探秘Transformer之(8)--- 位置编码
- 探秘Transformer之(8)--- 位置编码
- 0x00 概述
- 0x01 问题
- 1.1 词序的重要性
- 1.2 Transformer架构的缺陷
- 位置不变性
- 证明
- 查询矩阵的变化
- 注意力矩阵的变化
- 注意力分数的变化
- 最终结果
- 后果
- 1.3 解决思路
- 1.4 应具备的性质
- 0x02 编码方案演化
- 2.1 整型数字位置编码
- 2.2 乘法表示
- 2.3 归一化
- 2.4 二进制位置编码
- 2.5 需求拓展
- 2.6 三角函数编码
- 性质
- 定义
- 编码方式
- 公式解读
- 具体样例
- 优点
- 0x03 三角函数编码思路分析
- 3.1 作者的话
- 3.2 为何要多维度
- 利于处理
- 避免重复
- 区分特征维度
- 3.3 为何要多种频率
- 3.4 为何同时使用cos,sin
- 3.5 表示绝对位置
- 结论
- 解读
- 周期性
- 3.6 表示相对位置
- 相对语义的重要性
- 结论
- 证明
- 3.7 旋转
- 3.8 为何是相加
- 0x04 三角函数编码的特性
- 4.1 无向性
- 4.2 远距离衰减性
- 4.3 外推性
- 问题
- 论证
- 0x05 NoPE
- 5.1 不需要
- 5.2 需要
- 0xFF 参考
0x00 概述
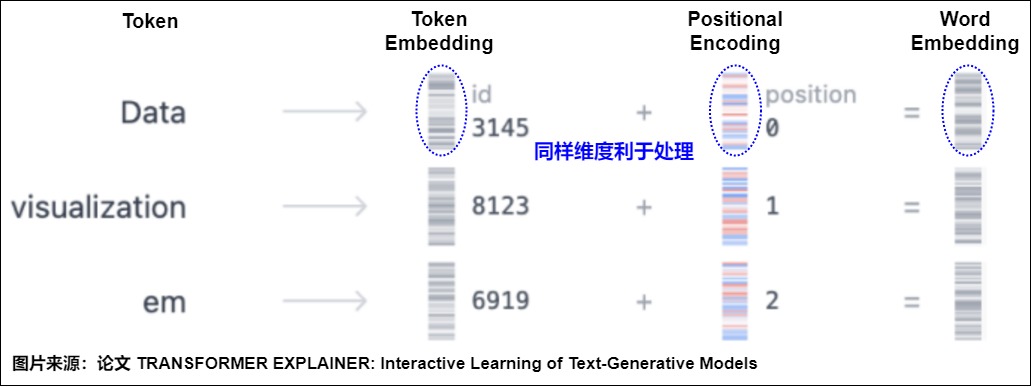
位置编码(Positional Embedding)是一种用于处理序列数据的技术,被用来表示输入序列中的单词位置。在Transformer 实现中起到了举足轻重的作用。Transformer 需要关注每个输入词的两个信息:该词的含义和它在序列中的位置。位置编码可以针对这两个关注点做关键的补充。
- 针对“输入词的含义”这个关注点,Transformer通过嵌入层对词的含义进行编码,位置编码可以在此之上注入位置相关的先验知识,比如:"相近的token应该具有相近的Embedding"、“相对位置比绝对位置更重要”、“远距离的相对位置可以不用那么准确”、“越远的相对位置越模糊”、“越近的Token越重要”和”越远的Token平均而言越不重要“等。
- 针对“输入词在序列中的位置”这个关注点,Transformer通过位置编码层表示该词的位置。在序列数据中,单词的顺序和位置对于语义的理解非常重要。传统的词向量表示只考虑了单词的语义信息,而没有考虑单词的位置,而注意力机制又有置换不变性的弊端。于是,位置编码为每个单词分配一个唯一的位置向量,这样可以将单词的位置信息融入到模型的表示中,进而克服注意力机制的置换不变性,使得模型在处理序列数据时更好地理解单词的上下文和关系。
最终,Transformer 通过结合这两个层的输出来完成两种不同的信息编码。
注:在深度学习中,一般将学习出来的编码称之为embedding,有将位置信息"嵌入" 到某个向量空间的意思。例如Bert的位置向量就是学习得到,所以称为"Position Embedding"。而原始Transformers模型中位置向量的思路是通过规则(三角函数)直接计算出来,不涉及学习过程,被称为Position Encoding。
0x01 问题
1.1 词序的重要性
无论何种语言,其语句都是一种时序型数据,即每个词都是位置相关的(position-wise)。句子中词的顺序和位置决定了句子的实际语义。单词相同但顺序不同可能会导致句子的语义发生变化。比如下面两个句子的意义就完全不同。
- 从北京到上海。
- 从上海到北京。
历史上还有经典的曾国藩例子:如果写“臣屡战屡败”,结果可能是曾国藩被拖出去斩首。如果写“臣屡败屡战”,结果曾国藩是忠勇无双有赏赐。
因此,自然语言文本信息的处理是一个具有先后顺序的序列任务,位置信息对于理解语言是相当重要的,学习不到顺序信息,那么模型效果将会大打折扣,因此需在模型中引入某种表达位置的机制。
1.2 Transformer架构的缺陷
位置不变性
Transformer模型抛弃了RNN、CNN作为序列学习的基本模型,完全采用注意力机制取而代之。对于一个输入句子,其单词不再是顺序输入,而是一次性输入一个序列中的所有词,依靠纯粹的自注意力机制来捕获词之间的联系,直接对这个序列整体进行特征变换。
注意力操作是一种全局操作,可以捕捉句子中较长的依赖关系。比如,Transformer可以让序列中每两个元素\(x_t\),\(x_s\)都能无视其绝对位置\(t\),\(s\)和相对位置\(t-s\)而进行信息交换,从而计算输入序列中的每个元素与整个序列的注意力权重。或者说,序列中位置信息是以常数形式进行变换,这样才能够防止长时信息丢失和遗忘问题。
然而,如果考虑到位置关系,则Transformer的优势就变成了劣势,因为Transformer本身来说是没有位置或者顺序的概念的,它具有位置不变性(ORDER INVARIANCE)或者说置换不变性(Permutation Invariance)。
置换不变性的意思是:词与词的位置随意变动,并不会导致这些词的注意力权重产生变化,注意力层的整个结果维持不变。即,无论位置如何变化,每一个词向量计算结果和位置变化之前完全一致,仅仅是词向量在输出矩阵的排列随着词和词位置互换而对应调整了一下。我们假设目前没有加入位置编码,则对于自注意力的计算公式\(A=softmax(QK^T)V\)来说,有如下例子。如果q是“我”,无论句子是“我爱你”还是“你爱我”,其注意力输出都是完全一致的。这说明在没有位置序列信息的情况下,改变词语顺序的句子实际语义是不一样的,但是注意力输出相同,无法准确建模。
import torch
import torch.nn.functional as F
d = 8 # 词嵌入维度
l = 3 # 句子长度
q = torch.randn(1,d) # 我
k = torch.randn(l,d) # 我爱你
v = torch.randn(l,d) # 我爱你orig_attn = F.softmax(q@k.transpose(1,0),dim=1)@v# 调转位置
k_shift = k[[2,1,0],:] # 你爱我
v_shift = v[[2,1,0],:] # 你爱我
shift_attn = F.softmax(q@k_shift.transpose(1,0),dim=1)@v_shiftprint('我爱你:',orig_attn)
print('你爱我:',shift_attn)
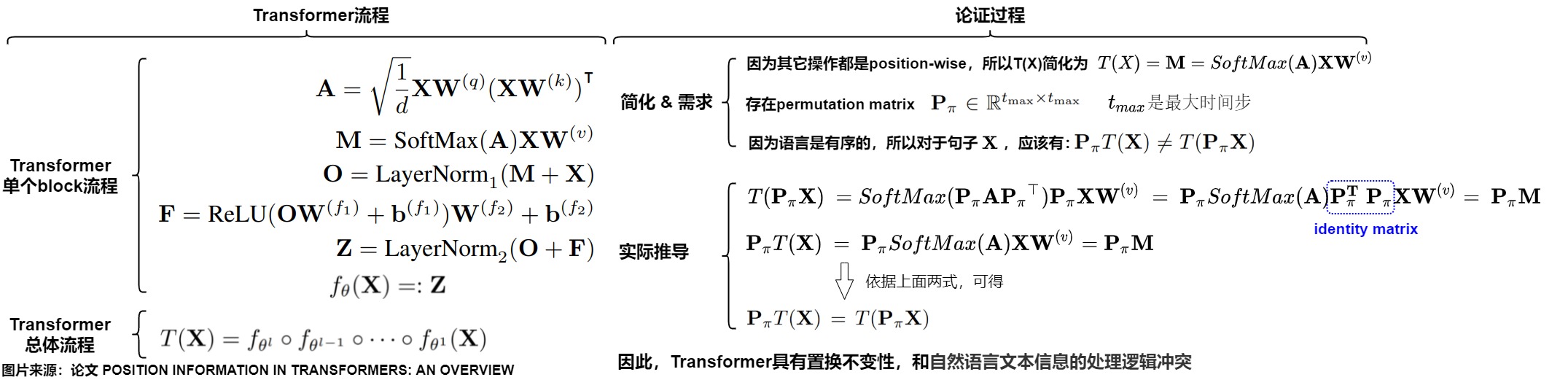
证明
我们接下来证明下位置不变性。在 Transformer-NoPE 架构中,Embedding 层和 FFN 层都是point-wise(逐点式),均与位置或者说顺序无关,只有注意力模块与位置相关。我们只需要关注注意力机制是否为置换等价或者顺序不变。
假设有置换矩阵\(\mathbf{P_\pi}\), 则\(\mathbf{P_\pi X}\) 是将\(\mathbf{X}\)的行依据\(\pi\)重新排列的结果(可以理解为把K,V按行打乱顺序,相当于把句子中的语序打乱),注意,\(\mathbf{P_\pi}\)只作用于\(\mathbf{X}\)的行,不改变列的顺序。我们看看把\(\mathbf{P_\pi X}\)输入注意力机制的运行逻辑中,是否会影响其运行结果。
查询矩阵的变化
原来的查询矩阵是:
则置换后的查询矩阵也要发生变化,即:
注意力矩阵的变化
原来的注意力计算公式是:
则置换后的注意力计算也要发生变化,即:
注意力分数的变化
原来的注意力分数的计算公式是:
则置换后的注意力分数的计算也要发生变化,即
因为置换矩阵只是排列的行,而Softmax的操作是行独立的,实际上对行和列进行重新排列并不会改变Softmax的结果,因此有:
最终结果
我们把上述变化综合起来,最终推导如下所示:无论句子顺序如何,其注意力计算结果完全一致。即假设\(x_s\),\(x_t\)分别代表第s和第t个输入单词,则有\(T(...,x_s,..., x_t, ...) = T(...,x_t,..., x_s, ...)\),T函数天然满足恒等式T(x,y)=T(y,x),无法区分输入的是\(x,y\)还是\(y,x\)。
后果
因此,在未加入位置信息的情况下,Transformer存在两个问题。
第一个问题是模型不能捕捉序列的顺序。
没有位置信息的自注意力模型顶多是一个非常精妙的“类词袋模型“,即模型把序列看成是一个集合,既然是集合,那么模型把输入序列的每一个单词都同等看待,自然就没有位置信息,那么隐状态就和时序无关。某个单词如果在不同的位置出现多次,其每次计算出的注意力加权求和结果都完全一致。
比如位置 j 的token最终的注意力输出如下。可以看到,因为位置信息是以常数形式进行变换,所以计算公式中没有任何位置信息的描述,只有求和算子,这就是类词袋模型。
而且,给定一个句子,最终的这个句子的词嵌入组合只来源于句子中所有单词的特征,和句子中单词的排序没有任何关系,即丢失了词之间的位置信息。输入元素位置的变动不会对注意力结果产生影响,从而只要集合中包含的元素是确定的,输出结果就是确定的。
然而,这显然和语言、代码、语音等序列的内在特征相违背:一句话打乱单词顺序后,所表达的意思、单词指代或修饰的对象、甚至单词对应的语义,可能都会随之改变。举个例子。将[我,爱,你]和[你,爱,我] 都输入Transformer,这个类词袋模型给出的句子表征会完全一致。而我们期望的是:“爱”这个词的词向量,在“我爱你”和“我你爱”这两个句子中,经过神经网络计算应该得到不同的输出,因为我们的输入中,“爱”这个词在句子中的位置实际上已经发生了变化,我们输入的是两个不同的句子,一个词在两个不同的句子中,应该是不同的向量表示,但是神经网络无法捕捉到这个变化。
[ [0.3, 0.5, 0.1, 0.4]
[我,爱,你] => Transformer => [0.1, -0.6, -0.2, 0.3], [0.3, 0.5, 0.3, -0.1] ][ [0.3, 0.5, 0.1, 0.4]
[你,爱,我] => Transformer => [0.1, -0.6, -0.2, 0.3], [0.3, 0.5, 0.3, -0.1] ]
第二个问题是单词间的权重和位置无关。
无论 t 和 s 所处的位置如何变化,它们之间的注意力权重 \(A_{t,s}\) 均不会发生变化,也就是位置无关。然而,这又和语言的特性相违背:多数的时候,离得越近的单词相关性可能越高,我们希望它们之间的的注意力权重更大;离得很远的两个单词可能毫无关系,我们希望其注意力权重更小。
1.3 解决思路
既然Transformer中的自注意力机制无法捕捉输入元素序列的顺序,因此我们需要对位置关系进行建模,把单词的顺序合并到Transformer架构中,从而打破这种置换不变性,于是Transformer作者提出了 Position Embedding 的方法,也就是“位置向量”或者说”位置编码“。
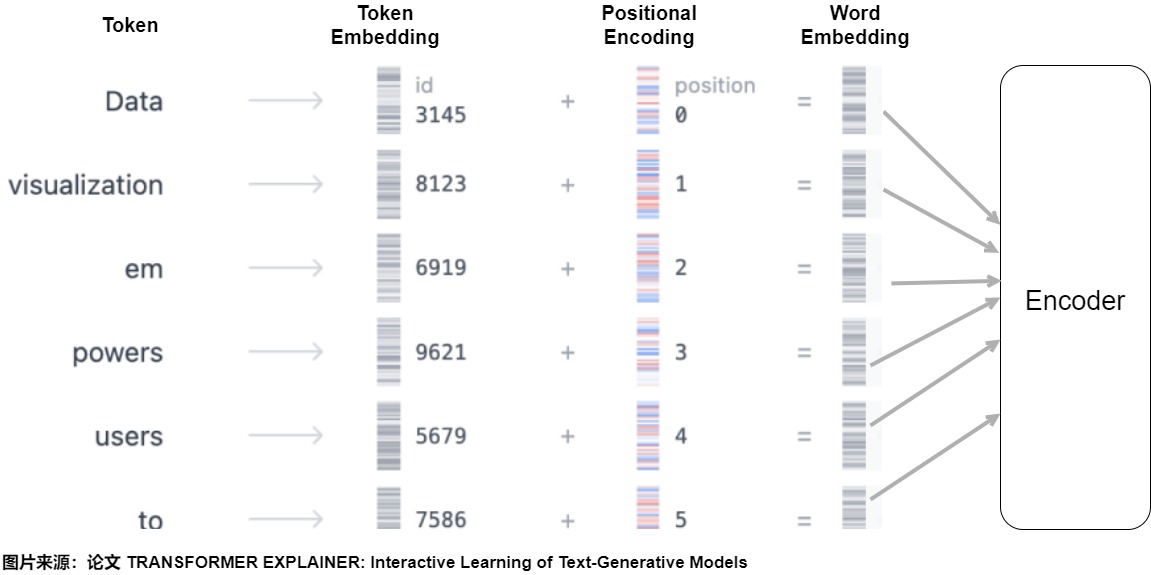
位置编码的作用就是给每个位置都加上一个唯一的位置编码向量,即将词序信息向量化。对于输入的每个单词,每个单词都有对应的向量 (与位置无关)。为了给每个位置都加上一个唯一的位置编码向量码,需要使用另一个具有相同维度的向量,其中每个向量唯一地代表句子中的一个位置。然后通过将词嵌入与其相应的位置嵌入求和来形成 Transformer 层的输入,即输入模型的整个Embedding是Word Embedding与Positional Embedding直接相加之后的结果。模型会将这个结果矩阵作为输入提供给后续层。

这样给每个词都引入了其在句子中特定位置的信息,类似\(T(..., x_s,..., x_t, ...) = T(...,x_s+p_s,..., x_t+p_t, ...)\)。注意力机制就可以分辨出不同位置的词,从而模型不但知道注意力要聚焦在哪个单词上面,还要知道单词之间的互相距离有多远,在计算注意力得分时就可以考虑两个元素之间的相对位置。模型也就具备了处理序列问题的能力。后面无论每个输入向量学习到了什么信息,都能够通过位置向量回溯到模型中的具体位置,也就为后面的输出提供了可参考的依据。
1.4 应具备的性质
论文"A Length-Extrapolatable Transformer"论文中提到了了transformers位置建模的三条设计原则:具备位置敏感性;针对位置平移具备鲁棒性;可以外推。原文摘录如下:
- First, a Transformer should be sensitive to order. Otherwise, it will degenerate into a bag-of-word model which confuses the whole meaning.
