一,YOLOv10 解析
1.简介
近些年来,研究人员对 YOLO 的架构设计、优化目标、数据增强策略等进行了探索,取得了显著进展。然而,后处理对非极大值抑制(NMS)的依赖阻碍了 YOLO 的端到端部署,并对推理延迟产生不利影响。此外,YOLO 中各个组件的设计缺乏全面彻底的检查,导致明显的计算冗余并限制了模型的能力。
YOLOv10 的突破就在于从后处理和模型架构方面进一步提升了 YOLO 的性能 - 效率边界。
为此,研究团队首次提出了 YOLO 无 NMS 训练的一致双重分配(consistent dual assignment),这使得 YOLO 在性能和推理延迟方面有所改进。
研究团队为 YOLO 提出了整体效率 - 准确率驱动的模型设计策略,从效率和准确率两个角度全面优化 YOLO 的各个组件,大大降低了计算开销并增强了模型能力。
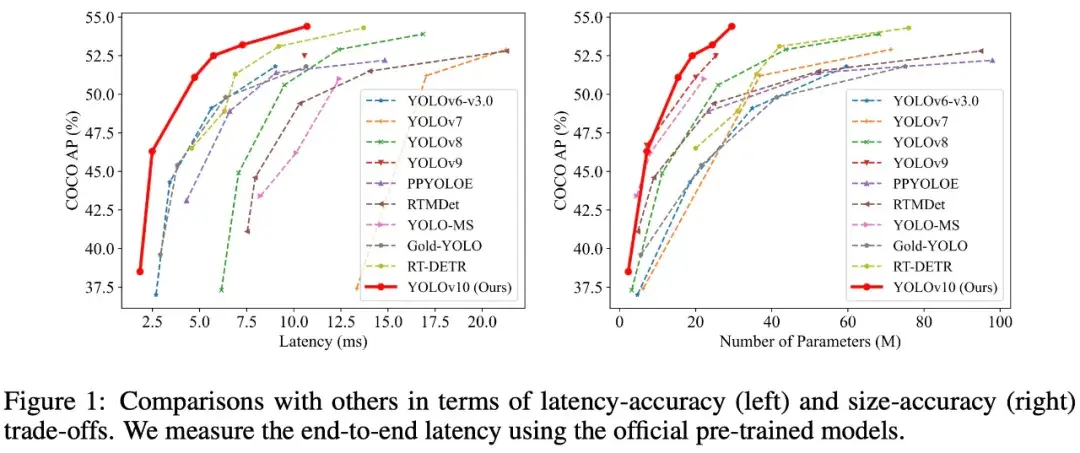
大量实验表明,YOLOv10 在各种模型规模上都实现了 SOTA 性能和效率。例如,YOLOv10-S 在 COCO 上的类似 AP 下比 RT-DETR-R18 快 1.8 倍,同时参数数量和 FLOP 大幅减少。与 YOLOv9-C 相比,在性能相同的情况下,YOLOv10-B 的延迟减少了 46%,参数减少了 25%。
2.方法介绍
为了实现整体效率 - 准确率驱动的模型设计,研究团队从效率、准确率两方面分别提出改进方法。
为了提高效率,该研究提出了轻量级分类 head、空间通道(spatial-channel)解耦下采样和排序指导的块设计,以减少明显的计算冗余并实现更高效的架构。
