1.介绍
编码器-解码器,是深度学习中常见的模型框架。Encoder-Decoder 并不是一个具体的模型,而是一个通用的框架。Encoder 和 Decoder 部分可以是任意文字,语音,图像,视频数据,模型可以是 CNN,RNN,LSTM,GRU,Attention 等等。所以,基于 Encoder-Decoder,我们可以设计出各种各样的模型。
encoder:编码,将输入序列转化转化成一个固定长度向量。
decoder:解码,将之前生成的固定向量再转化出输出序列。
Encoder-Decoder:阶段的编码与解码的方式可以是CNN、RNN、LSTM、GRU等;
2.Seq2Seq
Seq2Seq (Sequence-to-sequence 的缩写),输入一个序列,输出另一个序列。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。
最常见的就是机器翻译
案例:英文 it is a cat. 翻译成中文的过程。
1)先将整个源句子进行符号化处理,以一个固定的特殊标记作为翻译的开始符号和结束符号。此时句子变成 it is a cat .
2) 对序列进行建模,得到概率最大的译词,如第一个词为 “这”。将生成的词加入译文序列,重复上述步骤,不断迭代。
3)直到终止符号被模型选择出来,停止迭代过程,并进行反符号化处理,得到译文。
3.Encoder-Decoder框架
Encoder阶段编码RNN,Decoder阶段编码RNN。
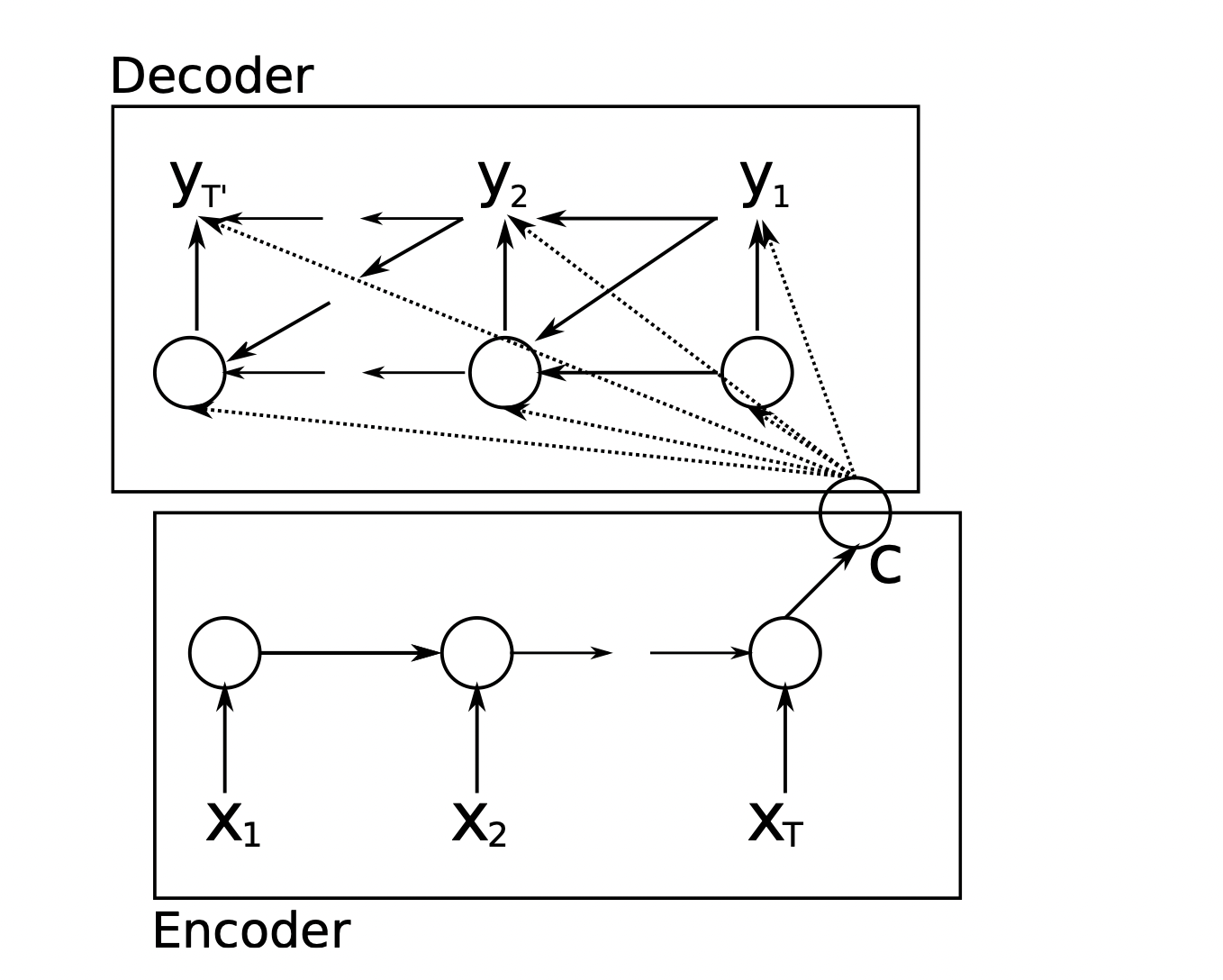
1) 编码器中RNN是一种由隐藏状态h和可选输出y组成的神经网络,该输出y在变长序列x = (x1,…,xT)上运行。
在每个时间步t, RNN的隐藏状态h(t)被更新为 h⟨t⟩ = f ( h⟨t-1⟩ , x(t) ),f为非线性激活函数
2) 语义向量C(长度固定,也是缺陷)是Encoder编码阶段的最终隐藏层的状态,或是多个隐藏层状态的加权总和,作为Decoder解码阶段的初始状态;
3) 解码器是另一个RNN,它被训练成通过给定隐藏状态h(t)来预测下一个符号y(t)来生成输出序列。然而,与编码器中描述的RNN不同,y(t)和h⟨t⟩也在输入序列的y(t−1)和c上被约束。因此,解码器在时刻t的隐藏状态计算为:h⟨t⟩ = f ( h⟨t-1⟩ , y(t-1) , x(t) )