- Then, position translation can’t hurt the representation a lot especially combing with the proper attention-mask operations.
- After that, a good sequence model needs to deal with any input length.
论文"On Position Embeddings in BERT"则指出,Position Embedding是为了位置的时序特点进行建模。基于此,该论文提出Position Embedding应该具有三个特性:平移不变性(translation invariance,两个位置的关系只与相对位置有关)、单调性(monotonicity,随着距离的增大而衰减),对称性( symmetry,两个位置的关系是对称的,i,j和i,j相同)。原文摘录如下:
Informally, as positions are originally positive integers, one may expect position vectors in vector space to have the following properties: 1) neighboring positions are embedded closer than faraway ones; 2) distances of two arbitrary m-offset position vectors are identical; 3) the metric (distance) itself is symmetric.
- Property 1. Monotonicity: The proximity of embedded positions decreases when positions are further apart.
- Property 2. Translation invariance: The proximity of embedded positions are translation invariant.
- Property 3. Symmetry: The proximity of embedded positions is symmetric
我们顺着这些展开,详细看看一个良好的位置编码应该具备的性质,理想情况下,位置编码应满足以下标准:
-
唯一性/确定性。每个位置都需要一个无论序列长度如何,都保持一致的编码,即无论当前序列的长度是 10 还是 10,000,位置 5 处的标记都应该具有相同的编码。而且,该位置编码必须是确定性的,即每个位置都有唯一的编码(或者尽量不同),这样才能体现同一个token在不同位置的区别,确保模型对位置有分辨能力。另外,如果位置编码能从一个确定的过程中产生,那将是最理想的。这样,模型就能有效地学习编码方案背后的机制。
-
有界性:编码范围是有界的,值要在一定的范围内不会过大导致溢出。因为位置信息本身就是矫正量,不应该随着句子加长,位置编码的数字就无限增大,那样容易对单词的本体语义向量造成影响。
-
相对性:对模型来说,真正重要的往往不是绝对位置,而是token之间的相对位置。所以我们期望位置编码即可以表达绝对位置信息(表示同一个单词在序列之中不同位置的区别,即token在序列之中的绝对位置),也可以表达相对位置信息(如果有一组词无论在什么位置都不会发生词义的变化,则我们认为这组词的实际含义与绝对位置没有关系)。
-
单调性或者说距离衰减性:位置编码的最大意义就是给模型提供位置语义相关性。而位置相关性应该随相对位置距离增大而减少,并且是单调衰减关系。具体就是距离近的相关性高,距离远的相关性低。距离衰减性相当于软的窗口注意力。这符合人类自然语言的习惯,即相近的文字关联性更强,位置相近的Token平均来说应该获得更多的注意力,而距离比较远的Token平均获得更少的注意力。单调性也可以等同为一个卷积神经网络,在做信息聚合的时候会优先考虑局部信息。距离越近的元素则会被考虑的越多。
-
平移不变性:任何位置之间的相对距离在不同长度的句子中应该是一致的。具体来说是,两个位置的关系只与相对位置有关,与序列长度无关。在任何长度不同的序列中,相同位置的Token之间的相对位置/距离保持一致(体现Token位置之间差异的不变性)。比如长度10和长度100的句子中,第1个单词和第5个单词之间的距离应该相同。即,如果两个token在句子1中的相对距离为k,在句子2中的相对距离也是k,那么这两个句子中,两个token之间的相关性应该是一致的,也就是attention_sample1(token1, token2) = attention_sample2(token1, token2)。
-
线性关系。位置之间的关系在数学上应该是简单的,或者说存在线性关系。如果知道位置 p 的编码,那么计算位置 p+k 的编码就应该很简单,这样模型就能更容易地学习位置模式。
-
多维度:随着多模态模型成为常态,位置编码方案应该能够自然地拓展至多个维度,从 1D 扩展到 nD。这将使模型能够使用图像或脑部扫描这样的数据,它们分别是 2D 和 4D 的。
-
外推性或者说泛化性:位置编码可泛化到比训练中遇到的序列更长的序列上。为了提高模型在现实世界中的实用性,它们应该在训练分布之外泛化。因此,编码方案需要有足够的适应性,以处理意想不到的输入长度,同时又不违反任何其他理想特性。具体说就是编码系统不受句子长短的影响(即适用于任意文本长度),在训练没有见到的样本上,没有见过的长度上也能表现不错。化未见为已见,化分布外为分布内。
-
周期性:这个性质是出于实现上的考虑。因为要求是相对且有界,所以容易联想到一个性质 —— 周期性,这样更远距离的值可以和较近距离的值相同,从而有一定的外推性。
-
结合语义信息。在涉及长上下文理解和搜索的任务中,注意力机制应该优先考虑语义相似性,而不是被与位置编码相关的信息所掩盖,因为在较长距离上位置编码的相关性可能较低。因此,PE 应该结合语义和位置信息,确保语义信息不受位置距离的过度影响。
0x02 编码方案演化
既然知道了理想位置编码的属性,我们就来尝试从无到有一步一步设计和迭代位置编码方案,并且比对各种方案和期望性质之间的差距。Positional encoding有一些想象+实验+论证的意味,或者说,在 LLM 引入位置信息更像是构建特征工程,这里特征对应的信息就是位置。
为了更好的说明,我们先给出哈佛代码。这就是Transformer论文中的方式。函数的总体目标是计算每个维度(每一列)的相关位置信息。因此需要:
-
初始化一个形状为 (max_len, 1) 的绝对位置矩阵position。对应代码中的position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) 。在position中,词汇的绝对位置用它的索引表示。绝对位置矩阵初始化之后,接下来就是考虑如何将这些位置信息加入到位置编码矩阵中。因此,需要将形状为 (max_len, 1) 的绝对位置矩阵,变换成(max_len, d_model) 形状,然后覆盖初始位置编码矩阵。这就需要构建一个转换矩阵 div_term。
-
构建转换矩阵div_term 就对应代码中的 div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)),具体操作为。
-
将自然数的绝对位置编码缩放成足够小的数字 10000 ^ (2i / d_model),这样有助于在之后的梯度下降过程中更快的收敛。
-
用 torch.exp()函数来构建一个形状为(1, d_model) 变换矩阵div_term,用于缩放不同位置的正弦和余弦函数。div_term是256维的张量,即公式里面sin和cos括号中的内容。和原始论文不同,哈佛代码通过e和ln进行了变换,这样速度会快一些。
-
div_term具体如下:
\[{div\_term}_i = 10000^{-\frac{i}{d_{model}}} \]
-
-
使用position和div_term构建位置编码pe,计算每个维度(每一列)的相关位置信息。具体是使用正弦torch.sin(position * div_term)和余弦函数torch.cos(position * div_term)来生成位置编码,位置编码是一个d_model维的向量,对于这个向量的每一个维度,如果这个维度为偶数,则用正弦函数进行编码,如果这个维度为奇数,则用余弦函数编码。
-
使用unsqueeze(0)在第一个维度添加一个维度batch_size,以便进行批处理。
代码中的几个注意点如下:
-
Transformer模型的输入X:[batch_size, max_len, d_model],是batch_size个句子的编码。位置编码是对一条句子中所有word的位置进行编码,并且由于我们对位置编码后要加到X上,因此,一个位置的编码的维度与一个word编码的维度相同,都是d_model。这样,一条句子的位置就编码为[max_len, d_model]维度的张量,batch_size条句子的位置编码就是[batch_size, max_len, d_model]维度的张量。
-
代码div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))使用等价的指数+对数运算,其原因是为了确保数值稳定性和计算效率。一方面,当d_model较大时,直接使用幂运算会导致10000 ^ (2i / d_model) 变得非常小,以至于在数值计算中产生下溢。通过将其转换为指数和对数运算,这样可以在计算过程中保持更好的数值范围,从而避免这种情况。另一方面,在许多计算设备和库中,指数和对数运算的实现通常比幂运算更快。
-
调用 Module.register_buffer 函数。register_buffer通常用于保存一些模型参数之外的值,比如在 BatchNorm 中的 running_mean,它不是模型的参数,但是模型也会修改它,而且在预测的时候也要使用它。在此处,pe 是一个提前计算好的常量,在前向传播时候要用到它。因此register_buffer()函数会把 pe保存下来。
具体代码如下。
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout=0.1, max_len=5000):"""d_model: 词嵌入维度max_len: 序列的最大长度dropout: 置0比率PE(pos, 2i) = sin(pos/pow(10000, 2*i/d_model)), (0<= i <= d_model)PE(pos, 2i + 1) = cos(pos/pow(10000, (2*i)/d_model)),PE(p+k, 2i) = PE(p, 2i)PE(k, 2i+1) + PE(p, 2i+1)PE(k, 2i)sin(a+b) = sin(a)cos(b) + cos(a)sin(b) 注: 序列上不同位置上token的同一个维度i上,才具有线性关系"""# 初始化一个全0位置矩阵,矩阵的大小是max_len x d_model,后续计算的位置编码会存储在pe中pe = torch.zeros(max_len, d_model) """初始化一个绝对位置矩阵position, 在这里,词汇的绝对位置用它的索引表示,具体操作是:1. 使用arange方法获得一个连续自然数向量(0到max_len-1的整数序列)。2. 使用unsqueeze方法拓展向量维度使其成为矩阵,目的是为了和div_term进行计算假设max_len是500,则 position是tensor([[0,1,2,...,499]]),形状是torch.Size([500, 1])"""position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) """构建一个1xd_model形状的变换矩阵div_term,具体操作是:1. 将自然数的绝对位置编码缩放成足够小的数字 10000 ^ (2i / d_model),这样有助于在之后的梯度下降过程中更快的收敛。2. 用 torch.exp()函数来构建一个形状为(1, d_model) 变换矩阵div_term,用于缩放不同位置的正弦和余弦函数。div_term是256维的张量,即公式里面sin和cos括号中的内容。和原始论文不同,此处通过e和ln进行了变换,这样速度会快一些。"""div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))"""使用position和div_term共同构建位置编码pe,计算每个维度(每一列)的相关位置信息具体是使用正弦和余弦函数生成位置编码,d_model的偶数索引使用正弦函数;奇数索引使用余弦函数此时pe形状是[max_len,d_model]"""pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term)# 在第一个维度添加一个维度batch_size,以便进行批处理pe = pe.unsqueeze(0).transpose(0, 1) # 此时pe形状是[1,max_len,d_model]self.register_buffer("pe", pe) # 将pe注册为缓冲区,以便在不同设备之间传输模型时保持其状态def forward(self, x):"""forward函数的参数是x, 表示文本序列的词嵌入表示。目的是返回Embedding + PositionEncoding"""# 在位置矩阵中取与输入序列长度相等的前x.size(1)行,然后和Token Embedding相加,因为默认max_len一般太大了,所以要进行与输入张量的适配。# 这里需要注意的一点便是,在输入x的维度中,batch_size是第1个维度,seq_len是第2个维度,size(1)实际获取的是第2个维度。# 因为不需要进行梯度求解的,因此把requires_grad设置成false。x = x + self.pe[:, : x.size(1)].requires_grad_(False)# 返回最后得到的结果并进行dropout操作return self.dropout(x)
2.1 整型数字位置编码
我们首先想到的方法是将 token 位置的整数值添加到 token 嵌入的每个分量中,即为每个时间步按一定步长线性分配一个数字。比如第i个位置token的位置编码就是i。i 的取值范围为 0→L,其中 L 是当前序列的长度。数学映射为 f(x) = x。比如:“我喜欢苹果”,其位置编码就是:
我们把哈佛代码修改如下,这里把词维度的所有索引都变成了位置数值。
max_len = 5
d_model = 4
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
pe[:, 0::2] = position
pe[:, 1::2] = position
print(pe)
输出为:
tensor([[0., 0., 0., 0.],[1., 1., 1., 1.],[2., 2., 2., 2.],[3., 3., 3., 3.],[4., 4., 4., 4.]])
