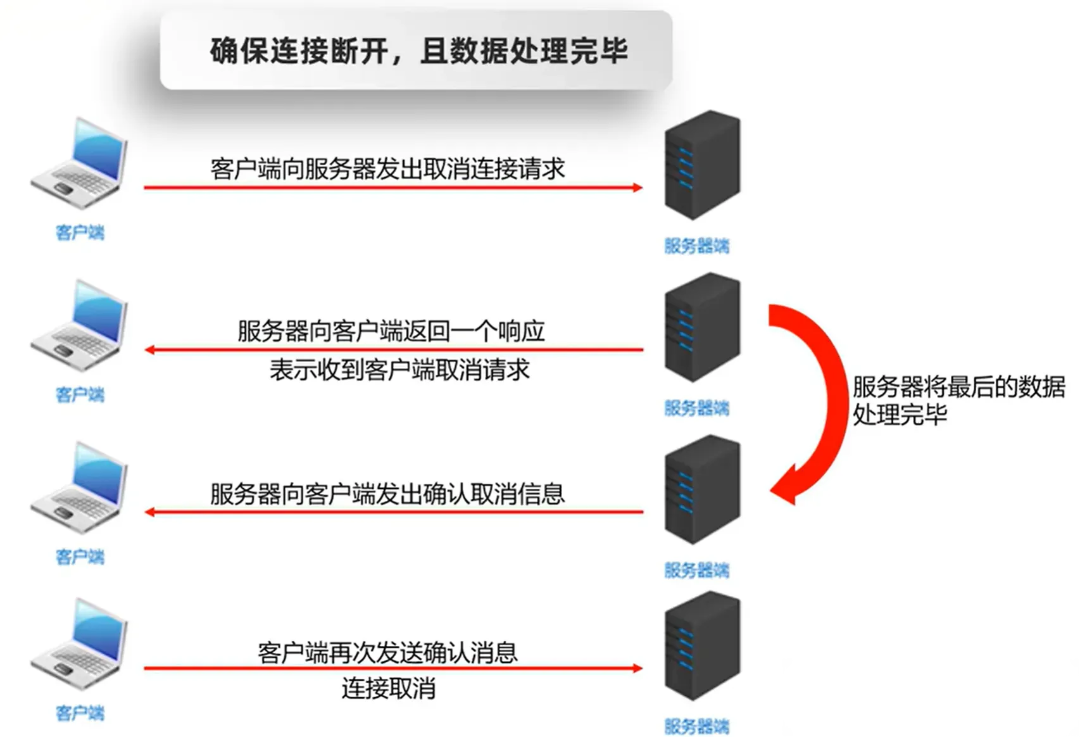
-
正向传播
- 尽量降低损失函数

- 尽量降低损失函数
-
梯度
- 梯度是一个向量(矢量),函数在一点处沿着该点的梯度方向变化最快,变化率最大。换而言之,自变量沿着梯度方向变化,能够使应变量(函数值)变化最大。
-
如图:如果想要 w 下降最快就沿着梯度的负方向下降,就能降低损失函数

-
方向传播
- 更新各个参数的值(如图中 w 的值),重新导入正向传播,达到减低损失函数
- 一次的方向传播会更新所有的参数

- 学习率 - Learning Rate(LR)
- 决定了模型参数的更新幅度,学习率越高,模型参数更新越激进,即相同loss对模型参数产生的调整幅度越大,反之越小
- 如果学习率太小,会导致网络loss下降非常慢;
- 如果学习率太大,那么参数更新幅度就非常大,产生振荡,导致网络收敛到局部最优,或者loss不降反增

- Batch size
- Batch size 是一次相模型输入的数据量,Batch size越大,模型一次处理的数据量就越大,能够更快的运行完一个Epoch,反之运行完一个Epoch越慢
- 由于模型一次是根据一个Batch size的数据计算Loss,然后更新模型参数,如果Batch size过小,单个Batch 可能与整个数据的分布有较大的差异,会带来较大的噪音,导致模型难以收敛
- 与此同时,Batch size越大,模型单个Step加载的数据量越大,对于GPU显存的占用也越大,当GPU现存不够充足的情况下,较大的Batch size会导致OOM(内存溢出),因此,需要针对实际的硬件情况,设置合理的Batch size取值
- 训练大模型时如果数据集越大,batch size越大越好,相反如果数据集越少,Batch size不能太大,否则参数迭代更新的次数太少,从而导致loss降不下来
- 在合理范围内,更大的Batch size能够:
- 提高内存利用率,提高并行化效率
- 一个Epoch所需的迭代次数变少,减少训练时间
- 梯度计算更加稳定,训练曲线更平滑,下降方向更准,能够取得更好的效果
- 对于传统的模型,在较多的场景中,较小的Batch size能够取得更好的模型性能;对于大模型,往往更大的Batch size能够取得更好的性能