为了提高准确率,研究团队探索了大核卷积并提出了有效的部分自注意力(partial self-attention,PSA)模块来增强模型能力,在低成本下挖掘性能改进的潜力。基于这些方法,该团队成功实现了一系列不同规模的实时端到端检测器,即 YOLOv10-N / S / M / B / L / X。
3.用于无 NMS 训练的一致双重分配
在训练期间,YOLO 通常利用 TAL 为每个实例分配多个正样本。一对多的分配方式产生了丰富的监督信号,促进了优化并使模型实现了卓越的性能。
然而,这需要 YOLO 依赖于 NMS 后处理,这导致了部署时次优的推理效率。虽然之前的研究工作探索了一对一匹配来抑制冗余预测,但它们通常引入了额外的推理开销。
与一对多分配不同,一对一匹配对每个 ground truth 仅分配一个预测,避免 NMS 后处理。然而,这会导致弱监督,以至于准确率和收敛速度不理想。幸运的是,这种缺陷可以通过一对多分配来弥补。
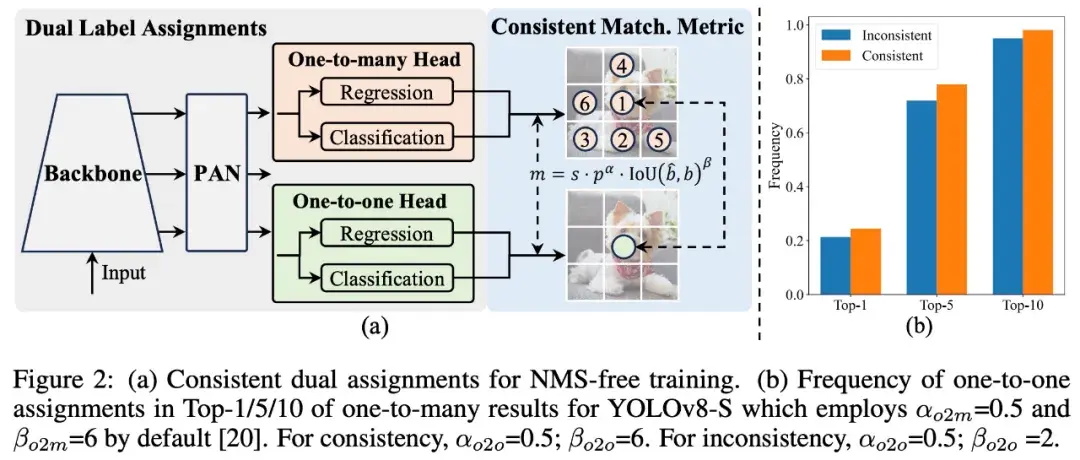
该研究提出的「双标签分配」结合了上述两种策略的优点。如下图所示,该研究为 YOLO 引入了另一个一对一 head。它保留了与原始一对多分支相同的结构并采用相同的优化目标,但利用一对一匹配来获取标签分配。在训练过程中,两个 head 联合优化,以提供丰富的监督;在推理过程中,YOLOv10 会丢弃一对多 head 并利用一对一 head 做出预测。这使得 YOLO 能够进行端到端部署,而不会产生任何额外的推理成本。
4.整体效率 - 准确率驱动的模型设计
除了后处理之外,YOLO 的模型架构也对效率 - 准确率权衡提出了巨大挑战。尽管之前的研究工作探索了各种设计策略,但仍然缺乏对 YOLO 中各种组件的全面检查。因此,模型架构表现出不可忽视的计算冗余和能力受限。