这种方案的优点是:实施简单、计算速度快。但是有几个缺点:
- 位置编码数值无界(单调递增),容易造成编码数值过大。这样又带来几个问题:
- 不能很好地处理长序列的输入。假如对句子序列长度没有限制,那么句子最后一个字的位置编码比第一个字的位置编码要大很多。即如果句子有1000个字,最后一个字的位置编码是999,比第一个字的位置编码0要大很多。数字越大就说明这个位置的权重越大,这与序列的真实权重不一定符合。
- 位置编码会干扰模型。位置编码和token的embedding会相加再传给attention,如果word embedding的范围比较小,则位置编码会给相加的结果造成很大干扰。比如:最后一个字的embedding是0.5,但是其位置编码是999,则0.5 + 999之后, 0.5的影响力会被极度消弱,数值会有倾斜,这意味着信噪比非常低,模型很难从位置信息中分离出语义信息。模型的效果会被干扰。另外也会导致模型的权重存在很大的数字,影响训练的稳定性(比如导致梯度消失)。
- 缺少泛化能力。位置编码是依据固定长度来计算的,而模型在推理时可能遇到比训练时更长的序列,这意味着如果序列太长,位置编码可能会失效。模型处理不好本方案训练时没见过的位置。比如,训练时候最长序列是1000,但是推理时候序列超出了1000,则难以泛化。
- 难以和注意力机制融合。目前的位置关系是通过如下方法进行表达:\(f(m-n) = f(m)-f(n) = m-n\),但是这个 f(x) 函数不好与自注意力机制结合,因为向量之间做内积乘法,减法显然无法接受。而且,因为self-attention层中的参数是用序列长度无关方法训练出来的,引入序列长度相关的任何参数都会导致参数目标的异化。
我们接下来分为两支来看看如何解决上述问题。一个是尝试减法之外的机制(乘法表示)。一个是如何解决位置编码数值无界问题(归一化)。
2.2 乘法表示
既然减法很难和注意力融合,而内积的方式限定了我们的计算方式只能为乘法,那我们来尝试乘法的性质构建距离函数 f(x),看看是否可以表达距离关系,比如如下公式:
这样的问题在于乘法有交换律,无法区分位置先后,比如:
会造成”从北京去上海“和”从上海去北京“无法区分的问题。因此我们需要细化对 f(x) 的需求,使得 f(x) 不仅需要满足:
还需要不满足交换律:
我们来看看向量乘法。对于位置 m、n 的 token,V(m)、V(n) 对应其位置向量,结果发现向量点积乘法也满足交换律,因此也不合适。
我们再看看矩阵乘法,发现矩阵 \(R_m \times R_n\) 相乘不满足交换律,即:
因此矩阵的乘法性质满足我们上面不断严苛的条件,顺利进入我们的视野。这为后续分析RoPE打下了基础。
2.3 归一化
为了解决整型值带来的位置编码数值无界问题,我们决定试试把位置编码限制在一定值域范围内,最简单的思路就是用句子长度来对位置编码进行归一化到[0,1]之间,即Position Encoding = position / (seq_len),这样就得到了一个等差数列。
代码修改为:
max_len = 5
d_model = 4
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
pe[:, 0::2] = position / max_len
pe[:, 1::2] = position / max_len
print(pe)
输出是:
tensor([[0.0000, 0.0000, 0.0000, 0.0000],[0.2000, 0.2000, 0.2000, 0.2000],[0.4000, 0.4000, 0.4000, 0.4000],[0.6000, 0.6000, 0.6000, 0.6000],[0.8000, 0.8000, 0.8000, 0.8000]])
这样虽然解决了上述问题,但是又有了新的问题:对于长度不同的序列,这种归一化方法会导致问题。
原因是:长度不同的序列的归一化方式不一致。因为不同句子的序列长度可能不同,因此不同长度的位置编码的步长是不同的。这就会导致在不同的句子中同一位置就会有不同的位置编码,这反过来会混淆我们的模型,不是我们希望的。因为位置信息之中,最关键的就是相对位置信息,如果使用本例方式,则长文本的相对次序关系会被削弱。在较短的文本中相邻的两个字的位置编码的差异与长文本中的相邻两个字的位置编码可能存在数量级上的差异。我们以如下两个句子为例:
- 不逢北国之秋,已将近十余年了。
- 北国的槐树,也是一种能使人联想起秋来的点缀。
两个句子中,”北国“都是相邻的,按照相关性的要求,在任何长度不同的序列中,相同位置的Token之间的相对位置/距离应该保持一致(体现Token位置之间差异的不变性),然而本方案却无法满足。第一个句子之中,PE(北) = 2/13,PE(国)=3/13。PE(北)-PE(国)=1/13。第二个句子之中,PE(北) = 0/20,PE(国)=1/20。PE(北)-PE(国)=1/20。其原因就是因为无法找到一个归一化的标准。

我们再回到代码来佐证,可以看到,上面示例中,每个token之间距离是0.2。如果把max_len修改为10,则得到如下,每个token之间距离是0.1。
tensor([[0.0000, 0.0000, 0.0000, 0.0000],[0.1000, 0.1000, 0.1000, 0.1000],[0.2000, 0.2000, 0.2000, 0.2000],[0.3000, 0.3000, 0.3000, 0.3000],[0.4000, 0.4000, 0.4000, 0.4000],[0.5000, 0.5000, 0.5000, 0.5000],[0.6000, 0.6000, 0.6000, 0.6000],[0.7000, 0.7000, 0.7000, 0.7000],[0.8000, 0.8000, 0.8000, 0.8000],[0.9000, 0.9000, 0.9000, 0.9000]])
2.4 二进制位置编码
有没有更好的方法来确保我们的数字介于 0 和 1 之间呢?如果我们认真思考一段时间,也许会想到将十进制数转换为二进制数。因此,我们将位置编码转换为二进制表示法,并将二进制值(可能已归一化)与嵌入维度相匹配,而不是将我们的(可能已归一化的)整数位置添加到嵌入的每个分量中。
比如,我们将感兴趣的位置(2)转换为二进制表示(0010),且限定在\(d_{model}\)之内,则可以和Embedding直接相加。具体是将每一位添加到 token 嵌入的相应维度中。最小有效位(LSB)将在每个后续标记的 0 和 1 之间循环,而最大有效位(MSB)将每 \(2^{n-1}\) 个 token 循环一次,其中 n 是位数。读者可以在下图中看到如何把0—15通过二进制编码,得到不同索引的位置编码向量。
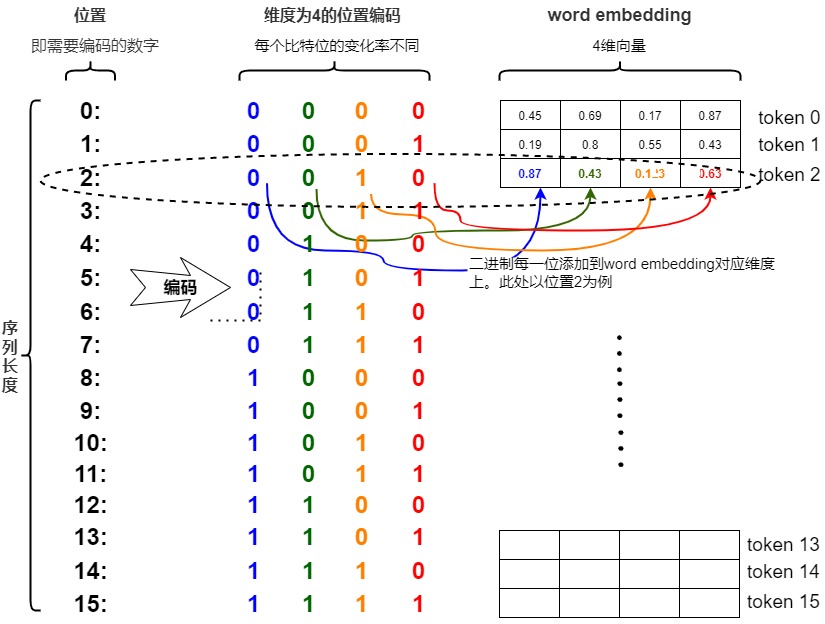
现在所有的值都是有界的(位于0,1之间),且transformer中的\(d_{model}\)本来就足够大,基本可以把我们要的每一个位置都编码出来了。
虽然看上去不错,但是二进制编码依然存在缺点:这样编码出来的位置向量处在一个离散的空间中,没法表示浮点型。而且不同位置间的变化是不连续的,所以输出会”跳跃“。而神经网络的优化过程喜欢平滑、连续和可预测的变化。其实,二进制位置编码就有了多维位置编码的影子。而神经网络恰好擅长处理高维数据。如果觉得二进制数字的跨度过小,想进一步增加数字的跨度,我们还可以进一步增大进制的基数,如使用6进制、8进制甚至16进制,这样也可以进一步减少输入的维度,又没有缩小相邻数字的差距(归一化的缺点)。如果我们将二进制编码变为连续的高进制版本,就可以建模0—10万甚至百万的位置编码。
2.5 需求拓展
我们先做个小结,迄今为止我们位置编码方案的成果是:我们已经解决了数值范围的问题,得到了在不同序列长度上保持一致的唯一编码。但是问题依然存在:
- 浮点数的世界中使用二进制值是对空间的浪费,因此我们需要一个有界又连续的周期函数。
- 前面的几种方法也可以看作是类词表方法,即建立一个长度为L的词表,按照词表的长度分配位置编码。或者也可以认为是单调函数方法,此方法的特点是:追求token在序列之中的绝对位置,使得后续token的位置编码都大于前面的token的位置编码。
因此,我们需要考虑下,是否可以把构建重心从绝对位置调整为相对位置?即构建一个函数f,其输入是token的绝对位置信息,输出是token的相对位置信息。
比如:“我喜欢苹果”,如果把“欢”的位置编码设置为0,其他token的位置编码为该token和“欢”之间的距离,负数表示在“欢”字前面。其位置编码就是:
通过使用相对位置,就可以知道token之间距离远近。注意:相对位置编码需要线性相关。
那么我们接下来的目标就明确了,需要寻找取值范围是有界、平滑、连续且可以表示相对位置的函数。如果把比特位看成维度,则最好各个维度的频率不同,低维度频率变化快,高维度频率变化慢。正弦函数sin就可以满足这一点。事实上,正弦函数也能表示出二进制那样的交替,随着正弦函数频率的降低,也可以达到上图红色位到橙色位交替频率的变化,具体特点如下:
- 不同维度用不同频率的sin组合。通过调整三角函数的频率,我们可以实现这种低位到高位的变化。
- 因为每个维度是用t除以维度index,所以每个维度变化的周期和index相关,即维度的周期不同。
- 波长如果变长,数据变换就会变慢,符合低位变化快、高位变化慢的情况。
于是,我们可以考虑把位置向量当中的每一个元素(对应一个维度)都用一个sin函数来表示,则第t个token的位置向量可以表示为:
我们还可以通过频率index来控制sin函数的波长,频率不断减小,则波长不断变大,此时sin函数对t的变动越不敏感。这样可以使得编码向量在任意维度上都能保持唯一性,即不同位置在同一个维度上不会有相同的值。这是由正弦和余弦函数的周期性和相位差保证的,即对于任意两个不同的位置,它们对应的编码向量在每一个维度上都不相等。假定
第一个维度sin函数周期是完整2pi, 第二维度是4pi,依次类推,越往后,维度增加值变化的频率依次变慢。于是我们就引入三角位置编码。
2.6 三角函数编码
性质
我们首先介绍几个和位置编码相关的三角函数的性质。
三角恒等式
三角恒等式是关于三角函数的一些已证明的恒等式,比如有两角和差、二倍角公式、三倍角公式等。对于位置编码最重要的是和差公式:依据两个角度自身的正弦和余弦可以计算出它们的和与差的正弦和余弦。
周期性
在数学中,周期函数是指经过一个确定的周期之后,数值皆能重复的函数。对于实数或者整数函数来说,周期性意味着按照一定的间隔重复一个特定部分就可以绘制出完整的函数图。如果在函数 𝑓中所有的位置 x 都满足:𝑓(𝑥+𝑇)=𝑓(𝑥),那么,𝑓就是周期为 𝑇的周期函数。
三角函数正弦函数与余弦函数都是常见的周期函数,其周期为 2π,即 𝑠𝑖𝑛𝑥=𝑠𝑖𝑛(𝑥+2𝜋)。这意味着正弦函数的图像会在水平方向上每隔2π的长度重复一次。这个周期性是正弦函数的基本特性之一,也是其在多个领域应用的基础。
波长
在物理学中,波形的频率表示每秒内完成的周期数,而波长(wavelength)表示波形重复的距离。正弦函数的波长是指正弦波完成一个完整周期所需要的距离或时间。sin函数的波长与它的频率和周期有关,频率指一秒内周期的数量,周期指一个波所需的时间。因此,波长等于速度乘以周期。
。在公式上,正弦函数通常表示为:𝑦=sin(𝑘𝑥+𝜙)。其中:
- 𝑦 是输出值。
- 𝑥是输入变量,通常代表时间或空间。
- 𝑘 是波数(wave number),它与波长 𝜆 的关系是 𝑘=2𝜋𝜆。
- 𝜙是相位偏移。
因此,波长 𝜆 的计算公式为:𝜆=2𝜋。对于RoPE而言 \(𝜆_𝑖=2𝜋/𝜃_𝑖\)
定义
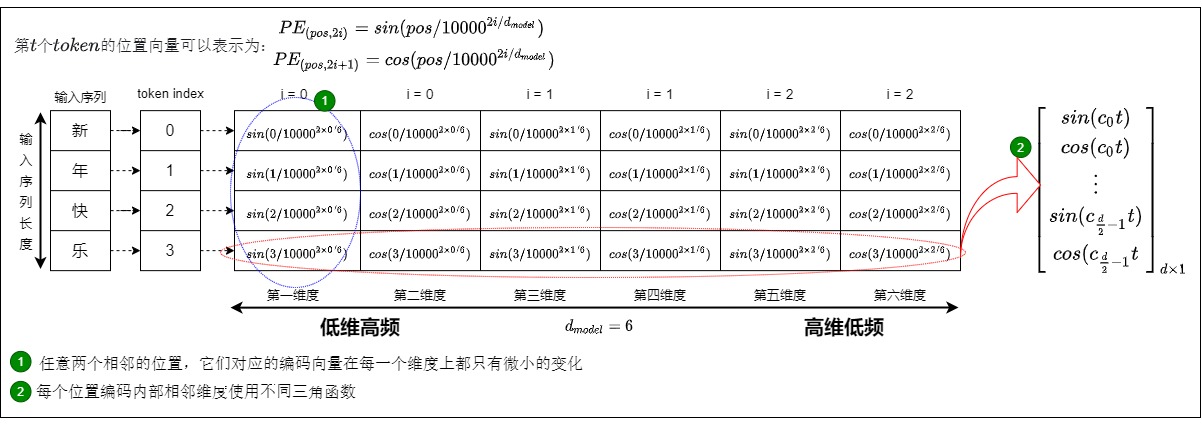
三角函数式位置编码(也称为Sinusoidal位置编码)是Transformer原始论文提出来的位置编码方案,这种编码方案基于无参数的固定式三角函数来计算编码向量(通过sin和cos函数的线性变换来提供给模型的位置信息),这样就用绝对位置编码来捕捉不同位置之间的相对关系,其定义如下:
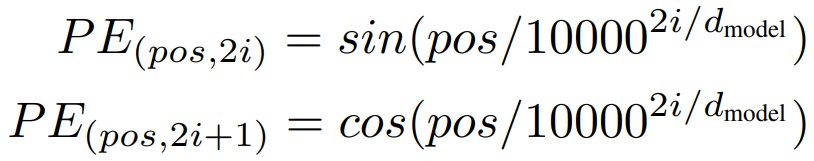
转换成具体代码如下:
PE(pos,2i) = sin(pos / 10000^(2i/d_model))
PE(pos,2i+1) = cos(pos / 10000^(2i/d_model))
编码方式
Transformer作者尝试了两种编码方法(学习和公式)。
- 从数据中学习:学习式是“learned and fixed”,即“Postional Embedding”。位置向量是在训练过程中从数据中学习到的,它只能表征有限长度内的位置,无法对任意位置进行建模。
- 正弦函数:公式方法是Position Encoding,此方法使用正弦函数为每个位置构建唯一的嵌入。算出来的可以接受更长的序列长度而不必受训练的干扰.
