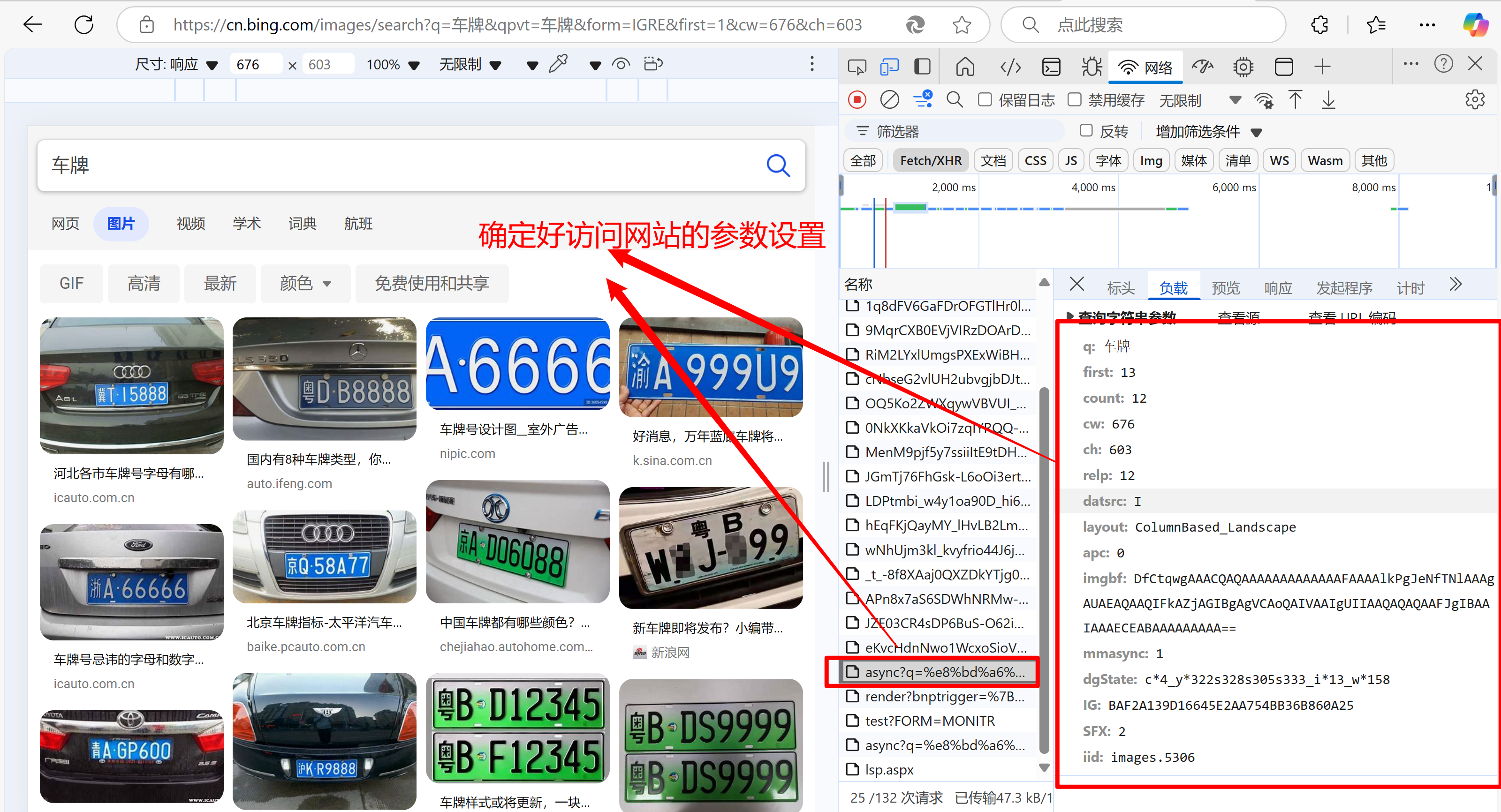
介绍
S2S (语音到语音) 是 Hugging Face 社区内存在的一个令人兴奋的新项目,它结合了多种先进的模型,创造出几乎天衣无缝的体验: 你输入语音,系统会用合成的声音进行回复。
该项目利用 Hugging Face 社区中的 Transformers 库提供的模型实现了流水话处理。该流程处理由以下组件组成:
- 声音活动检测 (VAD)
- 语音识别 (STT)
- 语言模型 (LLM)
- 文本转语音 (TTS)
除此之外,S2S 项目支持多语言!目前支持英语、法语、西班牙语、中文、日语和韩语。您可以使用单语言模式运行此流程或通过 auto 标志进行语言自动检测。请查看 这里 的仓库获取更多详情。
> 👩🏽这些都是很棒的功能,但我该如何运行 S2S 呢?