YOLO 中的组件包括 stem、下采样层、带有基本构建块的阶段和 head。作者主要对以下三个部分执行效率驱动的模型设计。
- 轻量级分类 head。
- 空间通道解耦下采样。
- 排序指导的模块设计。
二,yolov10 训练
1.下载模型训练代码。
github 网址:https://github.com/THU-MIG/yolov10
拉取压缩包如下图
2.搭建 conda 训练环境
conda activate yolov10 #先激活自己的虚拟环境
pip install -r requirements.txt #一键安装相应的安装包
3.设置数据集
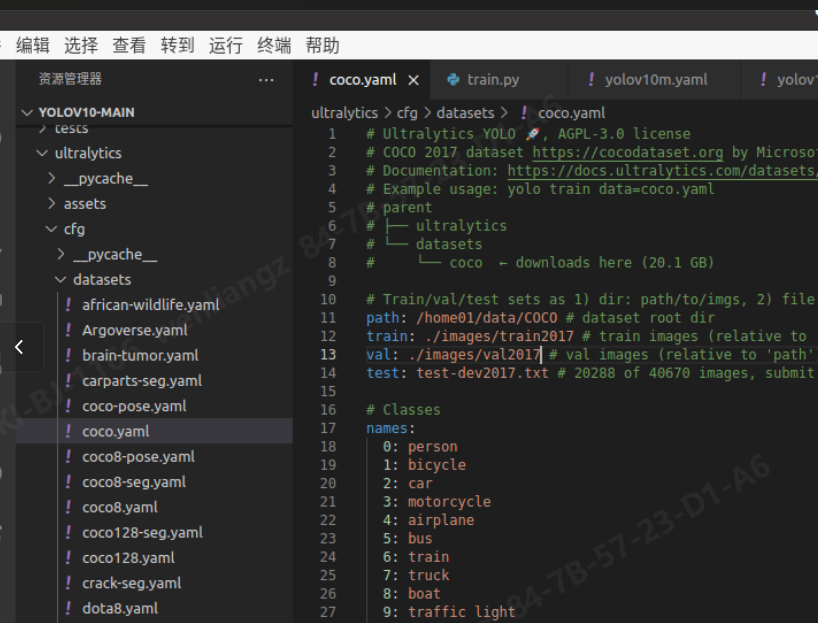
我使用的是 coco 数据集,如图
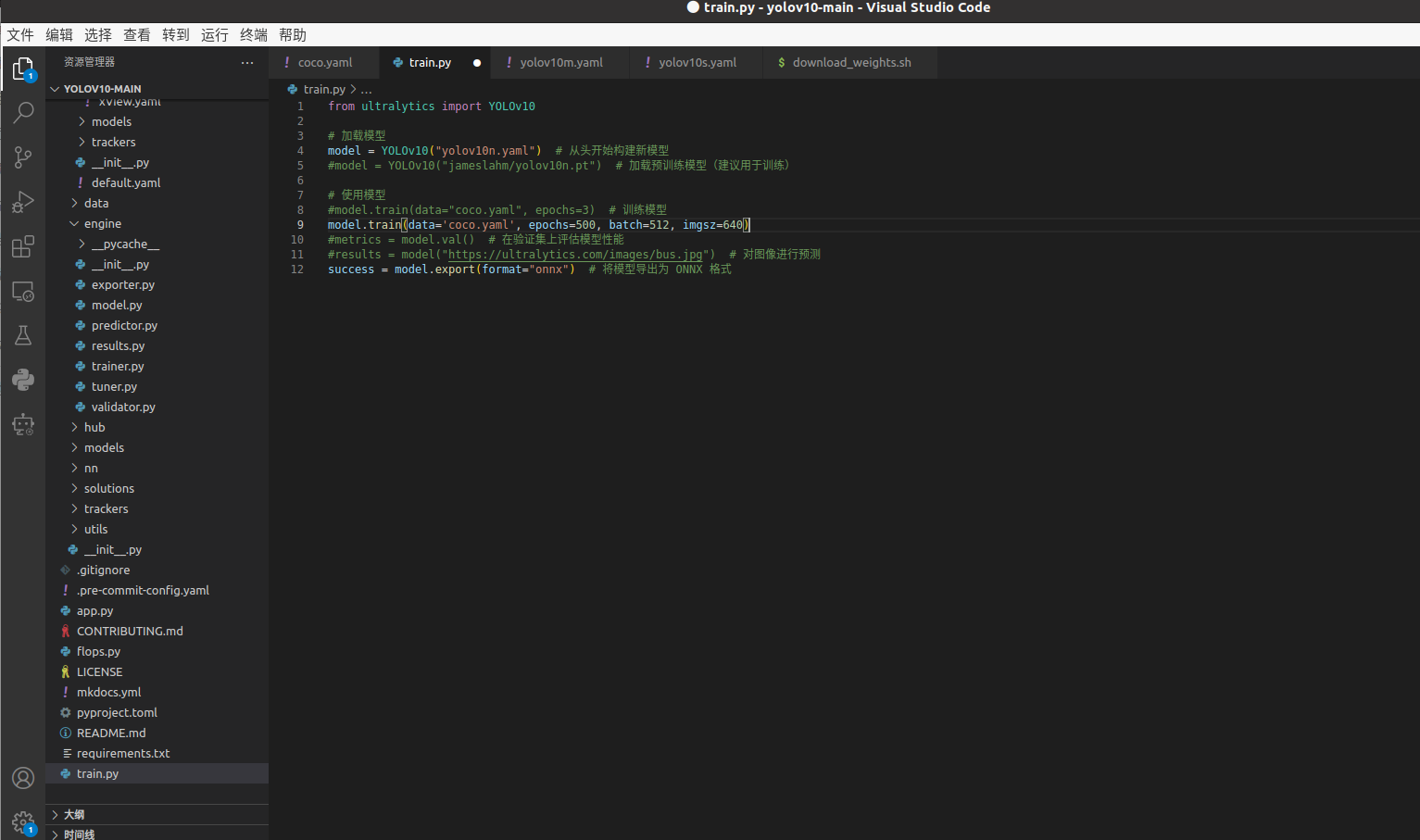