两种方法取得的效果都差不多。因为通过公式来计算更简单、参数量也更小,所以Transformer作者选择了第二种。
公式解读
以下是关于公式的一些说明:
- \(d_{model}\)是词向量维度。在论文中是直接将词嵌入向量和位置编码进行相加,所以我们需要让位置编码的维数和词嵌入向量的维数相等。
- pos是位置索引,表示此token在序列之中的位置,即单词在序列中的位置,设句子长度为L,那么pos取值范围是0~L-1。比如第一个token位置就是0。
- i 表示位置向量的维度索引,2i 表示偶数的维度,2i+1 表示奇数维度,例如\(d_{model}\) 为512,则i的取值范围是0~255。
- 10000:定义的超参数标量,这是Transformer作者所使用的值。
- \(PE_{(pos,i)}\)表示某个token的位置编码,位置编码不是单独某个数字,而是一个\(d_{model}\)维度向量。其可以由位置索引pos和维度索引i计算得到。即正弦这一类的参数式位置编码中涉及两个概念:一个是距离,另一个是维度。因为结合了这两个概念,所以可以保证在一定范围内位置编码的唯一性:
- 不同pos的同一维度特征对应的正弦值或者余弦值也会不一样,这样会导致不同位置的pos的位置编码变得唯一。
- 同一pos的不同维度所对应的数值也不一样。
- 同一个token中不同维度的特征信息,可以用sin和cos的方式计算,即使用不同频率的正弦、余弦函数生成。每个分量上是sin,cos轮流交替的,一对相邻的偶数和奇数分量形成一对,该对的三角函数输入相同。可以认为是输入x的嵌入维度上,依次加上不同频段的正余弦波。
- 位置嵌入函数的周期从2𝜋到10000*2𝜋变化,而每个位置在embedding dimension维度上都会得到不同周期的sin和cos函数的取值组合。维度 i 的周期为 \(𝑇=𝑏𝑎𝑠𝑒^{𝑖/𝑑}∗2𝜋\),其中0 <= i < d,因此周期T的范围是 𝑇∈[2𝜋,𝑏𝑎𝑠𝑒∗2𝜋]。
- sin和cos公式表达的含义是在偶数的位置使用sin函数计算,在奇数的位置使用cos函数计算。每对奇数和偶数拼成一组,例如0,1一组,2,3一组,分别用上面的sin和cos函数做处理。
- 每组内sin和cos函数共享一个频率,不同组函数的频率不同(低维用高频,高维用低频),从而产生不同的周期性变化。这有点傅里叶频谱变换的味道,希望用若干组cos和sin函数来代表不同的特征维度(类比频率)。
- 第k组的频率\(f_k=2\pi \cdot 10000^{2k/d}\),其中\(k=1,...,d/2\)。这样就在embedding dimension维度上随着维度序号增大,周期变化会越来越慢。
- 所有pos相同维度上的三角函数相同(偶数都是sin,奇数都是cos),差别仅是pos值不同,因此三角函数输入的分母相同,差异在分子。
- 位置编码将词的位置信息表征为向量,该向量由词位置和分量位置共同确定。对输入padding的位置采用全0向量作为位置编码。
- 位置编码矩阵所有句子共享,因此不同句子中相同位置的字/词的位置编码的结果相同。
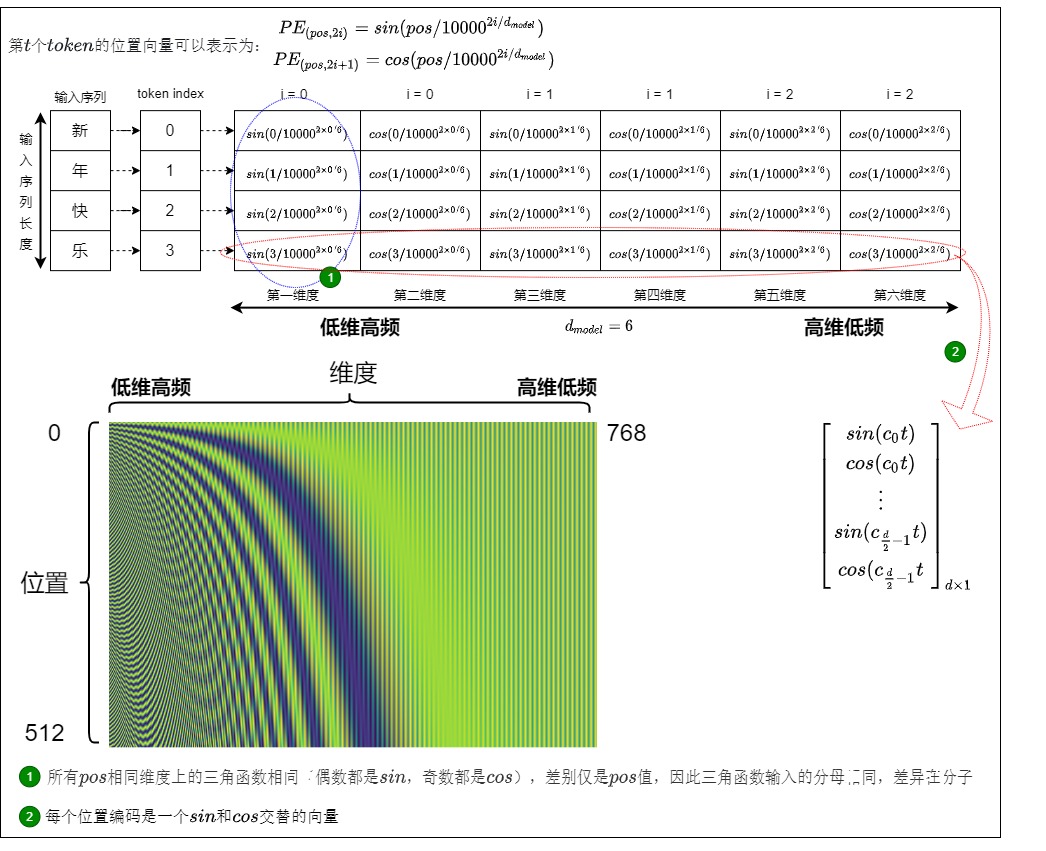
具体样例
三角函数式位置编码的具体样例如下图所示,位置编码层的输出是一个矩阵,矩阵的每一行表示一个 token 的位置编码向量,每个位置编码是一个sin和cos交替的向量(\(d_{model}\)可以被2整除)。其中\(c_i = 1/10000^{2i/d_{model}}\)
具体如下图所示。
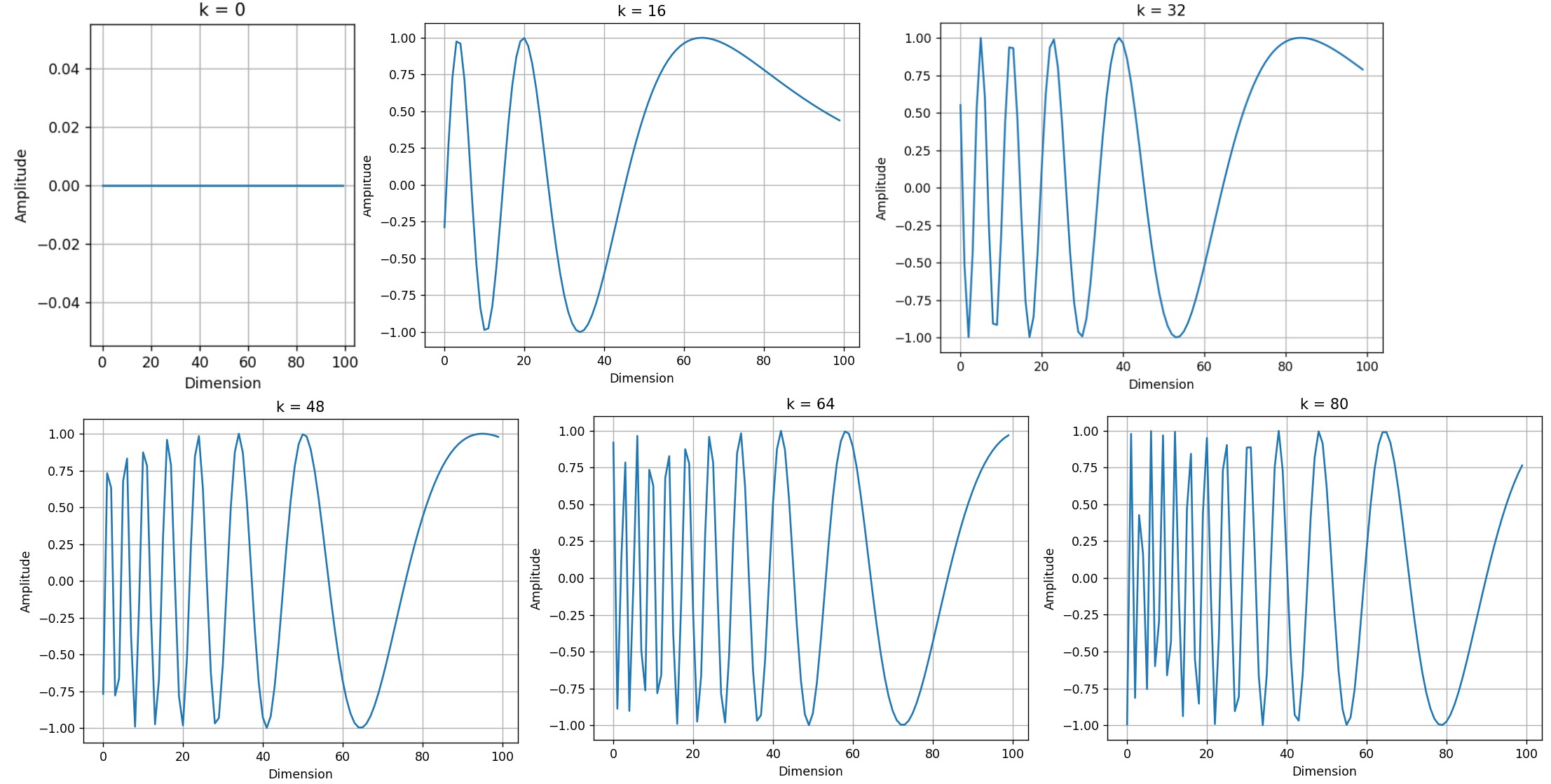
我们再设定n=10,000和d=512,看看不同位置的正弦波。
def plotSinusoid(k, d=512, n=10000):x = np.arange(0, 100, 1)denominator = np.power(n, 2*x/d)y = np.sin(k/denominator)plt.plot(x, y)plt.title('k = ' + str(k))fig = plt.figure(figsize=(15, 4))
for i in range(4):plt.subplot(141 + i)plotSinusoid(i*4)
可以看出,每个位置 𝑘 都对应一个不同的正弦波,它将该位置编码为一个向量。对于固定的嵌入维度 𝑖,波长是通过以下公式确定的:\(𝜆𝑖=2𝜋𝑛^{2𝑖/𝑑}\),而且,正弦波的波长随着嵌入维度 𝑖 的增长呈几何级数变化。
优点
简单来说,Transformer基于正余弦的位置编码用维度控制频率,用位置控制相位。就是对不同维度使用不同频率(随特征维度变化,低维用高频,高维用低频)的正/余弦函数进而生成不同位置的高维位置向量。
正弦位置编码有几个明显的优点:
-
简单且可解释。
-
采用公式生成,避免了训练得到的位置向量固定长度的尴尬。
- 位置编码是根据绝对位置计算的,而且是固定的,这意味着模型在训练和测试时使用相同的位置编码,保持一致性。
- 编码值不依赖于文本的长度。
-
有值域范围限制,其优点如下:
- 采用sin-cos位置编码保证了位置向量值在-1~1之间,稳定可控。 除了第一行以外,位置矩阵的所有值都是三角函数sin,cos的结果,因此所有位置和各分量上的结果都是介于-1到1之间的,使得位置编码值固定在一个区间内不会太大或者太小,从而使得位置编码和词原始embedding相加存在可行性。而且,导出的位置编码与input_embedding相加不会使得结果偏离过大而对词义产生破坏。
- cos, sin函数的值域在[-1, 1]之间,且是周期性的,非常适合用在神经网络中的初始化赋值中。
-
可以泛化到未见过的数据、以及易于扩展。
- 模型可以接受不同长度的输入。
- 三角函数有显式的生成规律,具有一定外推性。由于位置编码是基于三角函数计算的,使 PE 能够处理比训练时见过的序列更长的输入。假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
- 位置向量的值是有界的,且位于连续空间中。模型在处理位置向量时更容易泛化,即更好处理长度和训练数据分布不一致的序列(sin函数本身的性质)
-
可以反应相对位置信息.
