介绍
集合分为两种,一种是单列集合,一种是双列集合
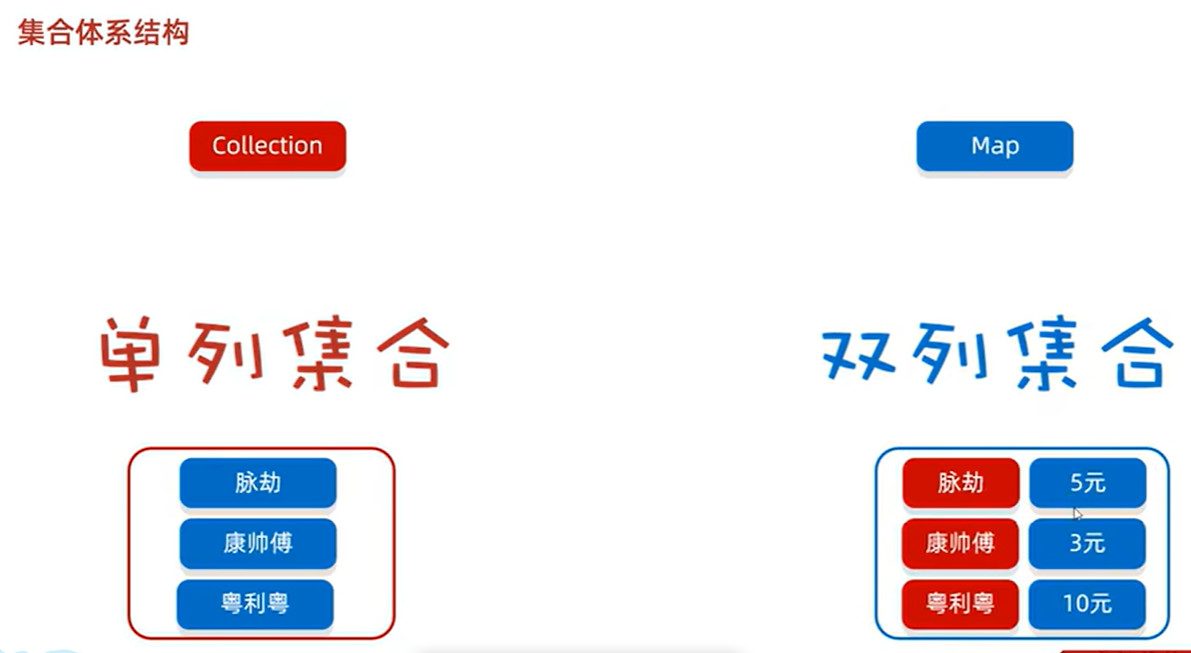
单列集合中
List系列集合添加元素是有序,可重复,有索引的
set系列集合添加元素是无序,不可重复,无索引的
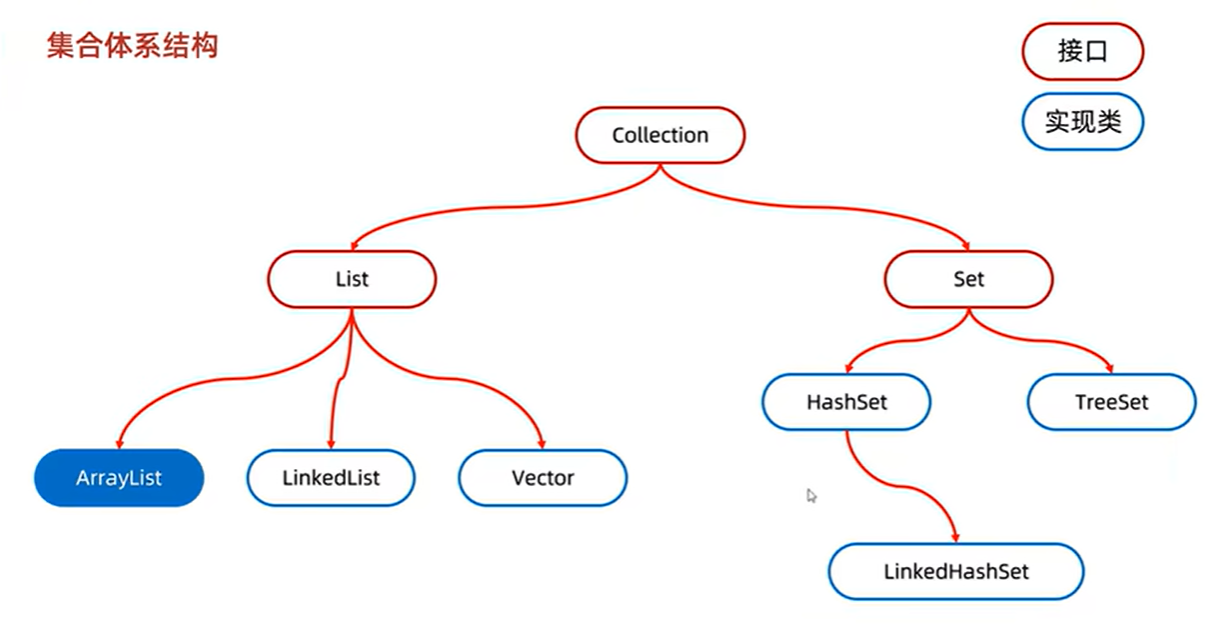
Collection是单列集合的祖宗接口,所以全部的单列集合都可以使用它的方法
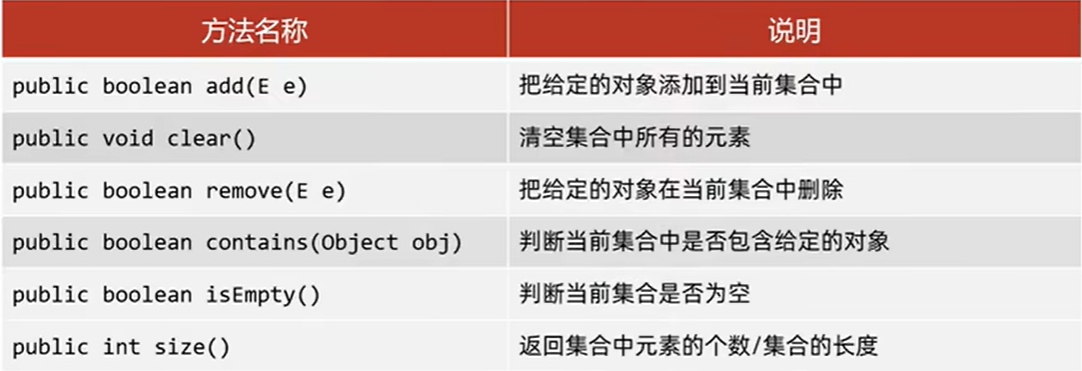
Collection基本方法
add方法,添加元素 如果向List系列中添加元素,则必定返回true,因为List系列允许重复;如果向Set系列中添加,如果里边已经有了该元素,则返回false,反之返回true
clear,清空所有元素
