1、查询帮助命令
man ls
help
info
2、文件和目录操作命令
ls # 仅了列出当前目录可见文件
ls -l # 列出当前目录可见文件详细信息
ls -hl # 列出相信信息并以可读大小显示文件大小
ls -al # 列出所有文件(包含隐藏)的详细信息
ls --human-readable --size -l -S --classify # 按文件大小排序
du -sh * | sort -h # 按文件大小排序(同上)cd # 进⼊⽤户主⽬录;
cd / # 进⼊根⽬录
cd ~ # 进⼊⽤户主⽬录;
cd .. # 返回上级⽬录(若当前⽬录为“/“,则执⾏完后还在“/";".."为上级⽬录的意思);
cd ../.. # 返回上两级⽬录;
cd !$ # 把上个命令的参数作为cd参数使⽤。
cd - # 切换到上⼀个⼯作⽬录的说明
cd ${OLDPWD}
# 命令会直接切换到上⼀个⼯作⽬录。cp -r dir desrdir
find
#语法
find(选项)(参数)
#选项
-amin<分钟>:查找在指定时间曾被存取过的⽂件或⽬录,单位以分钟计算;
-atime<24⼩时数>:查找在指定时间曾被存取过的⽂件或⽬录,单位以24⼩时计算;
-cmin<分钟>:查找在指定时间之时被更改过的⽂件或⽬录;
-ctime<24⼩时数>:查找在指定时间之时被更改的⽂件或⽬录,单位以24⼩时计算;
-depth:从指定⽬录下最深层的⼦⽬录开始查找;
-empty:寻找⽂件⼤⼩为0 Byte的⽂件,或⽬录下没有任何⼦⽬录或⽂件的空⽬录;
-exec<执⾏指令>:假设find指令的回传值为True,就执⾏该指令;
-maxdepth<⽬录层级>:设置最⼤⽬录层级;
-mmin<分钟>:查找在指定时间曾被更改过的⽂件或⽬录,单位以分钟计算;
-mtime<24⼩时数>:查找在指定时间曾被更改过的⽂件或⽬录,单位以24⼩时计算;
-perm<权限数值>:查找符合指定的权限数值的⽂件或⽬录;
-size<⽂件⼤⼩>:查找符合指定的⽂件⼤⼩的⽂件;
-type<⽂件类型>:只寻找符合指定的⽂件类型的⽂件;# 当前⽬录搜索所有⽂件,⽂件内容 包含 “140.206.111.111” 的内容
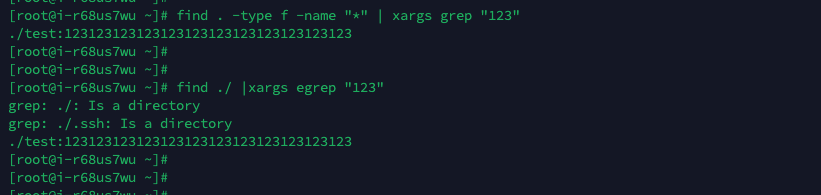
find . -type f -name "*" | xargs grep "140.206.111.111"
find ./ |xargs egrep "123"# 查找最后修改时间在 7 天之前的文件,文件名以.log结尾
find ./ -type f -mtime +7 -name "*.log"# 查找一分钟之内的文件
find ./ -type f -mmin -1 | xargs ls -al#在/home⽬录下查找以.txt结尾的⽂件名
find /home -name "*.txt"
find . -maxdepth 3 -type f#查看权限是644⽂件
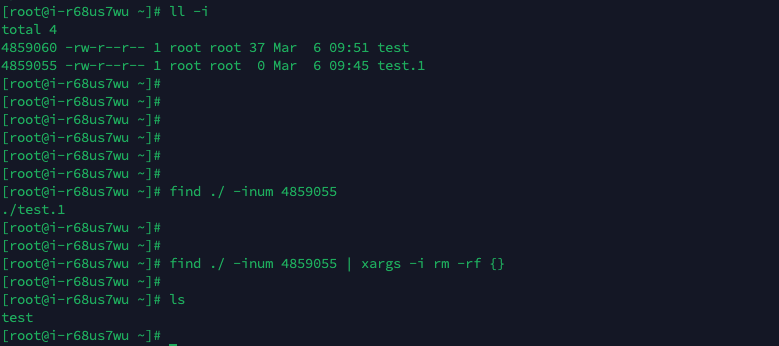
find ./ -type f -perm 644# 通过inode号删除文件
ll -I #查看文件的inode号
find ./ -inum 4859055 | xargs -i rm -rf {} # xargs的意思就是前边的作为参数 -I的意思就是前边文件作为参数 {}的意思就是-i传的参数
find ./ -inum 4859060 | xargs rm -rf # 同上都可以删除UNIX/Linux⽂件系统每个⽂件都有三种时间戳:
访问时间 (-atime/天,-amin/分钟):⽤户最近⼀次访问时间。
修改时间 (-mtime/天,-mmin/分钟):⽂件最后⼀次修改时间。
变化时间 (-ctime/天,-cmin/分钟):⽂件数据元(例如权限等)最后⼀次修改时间。# 查找7天以前的日志
find . type f -mtime -7 -name "*.log"# 统计代码行数
seq 100 > test.java # 生成个100行文件
find ./ -type f -name "*.java" | xargs cat |grep -v ^$|wc -l # 统计代码行数, ^$用来排除空行#创建文件夹
mkdir -p dir#改文件名称
mv old new#删除
rm file
rm -rf file #强制删除#创建文件
touch file
