前情
我们有个海外的项目,一共70个服务,前前后后花了超过一年时间完成了云服务迁移和架构调整。主要是架构调整了,原来的docker swarm托管服务,新架构改为Kubernetes托管。几台云服务器将n个服务堆在一起,只会对服务器资源做监控。新架构在新的云服务上线后,暴露了很多内存问题。在此拿某个服务根据解决过程,给个排查思路,希望能给到大家一点启示。
问题
服务为一个普通的ASP.NET Core gRPC工程,平常没什么流量。HPA设置的最大副本数为5,生产环境服务启动后,Pod内存达到或超过K8s内存请求值(512Mi),自动触发扩展到5个实例,即副本数达到最大。这与QA环境表现并不一样,也就没有在测试阶段发现。需要想办法复现、排查解决高副本和高内存占用问题。
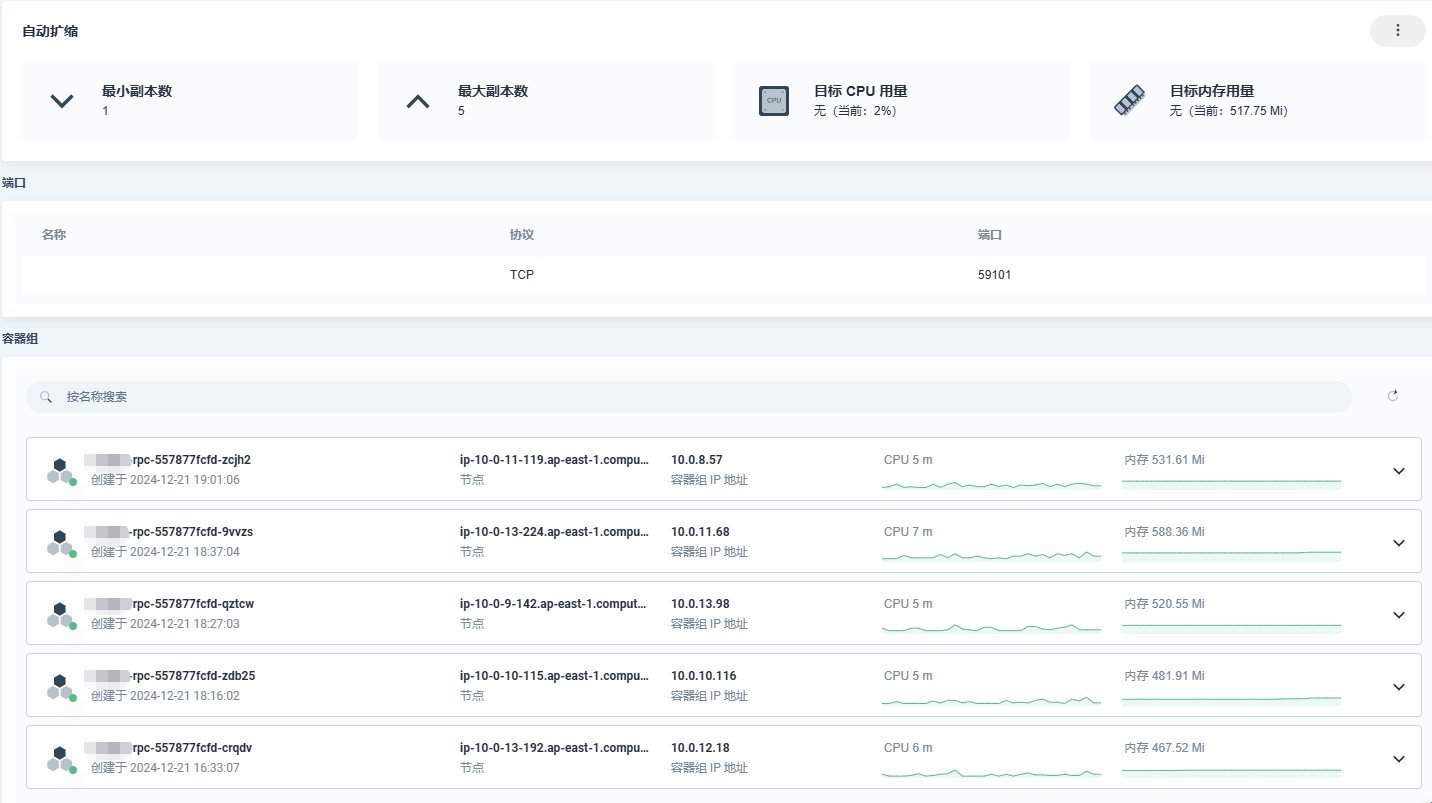
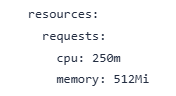
