题目
题目链接
题目的主要信息:
- 给定一个链表的头节点,判读该链表是否为回文结构
- 回文结构即正序遍历与逆序遍历结果都是一样的,类似123321
- 空链表默认为回文结构
举一反三:
学习完本题的思路你可以解决如下题目:
BM4.合并有序链表
BM5.合并k个已排序的链表
BM6.判断链表中是否有环
BM7.链表中环的入口节点
BM8.链表中倒数最后k个节点
BM9.删除链表的倒数第n个节点
BM10.两个链表的第一个公共节点
BM14.链表的奇偶重排
方法一:数组复制反转法(前置知识)
思路:
即然回文结构正序遍历和逆序遍历结果都是一样的,我们是不是可以尝试将正序遍历的结果与逆序遍历的结果一一比较,如果都是对应的,那很巧了!它就是回文结构!
这道题看起来解决得如此之快,但是别高兴太早,链表可没有办法逆序遍历啊。链表由前一个节点的指针指向后一个节点,指针是单向的,只能从前面到后面,我们不能任意访问,也不能从后往前。但是,另一个容器数组,可以任意访问,我们把链表中的元素值取出来放入数组中,然后判断数组是不是回文结构,这不是一样的吗?
具体做法:
- step 1:遍历一次链表,将元素取出放入辅助数组中。
- step 2:准备另一个辅助数组,录入第一个数组的全部元素,再将其反转。
- step 3:依次遍历原数组与反转后的数组,若是元素都相等则是回文结构,只要遇到一个不同的就不是回文结构。
Java实现代码:
import java.util.*;
public class Solution {public boolean isPail (ListNode head) {ArrayList<Integer> nums = new ArrayList();//将链表元素取出一次放入数组while(head != null){ nums.add(head.val);head = head.next;}ArrayList<Integer> temp = new ArrayList();temp = (ArrayList<Integer>) nums.clone();//准备一个数组承接翻转之后的数组Collections.reverse(temp); for(int i = 0; i < nums.size(); i++){int x = nums.get(i);int y = temp.get(i);//正向遍历与反向遍历相同if(x != y) return false;}return true;}
}
C++实现代码:
class Solution {
public:bool isPail(ListNode* head) {vector<int> nums;//将链表元素取出一次放入数组while(head != NULL){ nums.push_back(head->val);head = head->next;}vector<int> temp = nums; //准备一个数组承接翻转之后的数组reverse(temp.begin(), temp.end()); for(int i = 0; i < nums.size(); i++){//正向遍历与反向遍历相同if(nums[i] != temp[i]) return false;}return true;}
};
Python代码实现:
class Solution:def isPail(self , head: ListNode) -> bool:nums = []#将链表元素取出一次放入数组while head: nums.append(head.val)head = head.nexttemp = nums.copy()#准备一个数组承接翻转之后的数组temp.reverse() for i in range(len(nums)):#正向遍历与反向遍历相同if nums[i] != temp[i]: return Falsereturn True
复杂度分析:
- 时间复杂度:\(O(n)\),其中\(n\)为链表的长度,遍历链表转化数组为\(O(n)\),反转数组为\(O(n)\),后续遍历两个数组为\(O(n)\)
- 空间复杂度:\(O(n)\),记录链表元素的辅助数组,及记录反转后数组
方法二:数组复制双指针(前置知识)
知识点:双指针
双指针指的是在遍历对象的过程中,不是普通的使用单个指针进行访问,而是使用两个指针(特殊情况甚至可以多个),两个指针或是同方向访问两个链表、或是同方向访问一个链表(快慢指针)、或是相反方向扫描(对撞指针),从而达到我们需要的目的。
思路:
既然方法一我们已经将链表的值放入了数组中,数组是可以按照下标直接访问的,那干啥还要傻乎乎地用另一个数组来表示反转后的数组呢?我们直接从后往前遍历与从前往后遍历一同比较,利用两个指针对撞访问,不就少了很多额外的时间了吗?