touch test_{1..100} #批量创建文件ls > filename # 把查出来的所有文件名放到filename里边
cat filename |xargs touch # 创建filename里边所有文件名的文件
file install.log # 查看文件类型
install.log: UTF-8 Unicode text
file -b install.log <== 不显示⽂件名称
UTF-8 Unicode text
file -i install.log <== 显示MIME类别。
install.log: text/plain; charset=utf-8
file -b -i install.log
text/plain; charset=utf-8#列出⽬录/private/ 第⼀级⽂件名
tree /private/ -L 1
/private/
├── etc
├── tftpboot
├── tmp
└── varfstab目录
是硬盘挂载目录
#⽤chattr命令防⽌系统中某个关键⽂件被修改:
chattr +i /etc/fstab # 加锁防止被修改
chattr -i /etc/fstab # 解除锁
#让某个⽂件只能往⾥⾯追加内容,不能删除,⼀些⽇志⽂件适⽤于这种操作:
chattr +a /data1/user_act.loglsattr filename #用来查看文件件的第⼆扩展⽂件系统属性#⽣成⼀个⽂件insert.sql的md5值:
md5sum insert.sql
d41d8cd98f00b204e9800998ecf8427e insert.sql
# md5多用于文件校验安全检查

vi命令 是UNIX操作系统和类UNIX操作系统中最通⽤的全屏幕纯⽂本编辑器。Linux中的vi编辑器叫vim,它是vi的
增强版(vi Improved),与vi编辑器完全兼容,⽽且实现了很多增强功能。
vi编辑器⽀持编辑模式和命令模式,编辑模式下可以完成⽂本的编辑功能,命令模式下可以完成对⽂件的操作命
令,要正确使⽤vi编辑器就必须熟练掌握着两种模式的切换。默认情况下,打开vi编辑器后⾃动进⼊命令模式。从
编辑模式切换到命令模式使⽤“esc”键,从命令模式切换到编辑模式使⽤“A”、“a”、“O”、“o”、“I”、“i”键。
vi编辑器提供了丰富的内置命令,有些内置命令使⽤键盘组合键即可完成,有些内置命令则需要以冒号“:”开头输
⼊。常⽤内置命令如下:
Esc:从编辑模式切换到命令模式;
ZZ:命令模式下保存当前⽂件所做的修改后退出vi;
:⾏号:光标跳转到指定⾏的⾏⾸;
:$:光标跳转到最后⼀⾏的⾏⾸;
x或X:删除⼀个字符,x删除光标后的,⽽X删除光标前的;
D:删除从当前光标到光标所在⾏尾的全部字符;
dd:删除光标⾏正⾏内容;
ndd:删除当前⾏及其后n-1⾏;
nyy:将当前⾏及其下n⾏的内容保存到寄存器?中,其中?为⼀个字⺟,n为⼀个数字;
p:粘贴⽂本操作,⽤于将缓存区的内容粘贴到当前光标所在位置的下⽅;
P:粘贴⽂本操作,⽤于将缓存区的内容粘贴到当前光标所在位置的上⽅;
/字符串:⽂本查找操作,⽤于从当前光标所在位置开始向⽂件尾部查找指定字符串的内容,查找的字符串会被加亮显
示;
?字符串:⽂本查找操作,⽤于从当前光标所在位置开始向⽂件头部查找指定字符串的内容,查找的字符串会被加亮显
示;
a,bs/F/T:替换⽂本操作,⽤于在第a⾏到第b⾏之间,将F字符串换成T字符串。其中,“s/”表示进⾏替换操作;
a:在当前字符后添加⽂本;
A:在⾏末添加⽂本;
i:在当前字符前插⼊⽂本;
I:在⾏⾸插⼊⽂本;
o:在当前⾏后⾯插⼊⼀空⾏;
O:在当前⾏前⾯插⼊⼀空⾏;
gg: 跳转到第⼀⾏
Shift+G: 跳转到最后⼀⾏
:wq:在命令模式下,执⾏存盘退出操作;
:w:在命令模式下,执⾏存盘操作;
:w!:在命令模式下,执⾏强制存盘操作;
:q:在命令模式下,执⾏退出vi操作;
:q!:在命令模式下,执⾏强制退出vi操作;
:e⽂件名:在命令模式下,打开并编辑指定名称的⽂件;
:n:在命令模式下,如果同时打开多个⽂件,则继续编辑下⼀个⽂件;
:f:在命令模式下,⽤于显示当前的⽂件名、光标所在⾏的⾏号以及显示⽐例;
:set number:在命令模式下,⽤于在最左端显示⾏号;
:set nonumber:在命令模式下,⽤于在最左端不显示⾏号;
#多⾏⽂本追加
cat > 1.text <<EOF
> 1
> 2
> 3EOF