部署里面对容器的资源,容器资源只做了对CPU和内存的预留设置(request),没有做上限设置(llimit)。从内存曲线上看,很多副本的内存甚至超过了请求的512Mi。不过有一点很奇怪,服务的接口并没有出现性能下降的迹象。
问题复现
尝试在QA环境对相关接口进行压测,问题能复现,表现为HPA副本扩展后各个POD的内存居高不下,维持在500~600Mi长时间不释放,有时候压测甚至能冲到800Mi。即使没有什么接口请求,也需要超过20个小时才缓慢下降到350Mi左右。但尝试本地VS诊断工具则并没有发现什么内存不释放问题,除了一些个大对象驻留问题。
代码与dotnet-dump
因为其他类似的服务并不会这样,所以第一时间怀疑是代码问题,但这么想是错的,下面交代。怀疑代码问题后,想着是不是有什么内存泄漏,找了个服务的接口在QA压测后问题能复现(即内存长时间不释放)。看了好几遍代码,除了一些个ToList用的太过频繁并没什么问题(也与内存问题不相关),用VS诊断工具检查内存有运行又没内存泄露问题。于是在QA环境用dotnet-dump把内存快照下载回来分析,找到了个大对象堆LOH驻留类型的类,而且VS诊断工具找到的类是同一个,接着定位到了接口调用这个类的地方。业务调用很单纯,这个类就从数据库用Dapper查出来得到列表,然后分组计算下数据,不会有什么内存泄露的机会;但注释掉此部分查询则内存不再上升到500~600Mi,只在300Mi左右,而且内存使用率下降也变快了。继续二分法+注释大法调试,最后只保留数据库查询语句而不做后续业务处理,连引用都不做,内存还是会达到500~600Mi。这就让人摸不着头脑了,代码肯定是相关的,数据库查询几下一列表数据都能让内存达到预留临界值(request),列表也才约11000条数据,虽然确实是LOH对象,但不至于造成这么严重的内存不释放现象。
GC调参
代码摸不着头脑,就想办法调试下GC。
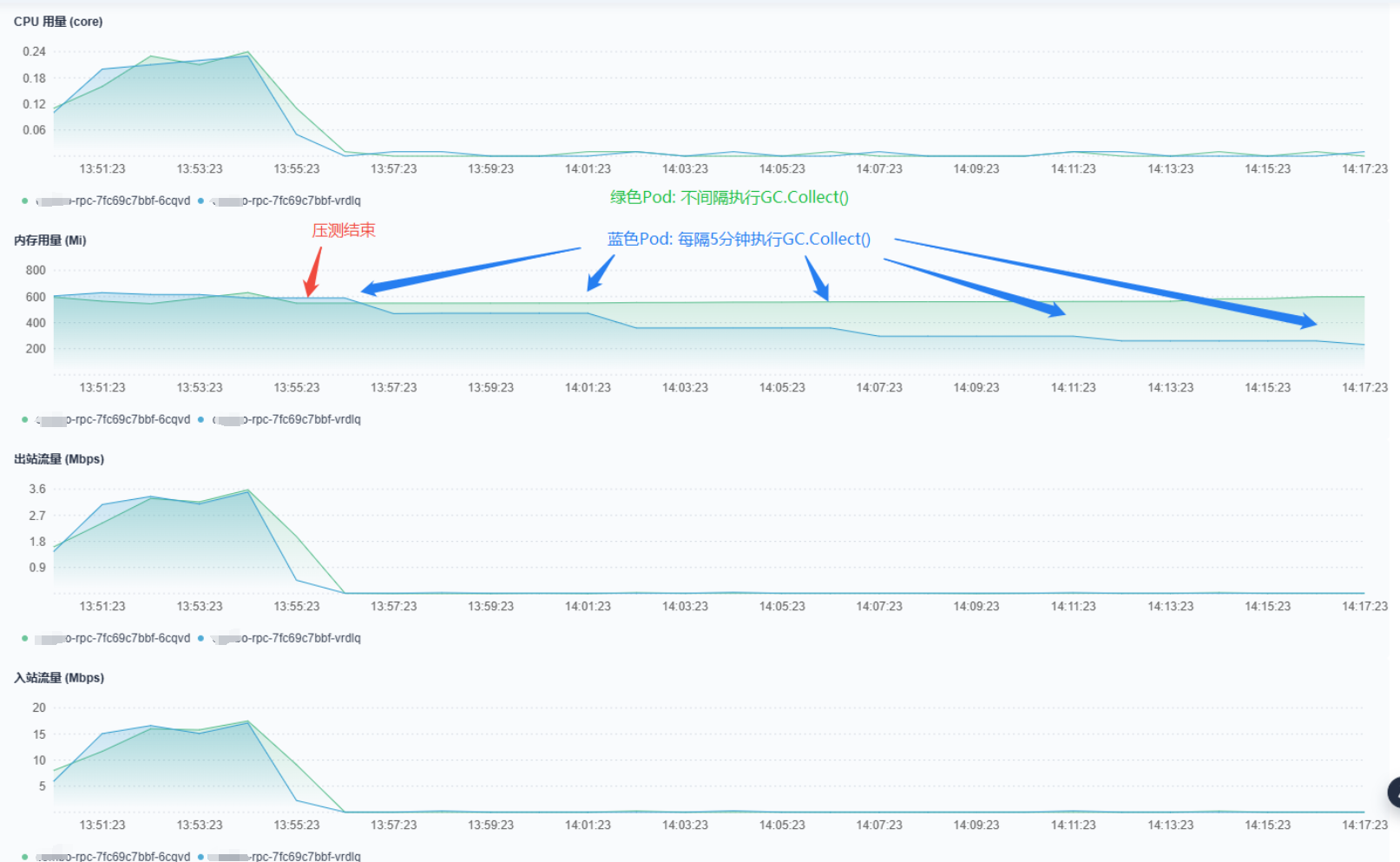
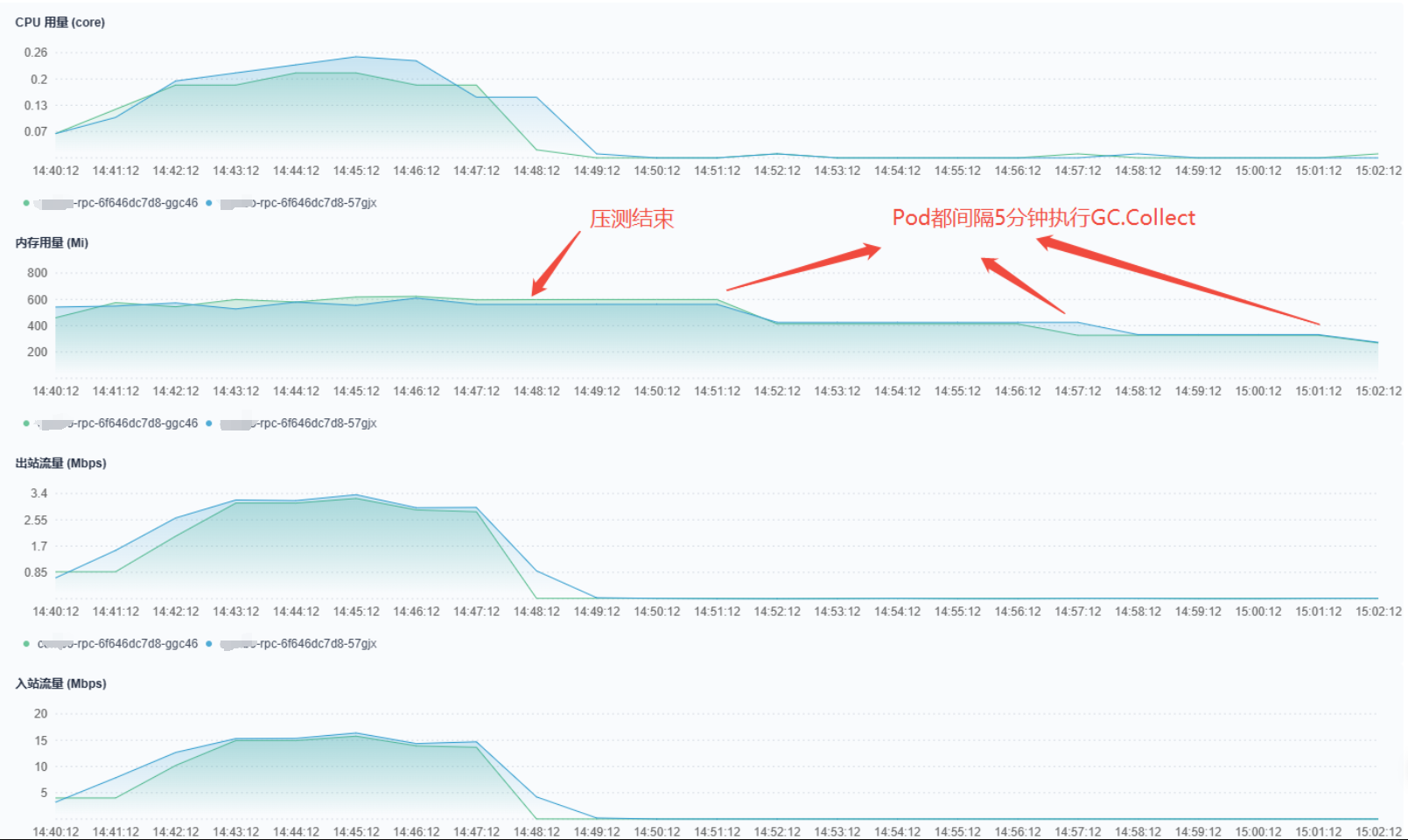
方案一: 定时调用GC.Collect来回收垃圾