具体做法:
- step 1:遍历一次链表,将元素取出放入辅助数组中。
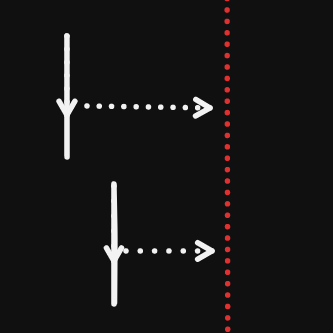
- step 2:使用下标访问,两个下标代表两个指针,两个指针分别从数组首尾开始遍历,左指针指向开头,从左到右,右指针指向数组末尾,从右到左,依次比较元素是否相同。
- step 3:如果有不一样,则不是回文结构。否则遍历到两个指针相遇就好了,因为左指针到了右半部分都是右指针走过的路,比较的值也是与之前相同的。
图示:

Java实现代码:
import java.util.*;
public class Solution {public boolean isPail (ListNode head) {ArrayList<Integer> nums = new ArrayList();//将链表元素取出一次放入数组while(head != null){ nums.add(head.val);head = head.next;}//双指针指向首尾int left = 0; int right = nums.size() - 1;//分别从首尾遍历,代表正序和逆序while(left <= right){ int x = nums.get(left);int y = nums.get(right);//如果不一致就是不为回文if(x != y) return false;left++;right--;}return true;}
}
C++实现代码:
class Solution {
public:bool isPail(ListNode* head) {vector<int> nums;//将链表元素取出一次放入数组while(head != NULL){ nums.push_back(head->val);head = head->next;}//双指针指向首尾int left = 0; int right = nums.size() - 1;//分别从首尾遍历,代表正序和逆序while(left <= right){ //如果不一致就是不为回文if(nums[left] != nums[right]) return false;left++;right--;}return true;}
};
Python实现代码:
class Solution:def isPail(self , head: ListNode) -> bool:nums = []#将链表元素取出一次放入数组while head: nums.append(head.val)head = head.next#双指针指向首尾left = 0 right = len(nums) - 1#分别从首尾遍历,代表正序和逆序while left <= right: #如果不一致就是不为回文if nums[left] != nums[right]: return Falseleft += 1right -= 1return True
复杂度分析:
- 时间复杂度:\(O(n)\),其中\(n\)为链表的长度,遍历链表转化数组为\(O(n)\),双指针遍历半个数组为\(O(n)\)
- 空间复杂度:\(O(n)\),记录链表元素的辅助数组
方法三:长度法找中点(推荐使用)
知识点:双指针
双指针指的是在遍历对象的过程中,不是普通的使用单个指针进行访问,而是使用两个指针(特殊情况甚至可以多个),两个指针或是同方向访问两个链表、或是同方向访问一个链表(快慢指针)、或是相反方向扫描(对撞指针),从而达到我们需要的目的。
思路:
在数组中,我们可以借助双指针,一个从前往遍历前一半数组,另一个从后往前遍历后一半数组,依次比较值。链表中如果我们要用这样的思想,左指针从前往后很容易,直接的链表的遍历就可以了。但是右指针是真的没有办法从尾巴往前走,要是链表后半段的指针是逆序的就好了。
怎么样能让链表后半段的指针反过来,将后半段链表整体反转不就行了吗?如果我们将后半段链表整体反转,那么相当于后半段就是从末尾指向中间,就可以实现后半段的逆序遍历——按照指针直接走就可以了。
while(head != null){//断开后序ListNode next = head.next; //指向前序head.next = prev; prev = head;head = next;
}
怎么找到中点,只要得到链表长度以后,遍历一半长度就可以找到中点。
具体做法:
- step 1:遍历链表,统计链表的长度。
- step 2:将长度除2,遍历这么多位置,找到链表的中点。
- step 3:从中点位置开始,对链表后半段进行反转。
- step 4:与方法二类似,双指针左指针指向链表开头,右指针指向链表尾,此时链表前半段是正常的,我们也可以正常遍历,但是链表后半段所有指针都被我们反转逆序,因此我们可以从尾节点往前遍历。
- step 5:依次比较对应位置的元素值是否相等。
图示:

Java实现代码:
import java.util.*;
public class Solution {//反转链表指针ListNode reverse(ListNode head) { //前序节点ListNode prev = null; while(head != null){//断开后序ListNode next = head.next; //指向前序head.next = prev; prev = head;head = next;}return prev;}public boolean isPail (ListNode head) {ListNode p = head;int n = 0;//找到链表长度while(p != null){ n++;p = p.next; }//中点n = n / 2; p = head;//遍历到中点位置while(n > 0){ p = p.next;n--;}//中点处反转p = reverse(p); ListNode q = head;while(p != null){//比较判断节点值是否相等if(p.val != q.val) return false;p = p.next;q = q.next;}return true;}