> EOFmore filename # 显示文件内容每次显示一屏cat /etc/passwd | head -n 2 # 查看文件前两行
# tail命令
tail file #(显示⽂件file的最后10⾏)
tail -n +20 file #(显示⽂件file的内容,从第20⾏⾄⽂件末尾)
tail -c 10 file #(显示⽂件file的最后10个字节)
tail -25 mail.log # 显示 mail.log 最后的 25 ⾏0
tail -f mail.log # 等同于--follow=descriptor,根据⽂件描述符进⾏追踪,当⽂件改名或被删除,追踪停
⽌
tail -F mail.log # 等同于--follow=name --retry,根据⽂件名进⾏追踪,并保持重试,即该⽂件被删除或
改名后,如果再次创建相同的⽂件名,会继续追踪
cut 命令
#语法
cut(选项)(参数)
#选项
-b:仅显示⾏中指定直接范围的内容;
-c:仅显示⾏中指定范围的字符;
-d:指定字段的分隔符,默认的字段分隔符为“TAB”;
-f:显示指定字段的内容;
-n:与“-b”选项连⽤,不分割多字节字符;
--complement:补⾜被选择的字节、字符或字段;
--out-delimiter= 字段分隔符:指定输出内容是的字段分割符;
--help:显示指令的帮助信息;
--version:显示指令的版本信息。cat test.txt
No Name Mark Percent
01 tom 69 91
02 jack 71 87
03 alex 68 98cut -f 1 test.txt
No
01
02
03cut -f2,3 test.txt
Name Mark
tom 69
jack 71
alex 68
sort命令netstat -ant # 查找所有tcp的网络连接
netstat -antup | egrep ssh # 查询ssh链接(tcp和udp ) p的意思是以进程的形式netstat -ant | awk 'NR>1{print $NF}' | sort | uniq -c | sort -nrk 1 # awk用来取列 $NF取最后一列 NR>1 行号大于1 sort排序 uniq去重 -c统计 -nrk 1 -n以数字排序r是倒序k是第几列 1就是第一列seq 100 | sort -nr | head -n 10 # 100个数以数字倒叙排序取前10行
uniq # 显示或忽略重复的⾏
grep egrep # 强⼤的⽂本搜索⼯具grep (global search regular expression(RE) and print out the line,全⾯搜索正则表达式并把⾏打印出来)是
⼀种强⼤的⽂本搜索⼯具,它能使⽤正则表达式搜索⽂本,并把匹配的⾏打印出来。⽤于过滤/搜索的特定字符。
可使⽤正则表达式能配合多种命令使⽤,使⽤上⼗分灵活。-A <显示⾏数> --after-context=<显示⾏数> # 除了显示符合范本样式的那⼀⾏之外,并显示该⾏之后的
内容。
-B<显示⾏数> --before-context=<显示⾏数> # 除了显示符合样式的那⼀⾏之外,并显示该⾏之前的内
容。
-o # 只输出⽂件中匹配到的部分。
-n --line-number # 在显示符合范本样式的那⼀列之前,标示出该列的编号。
-E --extended-regexp # 将范本样式为延伸的普通表示法来使⽤,意味着使⽤能使⽤扩展正则表
达式。
-i --ignore-case # 忽略字符⼤⼩写的差别。# 正则表达式
^ # 锚定⾏的开始 如:'^grep'匹配所有以grep开头的⾏。
$ # 锚定⾏的结束 如:'grep$' 匹配所有以grep结尾的⾏。
. # 匹配⼀个⾮换⾏符的字符 如:'gr.p'匹配gr后接⼀个任意字符,然后是p。
* # 匹配零个或多个先前字符 如:'*grep'匹配所有⼀个或多个空格后紧跟grep的⾏。
.* # ⼀起⽤代表任意字符。
[] # 匹配⼀个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] # 匹配⼀个不在指定范围内的字符,如:'[^A-Z]rep' 匹配不包含 A-Z 中的字⺟开头,紧跟 rep 的⾏
\(..\) # 标记匹配字符,如'\(love\)',love被标记为1。
\< # 锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的⾏。
