模型结构
MLA(Multi-Head Latent Attention)
主要作用是在保证效果的基础上, 利用低秩压缩的原理优化kvCache, 加速推理, 同时节省训练显存.
先回忆下MHA, 在每个head上, 分别经过K, V生成 $ attnweights=(W_Qh_i)^T∗(W_Kh_j) $, 然后再乘上V得到: $attnsv=attnweights * (W_vh_j) $, 当输入的token一致时, 经过 \(W_k\)计算的结果一致的, 所以就可以把经过K和V计算的中间结果缓存下来用于节省算力. 但序列变长也会导致KVCache的数量爆炸, 导致显存瓶颈.
在MLA上, 将所有head的K共有信息提取出来, 每个head都用相同的一个compress_K矩阵, 这样就能把多个头的K cache压缩成1个, 而不同head的k中的特有信息通过矩阵乘法交换律的特点, \(attnweights=(h_i^TW_Q^TW_k)∗(h_j)\) , 把这部分信息转移到了Qhead里. 这样就能避免出现特有信息的丢失.

最后,使用压缩后了共有信息的compress_k,和吸收了相异信息的q_head做计算,得到attn_weights.
MOE Auxiliary-Loss-Free Load Balancing
对MOE负载均衡的优化, 像之前的Gshard算法, 加一个辅助loss, 用来惩罚某个expert溢出的情况. 但是这种方法会影响模型精度, 所以deepseek设计了无辅助loss的负载均衡算法.

解释上面公式列出的MOE步骤:
- 经过gating网络对expert进行打分. 公式15
- 选出topk的expert, mask掉不是topk的expert, 公式14
- 对gating输出进行归一化, 使得向量加和为1
- 经过moe网络的结果为\(U_t\)(即输入本身, 对应残差概念) + 经过共享expert的输出 + 经过门控筛选的expert的输出
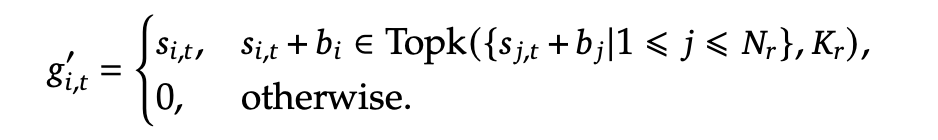
加了一个bias向量, 在每个train step里, 如果被选中的top expert溢出了, bias在更新的时候减去\(\gamma\) (指定的bias更新超参数), 在没溢出的时候加上\(\gamma\).

序列级辅助loss
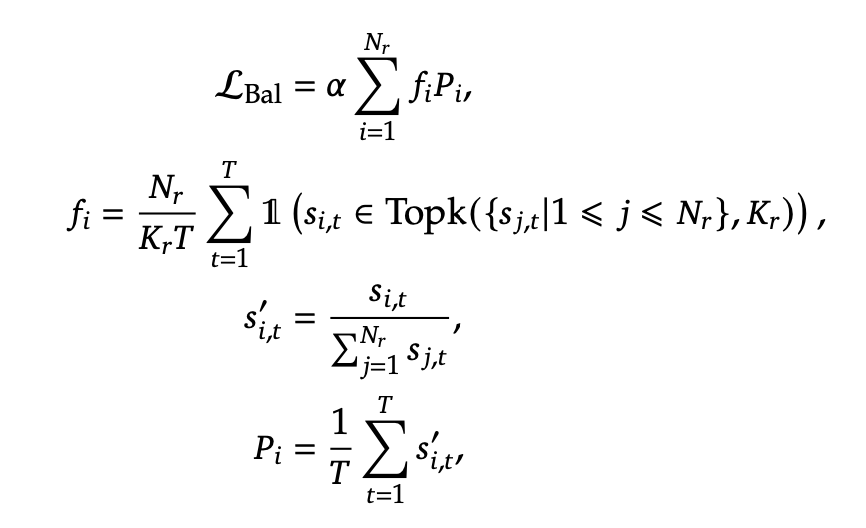
主要目的是防止单序列中的极度不平衡的情况出现, 加了个辅助loss用于避免这个情况.
T: 序列里的token数 \(\alpha\) 是一个较小的超参数
\(P_i\) : 表示第i个专家在所有token里出现的平均概率.
\(f_i\): 表示第i个专家在序列中被选择到的频率.
loss在minimize的时候, 如果\(P_i\) 很大, 同时他被选择到的次数也很多这种极限情况, 就会导致loss很大, 而小的\(P_i\)也有适当的选择频率后loss就会比较小
Multi-Token Prediction
一次训练多个token, 提高数据利用效率. 另外和llama实现不一样的地方在于这里是顺序预测而不是并行预测.
注意: 上个module的output和下一个输入emb concat, 因为维度double, 需要进行linear projection进行降维