remove,删除元素 因为Collection是接口,里面定义的是共性的方法,所以不能通过索引删除,只能通过元素的对象进行删除,如果有则删除成功,返回true,如果删除的元素不存在,则删除失败返回false
contains 判断当前集合中是否有xx对象,Array List的contains方法底层代码如下
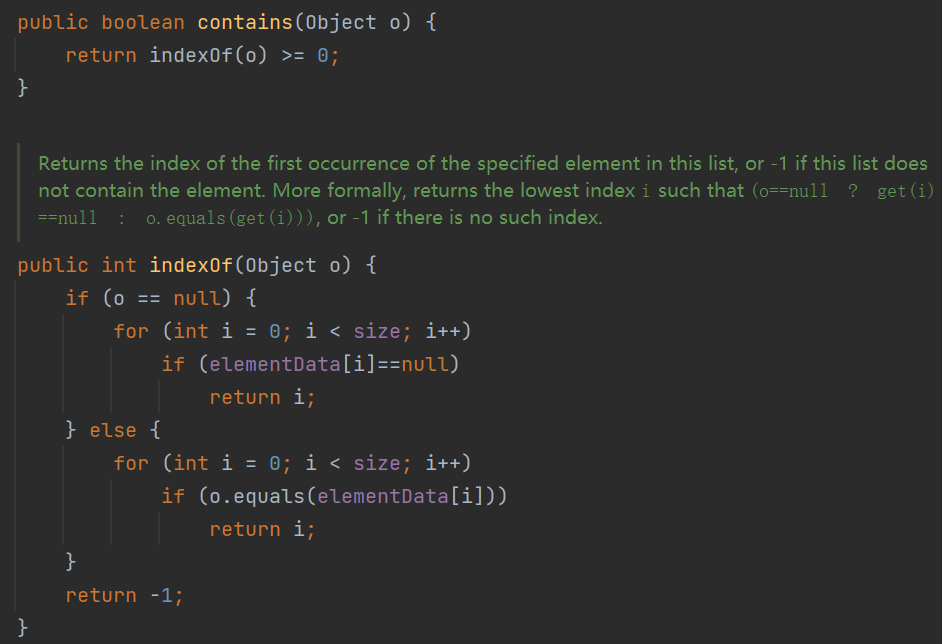
可见,contains方法是依赖于equals方法来进行操作,所以,如果想判断 有没有 与给定的对象 内容相同 的 自定义类型的对象,则需要在javabean类中重写equals方法
Java中equals()方法的使用_java中equals的用法-CSDN博客
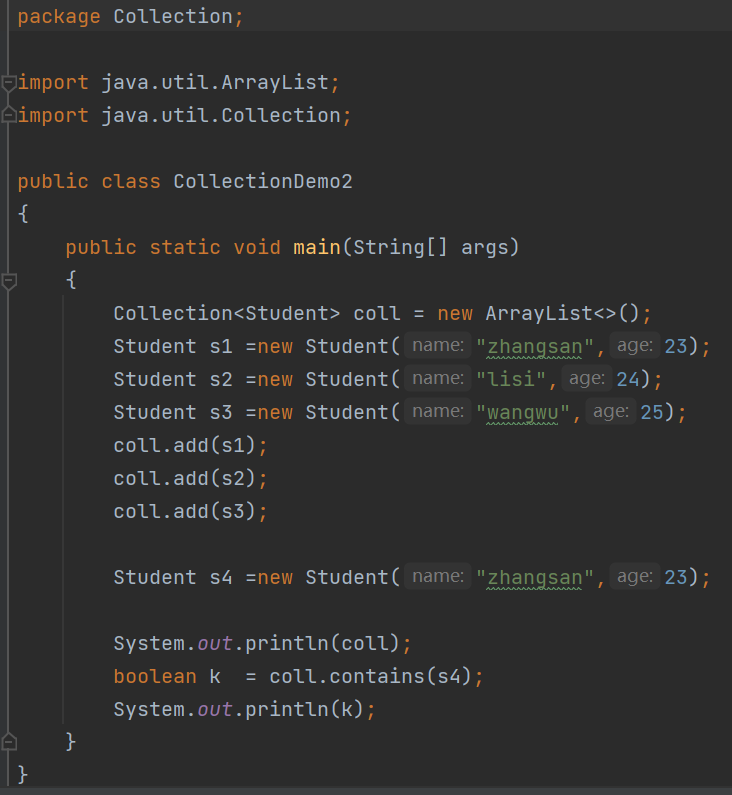