加入定时执行GC.Collect()后,内存占用能立即回落,这方案似乎也可以
方案二:GC配置调整:配置内存限制感知-DOTNET_GCHeapHardLimit
添加环境变量DOTNET_GCHeapHardLimit=0x20000000 # 512Mi的十六进制值,能限制内存的使用,但并不能让GC能敏感地进行回收,方案失败
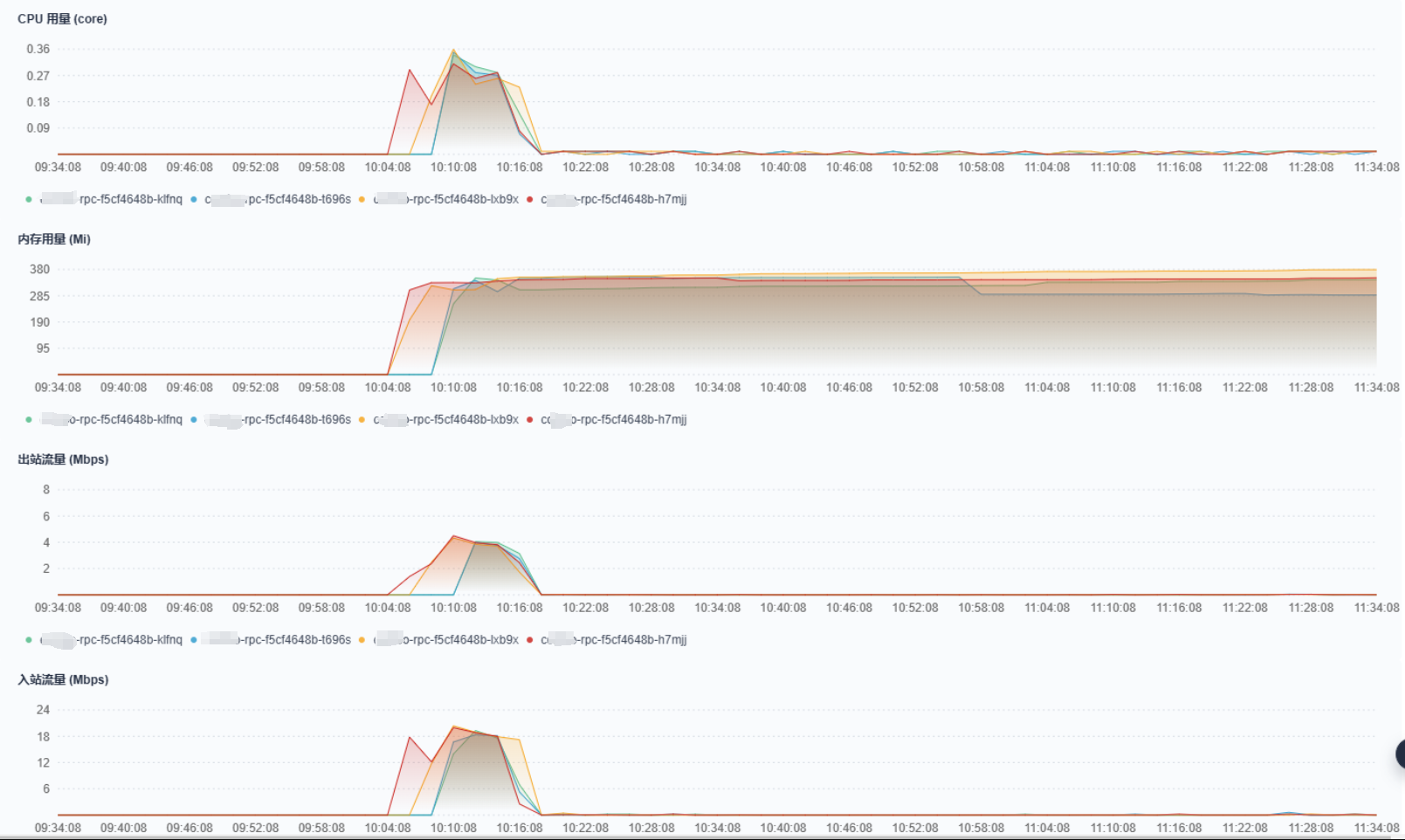
方案三:切换为GC场景类型到工作站
原默认为Server GC,指定为Workstation GC后,内存占用不到180Mi,扩容缩容正常,这方案看起来也可以
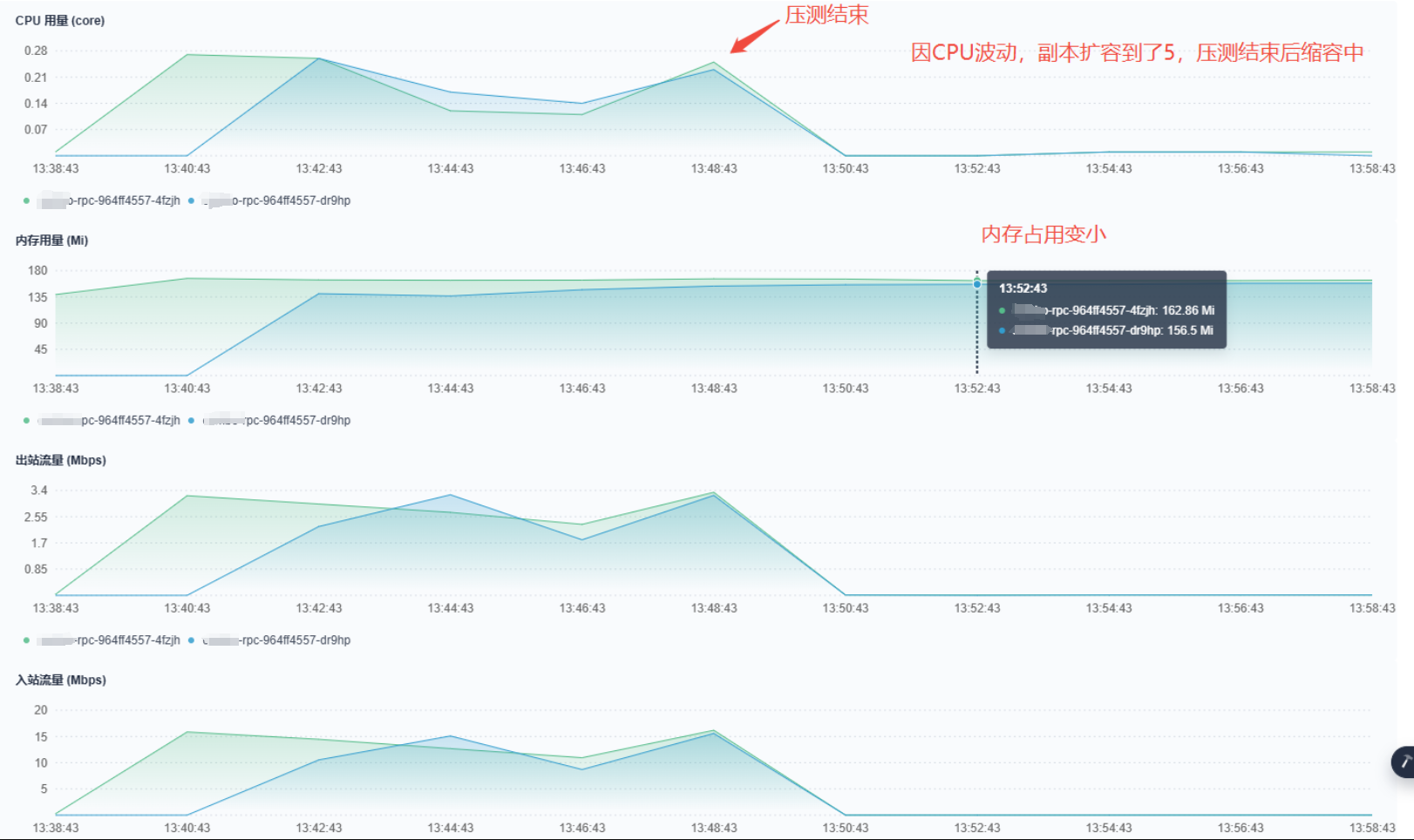
调试结束,方案一和方案三似乎可行,查了相关资料后,两个方案其实都有问题。方案一是代码主动强制执行了垃圾回收,但大多数情况下并不不被建议在代码里面去执行,因为执行GC.Collect多多少少会影响服务性能,GC自己能感知内存使用率然后自动进行执行回收。