\> # 锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的⾏。
x\{m\} # 重复字符x,m次,如:'0\{5\}'匹配包含5个o的⾏。
x\{m,\} # 重复字符x,⾄少m次,如:'o\{5,\}'匹配⾄少有5个o的⾏。
x\{m,n\} # 重复字符x,⾄少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的⾏。
\w # 匹配⽂字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个⽂字或数字字符,然后
是p。
\W # \w的反置形式,匹配⼀个或多个⾮单词字符,如点号句号等。
\b # 单词锁定符,如: '\bgrep\b'只匹配grep。egrep -r "^s.*nologin&" /etc/passwd # 搜索文件以s开头以nologin结尾 .*是匹配所有 -r是递归的方式查找 -l 打印文件名egrep -r "error" # 只显示error的内容
egrep -r "\berror\b" #只显示error的内容精确匹配egrep -v "error" filename # 过滤没有eorror内容
egrep "[1-9]" 1.txt # 过滤1-9#标记匹配颜⾊ --color=auto 选项:
grep "match_pattern" file_name --color=auto#使⽤正则表达式 -E 选项:
grep -E "[1-9]+"
# 或
egrep "[1-9]+"# 只输出⽂件中匹配到的部分 -o 选项:
echo this is a test line | grep -o -E "[a-z]+\."
line
echo this is a test line | egrep -o "[a-z]+\."
line统计⽂件或者⽂本中包含匹配字符串的⾏数 -c 选项:
grep -c "text" file_namehistory #历史命令
history -c #清空所有列表
history -d # 清空指定行
tr # 将字符进⾏替换压缩和删除
-d或--delete:删除所有属于第⼀字符集的字符;# 将输⼊字符由⼤写转换为⼩写:
echo "HELLO WORLD" | tr 'A-Z' 'a-z'
hello worldecho "hello 123 world 456" | tr -d '0-9' # 使用tr删除字符
hello world
vimdiff
# 文件内容对比
vimdiff file1 file2
dos2unix
# 将DOS格式⽂本⽂件转换成Unix格式
dos2unix file
# 文件压缩
tarunzip gzip zip
# 信息显示命令
name -a # 查看系统版本内核
hostname # 查看机器ip
hostname -I # 查看机器网卡ipifconfig eth0 | awk 'NR==2{print $2}' # 取第二行 2个空格后uptime # 查看系统运行时间
load average # 系统负载字段
stat filename # 查看文件属性
du -sh ./* # 查看当前目录下所有文件大小
df -h # 查看磁盘大小
df -I # 查看inodefind ./ -type f -empty |xargs rm -rf # 查找空文件并删除find ./ -type f -size +1b # 查找大于1b的文件top # 实时查看系统运行状态负载 内存 cpu 等
date # 看日期
free -h # 查看系统资源
网络命令
nslookup # 用于dns解析dig # 用于dns解析strace -e connect,socket nslookup www.baidu.com # 如果dns解析不了用这个跟踪命令查看状态tcpdump -I any port 53 -nn #抓包分析所有流量53端口的 -nn 表示不将地址和端口号转换为名称traceroute # 跟踪路由mtr # 跟踪路由tcpdump #分析网络相关故障或者流量
tcpdump -I any not arp and not port 22 -w dns.capa. # any代表所有网卡接口 not arp过滤arp协议mtr # 探测的速率快