- 能通过三角函数关系表达2个位置的相对关系,这样能够体现词汇在不同位置的区别(特别是同一词汇在不同位置的区别)。
- 不同位置之间的位置向量是正弦和余弦函数的周期函数。这使得不同位置之间的位置向量能够保持一定的相似性,从而帮助模型更好地理解位置信息并捕捉到序列中的顺序关系。可以让模型容易地计算出相对位置,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)。
0x03 三角函数编码思路分析
前面我们讲述了理想情况下位置编码应满足的性质。因为三角函数编码是Transformer论证采用的方案,所以我们用这些性质来验证三角函数编码的设计思路。
3.1 作者的话
Transformer为什么要使用正弦位置编码?论文作者表示是因为正弦位置编码可以表达相对位置,而且可以外推到训练之外的长度。原文如下。

因为作者并没有解释设计思路,所以我们需要在接下来继续探究。下面几个小节之间彼此有纠缠。比如讨论多维度时候会默认使用三角函数。讨论三角函数时候会使用多维度进行讨论。这是双生花,一个硬币的两面。
3.2 为何要多维度
把token在序列中的位置记为pos,把向量的某一维度记为i,我们需要为pos的向量的每个数设置一个实数数值,该数值要满足如下性质:
- 同一个pos的不同维度i的数值要各不相同。
- 不同向量的同一个维度的数值要依据pos不同而不同,且编码规则要满足相对关系,即\(f(pos+1)-f(pos)=f(pos)-f(pos-1)\)。
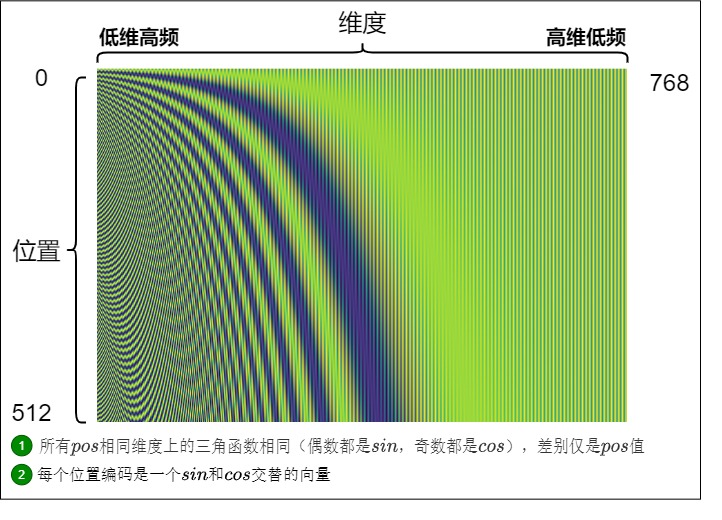
Sinusoidal位置编码恰恰可以满足上面的条件。我们用如下代码生成图例,假定句子长度是512,词向量维度是768。Positional Encoding是定义在位置-维度平面上的二元函数。
import numpy as np
import math
from matplotlib import imageseq_len = 512
dimension = 768
data = np.zeros((seq_len, dimension))for pos in range(seq_len):for i in range(dimension):if i % 2 == 0:data[pos,i] = math.sin(pos / math.pow(10000, i / dimension))else:data[pos,i] = math.cos(pos / math.pow(10000, (i-1) / dimension))image.imsave('Sinusoidal.png', data)
Sinusoidal位置编码与维度分量的关系如下图所示,可以发现:
- 每个分量都具有周期性,是正弦或余弦函数。
- 越靠后的分量(i 越大),波长越长,频率越低。
这样,每个位置在embedding dimension维度上都会得到不同周期的sin和cos函数的取值组合,每一维度上都包含了一定的位置信息,而各个位置字符的编码值又各不相同。从而产生独一的纹理位置信息,模型从而学到位置之间的依赖关系和自然语言的时序特性。
了解了这些基本的特性后,接下来就需要讨论更加深层次的问题。我们来看看为何要用一个向量来表达位置信息,具体来说,向量有如下几点优势:
- 利用处理。
- 避免重复。
- 增加差异性,能够对位置不同进行差异化刻画,区分特征维度。
利于处理
如何将positional encoding融合到自注意力算法中?具体有两个方案:直接改输入矩阵 X ,或者改self-attention的算法。显然改输入矩阵更直观和方便。
确定修改输入矩阵后,我们再考虑到位置信息作用在input embedding上。比起用单一的值,更好的方案是用一个和input embedding维度一样的向量来表示位置。只要让positional encoding生成的positional embedding和token embedding一样长,就能直接相加获得与原来相同大小的新输入矩阵,不需要修改self-attention算法。
避免重复
接下来我们看看为何为向量的每个维度设置一个周期。
我们先假设使用sin函数来生成位置编码。因为正弦图像是具有周期性的,如果各个维度使用同一sin函数,比如\(PE(pos)=sin(pos)\)。因为可能会出现不同的位置是一个值的情况,那么维度之间就会出现相关性,就不能有效的使用全部的高维度空间作为编码空间,也就失去了位置编码的意义,因为如何让不同词之间分开才是位置编码的目的。
因此不能直接使用pos,我们可以加入一个alpha参数来调控位置函数的波长。
如前文所述,token的embedding维度是\(d_{model}\),则位置编码的维度也是\(d_{model}\),那么这个\(d_{model}\)维度向量的不同维度上可以采用不同的\(\alpha\) 。假设\(\alpha\)就设定为维度的index,即,
我们得到如下公式。这一行代表第t个token的位置编码\(PE_t\),行中的第i个元素就是\(PE_t\)中的第i个维度的元素。这样每个维度sin函数的周期不同,就会降低重复的几率。
我们再来讨论下调控参数(或者叫做底数)\(\alpha\)的取值。实际上,Transformer位置编码中的分母 \(10000^{2i/d_{model}}\)就是\(\alpha\),我们可以通过α来调节函数周期。
- \(\alpha\) 如果比较小,\(pos/\alpha\)则容易很大,会导致函数的频率偏大,引起波长偏短,周期偏小,这样很容易进入下一个周期,从而出现不同t下的位置向量可能出现重合的情况,在长文本中还是可能会有一些不同位置的字符的编码一样(一个较小的t和一个较大的t代表的向量可能会重合)。因此需要拉长波长(三角函数周期)来确保不同位置的向量不发生碰撞,这就要把所有的频率都设成一个非常小的值,就是取较大的\(\alpha\)来减少重复几率。
- \(\alpha\) 如果比较大,位置向量能表示的序列就越长,这是大底数的好处。但是 \(\alpha\)如果过大,意味着周期越大,在-1到+1的范围内向量的取值越密集,则相邻token的位置编码差异较小,向量几乎重合。这对后续的Self-Attention模块来说是不利的,因为它需要经历更多的训练次数才能准确地找到每个位置的信息,或者说,才能准确地区分不同的位置。而且,长序列需要长编码。但这样又会增加计算量,特别是长编码会影响模型的训练时间。所以,底数并非是越大越好。
所以,\(\alpha\)的取值要定在一个合适的范围。我们进一步细化,把分母改写为\(\alpha ^{2i/d_{model}}\),这样更加清晰。对于\(\alpha\),Transformer作者取了一个实验上的经验数值10000。使用 10000 很可能就是确保循环周期足够大,以便编码足够长的文本。
区分特征维度
引入多个维度之后就会在高维的表示空间对位置编码以及token的语义做进一步细分,不止是按照一个一个词来分,而是按照词和词嵌入的特征来分,让不同维度刻画不同特征,在不同维度表示单一位置的不同信息,体现位置的差异性。比如高频分量对应局部语义影响,低频分量对应长上下文语义影响。在不同维度上用不同的函数,能够进一步增强这种差异性。这样不仅不同词之间分开了,同一个词不同的特征之间也能区分出来。
除此之外,从模型可解释性出发,位置编码,尤其是包含相对偏置的编码方案,为特征向量$ q_t,k_s$ 的不同维度赋予了不同的实际含义。增加了Transformer架构的可解释性。
3.3 为何要多种频率
位置编码存储的是一个包含各频率的正弦和余弦对,但是为什么用包含各多种频率的三角函数?其实,此问题和上一个问题有一定关联,因此放在一起分析。多种频率有几个好处:
-
可以使得不同位置的编码向量之间有一定的规律性(这是由正弦和余弦函数的连续性和单调性来保证的)。比如相邻位置之间的差异较小,而距离较远的位置之间的差异较大,即:
- 对于任意两个相邻的位置,它们对应的编码向量在每一个维度上都只有微小的变化。
- 对于任意两个距离较远的位置,它们对应的编码向量在每一个维度上都有较大的差异。
-
可以使得编码向量在任意维度上都能保持唯一性,即,对于任意两个不同的位置,它们对应的编码向量在这些维度上不会完全相等(这是由正弦和余弦函数的周期性和相位差保证的)。注:接下来会对周期性做严格分析。
-
和时钟系统有点类似,时针分针秒针分别表示不同粒度的时间。这里则用不同的颗粒度来捕获更细粒度的位置信息。
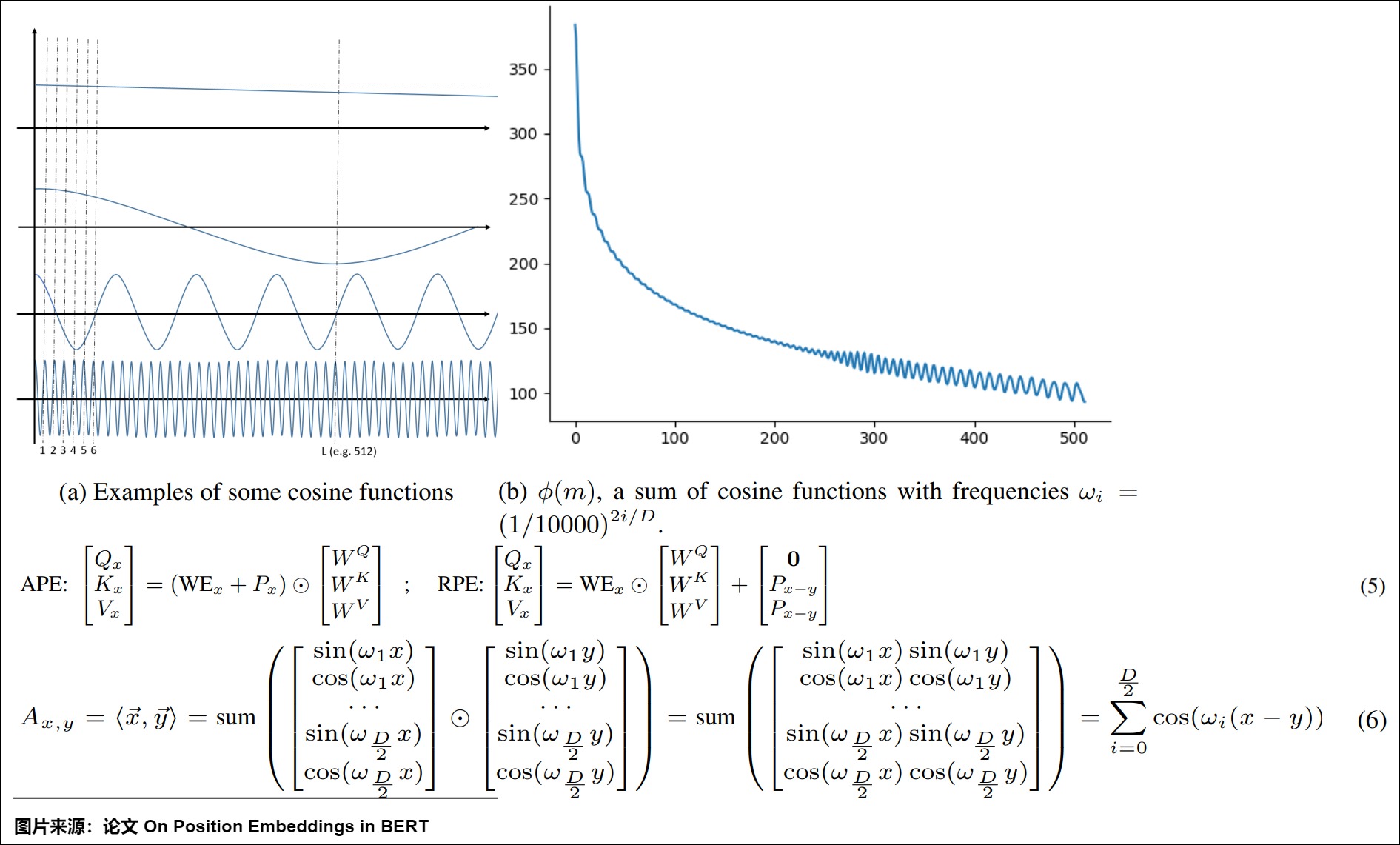
这种模式可以自适应地调整频率以满足不同的功能。比如上图(b), \(\phi(m)\)是单个频率的多个余弦函数之和,它决定了任意两个m距离位置向量之间的接近度,这里m是增加趋势。如(a)所示,每个频率可以发挥不同的作用:
- 极小的频率对公式中的整体单词表示(\(WE_x+P_x\))几乎没有影响,因为它使这种位置嵌入随着位置的增加而几乎相同。
- 一些较小的频率(\(ω_i<\frac{\Pi}{L}\))可能有利于保证单调性(随着距离的增大而衰减)。
- 一些更大的频率会促进局部参与机制,因为如果\(ω_i\)足够大,方程6中的cos函数在开始时会急剧下降。
- 一些大频率(\(ω_i>\Pi\))将是整体模式的平滑因子,因为它会随机地对所有位置施加偏差。
3.4 为何同时使用cos,sin
同时使用cos,sin的主要原因是:
- 让相近位置的单词更容易区分。如果两个词距离很近,则其携带信息其实是类似的,这样如果两个词转换为向量,则其在向量空间内就会距离很近,容易互相影响。如"I love reading books",reading和books它们一起出现的概率是较大的(对应于离得近的词)。因此,语义相近的单词一定要在位置上可以很容易的区分出来。为了让两个相邻的维度产生差异,对位置不同进行差异化刻画,Transformer在偶数维度用正弦,奇数维度用余弦。
- sin/cos交替可以让周期变得更长。
- sin/cos交替可以让模型很容易地计算出相对位置。对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B),即sin(x+k)和cos(x+k)都可以用二者表示出来。
另外,知乎上有帖子也对“是否一定设置奇偶下标 2i 和 2i+1”展开了讨论。讨论中提到 tensor2tensor 的最初版本只是简单地分了两段(前 256 维使用 sin,后 256 维使用 cos),并且tensor2tensor的作者解释是因为后面的全连接层可以帮助重排坐标,所以sin 和 cos 这个交错形式没有特别的意义,我们可以按照任意的方式重排它。相关代码如下:
return tf.concat([tf.sin(scaled_time), tf.cos(scaled_time)], axis=1)
// PE(pos, 0:channels/2) = sin(scaled_time)
// PE(pos, channels/2:) = cos(scaled_time)
tensor2tensor作者回复引用如下:
I think this does not matter, since there is a fully connected layer after the encoding is added (and before) and it can permute the coordinates.
