本文介绍了RNN循环神经网络的基本概念 和 各种神经网络(DNN、CNN、RNN)的对比,最后介绍了如何基于RNN来做时序预测的案例。
本文介绍了RNN循环神经网络的基本概念 和 各种神经网络(DNN、CNN、RNN)的对比,最后介绍了如何基于RNN来做时序预测的案例。大家好,我是Edison。
最近入坑黄佳老师的《AI应用实战课》,记录下我的学习之旅,也算是总结回顾。
今天是我们的第11站,一起了解RNN循环神经网络的基本概念 以及 通过RNN来做时序预测的案例。
RNN循环神经网络介绍
RNN(循环神经网络)是一种专门用于处理序列数据的神经网络架构。与传统的神经网络不同,RNN具有记忆能力,能够捕捉序列数据中的时间依赖关系。
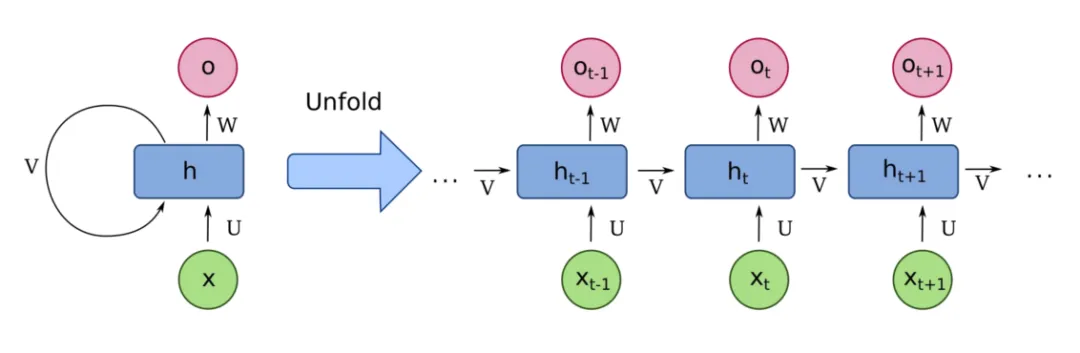
我们以一个例子来说RNN,有多个学生站成了一排,老师给第一个学生一个纸条,上面写着一句话,然后这个学生需要理解纸条上的第一个字的内容,然后再将纸条传给下一个学生,下一个学生理解第二个字的内容,然后再传给第三个学生理解第三个字的内容,以此类推不断往后传。与此同时,每个学生还有一个自己的笔记本,记录着自己对自己需要理解的那个字的理解,但可能并不是第一个字的真实内容,这个笔记本也会从第一个学生传到后续的学生。因此,从第二个学生开始,就有两条信息来源,一条是老师给的纸条自己需要去理解自己负责的那块内容,另一条是前面同学传来的笔记本可以去参考上一个同学给到的一些总结的隐藏信息,直到将这条纸条上的这句话理解完毕,再开始下一个纸条的理解传递。
从上面的解释看出,RNN对于每个序列在做循环处理,并且具有记忆功能,通过这种方式来捕捉序列模式和依赖关系。
RNN经常用于下列场景:
-
时间序列预测:例如股票市场预测、气象预测、流量分析等;
-
自然语言处理:例如文本生成、情感分析、机器翻译等;
-
语音识别:将语音信号转换成文本,广泛用于语音助手、转写工具等;
-
视频分析:处理视频数据中的连续帧,进行动作识别、事件检测等;
RNN的几种变体
主要的RNN变体有以下几种:
(1)Simple RNN
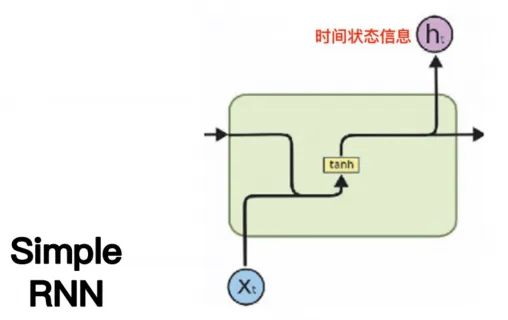
最原始的版本,它里面有一个时间状态信息作为短期记忆。它存在的问题是短期记忆,记不住太长的东西,处理到后面会把前面的内容忘记了。
(2)LSTM
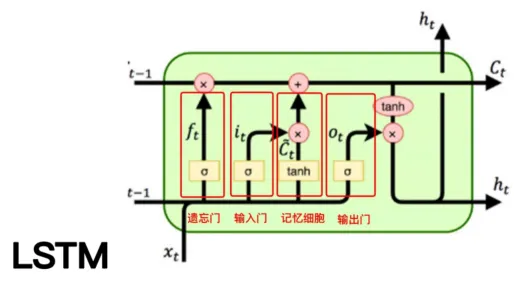
LSTM就解决了一部分短期记忆的问题,当然它的设计也复杂得多。但是它也没有完美的解决短期记忆问题,直到后期Transformer的自注意力机制出现,才把这个问题真正地解决。
(3)GRU
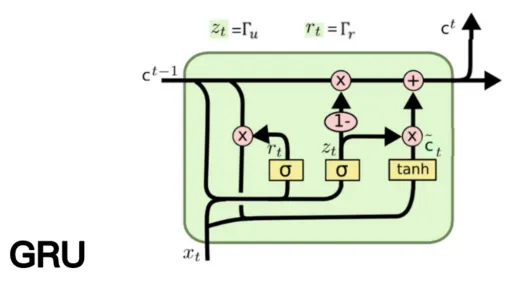
它解决了Simple RNN的问题,又比LSTM的设计简单一些,算是一个折中的方案。
各种神经网络的比较
(1)DNN(深度神经网络)
场景:
- 结构化数据的分类和回归问题
- 一些基本的图像识别任务
优势:对于非序列数据,DNN可以是一个良好的起点。
(2)RNN(循环神经网络)
场景:
- 时间序列预测
- 语音识别
- 语言模型和文本生成
- 机器翻译
优势:RNN设计用来捕捉时间或序列数据中的依赖关系,例如给定之前的单词或时间步,预测下一个单词或时间步的值。注意:需要注意RNN可能会遇到长序列的梯度消失或梯度爆炸的问题。
(3)CNN(卷积神经网络)
场景:
- 图像分类、对象检测和图像生成
- 语音识别和一些文本分类任务
优势:CNN可以捕捉到输入数据的局部特征,并且具有参数共享的特性,这使得它非常适合处理图像和其他具有空间或时间连续性的数据。
RNN做时序预测案例
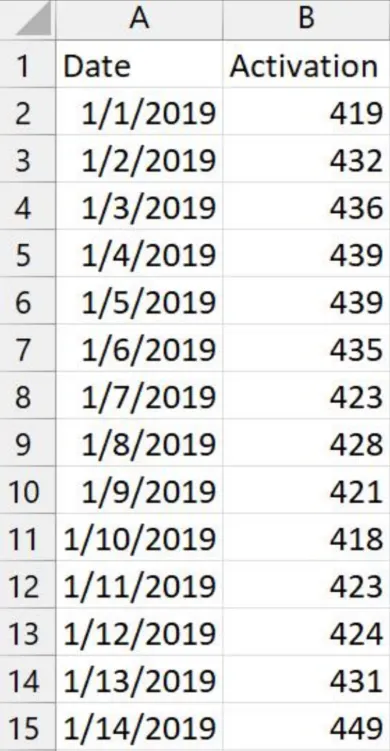
问题背景:
-
某App记录了过去两年每天的用户注册人数数据
问题目标:
-
根据历史数据,预测后续一段时间的用户注册数?
RNN做时序预测代码实战
Step1 读取数据并做归一化处理
# 导入所需库 import numpy as np import pandas as pd import torch import torch.nn as nn import torch.optim as optim from torch.autograd import Variabledf_app = pd.read_csv('app-user-activiation-data.csv', index_col='Date', parse_dates=['Date']) #导入数据 # 按照2020年10月1日为界拆分数据集 Train = df_app[:'2020-09-30'].iloc[:,0:1].values #训练集 Test = df_app['2020-10-01':].iloc[:,0:1].values #测试集 from sklearn.preprocessing import MinMaxScaler #导入归一化缩放器 Scaler = MinMaxScaler(feature_range=(0,1)) #创建缩放器 Train = Scaler.fit_transform(Train) #拟合缩放器并对训练集进行归一化 # 对测试数据进行归一化处理 Test = Scaler.transform(Test)
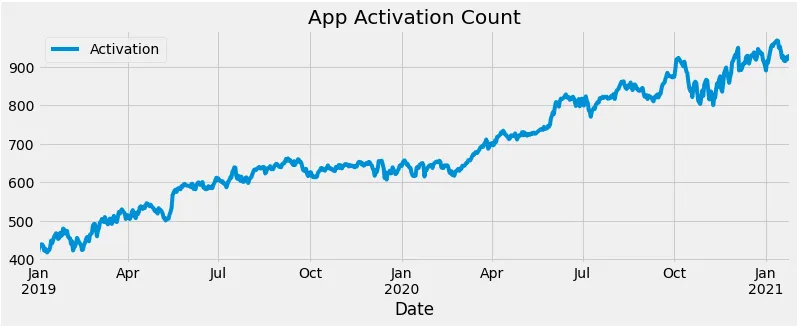
