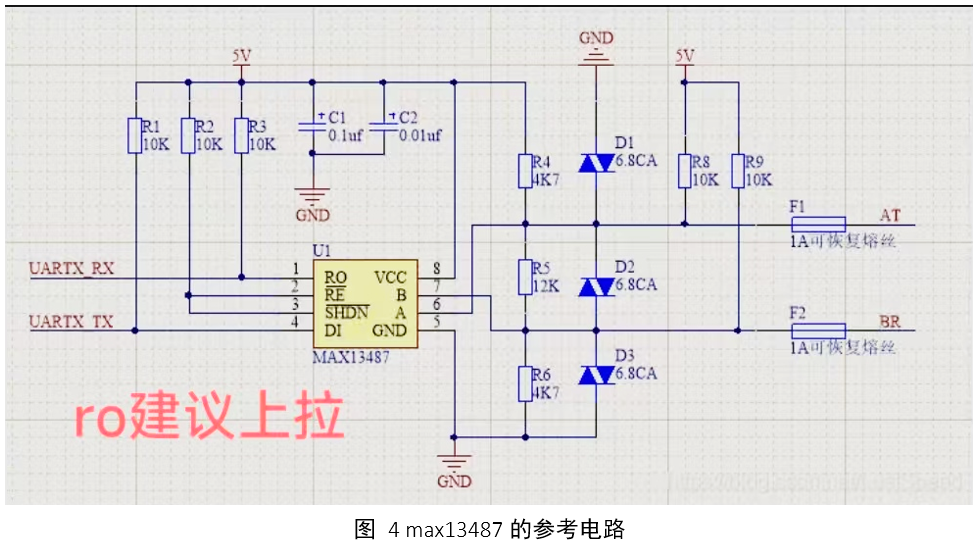
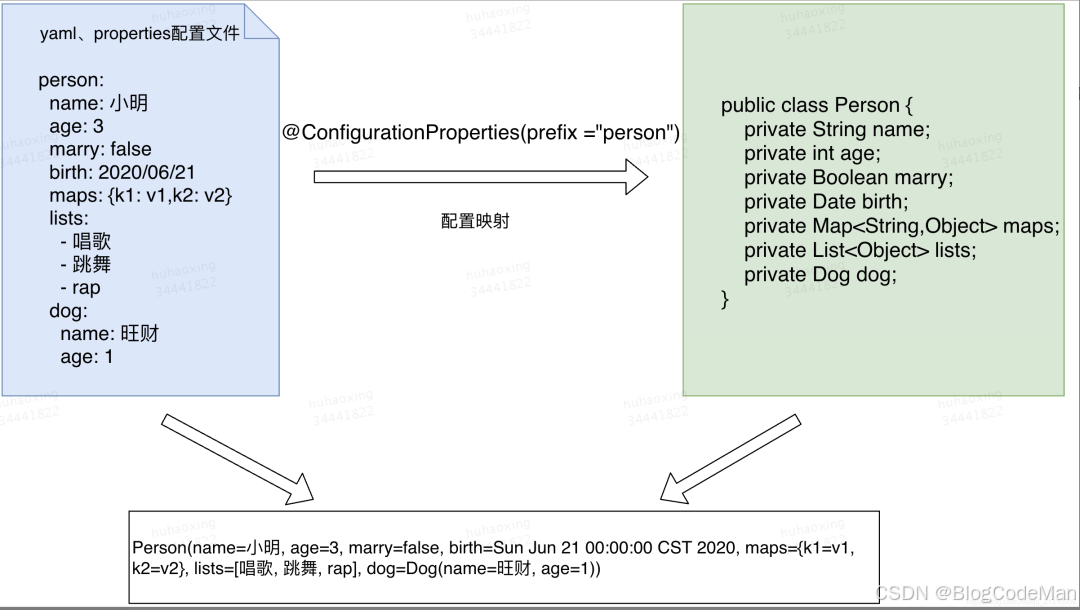
每个时间戳对应1×21数组,将其求和为1×1
#!usr/bin/env python # -*- coding:utf-8 -*- """ @author: Suyue @file: lianxi.py @time: 2025/03/11 @desc: """ import numpy as np import re import osdef calculate_concentration_clumnsum_intensity(concentration):"""雨滴谱数浓度 concentration:return: 求和 concentration_clumnsum (1×1),结果保留 2 位小数"""# 计算数浓度列求和,并保留 2 位小数concentration_clumnsum = round(np.sum(concentration), 2) # 对整个数组求和return concentration_clumnsumdef read_concentrations_data(file_path):"""读取雨滴谱数浓度数据:param file_path: 输入文件路径:return: timestamps (时间戳列表), concentration_matrices (浓度矩阵列表,每个矩阵为1×21)"""timestamps = []concentration_matrices = []with open(file_path, 'r') as file:lines = file.readlines()i = 0while i < len(lines):# 读取时间戳line = lines[i].strip()if re.match(r'\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}', line):timestamps.append(line)i += 1 # 移动到下一行# 初始化一个空列表来存储1×21数组的元素array_elements = []# 读取接下来的1行,每行包含21个数值if i < len(lines):row = lines[i].strip().split()# 检查当前行是否是时间戳(避免错误)if not re.match(r'\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}', lines[i].strip()):row_elements = list(map(float, row)) # 将行数据转换为浮点数 array_elements.extend(row_elements)i += 1# 将一维列表转换为1×21的NumPy数组if len(array_elements) == 21:concentration = np.array(array_elements).reshape(1, 21) # 转换为1×21的数组 concentration_matrices.append(concentration)else:# 如果数据不完整,跳过这个时间戳 timestamps.pop()else:# 如果当前行不是时间戳,则可能是空行或其他无效数据,跳过它i += 1return timestamps, concentration_matricesdef write_raindrop_concentration_clumnsum_to_file(timestamps, concentration_clumnsum, output_file_path):"""将时间戳和求和结果写入文件:param timestamps: 时间戳列表:param concentration_clumnsum: 求和结果列表(每个元素是一个标量值):param output_file_path: 输出文件路径"""with open(output_file_path, 'w') as file:for timestamp, sum_value in zip(timestamps, concentration_clumnsum):file.write(f"{timestamp}\n")file.write(f"{sum_value:.2f}\n") # 保留 2 位小数file.write("\n") # 每个时间戳的数据块之间加一个空行作为分隔# 批量处理多个文件夹 def batch_process_concentration_clumnsum_files(input_dir, output_dir):# 确保输出目录存在os.makedirs(output_dir, exist_ok=True)# 遍历输入目录中的所有TXT文件for filename in os.listdir(input_dir):if filename.endswith('.txt'):file_path = os.path.join(input_dir, filename)# 读取数据timestamps, concentration_matrices = read_concentrations_data(file_path)concentration_clumnsum_results = [] # 创建一个新的列表来存储降水强度结果for concentration in concentration_matrices:concentration_clumnsum_intensity = calculate_concentration_clumnsum_intensity(concentration)concentration_clumnsum_results.append(concentration_clumnsum_intensity) # 将计算结果添加到新列表中# 构造输出文件路径output_file_path = os.path.join(output_dir, f"{os.path.splitext(filename)[0]}_one.txt")# 将结果写入文件 write_raindrop_concentration_clumnsum_to_file(timestamps, concentration_clumnsum_results, output_file_path)# 输入和输出目录 input_dir = 'F:/lianxi2/' # 替换为您的输入文件目录路径 output_dir = 'F:/lianxi2/result' # 替换为您的输出文件目录路径# 批量处理文件 batch_process_concentration_clumnsum_files(input_dir, output_dir)