4.模型训练,代码如下图。
5.训练之后转 onnx 模型。
三,yolov10 模型量化
使用的是地平线 征程 6 的 docker,版本是 v3.0.22
1.首先进行模型检查。
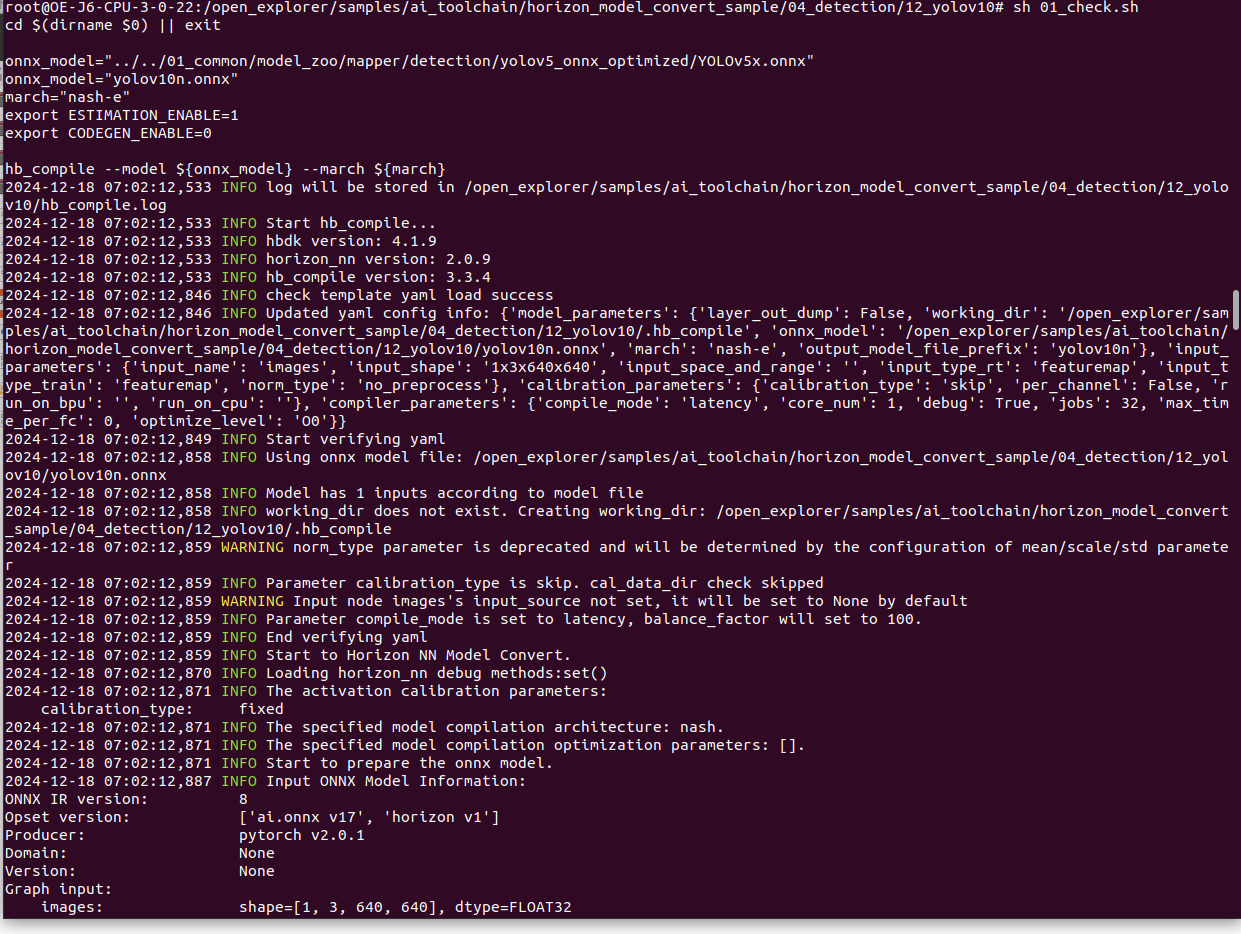
在浮点模型准备好之后,我们建议先进行快速的模型验证,以确保其符合计算平台的支持约束。启动样例里面的脚本,修改一下路径即可,如下图。如果模型验证不通过,请根据终端打印或在当前路径下生成的日志文件确认报错信息和修改建议。
2.准备校准数据集。
PTQ 方案的校准数据一般是从训练集或验证集中筛选 100 份左右(可适当增减)的典型数据,并应避免非常少见的异常样本, 如纯色图片、不含任何检测或分类目标的图片等。筛选出的校准数据还需进行与模型 inference 前一致的预处理操作, 处理后保持与原始模型一样的数据类型、layout 和尺寸。