然后,借助matplotlib绘制用户注册人数图:
import matplotlib.pyplot as plt #导入matplotlib.pyplot plt.style.use('fivethirtyeight') #设定绘图风格 df_app["Activation"].plot(figsize=(12,4),legend=True) #绘制激活数 plt.title('App Activation Count') #图题 plt.show() #绘图
绘制出来的图如下所示:
Step2 将数据集转化为序列 和 张量
为了能够将数据集转化为PyTorch可以识别的内容,需要对数据集做时序转换 以及 张量转换。
# 创建一个函数,将数据集转化为时间序列格式 def sliding_windows(data, seq_length):x = []y = []for i in range(len(data)-seq_length):_x = data[i:(i+seq_length)]_y = data[i+seq_length]x.append(_x)y.append(_y)return np.array(x),np.array(y) # 设定窗口大小 seq_length = 4 x_train, y_train = sliding_windows(Train, seq_length) # 使用滑动窗口为测试数据创建特征和标签 x_test, y_test = sliding_windows(Test, seq_length) # 将数据转化为torch张量 testX = Variable(torch.Tensor(np.array(x_test))) testY = Variable(torch.Tensor(np.array(y_test)))
Step3 设置模型参数 及 定义RNN
# 设置模型参数 input_size = 1 hidden_size = 64 num_layers = 1 output_size = 1class RNN(nn.Module):def __init__(self, input_size, hidden_size, num_layers, output_size):super(RNN, self).__init__()self.hidden_size = hidden_size# RNN层self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)# 全连接层,用于输出self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):# 初始化隐状态h0 = Variable(torch.zeros(num_layers, x.size(0), self.hidden_size))# 前向传播RNNout, _ = self.rnn(x, h0)# 解码RNN的最后一个隐藏层的输出out = self.fc(out[:, -1, :])return out
Step4 创建模型 和 训练模型
# 创建模型 rnn = RNN(input_size, hidden_size, num_layers, output_size) # 定义损失函数和优化器 criterion = torch.nn.MSELoss() # 均方误差 optimizer = torch.optim.Adam(rnn.parameters(), lr=0.01) # Adam优化器 # 将数据转化为torch张量 trainX = Variable(torch.Tensor(np.array(x_train))) trainY = Variable(torch.Tensor(np.array(y_train))) # 训练模型 num_epochs = 100 for epoch in range(num_epochs):outputs = rnn(trainX)optimizer.zero_grad()# 计算损失loss = criterion(outputs, trainY)loss.backward()optimizer.step()if epoch % 10 == 0:print("Epoch: %d, loss: %1.5f" % (epoch, loss.item()))
这个案例的数据集很小,也不涉及感知类的例如图片、音频或视频之类的,所以我们直接在CPU上做训练即可。打印出来的每一轮的损失为:
Epoch: 0, loss: 0.45516
Epoch: 10, loss: 0.02038
Epoch: 20, loss: 0.00982
Epoch: 30, loss: 0.00167
Epoch: 40, loss: 0.00174