3.5 表示绝对位置
接下来我们看看为何三角函数可以表示绝对位置,其实,这也是对三角函数优点的解读。
结论
我们先说结论,使用多个周期不同的周期函数组成的多维度编码和递增序列编码其实是可以等价的。这也就回答了为什么周期函数能够引入位置信息。实际上,只要能找到多个周期不同但特征相同(例如余弦函数的波形都是相同的,这就是特征相同)的函数,理论上都可以用来做positional encoding。
解读
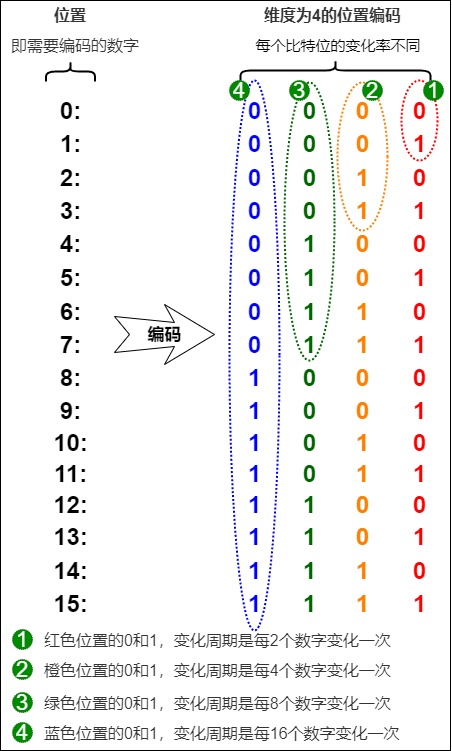
我们使用网上传播非常广的例子作为样例。因为转换进制可以理解为使用多维数据来表示相同含义,所以我们可以用二进制位置编码法来代替三角函数编码。如下图,假设有一个序列有16个token,且embedding size为4,我们就能用二进制编码法得出每个token的positional embedding,而且可以发现如下规律。
- 不同位置上的数字交替变化。每一列上的数字都是0,1交替变化。
- 每个维度(也就是每一列)其实都是有周期的,但是不同列上周期变换的规律不同。每个比特位的变化率是不一样的,越低位的变化越快,最后一位数字每次都会0、1交替;倒数第二位置上两个交替一次,以此类推。即红色位置0和1每个数字会变化一次,而橙色位,每2个数字才会变化一次。即,第i列上的周期为\(2^i\)个数据交替一次。
这其实也在一定层度上回答了为什么周期函数能够引入位置信息。而三角函数编码中正余弦的交替在某种意义上等价于位置的二进制表示的alternating bits。
周期性
我们接下来看看周期性会不会重复。
首先,我们采用网上同样经典的钟表例子,来看看钟表视角下的高维旋转。一块钟表有三根针:
- 秒针:走得最快。
- 分针:走得中等。
- 时针:走得最慢。
这三个频率各不相等的圆周运动就构成了时刻。当两块表摆在你面前时,即使走得最快的秒针重合了,但是如果走得较慢的分针和时针不一样,他们照样能代表不同的时刻。
正弦编码的公式就定义了一个“钟表”,“钟表”有d/2根指针,d就是编码的长度,i表示指针的序号。指针的位置可以唯一地由一对正余弦值表示,即(sinθ,cosθ),其中θ是指针与水平方向的夹角。不同指针的频率不同,第0根指针的频率是1,最后一根指针的频率是1/10000。相邻两个指针的频率呈一个固定的倍数关系,即中间的指针按等比数列的规律排列。很显然,不同的位置编码唯一对应“钟表”的“一个时间点”。我们知道,钟表是有周期的,12小时一个周期。正弦编码也有周期,如果选择得当,就会即表达了位置信息,也具备一定的外推性。
其次,我们看看在正弦编码中如何选择才能保证任意一个子空间内,位置编码都是唯一的,从而避免重复。
注:i 表达位置在序列中的独特性,由底数决定每个子空间的不同,子空间内部由sin,cos来区分。
三角函数的性质如下:
- (sinx, cosx)组成的向量对的周期是\(4\pi\)
- 假设在第k个子空间内,i,j位置发生了重复,那么存在整数m,使得\(j\theta_k - i\theta_k=4m\pi\),那么\(\theta_k=\frac{4m\pi}{j-i}\)
- 在任意第k个子空间内,只要\(\theta_k\)公式中不含有\(\pi\),则旋转角度序列\(\{{i\theta_k}\}_i\)都不会出现周期性重复。
因此,在设置合适的𝜃值的前提下,每个位置都能取到唯一的位置编码,这体现了位置编码的绝对性。
最后,我们看看周期内的一些特殊节点。记\(B=10000^{1/d}\),那么\(\theta_k=\frac{1}{B^{k-1}}\)是一个等比数列,其周期如下。
| 0 | \(1/B\) | \(1/B^2\) | ... | \(1/B^{d-1}\) | |
|---|---|---|---|---|---|
| 周期 | \(2\pi\) | \(2B\pi\) | \(2B^2\pi\) | ... | \(2B^{d-1}\pi\) |
在这个过程当中,有三个节点非常的关键,分别是\(\pi\)/2, \(\pi\), 2\(\pi\)。
- 只有当cos/sin内部的取值在训练阶段遍历0到\(\pi\)/2,模型才会意识到cos为负、sin不单调;
- 只有当cos/sin内部的取值达到\(\pi\),模型才会意识到cos不单调、sin为负;
- 只有当cos/sin内部的取值达到2\(\pi\),模型才能感知到所有的可能的cos/sin取值,进而可能意识到每个维度位置编码的周期性表示(真正意识到周期性表示可能需要在训练长度范围内经历一轮以上的周期)。
3.6 表示相对位置
相对语义的重要性
语义应该是和相对位置更加有关,而不是绝对位置,即i和j之间的语义相似性计算应该依赖向量还有相对距离,而不依赖其绝对位置。
之前我们对三角函数位置编码的推演如下:
PE形式只用sin()还没有解决相对性,如果能够实现任意位置的编码只需通过一个相对值的变换即能转换到距离当前同样相对值的位置编码表示的形式,则这种编码方式才可实现相对性的特性。所以我们对位置向量再提出一个要求,不同的位置向量是可以通过线性转换得到的。这样,我们不仅能表示一个token的绝对位置,还可以表示一个token的相对位置。这就需要cos函数的加入。此处其实也是部分回答了如下问题:为何用sin和cos交替来表示位置?
结论
我们也先说结论。所以三角式位置编码作为一种绝对位置编码,也包含了一定相对位置信息,即三角函数式位置编码可以用绝对位置编码来捕捉不同位置之间的相对关系。其原因是因为三角函数有如下性质:
这说明sin-cos位置编码具有表达相对位置的能力,即位置\(\alpha + \beta\)向量可以表达为位置\(\alpha\)向量和位置\(\beta\) 向量的组合。因此可以得到两个结论:
- 两个位置编码的点积仅取决于偏移量(相对位置),即两个位置编码的点积值可以反映出两个位置编码间的距离。
- 给定距离,任意位置的位置编码都可以表达为一个已知位置的位置编码的关于距离的线性组合。
证明
结论1是:时间步p和时间步p+k的位置编码的内积,即 \(PE_p . PE_{p+k}\) 是与p无关,只与k有关的定值。也就是说,任意两个相距k个时间步的位置编码向量的内积都是相同的,这就相当于内积蕴含了两个时间步之间相对位置关系的信息。
首先,下面是点积的计算。可以看到,两个位置向量的内积只和相对位置 𝑘 有关。
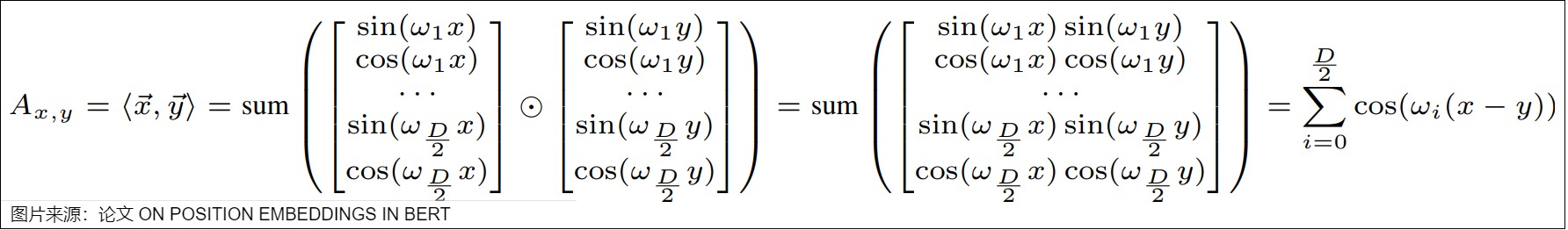
其次,具体证明过程如下,这里\(c_i\)是\(\frac{1}{10000^{\frac{2i}{d_{model}}}}\),其中,d 表示位置嵌入的维度
公式中用到了三角变换公式:

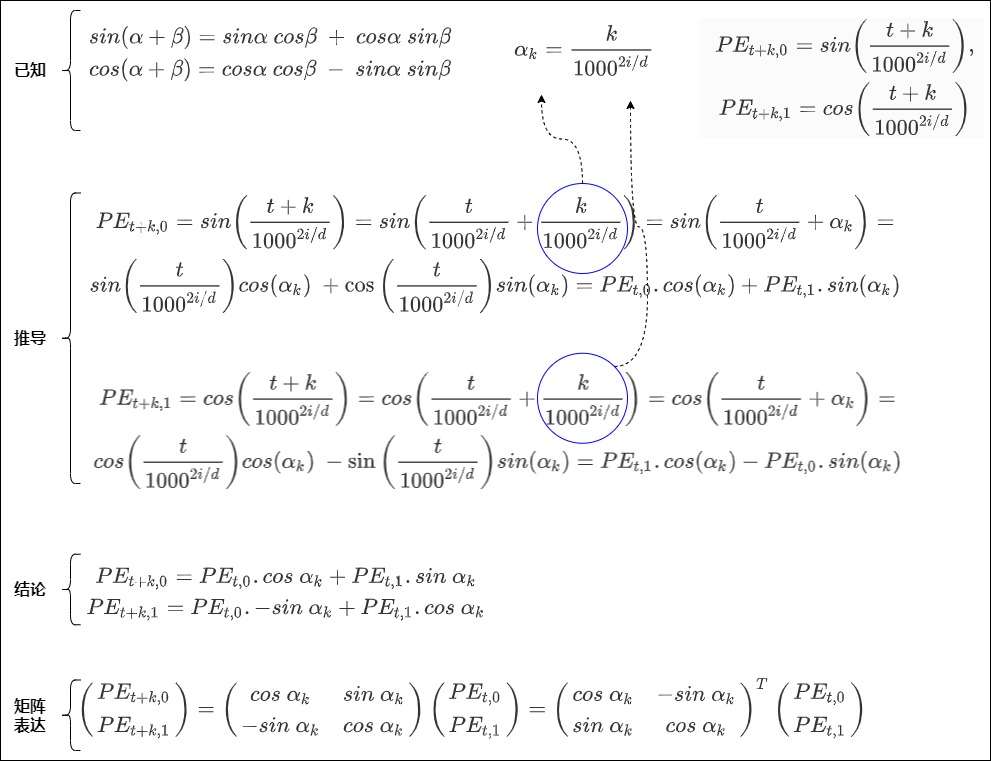
结论2是:相隔 k 个词的两个位置 pos 和 pos+k 的位置编码是由 k 的位置编码定义的一个线性变换,即\(PE_{pos+k}\)可以表示成\(PE_{pos}\)的线性函数。具体证明如下。
首先做简化,把pos用t来表示,把 \(d_{model}\)用d表示,使用1000。这样在三角式位置编码中,位置 t 对应的位置向量在偶数位和奇数位的值分别为:
已知三角恒等式如下:
假设位置编码的维度是2,即i=0的情况。有
假设
得到
以及
即
因为任何变换三角函数参数的运算T都必须是某种旋转,而旋转可以通过对(余弦,正弦)对来应用线性变化完成。所以我们用矩阵来把上面公式重新表示,得到。
这说明\(PE_{t+k}\) 可以分解为一个“与相对距离k有关的矩阵”和\(PE_t\)的乘积。假定这个“与相对距离k有关的矩阵”为\(R_k\),则有 \(PE_{t+k} = R^T_k . PE_t\),进一步可以得到
即有 \(R_{k_1+k_2} = R_{k_1}R_{k_2}\)。
另外依据 \(-sin\ \alpha_k = sin\ -\alpha_k\)和\(cos\ \alpha_k = cos \ - \alpha_k\),可以得到 \(R_{k_1} = R^T_{-k_1}\),进一步有
证明完成。我们再用一张图片总结如下:
或者我们进一步来拓展。
因此得到
因为相对距离k是常数,因此 \(PE_{k,2i}\)和\(PE_{k,2i+1}\)是常数。,分别简写为 u, v 可得下式:
\(PE_{t+k}\)可以表示为\(PE_t\) 的线性变换表示。作者希望借助上述绝对位置的编码公式,让模型能够学习到相对位置信息。我们继续拓展上面图得到如下。

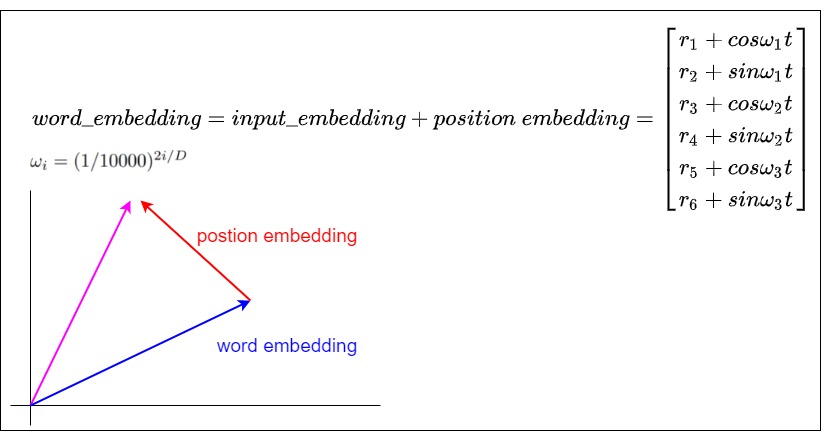
3.7 旋转
从一个角度来看,\(PE_{t+k}\)是\(PE_t\)按照顺时针旋转得到的。公式就是根据向量的下标两两配对,分成多组,每一组的二维向量根据 位置信息 进行 顺时针旋转 ,旋转的角度跟相对位置是线性关系。证明如下。

从另一个角度来看,三角函数式位置编码其实就是以旋转的方式给词向量注入位置信息。如果我们是用加法将词向量和位置向量合在一起,也相当于是在原始的词向量上施加一个平移。
3.8 为何是相加
此问题是:为什么位置编码是和词嵌入相加而不是将二者拼接起来?关于此问题也有很多讨论和分析。我们具体学习下。
- 解释1:无论拼接还是相加,最终都要经过多头注意力的各个头入口处的线性变换,进行特征重新组合与降维,其实每一维都变成了之前所有维向量的线性组合。而拼接会导致维度增加,需要再经过一个线性变换降低维度,这样会扩大参数空间,占用内存增加,而且不易拟合。和拼接相比,相加是先做线性变换后融合,可以节约模型参数。
- 解释2:相加,在一定程度上保持了token和position这两个embedding空间的独立性,体现的是一种特征交叉;拼接会让2个embedding空间被融合成了一个统一的大embedding空间,这时候再做线性变换只是相当于降维或者说池化。其实在数学上是等价的,用哪种方案都行。
0x04 三角函数编码的特性
我们已经知道了三角函数编码的一些优秀特性。
- 在设置合适的𝜃值的前提下,每个位置都能取到唯一的位置编码(绝对性)。
- 一个位置编码可以由另一个位置编码旋转而来(相对性)。
我们接下来看看三角函数编码的一些其它特性。
4.1 无向性
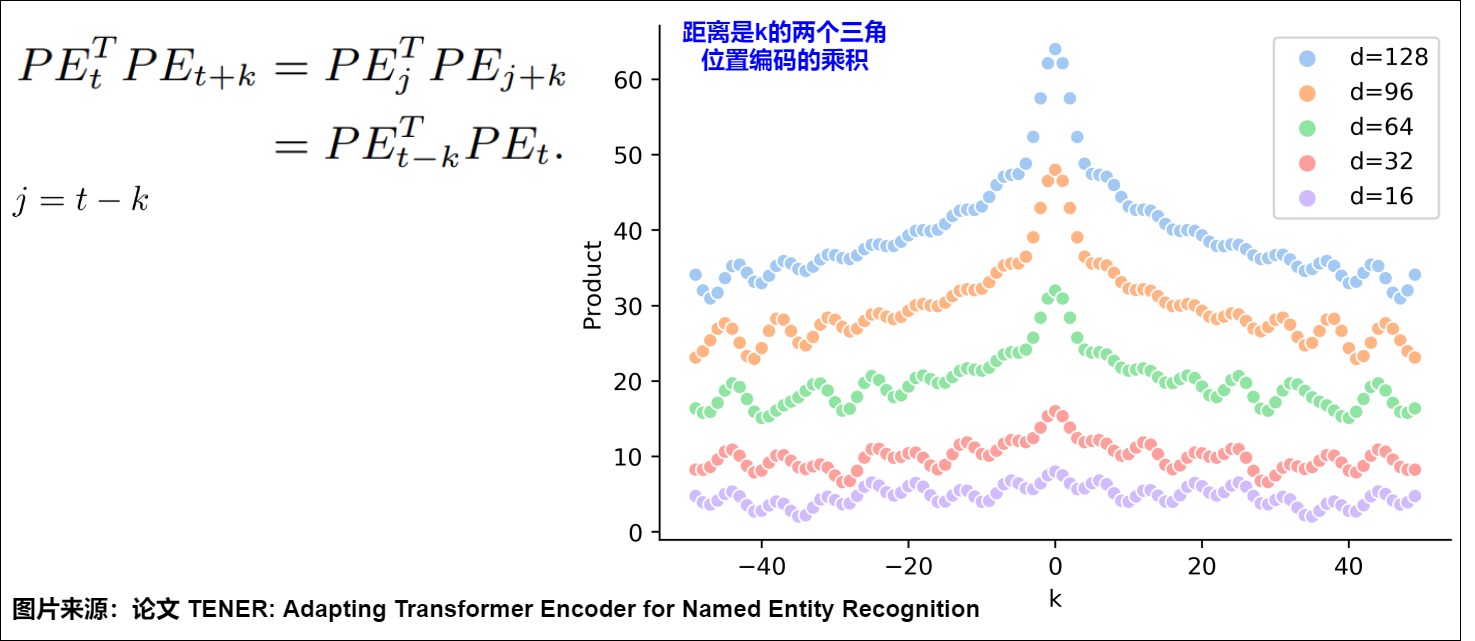