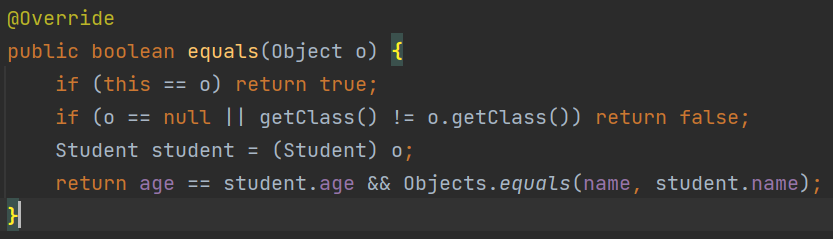
isEmpty方法,为空返回true,不为空返回flase
size方法,返回集合长度,即元素个数
迭代器
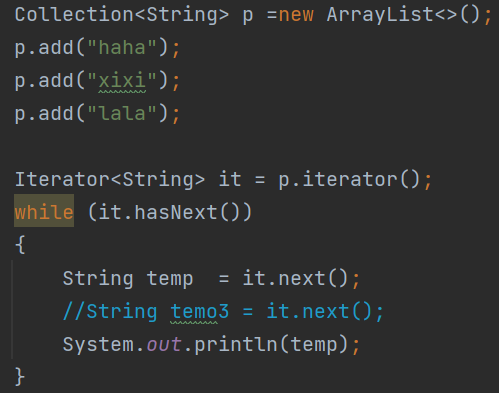
如果到了最后一位仍然进行it.next(),抛出异常NoSuchElementException
迭代器遍历完毕,指针不会复位
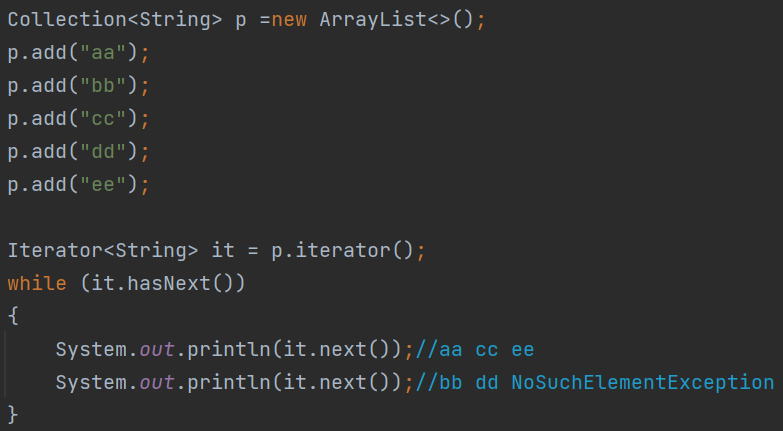
循环中只能用一次next方法,因为hasNext方法只能判断有无下一个,不能判断有没有下一个的下一个,所以下面会抛出NoSuchElementException的异常,如下 所以hasNext和next方法,要一对一的配套使用
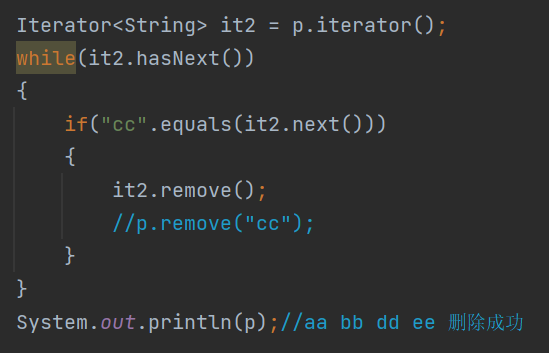
迭代器遍历时,不能用集合的方法进行增加或删除(抛出ConcurrentModificationException——并发修改异常),但是可以用迭代器的方法进行删除(添加要用列表迭代器),如下
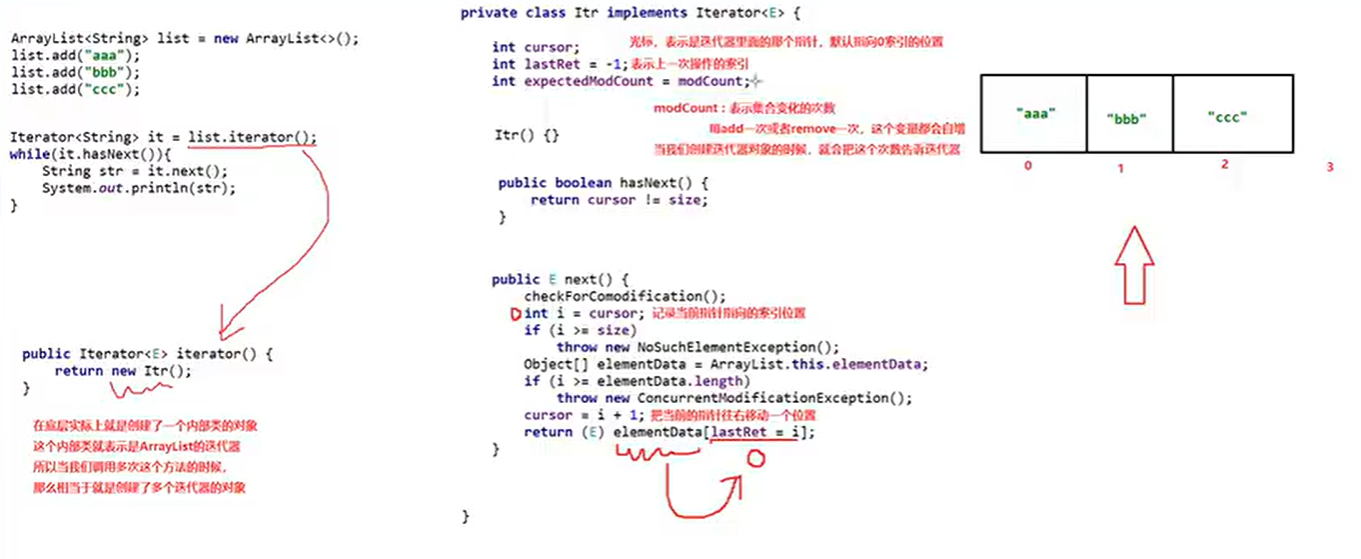
迭代器执行时底层代码如下 modCount为集合变化次数(增删次数)
Collection遍历方式
迭代器遍历
增强for循环遍历
Lambda表达式遍历
增强for遍历
增强for遍历的底层就是迭代器,为了简化迭代器的代码书写的
是在jdk5之后出现的,内部原理是个Iterator迭代器
所有的单列集合和数组才能用增强for遍历