Epoch: 50, loss: 0.00089
Epoch: 60, loss: 0.00058
Epoch: 70, loss: 0.00056
Epoch: 80, loss: 0.00052
Epoch: 90, loss: 0.00049
Step5 测试模型
# 使用训练好的模型进行预测 rnn.eval() # 设置模型为评估模式 test_outputs = rnn(testX) # 将预测结果逆归一化 test_outputs = test_outputs.data.numpy() test_outputs = Scaler.inverse_transform(test_outputs) # 逆归一化 # 真实测试标签逆归一化 y_test_actual = Scaler.inverse_transform(y_test) # 输出预测和真实结果 for i in range(len(y_test)):print(f"Date: {df_app['2020-10-01':].index[i+seq_length]}, Actual Activation: {y_test_actual[i][0]}, Predicted Activation: {test_outputs[i][0]}")
打印出来的真实值 和 预测值如下:
Date: 2020-10-05 00:00:00, Actual Activation: 923.0, Predicted Activation: 885.0889282226562 Date: 2020-10-06 00:00:00, Actual Activation: 919.0000000000001, Predicted Activation: 893.8333129882812 Date: 2020-10-07 00:00:00, Actual Activation: 915.0, Predicted Activation: 898.3600463867188 Date: 2020-10-08 00:00:00, Actual Activation: 910.0000000000001, Predicted Activation: 896.8088989257812 Date: 2020-10-09 00:00:00, Actual Activation: 905.0000000000001, Predicted Activation: 895.2501220703125 Date: 2020-10-10 00:00:00, Actual Activation: 901.0, Predicted Activation: 891.626953125 Date: 2020-10-11 00:00:00, Actual Activation: 913.0000000000001, Predicted Activation: 888.2245483398438 Date: 2020-10-12 00:00:00, Actual Activation: 900.0, Predicted Activation: 890.2631225585938 Date: 2020-10-13 00:00:00, Actual Activation: 888.0000000000001, Predicted Activation: 885.708984375 Date: 2020-10-14 00:00:00, Actual Activation: 883.0, Predicted Activation: 880.345458984375 Date: 2020-10-15 00:00:00, Actual Activation: 861.0, Predicted Activation: 878.3155517578125 Date: 2020-10-16 00:00:00, Actual Activation: 844.0, Predicted Activation: 865.739013671875 Date: 2020-10-17 00:00:00, Actual Activation: 837.0, Predicted Activation: 853.5955810546875 Date: 2020-10-18 00:00:00, Actual Activation: 841.0, Predicted Activation: 845.1204223632812 Date: 2020-10-19 00:00:00, Actual Activation: 821.0, Predicted Activation: 838.4027709960938 Date: 2020-10-20 00:00:00, Actual Activation: 843.0, Predicted Activation: 826.8444213867188 Date: 2020-10-21 00:00:00, Actual Activation: 857.0, Predicted Activation: 830.8392333984375 