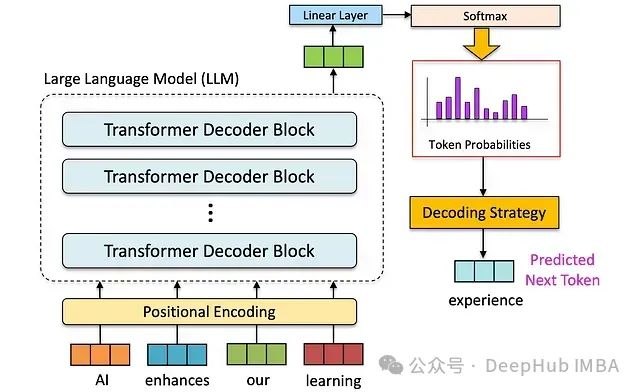
在构建AI本地知识库时,我们不可避免地需要对PDF文件进行处理。PDF文件大致分为两种:扫描的图片文件和非图片文件。对于非图片类型的PDF,可以直接提取文本并进行向量化处理;但对于图片类型的PDF(如扫描件),处理起来就复杂得多。
问题背景
图片类型的PDF文件通常存在以下问题:
- 扫描件可能不是一页一页扫描的,而是多页合并在一起。
- 文字方向多样,可能包含横排、竖排甚至不同语言的文字。
- 不同段落的文字容易被错误合并成一行,导致内容混乱。
幸运的是,借助现代AI技术,我们可以高效地解决这些问题。
处理流程
以下是图片PDF向量化处理的整体流程:
graph TDA[PDF输入] --> B[文本检测+方向分类+文本识别]B --> D[Ai整理合并]D --> E[小模型Ai校对]E --校对失败--> DE --校对成功--> F[Ai输出清理]F --> G[小模型校验]G --校验失败--> FG --校验成功--> H[输出整理完成的文档]H --> I[向量化]
-
PDF输入
将PDF文件作为输入源。 -
文本检测与方向分类
使用OCR技术检测文字区域,并识别文字方向。提取文字内容,生成初步的文本数据。 -
AI整理与合并
使用大模型对提取的文本进行整理和合并,确保段落结构正确。 -
小模型校对
使用小模型对整理后的文本进行校对。如果校对失败,则重新执行AI整理与合并步骤。 -
AI输出清理
对文本进行进一步清理,去除冗余信息。 -
小模型校验
再次使用小模型对清理后的文本进行校验。如果校验失败,则重新执行清理步骤。 -
输出整理完成的文档
将最终整理好的文档输出。 -
向量化
将整理完成的文档转化为向量形式,用于后续的知识库构建。
技术选型
1. 文本检测与识别
经过多次测试,发现百度飞桨(PaddlePaddle)的PP-OCR模型效果最佳,能够很好地识别繁体中文和其他复杂字符。相比一些收费的OCR工具,PP-OCR的表现更加出色。
2. AI整理与合并
为了确保文本整理的准确性,我选择了通义千问的Qwen2.5-72B-Instruct模型。该模型具有强大的指令遵循能力,并且通过将temperature设置为0,可以严格遵循输入文档的结构,避免不必要的改动。
3. 校对与校验
在校对环节,我使用了DeepSeek-R1:7B模型。经过测试,即使是较小的DeepSeek-R1:1.5B模型也能满足需求,但为了保险起见,最终选择了7B版本。
示例代码
以下是关键步骤的部分代码示例:
文本检测与识别
from paddleocr import PaddleOCR# OCR核心配置
ocr = PaddleOCR(use_angle_cls=True, # 自动旋转文本方向lang="ch", # 支持繁体识别det_model_dir='ch_PP-OCRv4_det_infer', # 文本检测模型rec_model_dir='ch_PP-OCRv4_rec_infer', # 文本识别模型gpu_mem=4000 # 控制显存占用
)
AI整理与合并