里面的s仅仅是一个临时变量,修改s不会修改原本的集合p,即值的拷贝,(但如果元素是自定义类型,是会改变的————来自弹幕,待考证)
Lambda表达式遍历
JDK8开始

forEach底层如下,它遍历集合,并将每一个元素交给action下的accept方法,所以我们需要自己去写accept方法

而Consumer是个函数接口,所以需要自己去写这个accept方法
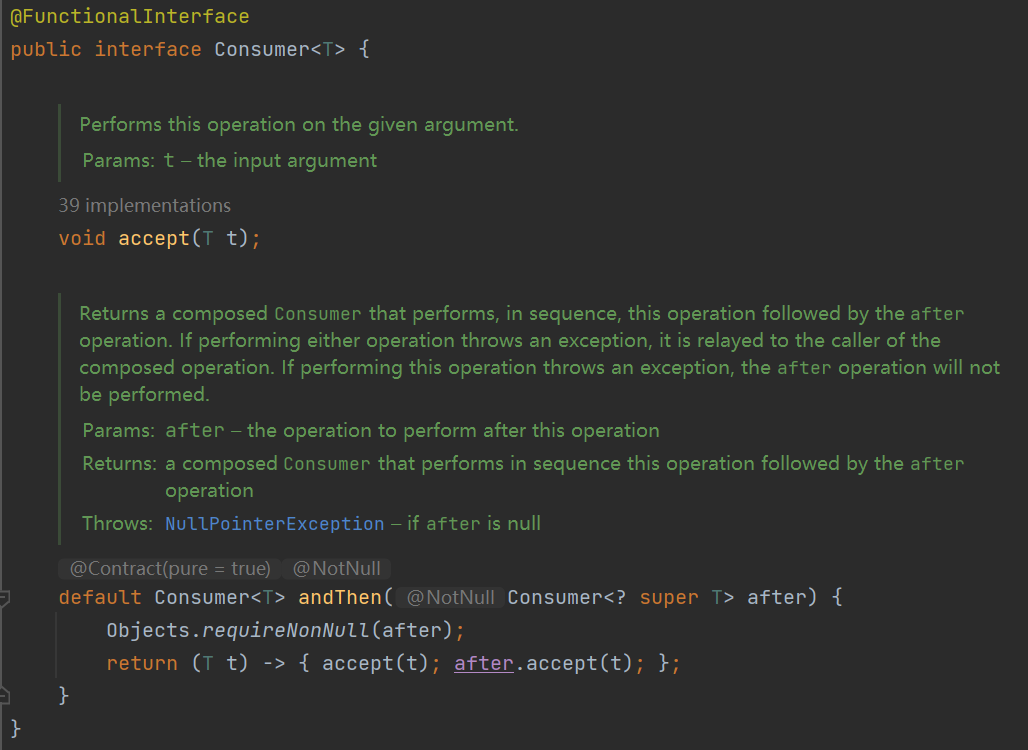
大致遍历代码如下

Lambda表达式的格式是 () -> { }

List
基本方法
包括ArrayList,LinkedList,Vector
特点是,有序,有索引,可重复
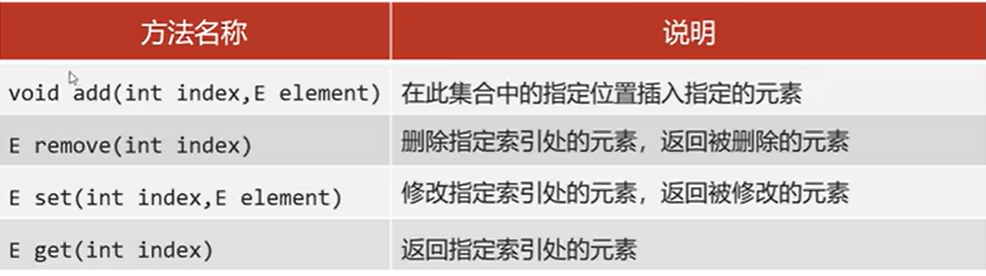
remove有两种
1、直接删除 remove(Object o)
2、通过索引删除指定位置的元素 remove(int Index)
比如集合对象为 1、2、3 ,存在元素1,此时remove(1)调用的是删除方法2,删除之后变为 1、3
因为在调用方法时,如果出现了方法重载的情况,优先调用实参和形参类型一致的函数,而第一个删除方法,Object o 的形参,还需要将实参1进行装箱,再删除
但如果想删除元素1,除了remove(0)外,也可以进行手动装箱,再按照 “优先调用实参和形参类型一致的函数” 的原理,删除元素1
set返回的是被修改的元素,也就是修改的位置上,修改之前的元素
遍历方法
迭代器遍历
增强for循环遍历
Lambda表达式遍历
普通for遍历(因为List存在索引)
列表迭代器——————涉及两个函数hasPrevious()和previous()和一个东西 listIterator

package List;import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.ListIterator; import java.util.function.Consumer;public class ListDemo3 {public static void main(String[] args){List<String> list = new ArrayList<>();list.add("aaa");list.add("bbb");list.add("ccc");//普通迭代器遍历Iterator<String> it = list.iterator();while (it.hasNext()){String str = it.next();System.out.println(str);}System.out.println("=========================================");//增强for遍历for (String s:list){System.out.println(s);}System.out.println("=========================================");//forEach遍历list.forEach(new Consumer<String>() {@Overridepublic void accept(String s) {System.out.println(s);}});System.out.println("=========================================");//简化forEachlist.forEach(s-> System.out.println(s));System.out.println("=========================================");//普通for循环for (int i = 0; i < list.size(); i++) {System.out.println(list.get(i));}System.out.println("=========================================");//列表迭代器ListIterator<String> it1 = list.listIterator();while (it1.hasNext()){String str =it1.next();if("bbb".equals(str)){it1.add("qqq");}}System.out.println(list);} }
数据结构