Date: 2020-10-22 00:00:00, Actual Activation: 861.0, Predicted Activation: 837.3353881835938 Date: 2020-10-23 00:00:00, Actual Activation: 858.0, Predicted Activation: 838.6307983398438 Date: 2020-10-24 00:00:00, Actual Activation: 832.0, Predicted Activation: 845.0518798828125 Date: 2020-10-25 00:00:00, Actual Activation: 811.0, Predicted Activation: 839.138427734375 Date: 2020-10-26 00:00:00, Actual Activation: 807.0, Predicted Activation: 828.6616821289062 Date: 2020-10-27 00:00:00, Actual Activation: 803.0, Predicted Activation: 820.3754272460938 Date: 2020-10-28 00:00:00, Actual Activation: 821.0, Predicted Activation: 809.3426513671875 Date: 2020-10-29 00:00:00, Actual Activation: 838.0, Predicted Activation: 809.6136474609375 ...Date: 2021-01-22 00:00:00, Actual Activation: 925.0000000000001, Predicted Activation: 897.9528198242188 Date: 2021-01-23 00:00:00, Actual Activation: 926.0, Predicted Activation: 898.5119018554688 Date: 2021-01-24 00:00:00, Actual Activation: 920.0, Predicted Activation: 899.7281494140625 Date: 2021-01-25 00:00:00, Actual Activation: 932.0, Predicted Activation: 899.1580200195312
光这样看不太直观,绘制一个对比图:
# 定义绘图函数 def plot_predictions(test,predicted):plt.plot(test, color='red',label='Real Count') #真值plt.plot(predicted, color='blue',label='Predicted Count') #预测值plt.title('Flower App Activation Prediction') #图题plt.xlabel('Time') #X轴时间plt.ylabel('Flower App Activation Count') #Y轴激活数plt.legend() #图例plt.show() #绘图 plot_predictions(y_test_actual,test_outputs) #绘图
绘制出来的对比图如下所示:

可以看到,预测值和真实值还是存在一定的差距。
Step6 计算性能
这里,我们计算一下MSE损失值 和 R平方分数:
import math #导入数学函数 from sklearn.metrics import mean_squared_errordef return_rmse(test,predicted): #定义均方损失函数rmse = math.sqrt(mean_squared_error(test, predicted)) #均方损失print("MSE损失值 {}".format(rmse)) return_rmse(y_test_actual, test_outputs)
MSE损失值 25.51237936695477
from sklearn.metrics import r2_scorer2 = r2_score(y_test_actual, test_outputs) print(f"R2 Score: {r2}")
R2 Score: 0.6570994936886689
小结
本文介绍了RNN循环神经网络的基本概念 和 各种神经网络(DNN、CNN、RNN)的对比,最后介绍了如何基于RNN来做时序预测的案例。
推荐学习
黄佳,《AI应用实战课》(课程)

黄佳,《图解GPT:大模型是如何构建的》(图书)
黄佳,《动手做AI Agent》(图书)

作者:周旭龙
出处:https://edisonchou.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。