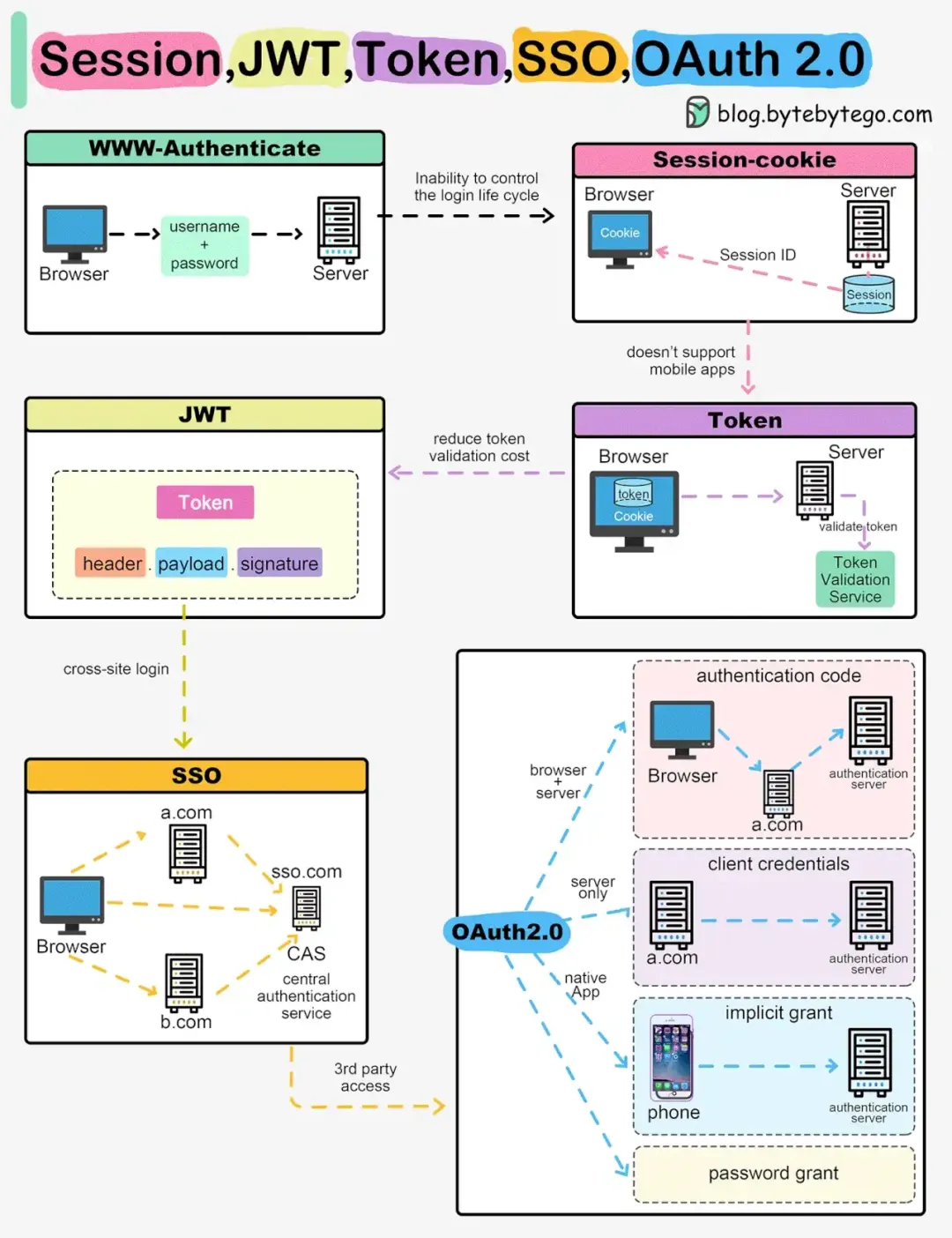
 本文章实现内容如下:
① 完成了更细粒度的内存分配机制——arena机制的建立
② 完成了内存分配系统调用 malloc() 的实现
③ 完成了内存释放系统调用 free() 的实现
本文章实现内容如下:
① 完成了更细粒度的内存分配机制——arena机制的建立
② 完成了内存分配系统调用 malloc() 的实现
③ 完成了内存释放系统调用 free() 的实现一、malloc 底层原理
- 之前我们虽然已经实现了内存管理,但显得过于粗糙,分配的内存都是以 4KB 大小的页框为单位的,当我们仅需要几十字节、几百字节这样的小内存块时,显然无法满足这样的需求了,为此必须实现一种小内存块的管理,可以满足任意内存大小的分配,这就是我们为实现 malloc 要做的基础工作。
- arena介绍
- arena 是很多开源项目中都会用到的内存管理概念,将一大块内存划分成多个小内存块,每个小内存块之间互不干涉,可以分别管理,这样众多的小内存块就称为arena。
- 原有系统只能分配 4KB 粒度的内存页框,因此 arena 的这“一大块内存”也是通过 malloc_page 获得的以 4KB 为粒度的内存,根据请求的内存量的大小,arena 的大小也许是 1 个页框,也许是多个页框,随后再将它们平均拆分成多个小内存块。
- 按内存块的大小,可以划分出多种不同规格的 arena,比如一种 arena 中全是 16 字节大小的内存块,故它只响应 16 字节以内的内存分配,另一种 arena 中全是 32 字节的内存块,故它只响应 32 字节以内的内存分配。
- 内存块规格以 16 字节为起始,向上依次是 32 字节、64 字节、128 字节、256字节、512 字节、1024 字节,总共 7 种规格
- 我们平时调用 malloc 申请内存时,操作系统返回的地址其实就是某个内存块的起始地址,操作系统会根据 malloc 申请的内存大小来选择不同规格的内存块。因此,为支持多种容量内存块的分配,我们要提前建立好多种不同容量内存块的arena。
- 不同内存块规格下:一个Page中划分的内存块数量 = arena 内存池区域的大小(如One-Page) / 内存块规格容量(如16字节)
- arena 是个提供内存分配的数据结构,它分为两部分
- 第一部分是元信息
- 元信息用来描述自己内存池中空闲的内存块数量,这其中包括内存块描述符指针(后面介绍),通过它可以间接获知本 arena 所包含内存块的规格大小,此部分占用的空间是固定的,约为 12 字节。
- 第二部分就是内存池区域
- 内存池区域里面有无数的内存块,此部分占用 arena 大量的空间。我们把每个内存块命名为mem_block,它们是内存分配粒度更细的资源,最终为用户分配的就是这其中的一个内存块。
- 第一部分是元信息
- 在我们的实现中,针对小内存块的 arena 占用 1 页框内存,除了元信息外的剩下的内存被平均分成多个小内存块。整个 arena 就像个仓库一样,元信息部分相当于库房管理员,内存块相当于库中物品。

