强化学习(Reinforcement Learning, RL)已成为提升大型语言模型(Large Language Models, LLMs)推理能力的重要技术手段,特别是在需要复杂推理的任务中。DeepSeek 团队在 DeepSeek-Math [2] 和 DeepSeek-R1 [3] 模型中的突破性成果,充分展示了强化学习在增强语言模型数学推理和问题解决能力方面的巨大潜力。
这些成果的取得源于一种创新性的强化学习方法——群组相对策略优化(Group Relative Policy Optimization, GRPO)。该方法有效解决了将强化学习应用于语言模型时面临的特殊挑战。本文将深入分析 GRPO 的工作机制及其在语言模型训练领域的重要技术突破,并探讨其在实际应用中的优势与局限性。
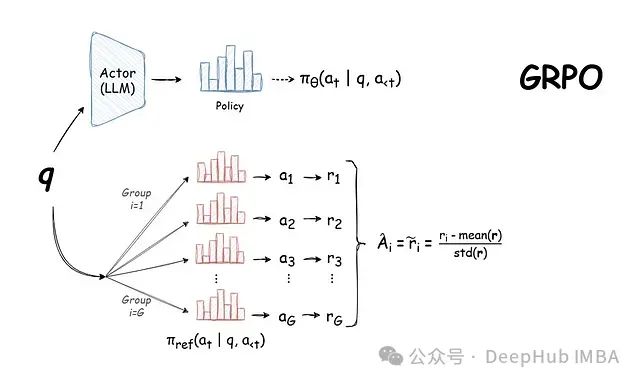
PPO 与 GRPO 的对比分析
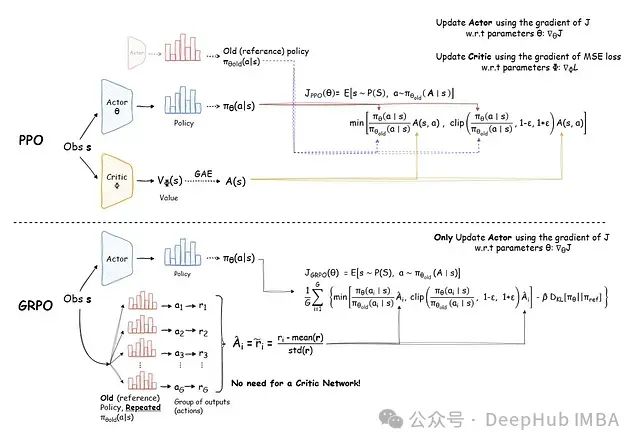
近邻策略优化(Proximal Policy Optimization, PPO)[1] 一直是语言模型强化学习微调的主流算法。PPO 的核心是一种策略梯度方法,通过裁剪(clipping)机制来限制策略更新的幅度,从而防止策略发生过大的破坏性变化。PPO 的目标函数可表示为:
https://avoid.overfit.cn/post/05d4b8fb001b4adeb4e050fb323cd21f



![[AI/GPT] 硅基流动(SiliconFlow) : AI大模型时代的基础设施](https://blog-static.cnblogs.com/files/johnnyzen/cnblogs-qq-group-qrcode.gif?t=1679679148)