至于方案三,不同的模式本来就对应着不同的服务场景,服务本身就是后端接口,切换为工作站模式也许可行,但ASP.NET Core默认就是Server GC,Server GC模式本身为了支持高性能并不会频繁执行垃圾回收(.NET 9开售则不同,.NET 9开始ASP.NET Core默认是第三种模式,.NET 8也支持这种模式,只不过不是默认的)。
为容器限定内存上线
查资料过程中才了解K8s的资源设置是有预留设置(request,又称请求设置)和上限设置(limit),服务只设置了请求request部分,没有limit部分,那有没有可能是服务容器因为没有被设置内存limit,导致GC如脱缰野马般豪气地使用内存呢?那为啥内存不释放?就是Server GC感觉内存还是够用的,具体文章参考:工作站和服务器垃圾回收和动态适应应用程序大小 (DATAS)。先查询下可用内存吧,于是加个下面接口查询:
app.MapGet("/runtime/memory", () => {return GC.GetGCMemoryInfo().TotalAvailableMemoryBytes.ToString("N0"); });
结果返回:
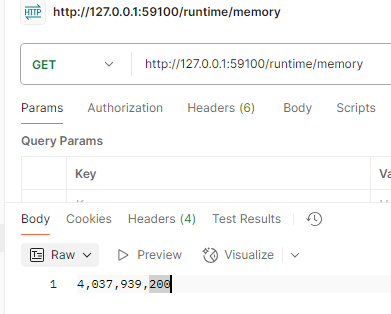
可用内存居然高达4Gi,真相很接近了。接着为服务设置内存limit为512Mi,再次查询得到可用内存为512Mi。没错!就是少设置了内存上限,没有这个,此时可用内存为节点内存(4GB);加了limit重新压测,曲线:
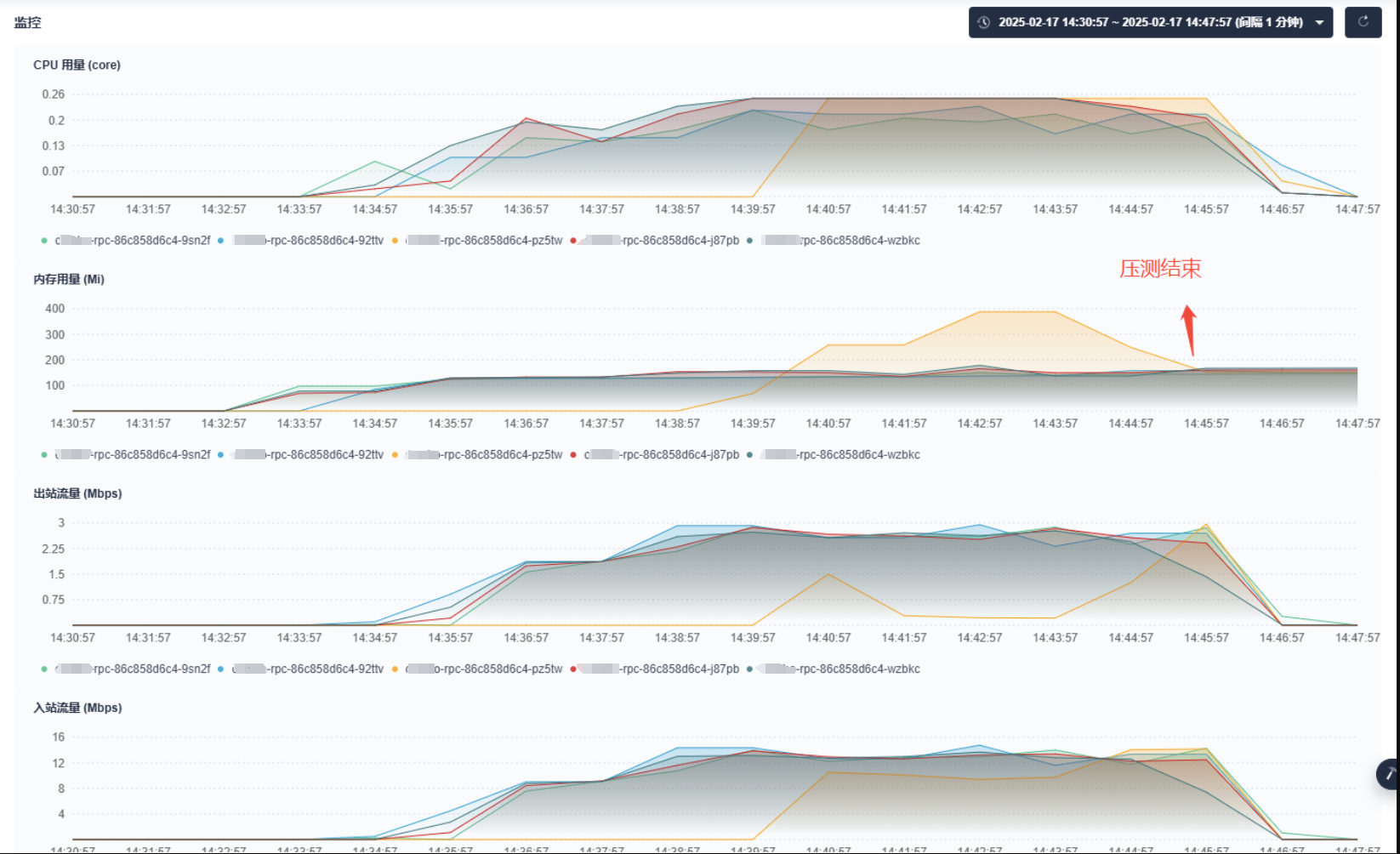
事件如下:

程序内存释放正常!副本数释放也正常!另外接口响应时间没有受到影响,问题得到解决!
总结
服务内存曲线高居不下是因为容器没有被限制内存,K8s没有指定内存limit,可用内存就是节点/宿主机的物理内存,高达4GB。没有设置内存limit,但是设置了HPA,于是服务一启动经过一些时间内存超过HPA阈值造成副本数增加;GC默认是Server GC,其感知的内存足够所以不释放(包括小对象和大对象)。虽然主动调用GC.Collect则可以释放,但一般不会这样做,因为GC有自己的一套逻辑。限定内存为0.5Gi后,内存释放曲线正常,HPA扩缩正常,响应时间正常,问题得到解决
启示
如果遇到类似内存居高不下问题,先确定.NET版本极其GC是Server GC还是Workstation GC。然后再确定其分配的可用内存是多少,K8s下要检查其资源limit有没有被设置。如果被设置之后依然有内存不释放/泄露问题,再怀疑代码问题。
参考:
为容器和 Pod 分配内存资源
Pod 和容器的资源管理
为 Pod 配置服务质量
工作站和服务器垃圾回收
内存没有被回收
动态适应应用程序大小 (DATAS)
了解 Fargate Pod 配置详细信息


![[译] DeepSeek开源smallpond开启DuckDB分布式之旅](https://img2024.cnblogs.com/blog/3526707/202503/3526707-20250303130218966-1162515742.webp)