> 🤗: 很好的问题!
运行语音转语音项目需要大量的计算资源。即使在高端笔记本电脑上,你也可能会遇到延迟问题,特别是在使用最先进的模型时。虽然强大的 GPU 可以缓解这些问题,但并不是每个人都有条件 (或意愿) 去搭建他们的硬件设备。
这正是 Hugging Face 的 推理端点 (IE) 发挥作用的地方。推理端点允许您租用带有 GPU (或其他可能需要的硬件) 的虚拟机,并仅需按系统运行时间付费,为部署如语音转语音这类大型应用提供了理想的解决方案。
在本文中,我们将逐步指导您将 Speech-to-Speech 部署到 Hugging Face 推理端点上。以下是主要内容:
- 理解推理端点,并快速了解设置 IE 的不同方式,包括自定义容器镜像 (这正是我们需要用于 S2S 的)
- 构建适用于 S2S 的自定义 Docker 镜像
- 将自定义镜像部署到 IE 并尽情体验 S2S!
推理断点
推理端点提供了一种可扩展且高效的方式部署机器学习模型。这些端点允许您在最少设置的情况下利用各种强大的硬件用模型提供服务。推理端点非常适合需要高性能和高可靠性的应用程序部署,而无需管理底层基础设施。
以下是几个关键功能,请查阅文档获取更多信息:
- 简洁性 - 由于 IE 直接支持 Hugging Face 库中的模型,您可以在几分钟内快速上手。
- 可扩展性 - 您无需担心规模问题,因为 IE 可以自动扩展 (包括缩小规模到零),以应对不同的负载并节省成本。
- 自定义 - 您可以根据需要自定义 IE 的设置来处理新任务。更多详情请参见下方内容。
推理端点支持所有 Transformers 和 Sentence-Transformers 任务,也可以支持自定义任务。这些是 IE 设置选项:
- 预构建模型: 直接从 Hugging Face 枢纽快速部署模型。
- 自定义处理器: 为更复杂的流程任务自定义推理逻辑。
- 自定义 Docker 映像: 使用您自己的 Docker 映像封装所有依赖项和自定义代码。
对于简单的模型,选项 1 和 2 是理想的选择,并且可以使用推理端点部署变得极其简单。然而,对于像 S2S 这样的复杂流程任务来说,您将需要选项 3 提供的灵活性: 通过自定义 Docker 镜像部署我们的 IE。
这种方法不仅提供了更多的灵活性,还通过优化构建过程并收集必要的数据提高了性能。如果您正在处理复杂的模型流程任务或希望优化应用程序的部署,请参考本指南以获得有价值的见解。
在推理端点上部署语音转语音模型
让我们开始吧!
构建自定义 Docker 镜像
为了开始创建一个自定义的 Docker 镜像,我们首先克隆了 Hugging Face 的标准 Docker 镜像仓库。这为在推理任务中部署机器学习模型提供了一个很好的起点。
git clone https://github.com/huggingface/huggingface-inference-toolkit
为什么克隆默认镜像仓库?
- 坚实的基础: 仓库提供了专门为推理工作负载优化的基础镜像,这为可靠地开始推理任务提供了一个牢固的基础。
- 兼容性: 由于该镜像是按照与 Hugging Face 部署环境对齐的方式构建的,因此在部署您自己的自定义镜像时可以确保无缝集成。
- 易于定制化: 仓库提供了干净且结构化的环境,使得为应用程序的具体要求定制镜像变得容易。
您可以查看所有更改内容 在这里
为语音识别应用自定义 Docker 镜像
克隆了仓库后,下一步是根据我们的语音识别流程需求来调整镜像。
- 添加语音到语音项目
为了无缝集成该项目,我们添加了语音转语音识别的代码库以及所需的任何数据集作为子模块。这种方法提供了更好的版本控制能力,在构建 Docker 镜像时可以确保始终使用正确的代码和数据版本。
通过将数据直接包含在 Docker 容器中,我们避免了每次实例化端点时都需要下载数据,这显著减少了启动时间并确保系统可重复。这些数据被存储在一个 Hugging Face 仓库中,提供了易于跟踪和版本控制的功能。
git submodule add https://github.com/huggingface/speech-to-speech.git
git submodule add https://huggingface.co/andito/fast-unidic
- 优化 Docker 镜像
接下来,我们修改了 Dockerfile 文件来满足我们的需求:
- 精简镜像: 移除了与用例无关的软件包和依赖项。这减少了镜像大小,并在推理过程中降低了不必要的消耗。
- 安装依赖项: 我们将
requirements.txt的安装从入口点移动到了 Dockerfile 本身。这样,当构建 Docker 镜像时会安装这些依赖项,从而加快部署速度,因为运行时将不需要再次安装这些包。
- 部署自定义镜像
完成修改后,我们构建并推送了自定义镜像到 Docker Hub:
DOCKER_DEFAULT_PLATFORM="linux/amd64" docker build -t speech-to-speech -f dockerfiles/pytorch/Dockerfile .