- arena 容纳的内存块是有限的,总会有内存块供不应求的时候。当某一规格 arena 中的内存块全部分配出去时,必须再增加新的同一规格的arena,由多个同一规格的 arena 组合为一个“大的仓库”,为同一规格的内存块提供货源。
- 初始时,为某一类型内存块供货的 arena 只有 1 个,当此 arena 中的全部内存块都被分配完时,系统再创建一个同规格的 arena 继续提供该规格的内存块,当此 arena 又被分配完时,再继续创建出同规格的arena,arena 规模逐渐增大,逐步形成 arena 集群。
- 既然同一类内存块可以由多个 arena 提供,为了跟踪每个 arena 中的空闲内存块,分别为每一种规格的内存块建立一个内存块描述符,即 mem_block_desc,在其中记录内存块规格大小,以及位于所有同类 arena 中的空闲内存块链表。

- 内存块描述符将所有同类 arena 中空闲内存块汇总,因此它相当于内存块超级大仓库,分配小块内存时必须先经过此入口,系统从它的空闲内存块链表 free_list 中挑选一块内存,也就是说,最终所分配的内存属于此类 arena 集群中某个 arena 的某个内存块。
- 内存块规格有多少种,内存块描述符就有多少种,因此各种内存块描述符的区别就是 block_size 不同,free_list 中指向的内存块规格不同。
- 由于有了内存块描述符,arena 中就没有必要再冗余记录本 arena 中内存块规格信息,而是用位于 arena 的元信息当中的内存块描述符指针指向本 arena 所属的内存块描述符,间接获得本 arena 中内存块的规格大小。
- 注意:处理大内存请求(申请的内存大于1024字节)时也会创建个 arena,但不会再将它拆分成小内存块,而是直接将整块大内存分配出去。故此类 arena 没有对应的内存块描述符,元信息中的内存块描述符指针为空。

- 【总结】
- 在内存管理系统中,arena 为任意大小内存的分配提供了统一的接口,它既支持 1024 字节以下的小块内存的分配,又支持大于 1024 字节以上的大块内存,malloc 函数实际上就是通过 arena 申请这些内存块。
- arena 是个内存仓库,并不直接对外提供内存分配,只有内存块描述符才对外提供内存块,内存块描述符将同类 arena 中的空闲内存块汇聚到一起,作为某一规格内存块的分配入口。
- 因此,内存块描述符与 arena 是一对多的关系,每个 arena 都要与唯一的内存块描述符关联起来,多个同一规格的 arena 为同一规格的内存块描述符供应内存块,它们各自的元信息中用内存块描述符指针指向同一个内存块描述符。