双向链表在查询第N个元素时,可以先比较离头节点近还是尾节点近,进而加快查询速度
ArrayList
addALL是复制另一个ArrayList对象到当前ArrayList对象
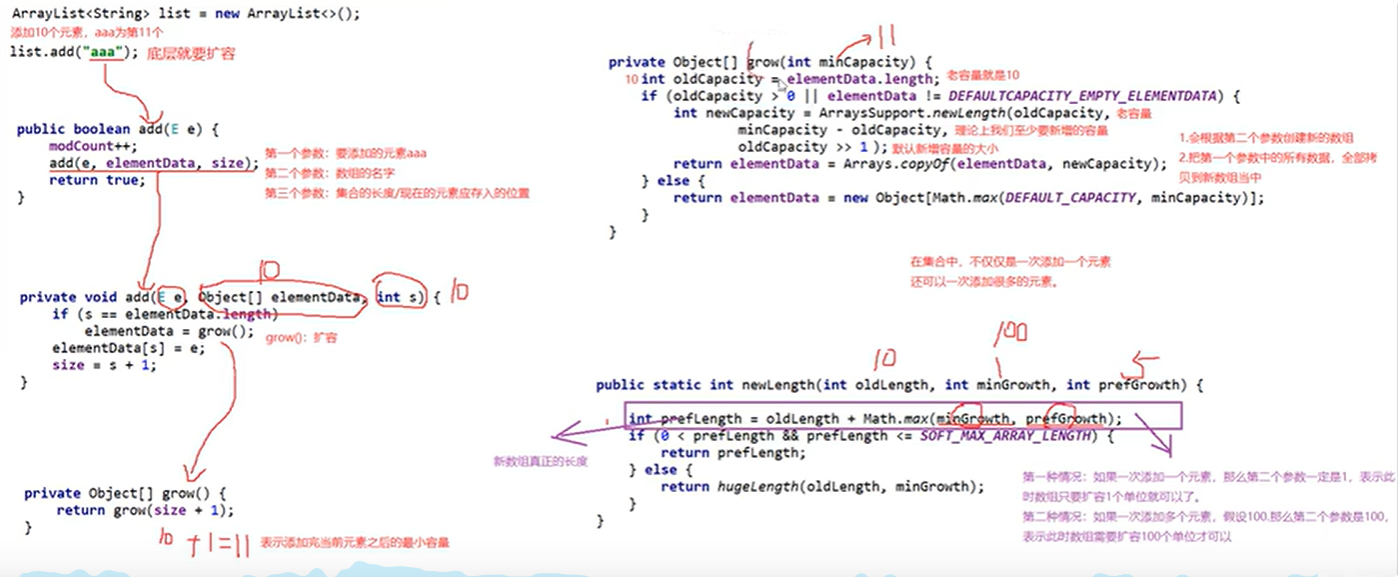
底层原理
利用空参创建的集合,在底层创建一个长度为0的数组
添加第一个元素时,底层会创建一个长度为10的数组,过程如下图
jdk8源码 (grow为扩容代码)

如果长度为10的数组已经满了,执行下边的底层代码
比较原有长度/2和所添加的实际所需长度相比较,扩容大的长度,实际是新开一个数组,并将原数组的数据拷贝过去
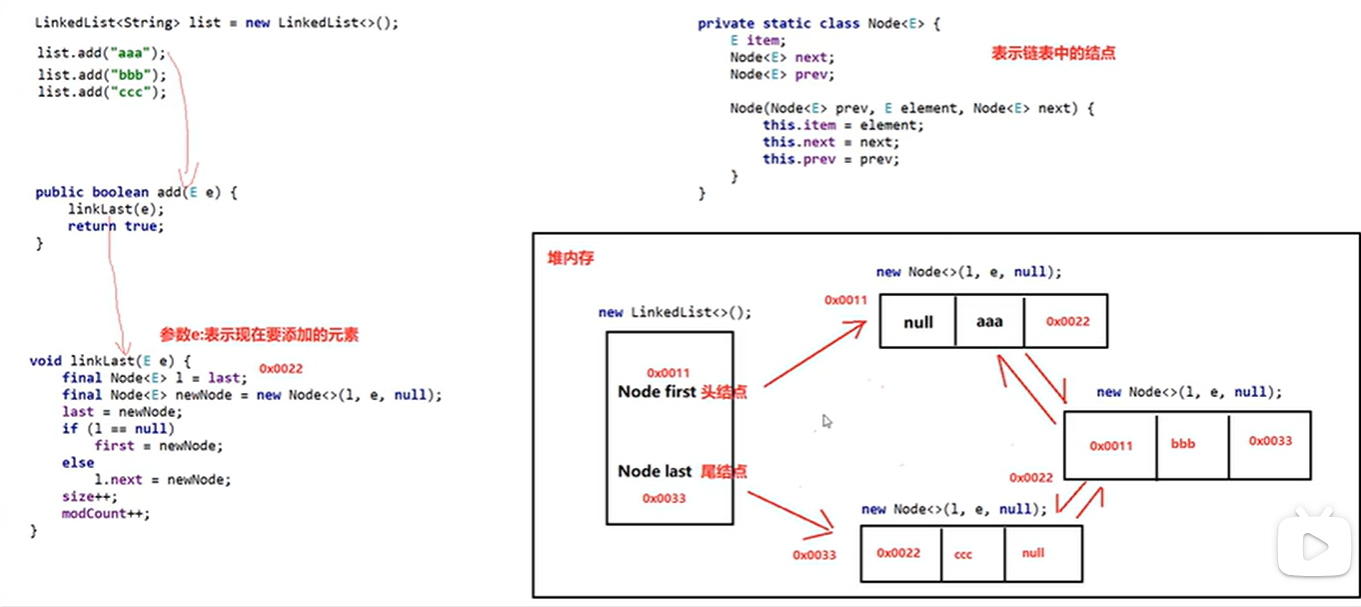
LinkedList
底层是双向链表,查询慢,增删快
由于是双向链表,所以对首尾操作速度极快,所以多了很多对首尾进行操作的API