-
激活函数
- 为什么需要激活函数:
- 线性函数是一次函数的别称,则非线性函数(即函数图像不是一条直线的函数)。非线性函数包括 指数函数、幂函数、对数函数、多项式函数等等基本初等函数以及他们组成的复合函数
- 激活函数时多层神经网络的基础,保证多层网络不退化成线性网络

-
不加激活函数时

-
由于线性模型的表达能力不够,激活函数 使得神经网络可以逼近其他的任何非线性函数,这样可以使得神经网络应用到更多非线性模型中

-
激活函数的种类
-
1.sigmoid - 会导致梯度消失
- sigmoid函数既有软饱和特性,在正负饱和区的梯度都接近于0,只在0附近有比较好的激活特性
- sigmoid导数值最大0.25,也就是反向传播过程中,每层至少有75%的损失,这使得当sigmoid被用在隐藏层的时候,会导致梯度消失(一般5层子内就会产生)
- 函数输出不以0为中心,也就是输出均值不为0,会导致参数更新效率减低
- sigmoid函数涉及指数运算,导致计算速度较慢

-
2.softmax 和 tanh

-
3.ReLu
- ReLU 是一个分段线性函数,因此是非线性函数
- ReLu 的发明是深度学习领域最重要的突破之一;
- ReLU 不存在梯度消失的问题
- ReLU 计算成本低(没有指数运算),收敛速度比sigmoid快6倍
- 函数输出不以0为中心,也就是输出的均值不为0,这样会导致参数更新效率降低
- 存在dead ReLU 问题(输入ReLU有负值时,ReLU输出为0,梯度在反向传播期间无法流动,导致权重不会更新)

-
4.Leaky ReLU 和ELU
- ReLU的变体
- 不存在 dead ReLU 问题

-
Swish
- 目前大模型普遍在用的激活函数
- 参数不变的情况下,将模型中ReLU替换为Swish,模型性能提升
- Swish无上界,不会出现梯度饱和
- Swish有下界,不会出现dead ReLU问题
- Swish处处连续可导

-
损失函数 - loss function
- 就是用来度量模型的预测值f(x)于真实值Y的差异程度(损失值)的运算函数,他是一个非负实值函数
- 损失函数仅用于模型训练阶段,得到损失值厚,通过反向传播来更新参数,从而减低预测值与真实值之间的损失值,从而提升模型性能
- 整个模型训练的过程,就是再通过不断更新参数,是的损失函数不断逼近全局最优点(全局最小值) - 很难
- 不同类型的任务会定义不同的损失函数,例如回归任务重的MAE、MSE,分类任务中的交叉熵损失等

-
损失函数类别
-
1.MSE 和 MAE
-
均方误差(mean squared error,MSE)也叫平方损失或L2损失,常用在最小二乘法中,他的思想是使得各个训练点得到最优拟合线的距离最小(平方和最小)

-
平均绝对误差(Mean Absolute Error,MAE)是所有单个观测值与算数平均值的绝对值的平均,也被称为L1 loss,常用于回归问题中

-
-
2.交叉熵损失
-
二分类
-
表达式中的:Yi为样本i的真实标签 - 要么为正=1, 负类=0
-
Pi表示样本i预测为正类的概率

-
案例

-
-
多分类
-
其中M为类别数量(如类别A、B、C。。。);Yic为符号函数,样本i真实类别等于 c 则为 1,否则为0;预测样本i属于类别c的预测概率

-
案例1

-
案例2
- 如下图:样本1的真实值是C、样本2的真实值是B、样本3的真实值是A,所以对应的真实值Yia(或Yib、或Yic) = 1


- 如下图:样本1的真实值是C、样本2的真实值是B、样本3的真实值是A,所以对应的真实值Yia(或Yib、或Yic) = 1
-
-

![[2025.2.23] 周记](https://img2023.cnblogs.com/blog/3480200/202502/3480200-20250223170430858-229479209.png)