4.Encoder-Decoder 的缺陷
与其说是 Encoder-Decoder 的局限,不如说是 RNN 的局限,在机器翻译中,输入某一序列,通过 RNN 将其转化为一个固定向量,再将固定序列转化为输出序列,即上面所讲的将英文翻译成中文。不管输入序列和输出序列长度是什么,中间的「向量 c」长度都是固定的。所以,RNN 结构的 Encoder-Decoder 模型存在长程梯度消失问题,对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有有效信息,即便 LSTM 加了门控机制可以选择性遗忘和记忆,随着所需翻译的句子难度怎能更加,这个结构的效果仍然不理想。
5.Attention机制
Attention 名为注意力机制,何为注意力机制。就像我们平时读文章一样,我们的视线不可能注意到所有的文字,随着眼睛的移动,我们的注意力也会跟着视线转移,最终会停留在认为重要的单词上,甚至还会划重点。一般来说,一篇文章的标题,小标题,我们都会第一时间注意到,这就是注意力机制。
在 Attention 模型中,我们翻译当前词,会寻找于源语句中相对应的几个词语,然后结合之前已经翻译的序列来翻译下一个词。
1) 对 RNN 的输出计算注意程度,通过计算最终时刻的向量与任意 i 时刻向量的权重,通过 softmax 计算出得到注意力偏向分数,如果对某一个序列特别注意,那么计算的偏向分数将会比较大。
2)计算 Encoder 中每个时刻的隐向量
3) 将各个时刻对于最后输出的注意力分数进行加权,计算出每个时刻 i 向量应该赋予多少注意力
4)decoder 每个时刻都会将 3 部分的注意力权重输入到 Decoder 中,此时 Decoder 中的输入有:经过注意力加权的隐藏层向量,Encoder 的输出向量,以及 Decoder 上一时刻的隐向量
5) Decoder 通过不断迭代,Decoder 可以输出最终翻译的序列。




![【洛谷P1196】银河英雄传说[NOI2002]](https://cdn.luogu.com.cn/upload/image_hosting/tkmxbxks.png)
![P3826 [NOI2017] 蔬菜 题解](https://cdn.luogu.com.cn/upload/image_hosting/a9qvsm06.png)