正弦位置编码的一个特性是:相邻时间步之间的距离是对称的,并随时间衰减。这说明三角函数位置编码无法学习到方向。其原因是因为两个token之间的距离只和相对距离k有关,和位置t或者j无关,所以位置t->t+k之间的距离,和 位置j->j+k之间的距离是相等的。具体如下图所示,图上一些基础信息如下:
- 横轴表示 Δ。
- 纵轴表示固定某个 \(𝑃𝐸_𝑡\) 的情况下,改变 Δ 后得到的 \(𝑃𝐸_𝑡\) 和 \(𝑃𝐸_𝑡+Δ𝑡\) 的内积。
- d表示不同的hidden_size。
我们可以看到 \(𝑃𝐸_𝑡^𝑇∗𝑃𝐸_{𝑡+Δ𝑡}\) 的变动趋势为:
- 在固定某个𝑃𝐸𝑡的情况下,两个位置编码的内积具有对称性。
- 在固定某个𝑃𝐸𝑡的情况下,两个位置编码的内积具有远程衰减性,即两个位置编码相距越远,点积值越小,但是不具备单调性。
这说明位置向量的点积虽然可以反映相对距离,但因为点积的结果是对称的,它并没有学习到位置的方向性。
4.2 远距离衰减性
远程衰减性(Distant Decay)是指位置编码应能捕获到序列中位置信息和长距离依赖关系(相隔较远的单词之间的关系)。具体来说就是:
- 当两个位置相隔较远时,它们的编码相差较大,相似度较低,这有助于模型区分这些位置,更好地理解和区分序列中的词序关系。
- 而当两个位置相隔较近时,它们的相似度较高,这有助于模型理解它们之间的关系。
远程衰减的先验是:文本是离散时序数据,我们通常会假设文字之间距离越近相关性越强。即位置相近的Token平均来说获得更多的注意力,而距离比较远的Token平均获得更少的注意力。在此先验条件下,良好的震荡曲线应该具备如下特点:可以在无限长度下保持连续单调衰减;衰减曲线是非线性的,近距离衰减变化迅速, 远距离衰减平缓;在衰减过程中,尽可能少震荡。其实,位置编码对自注意力的局部化可以想象成从全自注意力到卷积的过渡:如何没有位置编码,随意让token的语义无视相对距离交互,就会让序列失去顺序信息的同时,以无关语义干扰token特征的刻画;如果位置编码自注意力局部化过于显著,则Transformer模块刻画token特征时只能看到邻近位置token,那就和CNN没什么区别了。因此如何设计好位置编码随相对距离的下降曲线就显得尤为重要。
在使用正弦和余弦函数的位置编码方法中,不同位置的词的位置编码是通过正弦和余弦函数生成的。这种方法可以捕获到不同位置之间的关系,并且具有良好的远程衰减性。在设置合适的𝜃值的前提下,两个位置编码的内积大小可以反应位置的远近,内积越小,距离越远(衰减性)。具体如上图所示,随着相对距离的增加,位置向量的内积结果会逐渐降低,即会存在远程衰减。
但是我们也发现,在长距离下,衰减性并非预期单调下降,而是包括两种震荡:一种是局部窗口内的震荡,一种是随距离收敛到一定波动范围。其带来的影响是使得位置编码更倾向于捕捉局部信息,限制了远程交互的影响。这种特性对短序列有效,但对长序列可能受限,即造成 Sinusoidal 位置编码外推性一般。另外,这些震荡将会放大建模误差,这也是其中一个长文本难训的原因。
4.3 外推性
长度外推能力(extrapolation,也称length extrapolation):如果模型在不经微调的情况下,在超过训练长度的文本上测试,依然能较好的维持其训练效果,我们就称该模型具有长度外推能力。相反,如果大模型由于训练和预测时输入的长度不一致,导致模型泛化能力下降,我们就说模型的外推性存在问题。如何让位置编码在保证分布内表现的前提下,提升其外推表现,是设计位置编码的一个重要权衡。因为Sinusoidal位置编码中的正弦余弦函数具备如下特点,所以理论上也具备一定长度外推的能力。
- 有显式的生成规律。
- 周期性。
- 可以表达相对位置。因为$\sin (\alpha+\beta)=\sin \alpha \cos \beta+\cos \alpha \sin \beta $ , \(\cos (\alpha+\beta)=\cos \alpha \cos \beta-\sin \alpha \sin \beta\) ,这表明位置 \(\alpha + \beta\) 的向量可以表示成位置 \(\alpha\) 和位置 \(\beta\) 的向量组合,提供了位置拓展的可能性。
- 内积具备远程衰减的特性。
问题
然而实际上,三角函数编码在外推性上的表现不甚理想。部分是因为,sin和cos是高频振荡函数,不是直线或者渐近趋于直线类的函数,往往外推行为难以预估。
论文”TENER: Adapting Transformer Encoder for Named Entity Recognition“对这个问题做了精彩的实验和分析。为了更详细探究这个问题,论文假设:
- \(𝑥_𝑡\),\(𝑥_{𝑡+Δ𝑡}\) 分别为两个不同位置的原始token向量,其尺寸为
(hidden_size, 1) - \(𝑃𝐸_𝑡\),\(𝑃𝐸_{𝑡+Δ𝑡}\) 分别为两个不同位置的原始PE向量,其尺寸为
(hidden_size, 1) - \(𝑊_𝑄\),\(𝑊_𝐾\) 分别为尺寸为
(hidden_size, hidden_size)的Q、K矩阵
应用了sinusoidal位置编码的q和k点积如下:
从中我们不难发现,经过attention层后,位置编码真正起作用的不再是 \(𝑃𝐸_𝑡^𝑇𝑃𝐸_{𝑡+Δ𝑡}\) 这两个位置变量都相关的部,而是引入了线性变化后的 \(𝑃𝐸_𝑡^𝑇𝑊_𝑄^𝑇𝑊_𝐾𝑃𝐸_{𝑡+Δ𝑡}\) 。那么在引入这种线性变化后,位置编码还能保持上述所说的绝对性、相对性和远距离衰减性这种优良性值吗?论文用实验的方式来细看这一点。由于 \(𝑊_𝑄^𝑇𝑊_𝐾\) 本质上可以合成一种线性变化,所以我们可以随机初始化一个线性矩阵W来代替它。从下图我们可以看出看固定住某个t之后,变动 Δ 的点积结果。
- 浅蓝色代表:两个不同位置sinusoidal位置编码的点积\(𝑃𝐸_𝑡^𝑇∗𝑃𝐸_{𝑡+Δ𝑡}\),确实有很好的远程衰减,可以反映出两个位置编码间的距离。
- 黄色和绿色代表:引入两个随机初始化的线性变化的矩阵的点积。PE矩阵乘以W权重矩阵之后,没有明显规律了。表明引入线性变化后,\(𝑃𝐸_𝑡^𝑇∗𝑃𝐸_{𝑡+Δ𝑡}\)变成了\(𝑃𝐸_𝑡^𝑇W𝑃𝐸_{𝑡+Δ𝑡}\),原始位置编码的优良性质(远程衰减性等)都受到了极大程度的破坏,其内积所反映的距离因素效果就被破坏。
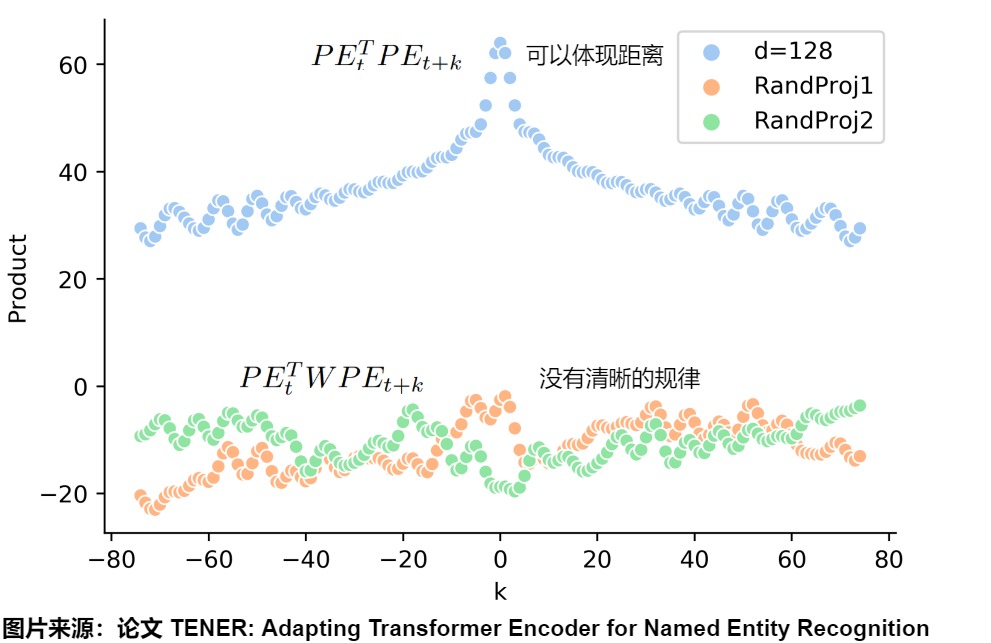
其原因在于:最初Transformers的位置编码巧妙的引入周期性变化的三角函数公式保证其值有界性,同时三角函数的加减变化的公式也满足了相对性。但这种相对位置信息仅仅包含在位置编码内部。当word embedding(位置编码和输入层的token相加)进入自注意力内部时,情况就发生了变化,此时,真正起作用的不是两个位置编码的乘积,位置编码还要乘上两个投影矩阵,而引入这个投影矩阵后,位置信息会被损坏,丢失了远程衰减这个性质。
苏神在其博客中也说到。\(cos(q_i,k_j)\)的训练不充分是Attention无法长度外推的主要原因。
第 i 个token与第 j 个token的相关性打分由内积完成:\(s(j|i)=q_i⋅k_j=∥qi∥∥kj∥cos(q_i,k_j)\)。第二个等号,我们从几何意义出发,将它分解为了各自模长与夹角余弦的乘积。如果模长不变,\(cos(q_i,k_j)\)变小,则意味着相距较远的两个位置编码的内积越小,即内积可以用于反馈两个位置向量在绝对位置上的远近。
为了提高某个位置j的相对重要性,模型有两个选择:
- 增大模长∥kj∥;
- 增大\(cos(q_i,k_j)\),即缩小\(q_i,k_j\)的夹角大小。
然而,由于“维度灾难”的存在,在高维空间中显著地改变夹角大小相对来说没有那么容易,所以模型会优先选择通过增大模长来完成,这导致的直接后果是:\(cos(q_i,k_j)\)的训练可能并不充分。被训练过的\(q_i,k_j\)的夹角只是一个有限的集合,而进行长度外推时,它要面对一个更大的集合,从而无法进行正确的预测。
论证
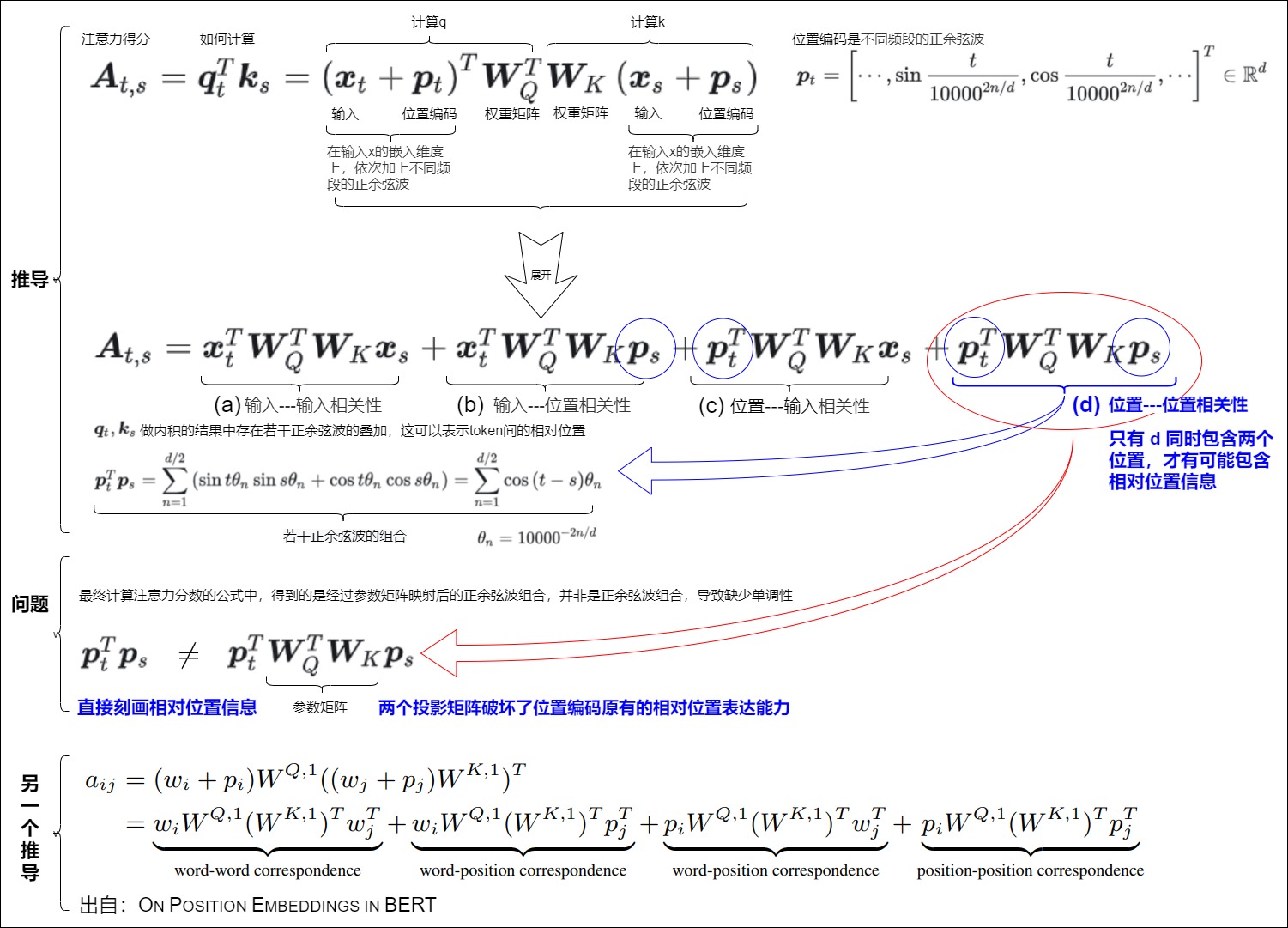
sinusoidal位置编码是在输入x的嵌入维度上,依次加上不同频段的正余弦波。这样,两个sinusoidal位置编码的点积结果中存在若干正余弦波的叠加,这可以表示token间的相对位置。
下面假设t,s这两个词。\(W^T_Q\)和\(W_K^T\)是权重矩阵,\(x_t\)和\(x_s\)是词嵌入,\(p_t\)和\(p_s\)是第t, 第s个位置的位置向量。我们希望\(p_t^Tp_s\)是\(g(i-j)\)。即是相对位置相关。从下图来看。
-
(a)是词的内容信息,是两个词的相关性,和位置向量和位置编码没关系。
-
(b)和(c)是词和位置的相关性,都只有一个位置的向量,是关于绝对位置编码的信息,所以也不包含相对位置信息。
-
(d)同时包含\(p_t\)和\(p_s\),是最有可能包含相对位置信息的,可以借此得到两个位置的相关性。
按照Vanilla Transformer的位置编码方法,如果没有\(W_Q\)和\(W_K\),那么,(d)只包含相对位置信息。但是,最终计算注意力分数的公式中,得到的是经过参数矩阵映射后的正余弦波组合,并非是正余弦波组合。中间加入一个“不可知”的线性变换以后,就没有相对位置信息了,即两者的点积无法反映方向性,导致缺少单调性。
这样,虽然原始transformer中的正弦位置编码其实就是一种想要通过绝对位置编码表达相对位置的位置编码,从而希望正弦位置嵌入能够推断出比所看到的更长的序列。但是研究人员随后发现,正弦APE很难外推。
因此,人们提出了各种APEs和RPEs,以增强正弦位置编码,从而增强Transformer的外推。后续我们会分析这些方案如何在刻画序列内部不同位置间的相对距离、控制自注意力矩阵不同位置的偏置大小的基础上,去左右模型的参数学习过程与最终效果。
0x05 NoPE
位置编码是Transformer模型的一个关键部分,它使模型能够处理序列数据,捕捉到元素之间的顺序关系。尽管存在一些限制,但它的引入是实现高效并行处理的重要步骤。然而位置编码似乎像是个临时的救火队长或者说权宜之计。因此有人认为位置编码不那么重要,尤其是Decoder-only模型基于Causal Attention,而Causal Attention本身不具备置换不变性,所以它原则上似乎不需要位置编码(NoPE)。当然也有研究人员认为即便是Decoder-only模型,也需要PE。我们接下来看看这些观点。
5.1 不需要