}
C++实现代码:
class Solution {
public://反转链表指针ListNode* reverse(ListNode* head) { //前序节点ListNode* prev = NULL; while(head != NULL){//断开后序ListNode* next = head->next; //指向前序head->next = prev; prev = head;head = next;}return prev;}bool isPail(ListNode* head) {ListNode* p = head;int n = 0;//找到链表长度while(p != NULL){ n++;p = p->next; }//中点n = n / 2; p = head;while(n > 0){p = p->next;n--;}//中点处反转p = reverse(p); ListNode* q = head;while(p != NULL){//比较判断节点值是否相等if(p->val != q->val) return false;p = p->next;q = q->next;}return true;}
};Python实现代码:
class Solution:#反转链表指针def reverse(self, head:ListNode): #前序节点prev = None while head:#断开后序next = head.next #指向前序head.next = prev prev = headhead = nextreturn prevdef isPail(self , head: ListNode) -> bool:p = headn = 0#找到链表长度while p : n += 1p = p.next#中点n = (int)(n / 2) p = headwhile n > 0:p = p.nextn -= 1#中点处反转p = self.reverse(p) q = headwhile p:#比较判断节点值是否相等if p.val != q.val: return Falsep = p.nextq = q.nextreturn True
复杂度分析:
- 时间复杂度:\(O(n)\),其中\(n\)为链表的长度,遍历链表找到长度为\(O(n)\),后续反转链表为\(O(n)\),然后再遍历两份半个链表
- 空间复杂度:\(O(1)\),常数级变量,没有额外辅助空间
方法四:双指针找中点(推荐使用)
思路:
上述方法三找中点,我们遍历整个链表找到长度,又遍历长度一半找中点位置。过程过于繁琐,我们想想能不能优化一下,一次性找到中点。
我们首先来看看中点的特征,一个链表的中点,距离链表开头是一半的长度,距离链表结尾也是一半的长度,那如果从链表首遍历到链表中点位置,另一个每次遍历两个节点的指针是不是就到了链表尾,那这时候我们的快慢双指针就登场了:
具体做法:
- step 1:慢指针每次走一个节点,快指针每次走两个节点,快指针到达链表尾的时候,慢指针刚好到了链表中点。
- step 2:从中点的位置,开始往后将后半段链表反转。
- step 3:按照方法三的思路,左右双指针,左指针从链表头往后遍历,右指针从链表尾往反转后的前遍历,依次比较遇到的值。
图示:

Java实现代码:
import java.util.*;
public class Solution {//反转链表指针ListNode reverse(ListNode head) { //前序节点ListNode prev = null; while(head != null){//断开后序ListNode next = head.next; //指向前序head.next = prev; prev = head;head = next;}return prev;}public boolean isPail (ListNode head) {//空链表直接为回文if(head == null) return true;//准备快慢双指针ListNode slow = head; ListNode fast = head;//双指针找中点while(fast != null && fast.next != null){ slow = slow.next;fast = fast.next.next;}//中点处反转slow = reverse(slow); fast = head;while(slow != null){ //比较判断节点值是否相等if(slow.val != fast.val) return false;fast = fast.next;slow = slow.next;}return true;}
}
C++实现代码:
class Solution {