二、底层初始化
- 本节我们要完成上一节中介绍的基础,构建 7 种规格的内存块描述符,以后在实际 malloc 时,若发现缺失内存块时再创建相应的arena。
- 将来我们会从堆中创建arena,我们会给 arena 结构体指针赋予 1 个页框及以上的内存,那时候的 arena 就是个名符其实的内存仓库了,页框中除了arena元信息结构体外的部分都将作为 arena 的内存池区域,该区域会被平均拆分成多个规格大小相等的内存块,即 mem_block,这些 mem_block 会被添加到内存块描述符的 free_list。
三、实现 sys_malloc
- 对计算机来说,内存资源再大也不嫌多,因此不能浪费,必须本着按需分配的原则合理使用,内存块并不是提前“盲目”准备好的,它在需要时由程序动态创建,创建它的函数就是sys_malloc,即 malloc 对应的子功能处理函数 sys_malloc,sys_malloc 的功能是分配并维护内存块资源,动态创建 arena 以满足内存块的分配。
- 【总结】
- 在各种 list 中的结点是 list_elem 的地址,并不是 list_elem 所在的“宿主数据结构”(这个词是作者自己杜撰的,仅供说清楚问题),比如在就绪队列 thread_ready_list 中的是 pcb 的 general_tag 的地址,pcb 便是 general_tag 的宿主数据结构。宿主数据结构中 list_elem 的地址才是链表中的结点,而 list_elem 中存储的是前躯和后继结点的地址,也就是其他宿主数据结构的 list_elem 的地址。当结点从链表中脱离时,要将其还原成宿主数据结构才能使用,还原工作是通过宏 elem2entry 完成的,本节的内存块分配便是通过该宏得到内存块的起始地址。内存块地址被返回给用户后,用户可以自由使用此内存块,自然也会把此内存块中的 “list_elem型的变量free_elem” 覆盖,不过没关系,它并不影响该内存块的回收和分配,因为 free_list 中的元素是list_elem 的地址,地址是不变的,将来回收或再次分配时依然可以正常使用。
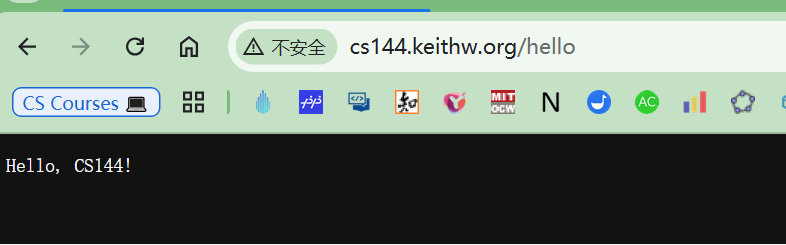
- 下图框出来的是两个线程的输出,我们注意各线程获得的内存地址,分别是 0xc010200c 和 0xc010204c,下面分析下这两个地址背后的“故事”。
- 这两个线程申请的内存字节一个是 33,一个是 63,它们与规格为 64 字节的内存块最接近,因此 sys_malloc 会创建规格为 64 字节的 arena,然后把它拆分成 64 字节的内存块,由于是第 1 次申请内存且只申请了一种内存块,故系统中只存在这一个 arena。把线程 thread_a 获得的内存地址 0xc010200c 拆分成 0xc0102000+0xc 来看,其中 0xc0102000 是 arena 的首地址,0xc 是arena 元信息大小,故返回的 0xc010200c 是 arena 中第 1 个 64 字节内存块的地址。线程 thread_b 获得的内存地址是0xc010204c,它与 0xc010200c 相差为0x40,即十进制 64 字节,这证明 thread_a 申请的 33 字节也占用了 64 字节的内存块,thread_b 申请的 63 字节占用的是 arena 中第 2 个 64 字节内存块。