def merge_text_with_ai(blocks_metadata, page_size, model_name=MERGE_MODEL):"""智能版面分析及多语言文本合并"""system_prompt = """你是一个专业的OCR文本处理专家,擅长分析和重组OCR识别的文本块。
你的任务是将散乱的文本块重新组织成有序、连贯的文章。
只能输出重组后的纯文本内容,不要解释处理过程。"""user_prompt = """# OCR文本重组任务
【输入信息】
页面尺寸:{width}x{height}
文本块数据:
{blocks_metadata}【重组规则】
1. 文本分析- 识别段落关系:通过内容连贯性和位置关系- 重排段落:基于语义和排版位置2. 内容处理- 合并断行:修复被错误分割的句子- 保持段落完整性3. 质量要求- 保持语义连贯性- 避免重复内容- 维护完整段落结构- 保证内容完整不遗漏"""# 初始化merged变量merged = ""original_text = '\n'.join(block['text'] for block in blocks_metadata)for attempt in range(MAX_RETRIES):try:print("开始合并文本...")response = client_sf.chat.completions.create(model=model_name,messages=[{"role": "system", "content": system_prompt},{"role": "user", "content": user_prompt.format(width=page_size[0],height=page_size[1],blocks_metadata=blocks_metadata # 修正变量名)}],temperature=0,timeout=MODEL_TIMEOUT)merged = response.choices[0].message.content.strip()# 后处理流程merged = re.sub(r'<think>.*?</think>', '', merged, flags=re.DOTALL)merged = re.sub(r'[※★◆▁▂▃▄▅▆▇█▏▎▍▌▋▊▉]+', '', merged)merged = re.sub(r'[,,]+', ',', merged)merged = re.sub(r'\n{3,}', '\n\n', merged)if validate_output(original_text, merged):print("校验通过,返回合并结果")return mergedprint(f"校验未通过,开始第{attempt+1}次重试...")except Exception as e:if 'timeout' in str(e).lower():logging.error(f"AI响应超时({MODEL_TIMEOUT}秒),尝试第{attempt+1}次重试...")else:logging.error(f"合并失败: {str(e)}")if attempt == MAX_RETRIES - 1:breaktime.sleep(RETRY_BASE_DELAY ** attempt)return original_text # 如果所有尝试都失败,返回原始文本
