文件,对文件的修改会被暂时保存在一个私有副本中。MAP_ANONYMOUS:创建一个匿名映射,不与任何文件关联。MAP_FIXED:强制映射到指定区域,如果不允许映射,则返回错误。
使用完内存映射实现进程间通信之后,我们需要调用 munmap() 函数释放映射区。
/*** @brief 释放映射区* * @param __addr 映射区的地址* @param __len 要释放映射区的长度* @return int 成功返回0,失败返回-1*/
int munmap(void *__addr, size_t __len);
最后,我们还需要使用 shm_unlink() 来释放这块共享内存。
/*** @brief 释放共享内存对象* * @param __name 共享内存对象绑定的文件路径* @return int 0 成功释放 -1 释放失败*/
int shm_unlink(const char *__name);
然后,我们修改 main.c 文件。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <sys/wait.h>
#include <string.h>int main(void)
{int fd = 0;char *shm = NULL;pid_t pid = 0;// 1.创建共享内存char shm_name[128] = {0};sprintf(shm_name, "/letter%d", getpid());if ((fd = shm_open(shm_name, O_RDWR | O_CREAT, 0644)) < 0){perror("open shared memory failed!");exit(EXIT_FAILURE);}// 2.设置共享内存对象大小if (ftruncate(fd, 1024) == -1){perror("set shared memory size failed!");exit(EXIT_FAILURE);}// 3.内存映射if ((shm = mmap(NULL, 1024, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0)) == MAP_FAILED){perror("shared memory address map failed!");exit(EXIT_FAILURE);}// 4.映射完成之后,需要关闭fd连接不是释放close(fd);// 5.使用内存映射实现进程间通信if ((pid = fork()) < 0){perror("create child process failed!");exit(EXIT_FAILURE);}else if (pid == 0){// 这里是子进程要指定的代码// 将数据写入到共享内存对象中strcpy(shm, "hello world!");}else{// 这里是父进程要指定的代码// 等待子进程完成,确保子进程写入数据到共享内存waitpid(pid, NULL, 0);printf("receive data from child process (%d): %s\n", pid, shm);}// 6.无论父子进程都应该释放映射区if (munmap(shm, 1024) == -1){perror("release memory map failed!");exit(EXIT_FAILURE);}// 7.释放共享内存对象if (pid > 0){if (shm_unlink(shm_name) == -1){perror("release shared memory failed!");exit(EXIT_FAILURE);}}return 0;
}
在终端中输入 make 运行。