对于校准数据的预处理,地平线建议直接参考示例代码进行修改使用,preprocess.py 文件中 的 calibration_transformers 函数的包含了其校准数据的前处理 transformers,处理完的校准数据与其 yaml 配置文件保持一致,
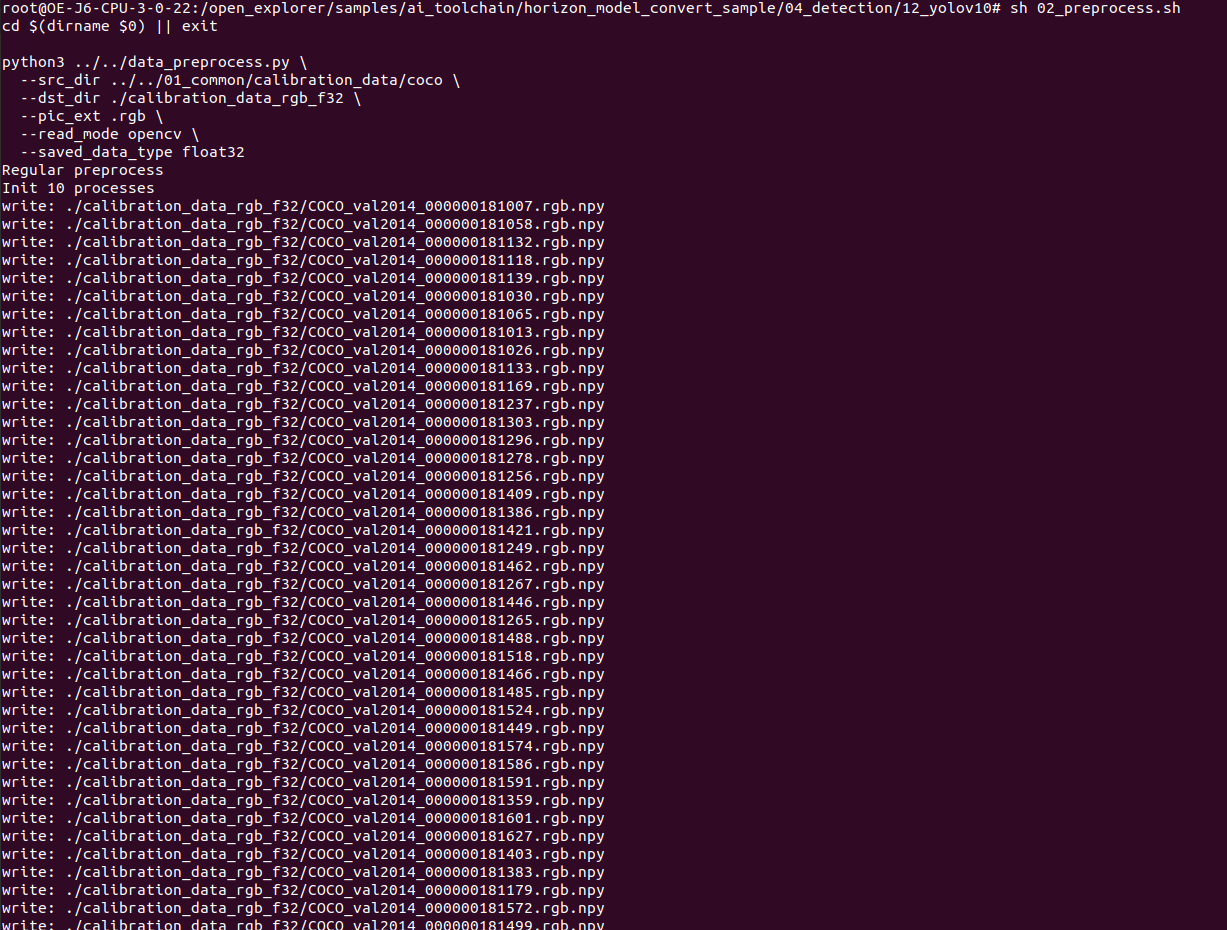
3.编辑 yaml 文件进行模型量化编译
Yaml 配置文件共包含 4 个必选参数组和 1 个可选参数组, 每个参数组下也区分必选和可选参数(可选参数默认隐藏), 具体要求和填写方式可以参考 OE 文档里的具体章节。
准备完校准数据和 yaml 配置文件后,即可一步命令完成模型解析、图优化、校准、量化、编译的全流程转换。