小模型校对
def validate_output(original_text, processed_text):"""严格单结果校验"""system_prompt = """你是一个严格的文本质量检查员。
你的任务是对比原始文本和处理后的文本,检查是否存在内容缺失、非法删除或重复问题。
只需回答"是"或"否",不需要解释原因。"""user_prompt = """请对比原文和处理后文本,严格检查:
1. 内容缺失:处理后文本是否删除了原文中的句子
2. 非法删除:是否错误删除正文内容
3. 重复问题:是否产生了原文中不存在的重复内容▼原始文本▼
{original_sample}▼处理后文本▼
{processed_sample}如果存在任何一个问题,请回答[否]
如果全部符合要求,请回答[是]
仅允许输出[是]或[否]"""try:print("开始校验...")print("原始文本:",original_text.replace('\n', ' '))print("处理后文本:",processed_text.replace('\n', ' '))response = client_local.chat.completions.create(model=VALIDATE_MODEL,messages=[{"role": "system", "content": system_prompt},{"role": "user", "content": user_prompt.format(original_sample=original_text[:300].replace('\n', ' '),processed_sample=processed_text[:500].replace('\n', ' '))}],temperature=0,timeout=VALIDATE_TIMEOUT)# 严格清洗响应print("校验结果:",response.choices[0].message.content)clean_res = re.sub(r'<think>.*?</think>', '', response.choices[0].message.content, flags=re.DOTALL)clean_res = re.sub(r'[^是否]', '', clean_res)return '否' not in clean_resexcept Exception as e:logging.error(f"校验失败: {str(e)}")return False
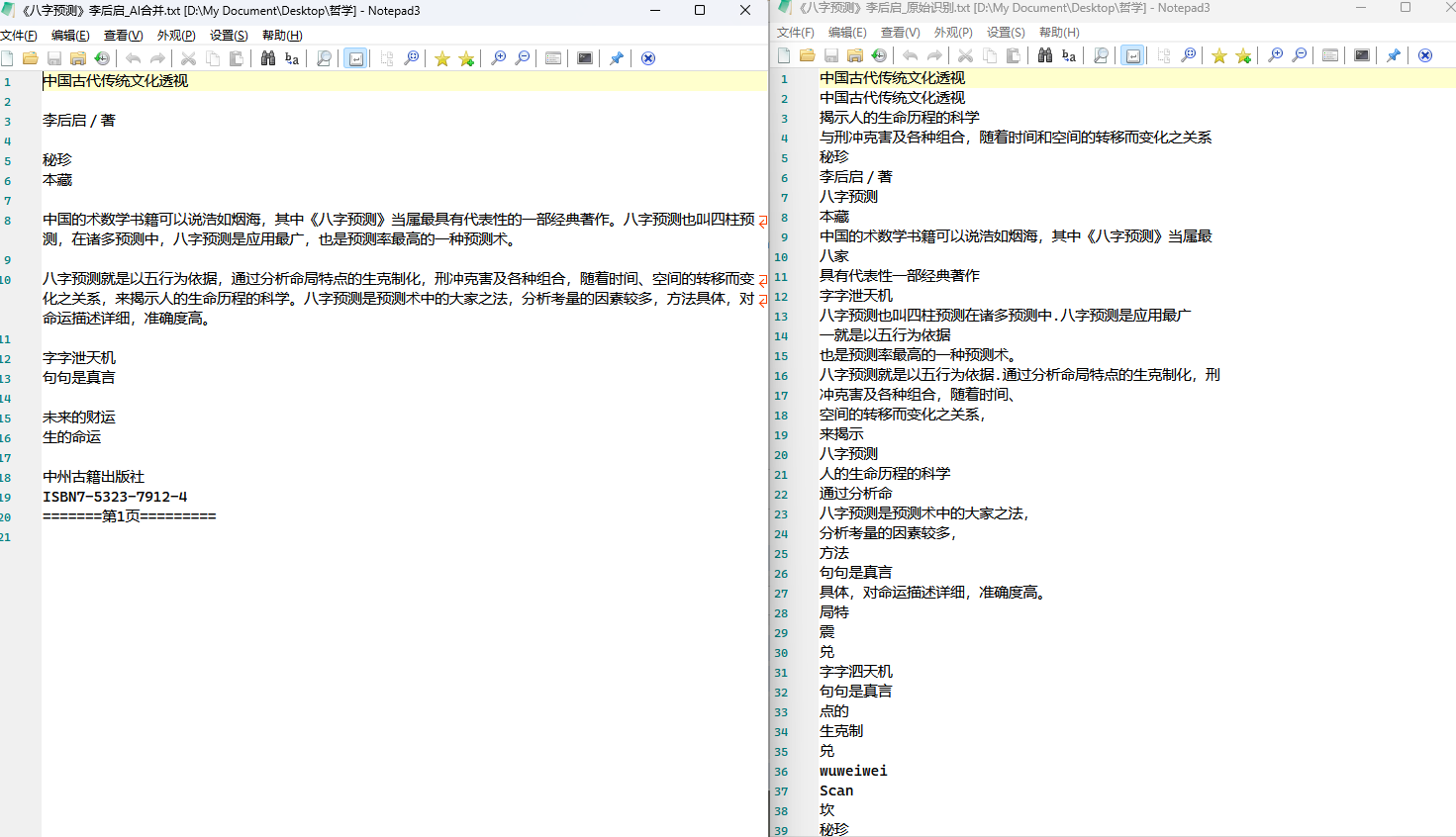
原始图像

处理后效果




![[AI/前沿展望/综述] AI大模型的技术生态链全景图](https://blog-static.cnblogs.com/files/johnnyzen/cnblogs-qq-group-qrcode.gif?t=1679679148)