当对其添加元素时,涉及的函数和空间如下
泛型类
简介
JDK5引入,可以在编译阶段 约束 操作的数据类型,并进行检查
格式:<数据类型>
泛型只能支持引用数据类型,不能写基本类型
泛型优点
统一数据类型
把运行时期的问题提前到了编译期间,避免了强制类型转换可能出现的异常,因为在编译阶段类型就能确定下来
泛型擦除
Java中的泛型实际是伪泛型,当添加数据时,编译器会检查添加的数据是否是泛型的数据类型,添加进去后仍然转成Object类,然后强制转换成泛型的数据类型进行各种操作
在.java文件是真的泛型,但编译成.class文件后泛型则不再存在,这个过程叫泛型擦除
细节
不能写基本数据类型
指定泛型的具体类型后,传递数据时,可以传入该类类型或者其子类类型
如果不屑泛型,类型默认是Object
可以用到的地方
泛型类
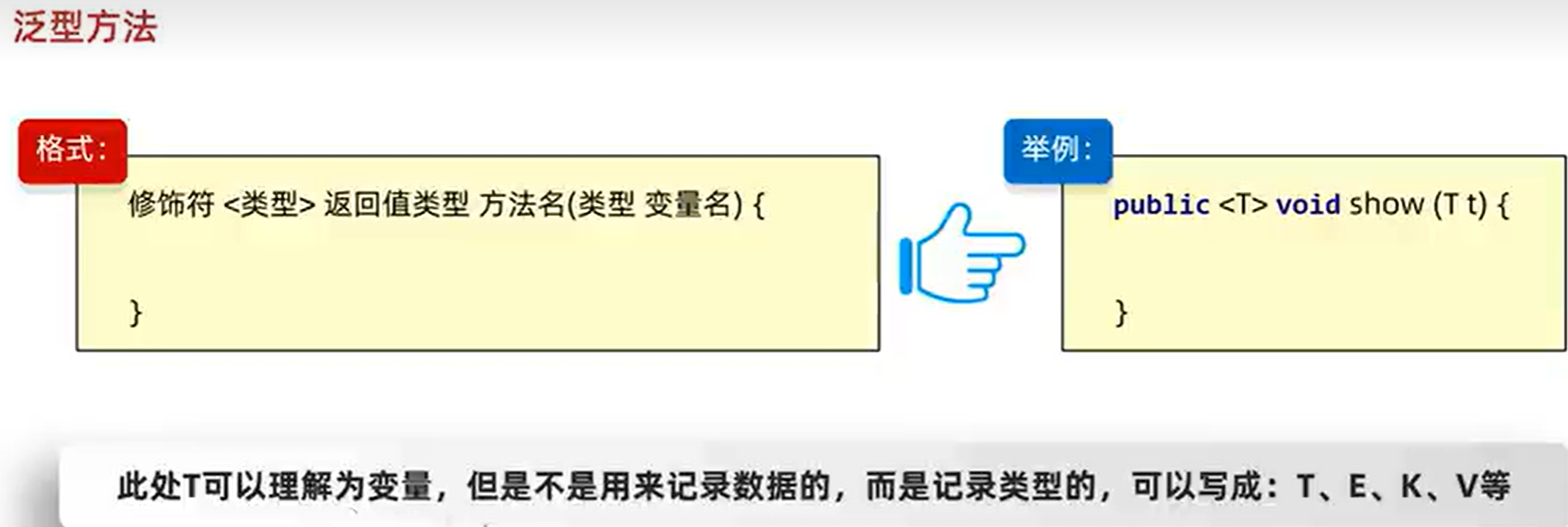
泛型方法
泛型接口
(代码在Generics2到4)