Infra优化
并行方案: PP: 16 EP: 64 DP: zero1, 没有使用TP(通信量太大)
PP优化(DualPipe)
DualPipe看着是整个论文最重要的部分之一, 因为模型结构MOE的特性, 在MOE前后的2个AllToAll通信数据量非常大, 成为整个训练的瓶颈. DualPipe的实现主要借鉴了2个思想:
BackWard拆分:
ZeroBubble的主要目的是基于1F1B调度场景减少Bubble率, 在模型整体计算里, BP计算量是要比FP计算量大的, BP包含两个计算: 计算输入X的梯度,和计算参数W的梯度分别用\(B\)和\(W\)来表示, 流水线执行依赖X的梯度用于下个stage的计算, 但是对W梯度并没有串行限制, 这就可以通过拆分bp计算, 先算B再算W的方式减小Bubble.

双流PP:
双向流水线的主要设计思路在于: 如果存储2份模型副本, 同时在两个方向上开始训练. 那么副本0的FP和副本1的BP就能没有依赖关系的完全并行起来. 通过这种方式来减少流水线空等耗时.
蓝色和黄色块表示向下的前向和反向传播,绿色和橙色表示向上的传播

基于上面两个算法的思想出现了DualPipe

以 8PP 为例:
- Stage 0 上有 Layer 0, 1 以及 Layer 14, 15 的权重
- Stage 1 上有 Layer 2, 3 以及 Layer 12, 13 的权重
- Stage 7 上有 Layer 14, 15 以及 Layer 0, 1 的权重
- 相当于有 2 份相同的模型副本,Forward 的顺序可以从 Stage 0 到 7,也可以从 Stage 7 到 0。(因为deepseek设置的EP很大, 增加一份参数副本不会有太大的显存负担)
通信overlap:

- 限制每个token最多被发到4个node上, 从而减少IB流量
- NVLink 提供 160 GB/s 带宽,大约是 IB(50 GB/s)的 3.2倍. 当每个节点最多选3.2个专家的时候, IB和nvlink的通信可以完全overlap住. 所以deepseek选择8个expert是有通信上专门考虑的(< 4*3.2=12.8)
- 对于每个 Token,在做出路由决策时,首先通过 IB 传输到其目标节点上具有相同节点内索引的 GPU。一旦到达目标节点,将努力确保它通过 NVLink 立即转发到承载目标专家的特定 GPU,而不会被随后到达的 Token 阻塞。(PS:比如说,节点 A 上 GPU 0 的 Token 要发送到节点 B 上的 GPU 3,则对应的路径为:节点 A GPU 0 -> 节点 B GPU 0 -> 节点 B GPU 3。这样做是因为高性能 GPU 训练集群往往会采用轨道优化,同号 GPU 在一个 Leaf Switch 下,如下图所示,因此可以利用高速的 NVLink 来代替从 Leaf Switch 到 Spine Switch 的流量,从而降低 IB 通信时延,并且减少 Leaf Switch 和 Spine Switch 之间的流量)
- Dispatching工作: (1)InfiniBand(IB)发送、(2)IB 至 NVLink 转发,以及(3)NVLink接收分别由相应的 warp 处理
- combing工作: (1)NVLink 发送、(2)NVLink 至 IB 转发与累加,以及(3)IB 接收与累加
- 这里之所以使用定制化的PTX优化, 是为了自动调整dispatching/Combining这两个通信kernel占用的warp数, 从而减少L2 cache使用率避免影响计算中的SM.
显存优化手段
-
选择性激活重计算: 经典优化手段, 把RMSNorm和MLA里上投影 在bp需要用到的fp计算出的激活放弃缓存, 在bp时重新计算. 通过重计算的方式节省显存.
-
指数移动平均(Exponential Moving Average, EMA)通过赋予近期数据更高权重,平滑时间序列数据,常用于评估大语言模型(LLM)的训练稳定性和收敛性。
- 平滑损失曲线:训练损失通常波动较大,EMA 可生成平滑曲线,更容易识别长期趋势(如持续下降或平台期)。
- 如果EMA 损失持续下降,说明模型有效学习;若剧烈波动,可能需调整超参数(如学习率)。
deepseek把EMA参数在训练完成后异步传入到内存里, 用来评估模型训练是否正常.通过这种方式来节省显存.
-
DualPipe的PP设计, 使得embedding layer和output head在同一个PP stage上, 这种设计可以让MTP实现在物理显存里共享embed和output的参数和梯度, 节省存储.
FP8训练
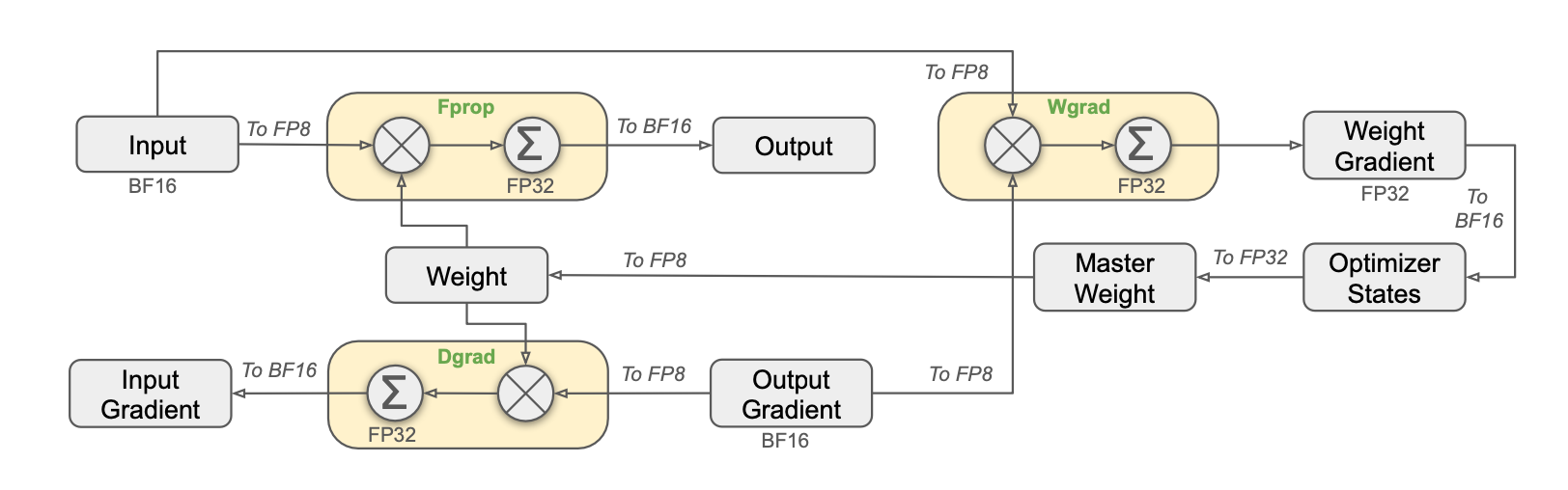
混合精度优化
对比主流BF16的实现方案, 主要区别在于以下几点:
- 激活/optimizer states 在训练过程中的存储其实主要还是BF16格式, 只是在计算前转成FP8
- GEMM优化后, 输入是FP8, 输出是FP32, 再转回BF16进行数据流转.
- FP和BP用到的weight, 从BF16变成了FP8.
- 不是所有的计算都变成了FP8, 部分对精度要求高的网络结构运算的时候还是使用BF16/FP32:
the embedding module, the output head, MoE gating modules, normalization operators, and attention operators - 在MOE dispatch之前的激活进行FP8量化再进行allToAll通信, 但是在combine的时候需要保持BF16保证训练精度
量化优化
重点是解决FP8上下界溢出的问题. 通过分组scale的方式进行