已经有研究证明,无位置编码(NoPE)的 Transformer 已经被证明在自回归语言模型任务上和 Transformer+RoPE 效果相当,这些任务包括。
- 因果关系自回归模型:在自回归模型(如GPT系列)中,因果注意力机制(causal attention mechanism)通过限制每个元素只能与之前的元素进行交互,从而隐含地引入了位置信息。尽管显式的位置编码可以提高模型性能,但一些研究表明,即使没有显式位置编码,这类模型也能够学习到一定的位置信息。
- 特定的非序列任务:对于一些不依赖于元素顺序的任务,如某些类型的图像分类,位置编码可能不是必需的,因为模型的目标可能更多地侧重于提取全局特征而非理解元素间的顺序关系,加上位置编码甚至可能还会导致性能下降。
具体可以参见。
Haviv, A., Ram, O., Press, O., Izsak, P., & Levy, O. (2022). Transformer Language Models without Positional Encodings Still Learn Positional Information. (EMNLP 2022).
Chi, T.C., Fan, T.H., Chen, L.W., Rudnicky, A., & Ramadge, P. (2023). Latent Positional Information is in the Self-Attention Variance of Transformer Language Models Without Positional Embeddings. (ACL 2023)
Kazemnejad, A., Padhi, I., Natesan Ramamurthy, K., Das, P., & Reddy, S. (2023). The Impact of Positional Encoding on Length Generalization in Transformers. (NeurIPS 2023).
论文“Length Generalization of Causal Transformers without Position Encoding”也提出了适用于 NoPE 的长度泛化方法。该论文讨论了无位置编码(NoPE)模型的长度泛化性问题。作者发现,通过简单的注意力缩放(引入 SoftMax 温度超参让注意力强制集中)就能显著提升 NoPE 的长度泛化能力,但是对 RoPE 没有显著效果。论文认为,NoPE 去除了显式位置编码的干扰,直击模型内部的位置信息表示。
5.2 需要
下面引用苏剑林大神的结论:NoPE对于长文本可能会存在位置分辨率不足、效率较低、注意力弥散等问题,所以即便是Decoder-only模型,我们仍需要给它补充上额外的位置编码(特别是相对位置编码),以完善上述种种不足之处。
NoPE主要是通过hidden state向量的方差来表达位置信息的。“Causal + NoPE”实际上是将位置信息隐藏在了𝑦的分量方差之中,或者等价地,隐藏在𝑦的\(l_2\)范数中。它相当于说𝑦𝑛是由某个不带位置信息的向量𝑧𝑛乘上某个跟位置𝑛相关的标量函数𝑝(𝑛)得到,这又意味着:
- NoPE实现的是类似于乘性的绝对位置编码,并且它只是将位置信息压缩到单个标量中,所以这是一种非常弱的位置编码
- 单个标量能表示的信息有限,当输入长度增加时,位置编码会越来越紧凑以至于难以区分,比如极简例子有\(p(n)∼\frac{1}{\sqrt n}\),当n𝑛足够大时\(\frac{1}{\sqrt n}\)与\(\frac{1}{\sqrt {n+1}}\)几乎不可分辨,也就是没法区分位置𝑛与𝑛+1;
- 主流的观点认为相对位置编码更适合自然语言,既然NoPE实现的是绝对位置编码,所以效率上自然不如再给模型额外补充上相对位置编码;
- NoPE既没有给模型添加诸如远程衰减之类的先验,看上去也没有赋予模型学习到这种先验的能力,当输入长度足够大可能就会出现注意力不集中的问题。
0xFF 参考
Position Information in Transformers: an Overview
Transformer Architecture: The Positional Encoding
一文读懂Transformer模型的位置编码
机器翻译:基础与模型
让研究人员绞尽脑汁的Transformer位置编码
[Transformer位置编码(意义)河畔草lxr](https://www.zhihu.com/people/liuxiaoran-34)
[深度学习] 自然语言处理---Transformer 位置编码介绍 舒克与贝克
A Gentle Introduction to Positional Encoding in Transformer Models, Part 1
baiziyu:基于端到端注意力网络的英德翻译-1
baiziyu:基于端到端注意力网络的英德翻译-2
Decoder-only的LLM为什么需要位置编码? 苏剑林
https://arxiv.org/pdf/2006.15595.pdf
https://github.com/guolinke/TUPE
HuggingFace工程师亲授:如何在Transformer中实现最好的位置编码 [机器之心]
LANGUAGE TRANSLATION WITH TORCHTEXT
Learning to Encode Position for Transformer with Continuous Dynamical Model
Length Extrapolation of Transformers: A Survey from the Perspective of Positional Encoding Liang Zhao, Xiaocheng Feng, Xiachong Feng, Dongliang Xu, Qing Yang, Hongtao Liu, Bing Qin, Ting Liu
Length Generalization of Causal Transformers without Position Encoding
LLM - 通俗理解位置编码与 RoPE BIT_666
LLM中use_cache作用、past_key_value的使用机制
LLM时代Transformer中的Positional Encoding
LLM(廿三):LLM 中的长文本问题 紫气东来
On Position Embeddings in BERT
Sinusoida 位置编码详解 Zhang
TENER: Adapting Transformer Encoder for Named Entity Recognition
Transformer Architecture: The Positional Encoding Amirhossein Kazemnejad's Blog
Transformer Architecture: The Positional Encoding
transformer中: self-attention部分是否需要进行mask?
Transformer中的position encoding 青空栀浅
Transformer位置编码(基础) 河畔草lxr
Transformer位置编码(意义)[河畔草lxr]
Transformer位置编码(改进) [河畔草lxr]
Transformer升级之路:15、Key归一化助力长度外推 苏剑林
Transformer升级之路:16、“复盘”长度外推技术 苏剑林
Transformer升级之路:18、RoPE的底数设计原则 苏剑林
Transformer升级之路:1、Sinusoidal位置编码追根溯源
Transformer学习笔记一:Positional Encoding(位置编码) 猛猿
“追星”Transformer(二):基于Transformer的预训练模型GPT 铁心核桃
《Convolutional Sequence to Sequence Learning》
《中文语言模型研究:(1) 乘性位置编码》 PENG Bo
【OpenLLM 009】大模型基础组件之位置编码-万字长文全面解读LLM中的位置编码与长度外推性(上) OpenLLMAI
【OpenLLM 009】大模型基础组件之位置编码-万字长文全面解读LLM中的位置编码与长度外推性(上) OpenLLMAI
【OpenLLM 010】大模型基础组件之位置编码-万字长文全面解读LLM中的位置编码与长度外推性( 中) OpenLLMAI
一文搞懂Transformer的边角料知识:位置编码 小殊小殊
一文通透位置编码:从标准位置编码、欧拉公式到旋转位置编码RoPE v_JULY_v
万字逐行解析与实现Transformer,并进行德译英实战(一) iioSnail
万字逐行解析与实现Transformer,并进行德译英实战(三)
万字逐行解析与实现Transformer,并进行德译英实战(二)
从词到数:Tokenizer与Embedding串讲 HeptaAI
位置编码全面研究 欲上青天揽明月
位置编码算法背景知识 Zhang
六种位置编码的代码实现及性能实验 张义策
再论大模型位置编码及其外推性(万字长文)
再谈长度外推 uuuuu
图解RoPE旋转位置编码及其特性 红雨瓢泼
基于端到端注意力网络的英德翻译-1
干货!On Position Embeddings AI TIME
序列到序列(seq2seq)模型实现文本翻译
无位置编码 (NoPE) 也有长度泛化问题?首个针对NoPE的长度外推方法 CV技术指南
浅谈LLM的长度外推 uuuuu
看图学大模型:从绝对位置编码到旋转位置编码(RoPE),初中生能看懂,甚至会认表就能看懂:) 看图学
碎碎念:Transformer的细枝末节 小莲子
让研究人员绞尽脑汁的Transformer位置编码 苏剑林
论文笔记 :Multi30K: Multilingual English-German Image Descriptions 帅帅梁
超超超超超简单!从结果推导RoPE旋转位置编码 楠楠楠楠xhttps://www.zhihu.com/people/nan-nan-nan-nan-x)
https://github.com/meta-llama/llama/blob/main/llama/model.py
https://zhuanlan.zhihu.com/p/372858304