public://反转链表指针ListNode* reverse(ListNode* head) { //前序节点ListNode* prev = NULL; while(head != NULL){//断开后序ListNode* next = head->next; //指向前序head->next = prev; prev = head;head = next;}return prev;}bool isPail(ListNode* head) {//空链表直接为回文if(head == NULL) return true;ListNode* slow = head;ListNode* fast = head;//双指针找中点while(fast != NULL && fast->next != NULL){ slow = slow->next;fast = fast->next->next;}//中点处反转slow = reverse(slow); fast = head;while(slow != NULL){ //比较判断节点值是否相等if(slow->val != fast->val) return false;fast = fast->next;slow = slow->next;}return true;}
};
Python实现代码:
class Solution:#反转链表指针def reverse(self, head:ListNode): #前序节点prev = None while head:#断开后序next = head.next #指向前序head.next = prev prev = headhead = nextreturn prevdef isPail(self , head: ListNode) -> bool:#空链表直接为回文if head == None: return True#准备快慢双指针slow = head fast = head#双指针找中点while fast and fast.next: slow = slow.nextfast = fast.next.next#中点处反转slow = self.reverse(slow) fast = headwhile slow:#比较判断节点值是否相等if slow.val != fast.val: return Falsefast = fast.nextslow = slow.nextreturn True
复杂度分析:
- 时间复杂度:\(O(n)\),其中\(n\)为链表的长度,双指针找到中点遍历半个链表,后续反转链表为\(O(n)\),然后再遍历两份半个链表
- 空间复杂度:\(O(1)\),常数级变量,没有额外辅助空间
方法五:栈逆序(扩展思路)
知识点:栈
栈是一种仅支持在表尾进行插入和删除操作的线性表,这一端被称为栈顶,另一端被称为栈底。元素入栈指的是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;元素出栈指的是从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
思路:
同样的,逆序访问我们不一定需要借助可以随机访问的数组,或者反转链表,我们还可以借助先进先出的栈:根据链表顺序入栈的元素,越在前面的就越在栈底,越在后面的就越在栈顶,因此后续从栈中弹出的元素,依次就是链表的逆序。
具体做法:
- step 1:遍历链表,将链表元素依次加入栈中。
- step 2:依次从栈中弹出元素值,和链表的顺序遍历比较,如果都是一一比较相同的值,那正好就是回文,否则就不是。
Java实现代码:
import java.util.*;
public class Solution {public boolean isPail (ListNode head) {ListNode p = head;Stack<Integer> s = new Stack();//辅助栈记录元素while(p != null){ s.push(p.val);p = p.next;}p = head;//正序遍历链表,从栈中弹出的内容是逆序的while(!s.isEmpty()){ //比较是否相同if(p.val != s.pop()) return false;p = p.next;}return true;}
}
C++实现代码:
class Solution {
public:bool isPail(ListNode* head) {ListNode* p = head;stack<int> s;//辅助栈记录元素while(p != NULL){ s.push(p->val);p = p->next;}p = head;//正序遍历链表,从栈中弹出的内容是逆序的while(!s.empty()){ //比较是否相同if(p->val != s.top()) return false;s.pop();p = p->next;}return true;}
};Python实现代码:
class Solution:def isPail(self, head: ListNode) -> bool:p = heads = []#辅助栈记录元素while p: s.append(p.val)p = p.nextp = head#正序遍历链表,从栈中弹出的内容是逆序的while len(s)!=0 : #比较是否相同if p.val != s.pop(): return Falsep = p.nextreturn True
复杂度分析:
- 时间复杂度:\(O(n)\),其中\(n\)为链表的长度,遍历链表入栈为\(O(n)\),后续再次遍历链表和栈
- 空间复杂度:\(O(n)\),记录链表元素的辅助栈长度和链表相同




![[汽车电子/车联网] CANoe](https://blog-static.cnblogs.com/files/johnnyzen/cnblogs-qq-group-qrcode.gif?t=1679679148)


