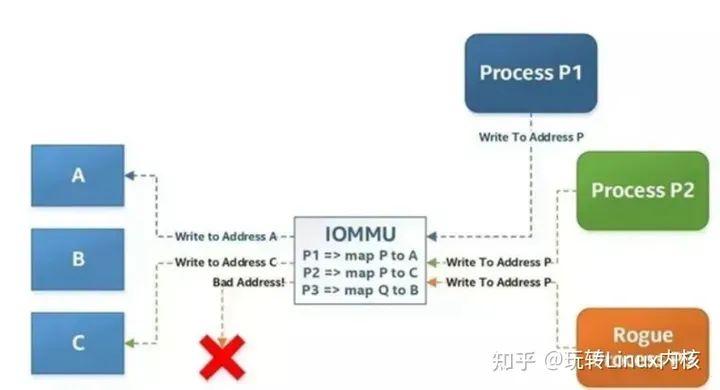
知乎,作为国内知名的知识分享平台,其背后复杂的架构和庞大的用户量对技术团队提出了极高的要求。近年来,知乎在云原生和Kubernetes(K8S)方面的实践,尤其是稳定性建设方面的经验,值得深入探讨和学习。本文将基于知乎核心架构平台工程师赵禹的分享,详细解析知乎在Kubernetes稳定性建设中的关键步骤和取得的成果。
知乎云原生架构的演进
从2016年开始,知乎的云原生架构经历了从业务容器化到混合云的多个阶段。最初,知乎使用Mesos作为容器编排工具,随后迁移到Kubernetes,实现了中间件和数据库的容器化,并引入了ServiceMesh。目前,知乎的Kubernetes集群数量超过10个,分为基础组件集群、业务集群以及训练和推理服务专用集群,整体架构分为应用层、组件层、OS层和基础组件层。
Kubernetes稳定性建设的挑战
在Kubernetes的稳定性建设过程中,知乎遇到了多种挑战,包括集群的容灾能力不足、资源碎片化、紧急增加机器时装机速度慢、Kubernetes问题排查困难、权限管理混乱、调度不均衡、资源干扰过大、缺乏审计操作无法追溯、告警过多等问题。
稳定性建设的关键阶段和案例
知乎的Kubernetes稳定性建设经历了四个主要阶段:
Kubernetes集群改造:这一阶段主要关注Apiserver和DNS的稳定性。通过改造CoreDNS代码,使其在Apiserver挂掉时能够缓存数据,并使用本地DNS组件,确保DNS的稳定性。
系统能力改造:知乎自研了多云管控平台,收敛权限,提升人效,并实现了多集群的可观测性。
资源兜底能力改造:包括多云弹扩能力和镜像多活组件的自研,确保在在线业务利用率过高时能够伸缩节点兜底。
基础组件能力改造:知乎优化了调度器,降低了告警频率,并自研了自愈组件(Joba),通过NPD组件的二次开发,实现了自愈规则和故障SOP。
收益与展望
通过这些改造,知乎在Kubernetes的稳定性方面取得了显著收益,包括自愈能力、伸缩弹扩、核心组件的限流与兜底、隔离能力、多云管控能力以及负载均衡与隔离能力。资源使用方面,改造后的集群在内存使用和均衡性方面有显著提升。同时,知乎还实现了精准的告警与监控,以及多云事件中心的可观测性。
展望未来,知乎计划在网络可观测性、数据集调度和多云多集群基础能力支持方面进行进一步优化。
结语
知乎在Kubernetes稳定性建设方面的实践,不仅展示了其在云原生领域的深厚技术积累,也为行业提供了宝贵的经验。通过不断的优化和改造,知乎成功应对了大规模集群管理的挑战,为业务的稳定和高效运行提供了坚实的技术保障。