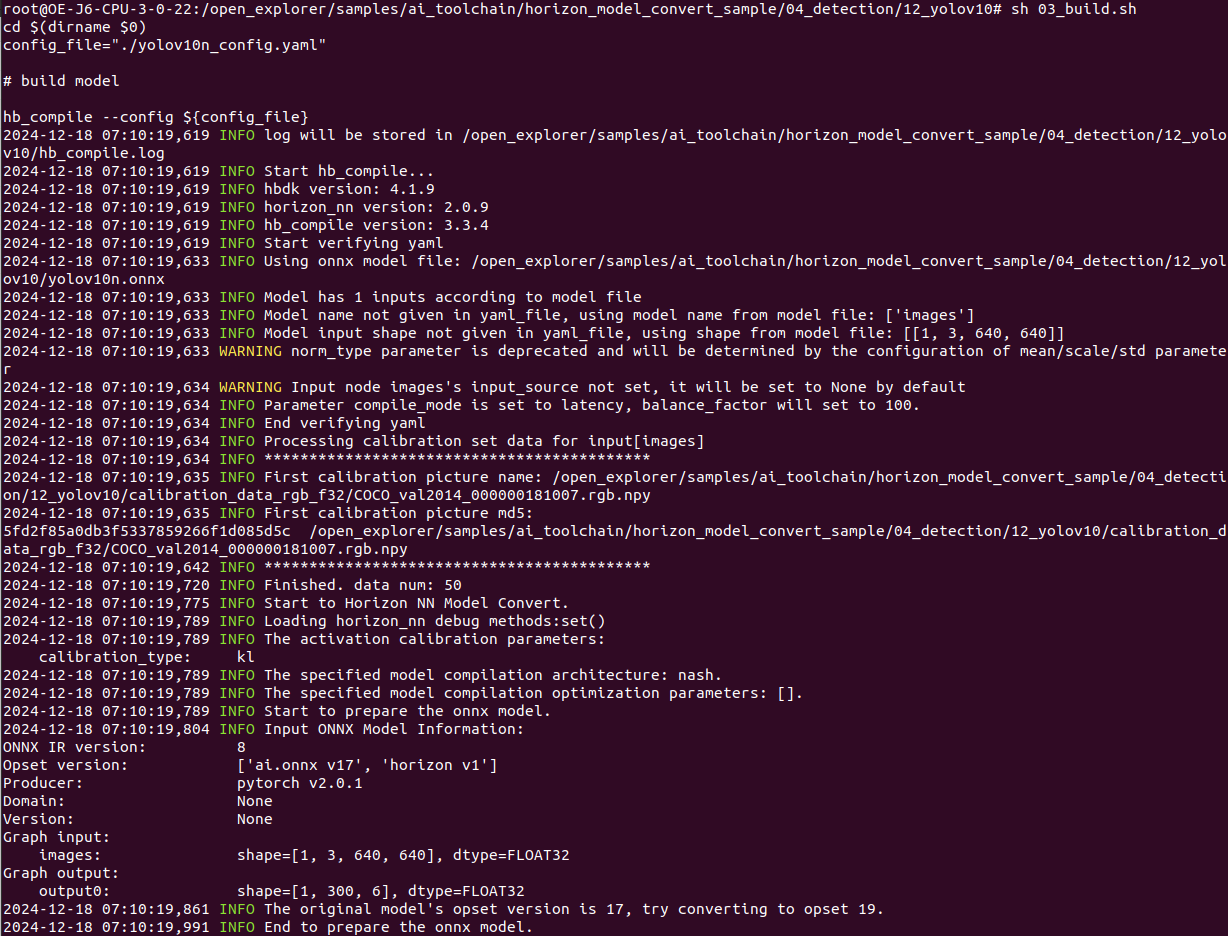
4.编译模型结果查看
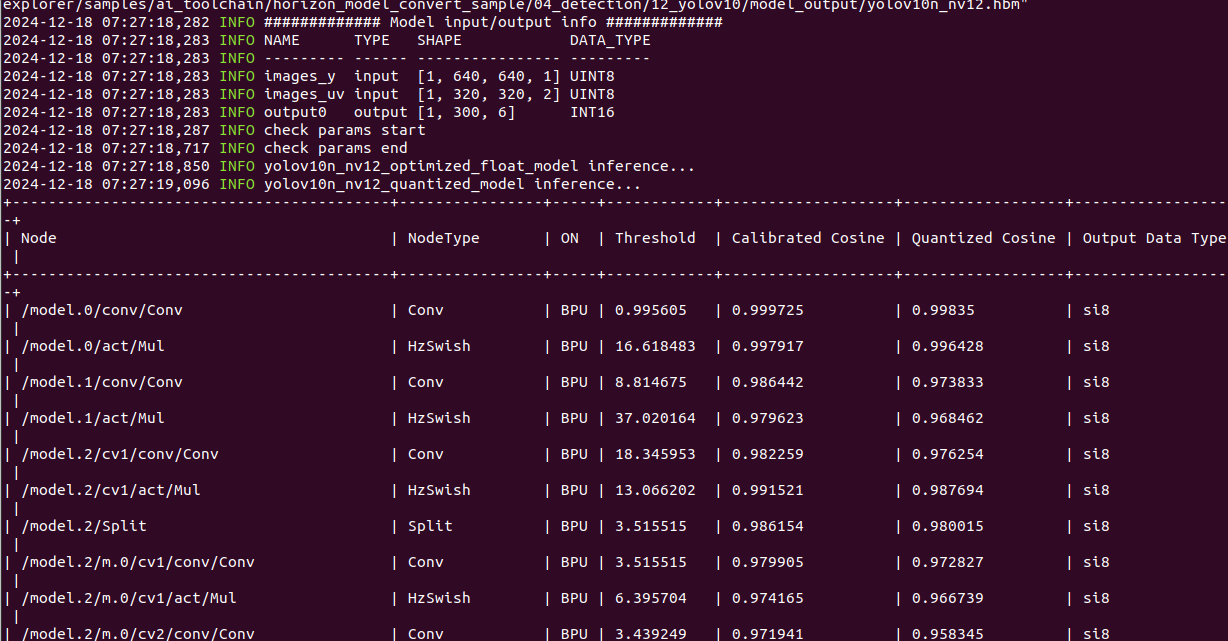
转换完成后,会在 yaml 文件配置的路径下保存各阶段流程产出的模型文件和编译器预估的模型 BPU 部分的静态性能评估文件。
各个算子余弦相似度如图
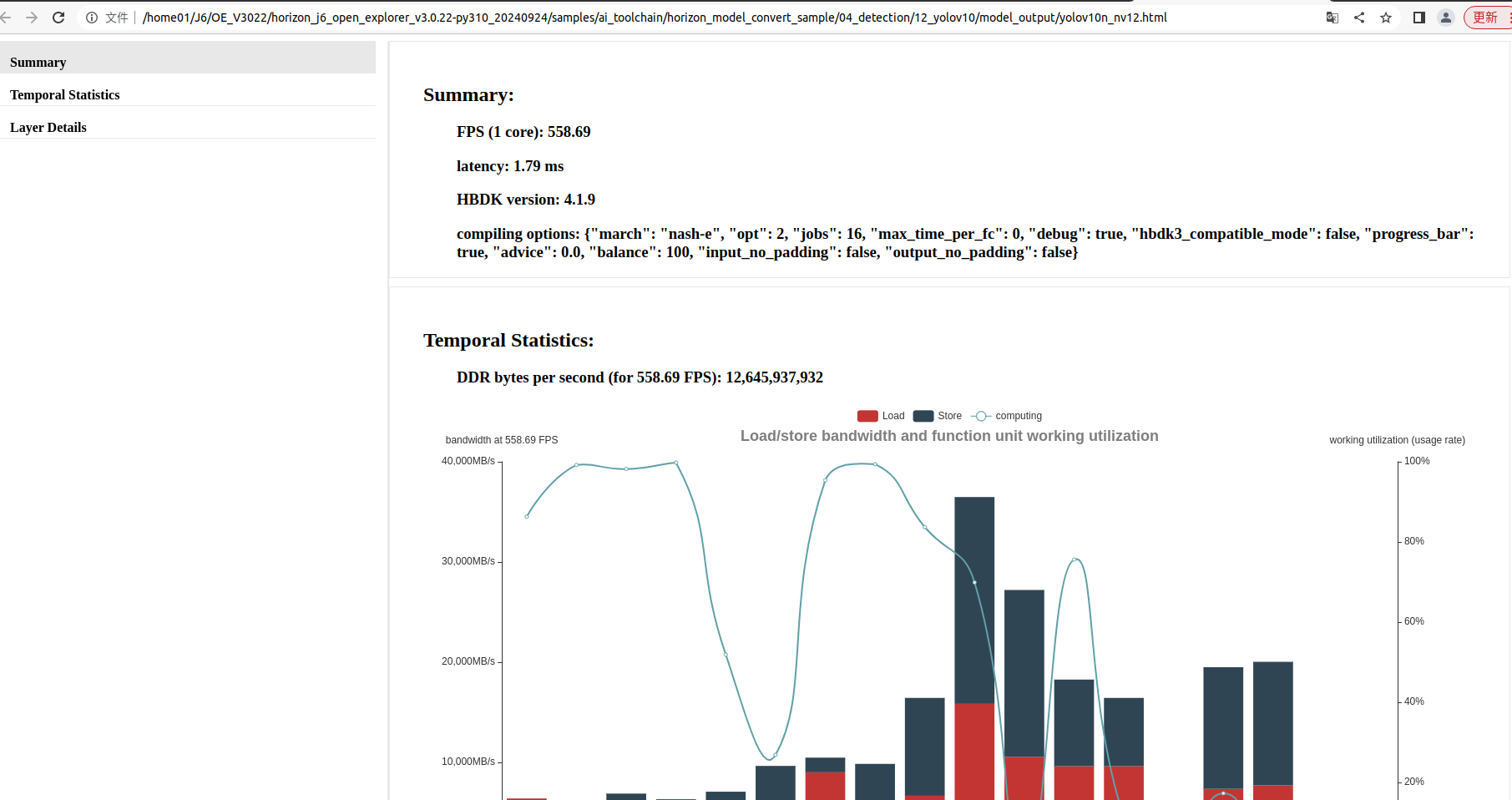
生成包含模型静态性能预估的 html 和 json 文件,两者内容相同, 但 html 文件的可读性更好,如下图。



![redis - [06] redis-benchmark性能测试](https://img2024.cnblogs.com/blog/1729889/202502/1729889-20250225203440614-1167673726.png)