近期大语言模型(LLM)的基准测试结果引发了对现有架构扩展性的思考。尽管OpenAI推出的GPT-4.5被定位为其最强大的聊天模型,但在多项关键基准测试上的表现却不及某些规模较小的模型。DeepSeek-V3在AIME 2024评测中达到了39.2%的Pass@1准确率,在SWE-bench Verified上获得42%的准确率,而GPT-4.5在这两项基准测试上的得分分别仅为36.7%和38%。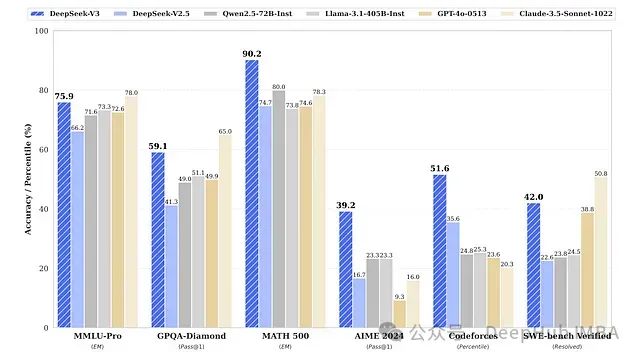
DeepSeek-V3与其他LLM的性能对比(数据来源:ArXiv研究论文《DeepSeek-V3 Technical Report》)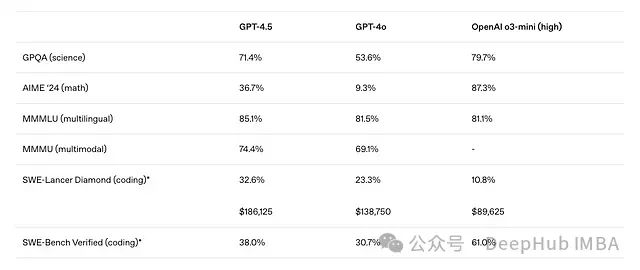
GPT-4.5与其他OpenAI模型的性能对比(数据来源:OpenAI博客文章《Introducing GPT-4.5》)
这一现象促使研究者思考:现有的LLM架构是否需要根本性的改进以实现更高水平的扩展性能?
研究人员最近提出的FANformer架构为这一问题提供了一个可能的解决方案。该架构通过将傅里叶分析网络(Fourier Analysis Network, FAN)整合到Transformer的注意力机制中,形成了一种创新的模型结构。实验数据显示,随着模型规模和训练数据量的增加,FANformer始终表现出优于传统Transformer架构的性能。特别值得注意的是,拥有10亿参数的FANformer模型在性能上超过了同等规模和训练量的开源LLM。
https://avoid.overfit.cn/post/1b2f515689d947fc9aae9d22f41b506f