From:https://www.big-yellow-j.top/posts/2025/02/21/Kimi-DS-Paper.html
DeepSeek最新论文:Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention以及 Kimi最新论文MOBA: MIXTURE OF BLOCK ATTENTION FOR LONG-CONTEXT LLMS这几篇文章都是针对长上下文的压缩方法,长上下文带来的平方级别的运算或存储复杂度给推理优化带来非常大的影响,因此是当前大模型推理优化中非常重要的一项研究内容。解决长上下文问题,主要分为稀疏化之后的 Token Dropping、KVCache 的量化压缩、Prompt Compression 提示词压缩、还有结构性稀疏压缩等几大类。里面都提到了 稀疏这一个内容,什么是 稀疏注意力(Sparse Attention)
1、稀疏注意力(Sparse Attention)
传统self-attention计算在理论上时间和空间占用为\(O(n^2)\)其中n为序列长度,这是因为对于一个长度为n的序列,任意向量之间都需要计算相关度,得到一个\(n^2\)的相关度矩阵,因此为\(O(n^2)\)。借鉴Blog中描述:
对于self-attention中 每个元素都跟序列内所有的元素都有关联 ,那么一个基本的思路就是 减少关联性的计算,也就是认为每个元素只跟序列内的一部分元素相关,这就是稀疏Attention的基本原理(其实就是如何高效的处理Q,K,V之间关系,不要全部计算)。
2、Kimi:MOBA
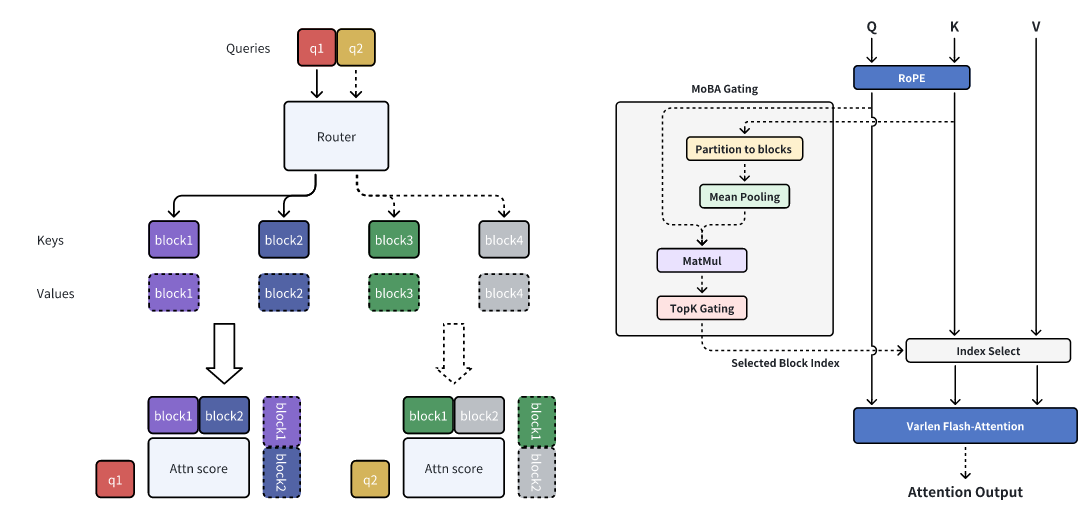
正如上面提到的,文本长度(n)变成导致无论是时间还是空间上消耗增加,因此在MOBA中就是让 Q去和K,V的子集进行计算:
\(I\)代表被筛选的子集。其中如何筛选子集以及如何确定子集个数。对于后者子集个数的确定,对于长度为\(N\)可以直接划分到\(n\)个blocks中,至于如何筛选子集,作者提到就是直接通过MoE中的 router机制去筛选出来即可。

在论文中 Router设计方法(不是像MoE里面直接简单用一个MLP计算),因为想通过一个 Router来选择出哪些是需要使用的,参考代码以及上面流程图的描述,对于分块的Key,在MoBA里面直接计算平均值,然后将结果拼接起来,然后直接和Q进行计算然后再去筛选出结果。
3、DeepSeek:NSA
正如论文里面描述的,NSA采用了一种动态层次稀疏策略,将粗粒度的token压缩与细粒度的token选择相结合,以保持全局上下文感知和局部精度。换言之就是通过:压缩Token以及筛选Token来实现稀疏注意力
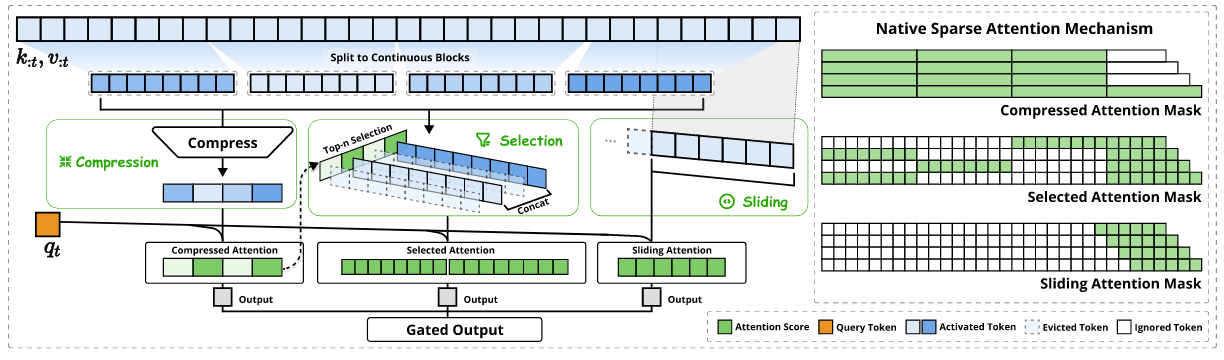
从上面提供的结构图,在NSA中的稀疏注意力大致3个部分:
-
1、compression,压缩:按照论文里面的描述,作者实现方式为,首先对K/V进行通过一个指定一个窗口进行划分(\(id+1:id+l\))(有点像ViT中将图片切分成不同的小batch操作一样)然后再去通过一个 可学习的MLP来实现最后压缩
-
2、selection,筛选:这块比较有意思,因为最开始K/V都已经通过分组了,如果在要去挑选哪些重要/哪些不重要,不去和Q计算你很难得重要性,但是第一步中不是有一个“压缩注意力”得分,那就直接用第一步中计算得到的压缩内容来得到重要性
- 3、sliding window,滑动窗口
简单总结一下上面处理,处理长度长问题,就可以先 分块,然后去对不同块之间进行压缩,但是如果只是简单这样对于信息丢失而言很大,因此会有一个 “筛选”操作来弥补信息丢失问题。对于滑动窗口而言,进一步对信息进行弥补(就比如有些多模态里面除了用batch信息之外还会用到全局信息,不要让模型过度的关注细节内容)
总结
从思路上MoBA和NSA都有一个相通的点,对于 稀疏注意力实现,都是通过“筛选”操作,但是“注意力筛选”势必要用到\(QK^T\)计算,因此两者都有一个有意思点,都会用一个小的替换大的(先分块再去压缩处理)
参考
1、Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
2、MIXTURE OF BLOCK ATTENTION FOR LONG-CONTEXT LLMS
3、Generating Long Sequences with Sparse Transformers
4、https://spaces.ac.cn/archives/6853
5、https://zhuanlan.zhihu.com/p/24841366485