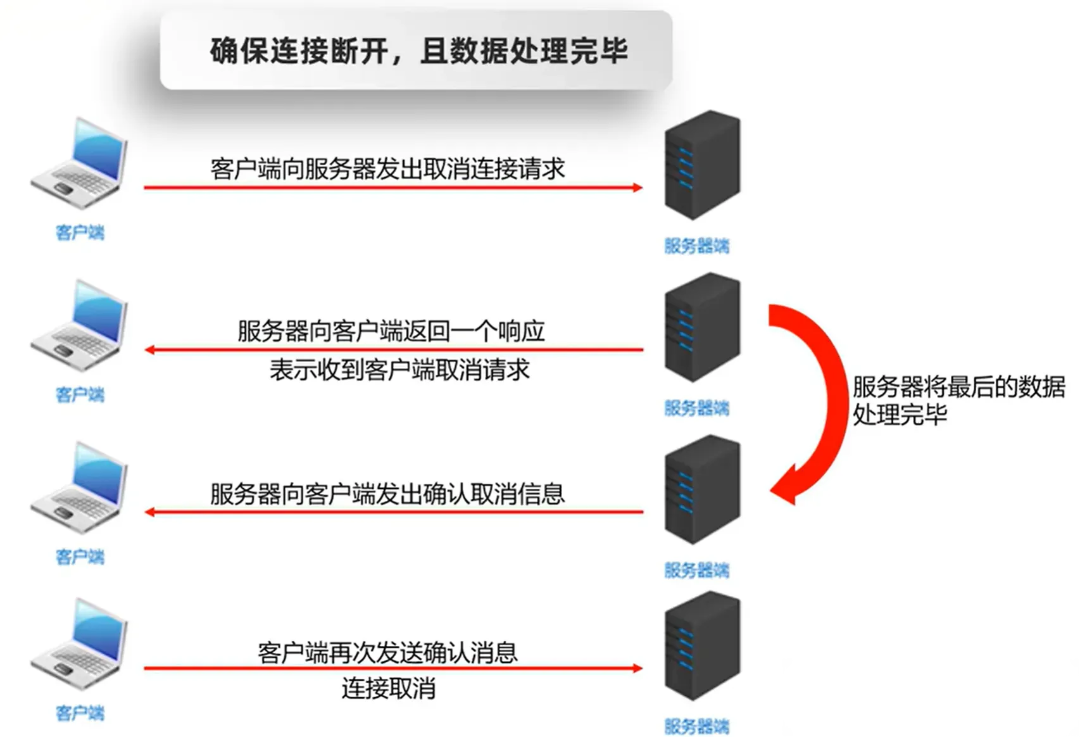
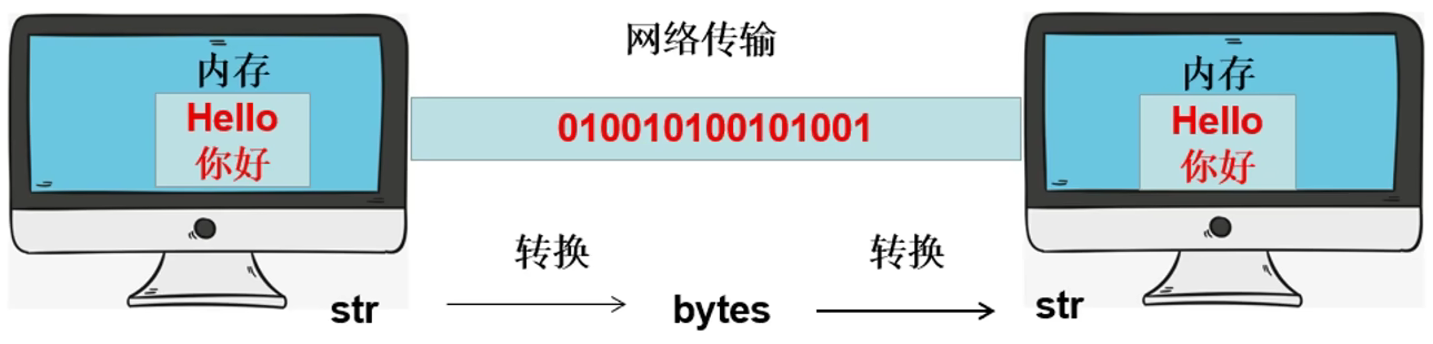
1. 字符串的编码及解码解释
-
str类型转换为bytes类型为编码
-
bytes类型转换为str类型为解码
2. 字符串的编码
-
str类型转换为bytes类型使用字符串encode()方法
-
语法格式:
-
str.encode(encodeing= 'utf8',errors='strict/ignore/replace')
-
出错方式:strict:严格的;报错。 ignore:忽略;replace:替换为?
-
3. 字符串的解码
-
bytes类型转换为bytes类型使用字符串decode()方法
-
语法格式:
-
bytes.decode(encodeing= 'utf8',errors='strict/ignore/replace')
-
出错方式:strict:严格的;报错。 ignore:忽略;replace:替换
-
4. 应用
s = '伟大的中国梦'
# 编码 str->bytes
code_utf = s.encode(errors='replace') # 编码方式默认为utf-8,utf-8中文占3个字节 出错方式,replace替换
# b'\xe4\xbc\x9f\xe5\xa4\xa7\xe7\x9a\x84\xe4\xb8\xad\xe5\x9b\xbd\xe6\xa2\xa6' 18个
print(code_utf)# 编码gbk
code_gbk = s.encode('gbk',errors='replace')
print(code_gbk) # 编码gbk 中文占2字节
# b'\xce\xb0\xb4\xf3\xb5\xc4\xd6\xd0\xb9\xfa\xc3\xce'#解码 bytes->str
bcode = code_utf.decode(errors='replace')
print(bcode) # 伟大的中国梦gbcode = code_gbk .decode('gbk',errors='replace')
print(gbcode) # 伟大的中国梦------------------------------------------------------# 编码中的出错问题
s2= '耶✌'
s0code_utf = s2.encode('gbk',errors='ignore')
print(s0code_utf) # b'\xd2\xae'
s1code_utf = s2.encode('gbk',errors='replace')
print(s1code_utf) # b'\xd2\xae?'
# s2code_utf = s2.encode('gbk',errors='strict')
# print(s2code_utf) # UnicodeEncodeError: 'gbk' codec can't encode character '\u270c'
# 解码
dcode= s0code_utf.decode('gbk',errors='replace')
print(dcode) # 耶
dcode= s1code_utf.decode('gbk',errors='replace')
print(dcode) # 耶?


![[2025.2.23] 周记](https://img2023.cnblogs.com/blog/3480200/202502/3480200-20250223170430858-229479209.png)