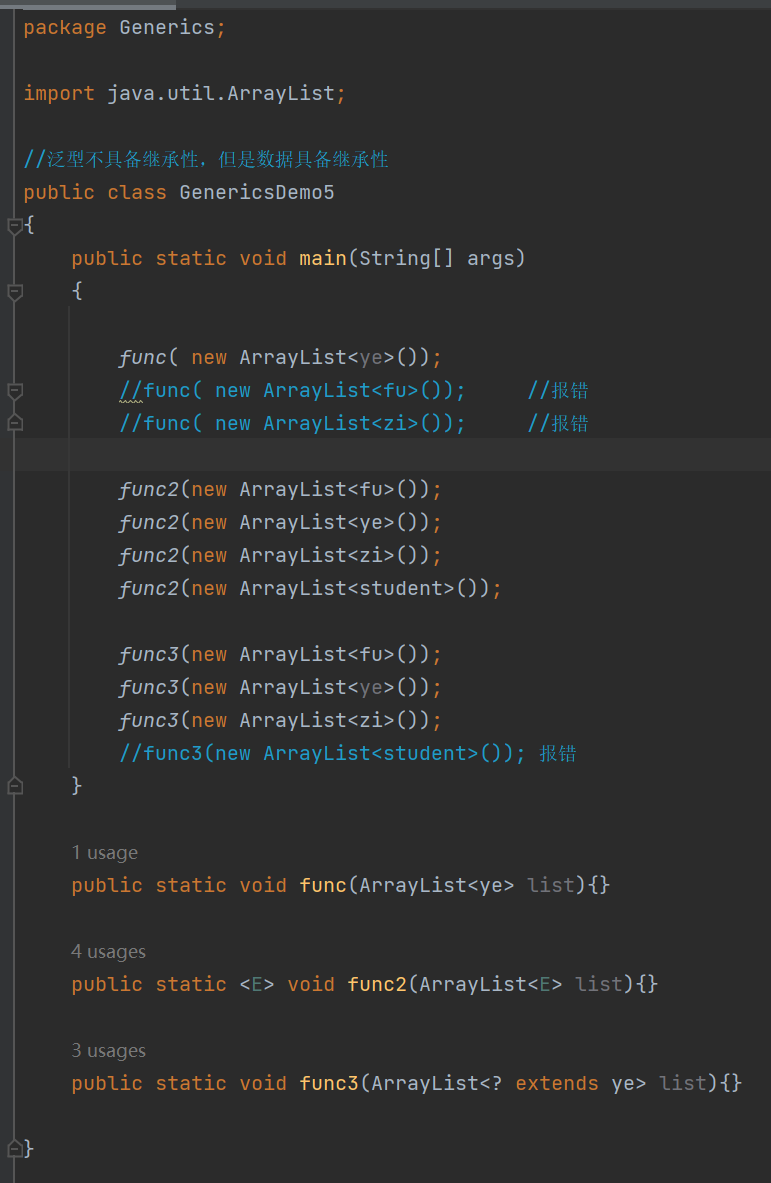
通配符
泛型不具有继承性,但是数据具有继承性
通配符的符号是‘ ? ’
二叉树
二叉树分类
二叉树 每个结点最多有两个分支
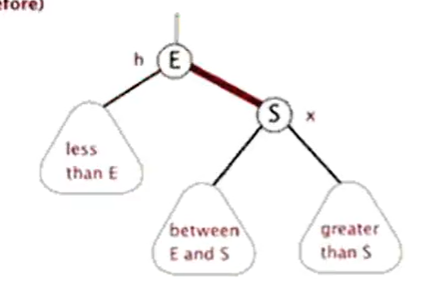
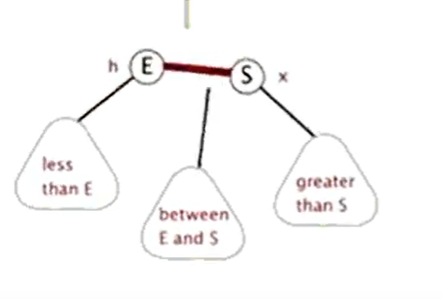
二叉查找树 每个结点最多有两个分支 左节点<当前节点<右节点
平衡二叉树 每个结点最多有两个分支 左节点<当前节点<右节点 每个节点的左子树和右子树,两者的高度差不超过1
平衡二叉树的旋转机制
关于平衡二叉树是如何形成的————是通过旋转机制保证 ”平衡“ 二字的
旋转机制分为两种,一种是左旋,一种是右旋,旋转时候是当添加节点后,该树不再平衡,然后才旋转

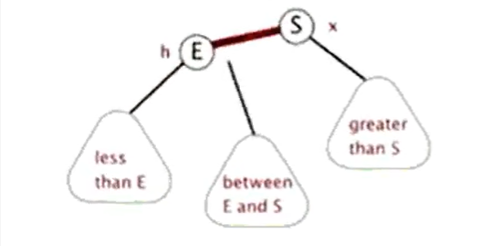
左旋
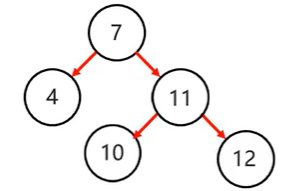
以下图为例

加入节点12后,平衡二叉树不再平衡


如此,变为
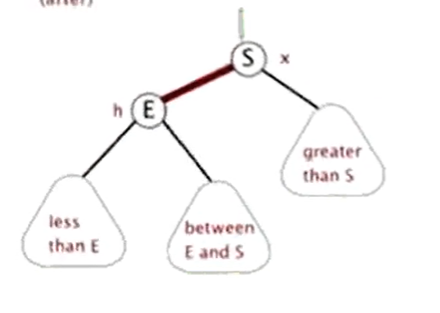
例2

加入节点12后,不再平衡,此时从添加的节点依次往上找,第一个不平衡的节点为7,于是左旋,10晋升为新的父节点

然后多出来的节点9,按照平衡二叉树的定义,分给7节点的右节点
模拟动画如下
右旋
与左旋轴对称


需要旋转的四种情况
左左
 只需要一次右旋
只需要一次右旋
左右
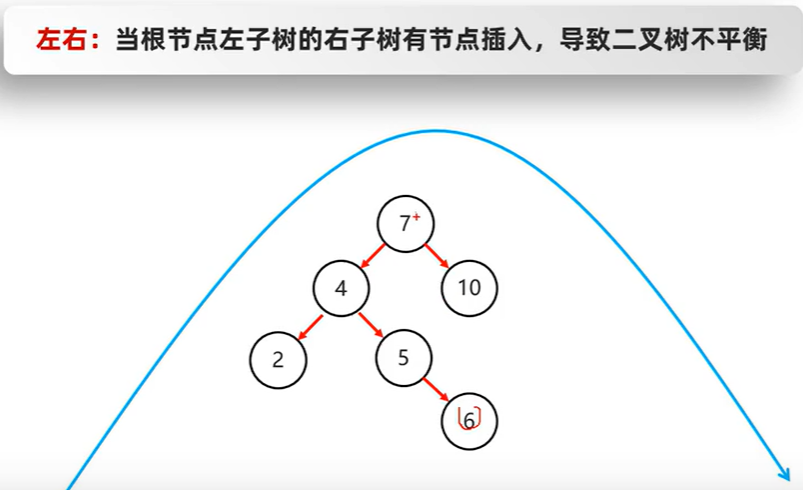 此时仅仅一次右旋是不行的
此时仅仅一次右旋是不行的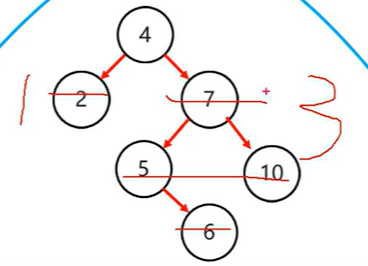
此时应该先将紫色部分进行一次左旋,然后再进行整体的一次右旋
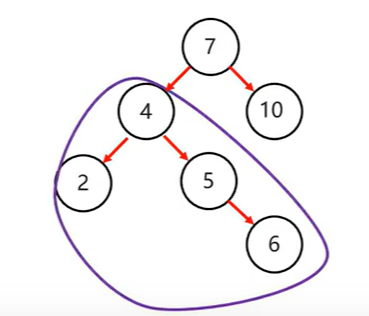
右右