- 这两个线程申请的内存字节一个是 33,一个是 63,它们与规格为 64 字节的内存块最接近,因此 sys_malloc 会创建规格为 64 字节的 arena,然后把它拆分成 64 字节的内存块,由于是第 1 次申请内存且只申请了一种内存块,故系统中只存在这一个 arena。把线程 thread_a 获得的内存地址 0xc010200c 拆分成 0xc0102000+0xc 来看,其中 0xc0102000 是 arena 的首地址,0xc 是arena 元信息大小,故返回的 0xc010200c 是 arena 中第 1 个 64 字节内存块的地址。线程 thread_b 获得的内存地址是0xc010204c,它与 0xc010200c 相差为0x40,即十进制 64 字节,这证明 thread_a 申请的 33 字节也占用了 64 字节的内存块,thread_b 申请的 63 字节占用的是 arena 中第 2 个 64 字节内存块。
四、内存的释放
- 内存管理系统不仅能分配内存,还应该能回收内存,这是最基本的内存管理机制。
- 内存的使用情况都是通过位图来管理的,因此,无论内存的分配或释放,本质上都是在设置相关位图中的相应位,都是在读写位图。回收物理地址就是将物理内存池位图中的相应位清0,无需将该 4KB 物理页框逐字节清0。回收虚拟地址就是将虚拟内存池位图中的相应位清0。分配则是相反的,也就是将位图中相应位置为 1 即可。
- 【重点知识】分配内存时的一般步骤如下【以下三个步骤将封装在函数 malloc_page 中】
- 在虚拟地址池中分配虚拟地址,相关的函数是 vaddr_get,此函数操作的是内核虚拟内存池位图“kernel_vaddr.vaddr_bitmap”或用户虚拟内存池位图“pcb->userprog_vaddr.vaddr_bitmap”。
- 在物理内存池中分配物理地址,相关的函数是 palloc,此函数操作的是内核物理内存池位图“kernel_pool->pool_bitmap”或用户物理内存池位图“user_pool->pool_bitmap”。
- 在页表中完成虚拟地址到物理地址的映射,相关的函数是page_table_add。
- 【重点知识】将要设计的释放内存的步骤如下【功能封装在 mfree_page 中】
- 在物理地址池中释放物理页地址,相关的函数是 pfree,操作的位图同 palloc。
- 在页表中去掉虚拟地址的映射,原理是将虚拟地址对应 pte 的 P 位置0,相关的函数是 page_table_pte_remove(仅对PTE修改,不对PDE修改)。
- 只要 pte 的 P 位为0,CPU 就认为该虚拟地址未做映射,从而达到删除虚拟地址的目的。
- P 位的实际意义是当可用物理内存较少时,可以将 pte 指向的物理页框中的数据转储到外存上,这样就省出了 4KB 的物理内存空间。将物理页中的数据存储到外存的同时,需要将 pte 的 P 位置为0。这样在下次访问该 pte 对应的虚拟地址时,由于 pte 的 P 位为0,CPU 会抛出 pagefault 缺页异常,我们可以在处理 pagefault 异常的中断处理程序中将之前保存到外存的页框数据再次载入到物理内存中【依据什么定位外存中的数据呢?后续再补充】,该物理内存可以是原来的物理页,也可以是新的物理页,这取决于实际物理内存的使用情况,然后把目标物理页地址更新到 pte 中,并将 P 位置为 1 。pagefault 中断处理程序退出后,CPU 自动会再次访问引起此 pagefault 的虚拟地址,这次发现 pte 的 P 位为 1,从而访问正常,这就是 CPU 原生支持的页式虚拟地址管理策略,话说 Linux 虚拟地址管理也是利用 P 位和 pagefault 异常实现的。
- 按理说,当页表中所有的 pte 都无效时,就可以将页表所在的 4KB 页框回收了,但不值得只为节省一两个页框的内存而在程序运行中频繁操作页表,因此,我们对于删除虚拟地址的处理方法仅仅是将 pte 中的 P 位清 0。
- 在虚拟地址池中释放虚拟地址,相关的函数是 vaddr_remove,操作的位图同 vaddr_get。
五、实现 sys_free
- 我们之前实现的 mfree_page 只能释放页框级别的内存块,这当然不能满足我们的需求,必须支持释放任意字节大小的内存,而这就是 sys_free 的使命。
- sys_free 是内存释放的统一接口,无论是页框级别的内存和小的内存块,都统一用 sys_free 处理。因此,sys_free 针对这两种内存的处理有各自的方法
- 对于大内存的处理称之为“释放”,就是把页框在虚拟内存池和物理内存池的位图中将相应位置 0 ,再加对 PTE 的相关操作。
- 对于小内存的处理称之为“回收”,是将 arena 中的内存块重新放回到内存块描述符中的空闲块链表 free_list。
六、实现系统调用 malloc 和 free
- malloc 和 free 的原型
- malloc:
void *malloc(size_t size);:分配size字节大小的内存,并返回所分配的地址。 - free:
void free(void *ptr);:释放ptr所指向的内存。
- malloc:


![[2025.2.10~16 鲜花] 仆は可怜な少女にはなれない](https://img2024.cnblogs.com/blog/2942935/202502/2942935-20250216193228959-113263946.png)

![[ubuntu使用]安装微信](https://img2024.cnblogs.com/blog/1612208/202502/1612208-20250216185435693-894398391.png)