对激活量化: 每128分一个block进行scale系数计算
对W量化: 128*128的block进行量化(TODO: 没看懂input channel和output channel的意思)
MMA(矩阵相加)精度优化
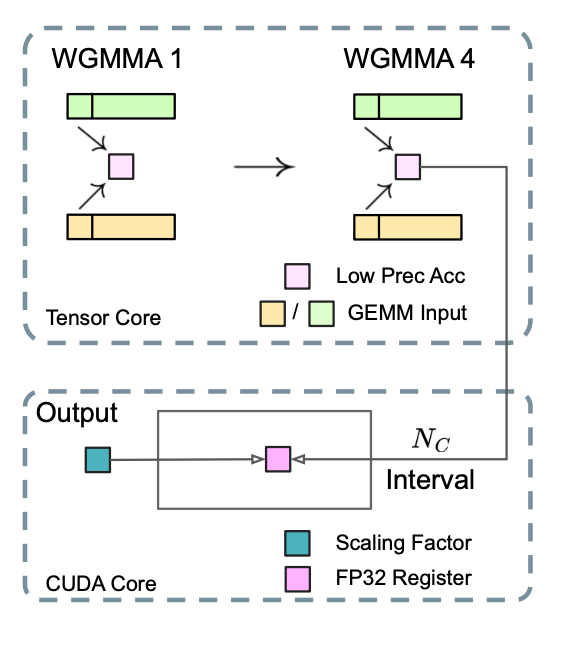
FP8 GEMM的精度损失主要受限于在GEMM计算每个子矩阵移动累加的时候, 容易超出FP8的精度范围. deepseek的解决方法是每执行\(N_c =128\)次MMA之后, 就把累加结果复制到FP32的cudacore里面, 进行全精度的FP32累加. 而且结合在之前细粒度量化里的scaling Factor, 可以很方便的在cudacore里进行反量化.
这个修改虽然会降低单个WGMMA的指令发射效率, 但在H800架构上通常由2个WGMMA在并发执行, 一个warpgroup在进行promotion操作的时候, 另一个在进行MMA计算, 上面的搬运操作可以被这两个操作overlap掉.
promotion解释:
指的是多个线程束(warp,通常由32个线程组成)通过协作将数据从低层次内存(如全局内存)高效地提升到高层次内存(如共享内存或寄存器)的优化操作。这一过程旨在减少全局内存访问延迟并提高内存带宽利用率,通常在需要高性能计算的场景(如矩阵乘法、张量核心操作)中尤为重要。
参考:
MLA解析: https://mp.weixin.qq.com/s/E7NwwMYw14FRT6OKzuVXFA
nvidia FP8 bench: https://developer.nvidia.com/zh-cn/blog/nvidia-gpu-fp8-training-inference/
EMA解释: https://zhuanlan.zhihu.com/p/554955968
Zero Bubble论文: https://arxiv.org/abs/2401.10241 zero Bubble分析: https://zhuanlan.zhihu.com/p/681363624
Chimera论文: https://arxiv.org/abs/2107.06925
Deepseek-V3解读: https://mp.weixin.qq.com/s/DKdXcguKcCS5gcwIRLH-Cg
Warp serialization解释(DeepSeek R1):
- 性能瓶颈:当所有Warp执行相同任务时,可能出现资源争用(如计算单元或内存带宽)或依赖延迟(如全局内存访问),导致SM(流多处理器)利用率低下。
- 解决方案:通过为不同Warp分配不同角色,允许它们异步协同工作,隐藏延迟并提高吞吐量。
Warp Specialization主要通过以下方式实现:
-
任务划分:
- 计算型Warp:专注于执行密集计算任务(如矩阵乘法、物理模拟)。
- 内存型Warp:负责全局内存与共享内存之间的数据搬运(如预取数据或存储结果)。
- 同步型Warp:管理线程间同步或与其他Warp的协调。
这种划分类似于CPU中的生产者-消费者模型,通过流水线化减少等待时间。
-
编程实现:
- 条件分支:在同一Kernel中使用
if (warp_id % N == 0)划分不同任务路径(需结合__shfl_sync等同步操作)。 - 协作组(Cooperative Groups):利用CUDA 9+引入的协作组API(如
coalesced_group或thread_block_tile),显式控制Warp的行为。 - 动态并行:在支持CUDA Dynamic Parallelism的架构中,子Kernel可特定化执行某些任务。
- 条件分支:在同一Kernel中使用
![【洛谷P1196】银河英雄传说[NOI2002]](https://cdn.luogu.com.cn/upload/image_hosting/tkmxbxks.png)
![P3826 [NOI2017] 蔬菜 题解](https://cdn.luogu.com.cn/upload/image_hosting/a9qvsm06.png)