右左
先局部右旋,再整体左旋
总结

红黑树
介绍
红黑树是一种自动平衡的二叉查找树,又称平衡二叉B树
每个节点都有自己的颜色——红/黑
红黑树不是高度平衡的,它的平衡是通过红黑规则来实现的
红黑树的增删改查功能都很好
平衡二叉树和红黑树的差异

红黑规则
每个节点是红色或者黑色
根节点必须是黑色
如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的
如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点 (后代,即子树上所有子节点 叶节点(即Nil) 简单路径:最直接就能到达,只能往前走不可回头的路径)

右侧红色圆圈为每个节点所存储的信息
添加节点的规则
添加节点时,默认是红色的,因为效率高(需要修改的次数少)
具体如下图

上图中,“将XX设置为当前节点再进行其他判断”————指的是,将这个节点当作你新添加的节点,然后重新来一遍此图的流程
Set
特点
无序(存进去的顺序和在里面存储的顺序不同,比如你先存的2,再存进去1,在里面1在2前面)
不重复
无索引
实现类
HashSet 无序,不重复,无索引
LinkedHashSet 有序,不重复,无索引
TreeSet 可排序,不重复,无索引
方法
Set是个接口,而且Set接口继承于Collection接口,里面的方法基本上与Collection的API一致

HashSet
底层是用哈希表来存储数据
哈希表
哈希表对于增删改查的性能都挺好
JDK8之前是 数组 链表 来实现哈希表
JDK8之后是 数组 链表 红黑树 来实现哈希表
哈希值
哈希值————对象的整数表现形式
往哈希表里存元素,元素的索引(元素在表里的位置)是根据哈希值来决定————int index = (数组长度 - 1)& 哈希值
哈希值是根据hashCode方法计算出的int类型的整数,该方法定义在Object类中,所有对象都可以调用
hashCode方法默认使用地址值进行计算哈希值,所以一般情况下,会重写hashCode方法,利用对象内部的属性值计算哈希表
对象的哈希值特点
如果没有重写hashCode方法,不同对象计算出的哈希值是不同的,因为每个对象地址值是不一样的
如果已经重写hashCode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样(哈希碰撞)
哈希表底层创建原理
底层使用的数据结构
JDK8之前是 数组 链表 来实现哈希表
JDK8之后是 数组 链表 红黑树 来实现哈希表
创建——填充元素步骤
HashSet<String> hm = new HashSet<>();
1、创建一个默认长度为16,默认加载因子为0.75的名为table的一个数组
2、根据元素的哈希值跟数组的长度计算出应存入的位置 int index = (数组长度 - 1)& 哈希值
3、计算得出的索引index,如果此位置没有元素,为NULL,则直接把元素放进去
但如果此索引上已经有元素了,就会调用equals方法去比较对象内部的属性值
4、如果比较结果一样,则不存,如果不一样,则存进去,存的位置见下图
 (挂在下面————即两者/多者形成链表,JDK8之前是插入链表头部——头插,JKD8之后是插入链表尾部——尾插,链表头部地址即为数组的那个索引的地址)
(挂在下面————即两者/多者形成链表,JDK8之前是插入链表头部——头插,JKD8之后是插入链表尾部——尾插,链表头部地址即为数组的那个索引的地址)
扩容步骤
当存入了数组长度*加载因子个元素时,数组长度会扩容到原来长度的两倍
比如最开始是默认长度为16,默认加载因子为0.75,当里边有16*0.75=12个元素时,数组长度会从16变为32
当链表长度>8,而且数组长度 >= 64时,链表会自动转成红黑树,从而提高查找效率
注意点
JDK8以后,当链表长度超过8而且数组长度大于等于64时,自动转换为红黑树
如果集合中存储的是自定义对象,必须要重写hashCode和equals方法
HashSet为什么存和取顺序不一样
HashSet为什么没有索引
HashSet是利用什么机制保证数据去重的
利用HashCode方法和equals方法
一个是获取哈希值,一个是去比较内容是否相同
LinkHashSet
特点
有序(存储和取出的顺序一致),不重复,无索引
原理:底层数据结构是依然哈希表,只是每个元素又额外的多了一个双链表的机制 用来 记录存储的顺序
TreeSet
特点
不重复
无索引
可排序(按照元素的默认规则从小到大排序)——————对于默认数据类型可以这样,但对于自定义数据类型需要自己去写比较大小的规则

依次是 this<o this>o this==o
底层
基于红黑树实现排序,增删改查性能都很好
自定义数据类型的比较规则
一般使用默认排序,不符合需求才使用比较器排序
默认排序/自然排序
Javabean类实现Comparable接口,进而指定比较规则
![]()
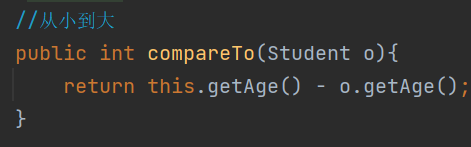
this表示当前节点,o表示红黑树上每个节点,即当你在增加节点时,需要对每个节点都去调用这个方法,从而在最后判断出当前节点该放在红黑树的哪个地方,再然后进行红黑规则
比较器排序
创建TreeSet集合时,自定义Comparator比较器对象,指定比较规则
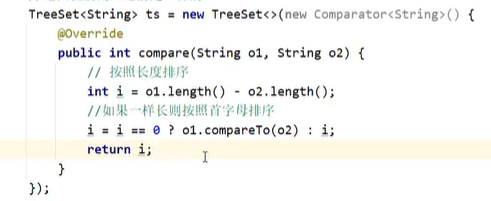
两者同时存在
如果默认排序和比较器排序都存在,排序时按比较器排序进行排序
使用场景