5. python re
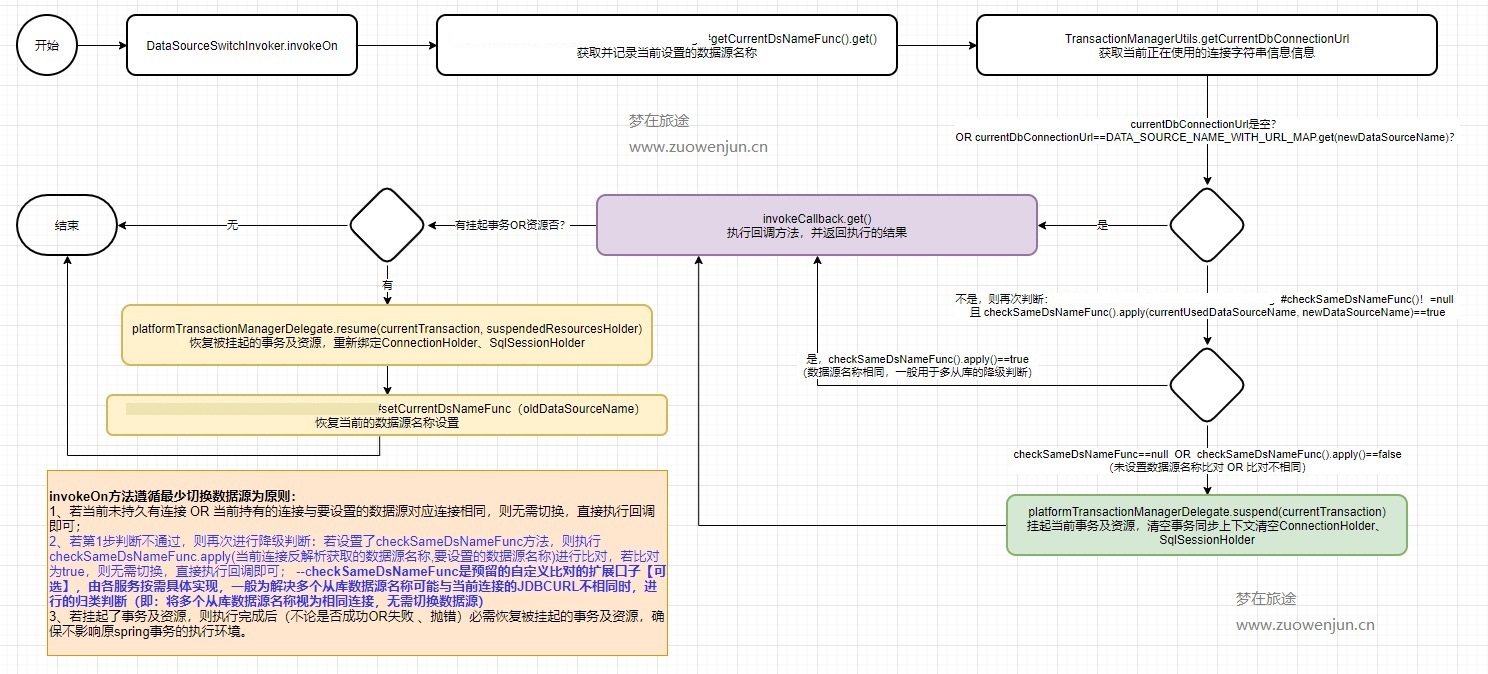
5.1 正则表达式模式
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re | 精确匹配 n 个前面表达式。例如, o{2} 不能匹配 "Bob" 中的 "o",但是能匹配 "food" 中的两个 o。 |
| re | 匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。"o{1,}" 等价于 "o+"。"o{0,}" 则等价于 "o*"。 |
| re | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | 对正则表达式分组并记住匹配的文本 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字及下划线 |
| \s | 匹配任意空白字符,等价于 [ \t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
5.2 匹配方法
1)findall()
-
re.findall(pattern,string,flags=0) 该方法返回列表形式
- pattern指定匹配的正则表达式,string指定要匹配的字符串,flags是标志位(用于控制正则表达式的匹配模式)
In [8]: print(re.findall('com','163.com.com.com')) ['com', 'com', 'com']
2)match()
-
re.match() 参数与findall相同,该方法从字符串的起始位置匹配,若匹配成功返回match类型对象
- 该方法只能使用group(num)或groups()方法获取比配的字符串
In [1]: import reIn [2]: print(re.match('\d+','163.com')) <re.Match object; span=(0, 3), match='163'>In [3]: print(re.match('\d+','163.com').group()) 163In [4]: print(re.match('com','163.com')) #不是起始位置 None
3)search()
-
re.search() 与match方法用法基本相同,不同的是search()方法可在任意位置匹配,匹配成功返回第一个结果,结果也是match()类型
In [5]: print(re.search('com','163.com')) <re.Match object; span=(4, 7), match='com'>In [6]: print(re.search('com','163.com').group()) comIn [7]: print(re.search('com','163.com.com').group()) #只返回第一个匹配的结果 com
5.3 替换方法
sub()
- re.sub(pattern,repl,string,count=0,flags=0) 和字符串的replace()功能类似,用于替换字符串中的匹配项
- repl参数指定替换的字符串,也可以是一个函数;count参数指定匹配后替换的最大次数,默认值0
In [9]: date_str="start 05/09/2022 end 06/26/2022"In [10]: re.sub(r'(\d+)/(\d+)/(\d+)',r'\3-\1-\2',date_str)
Out[10]: 'start 2022-05-09 end 2022-06-26'
5.4 分割方法
split()
- re.split(pattern,string[,maxsplit=0,flags=0]) 和字符串的split()功能类似
5.5 编译正则表达式的方法
re.complie()
- re.complie()方法用来编译正则表达式,生成一个正则表达式对象,供findall()、match()、search()等方法使用
- “一处编译,多处使用”,编译的正则表达式比非编译的执行速度更快,适合大量文本的处理。
In [1]: import reIn [2]: re_obj=re.compile('[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}')In [3]: re_obj.search('inet 172.26.224.66/20 metric 100 brd 172.26.239.255 scope global dynamic eth0').group()
Out[3]: '172.26.224.66'