docker tag speech-to-speech andito/speech-to-speech:latest
docker push andito/speech-to-speech:latest
Docker 镜像构建并推送后,就可以在 Hugging Face 推理端点中使用了。通过使用这个预构建的镜像,端点可以更快地启动并且运行得更高效,因为所有依赖项和数据都已预先打包在镜像中。
设置推理端点
使用自定义 Docker 镜像只需稍微不同的配置,您可以点击并查看 文档。我们将通过图形界面和 API 调用两种方式来介绍如何做到这一点。
前置步骤
- 登录: https://huggingface.co/login
- 请求访问 meta-llama/Meta-Llama-3.1-8B-Instruct
- 创建细粒度令牌: https://huggingface.co/settings/tokens/new?tokenType=fineGrained

- 选择访问受限制的仓库权限
- 如果您正在使用 API,请确保选择管理推理端点的权限
推断端点 GUI
- 访问 https://ui.endpoints.huggingface.co/new
- 填写相关信息:
- 模型仓库 -
andito/s2s - 模型名称 - 如果不喜欢生成的名称,可以自由重命名
- 例如:
speech-to-speech-demo - 保持小写字母且简短
- 例如:
- 选择您偏好的云和硬件配置 - 我们使用了
AWS GPU L4- 只需每小时 $0.80,足够用来处理模型
- 高级配置 (点击展开箭头 ➤)
- 容器类型 -
Custom - 容器端口 -
80 - 容器 URL -
andito/speech-to-speech:latest - 密钥 –
HF_TOKEN|<您的令牌在这里>
- 容器类型 -
点击展示图片步骤


- 点击
创建终端节点
[!NOTE] 实际上模型仓库并不重要,因为模型会在容器创建时指定和下载。但是推理终端节点需要一个模型,所以你可以选择你喜欢的一个较轻量级的。
[!NOTE] 你需要指定
HF_TOKEN因为我们需要在容器创建阶段下载受限制访问的模型。如果你使用的是未受限或私有的模型,则不需要这样做。
[!WARNING] 当前
[huggingface-inference-toolkit 入口点](https://github.com/huggingface/huggingface-inference-toolkit/blob/028b8250427f2ab8458ed12c0d8edb50ff914a08/scripts/entrypoint.sh#L4)默认使用的是端口 5000,但推理终端节点期望的端口号是 80。你应该在 容器端口 中匹配这一点。我们已经在 Dockerfile 中设置了这个值,但如果从零开始构建,请务必注意!
推理端点 API
在这里,我们将逐步介绍创建带有 API 的端点步骤。只需在您选择的 Python 环境中使用以下代码。
确保使用版本 0.25.1 或更高版本
pip install huggingface_hub>=0.25.1
使用一个可以写入端点 (Write 或 细粒度权限) 的 Hugging Face 令牌
from huggingface_hub import login
login()
from huggingface_hub import create_inference_endpoint, get_token
endpoint = create_inference_endpoint(# Model Configuration"speech-to-speech-demo",repository="andito/s2s",framework="custom",task="custom",# Securitytype="protected",# Hardwarevendor="aws",accelerator="gpu",region="us-east-1",instance_size="x1",instance_type="nvidia-l4",# Image Configurationcustom_image={"health_route": "/health","url": "andito/speech-to-speech:latest", # Pulls from DockerHub"port": 80},secrets={'HF_TOKEN': get_token()}
)# Optional
endpoint.wait()
预览

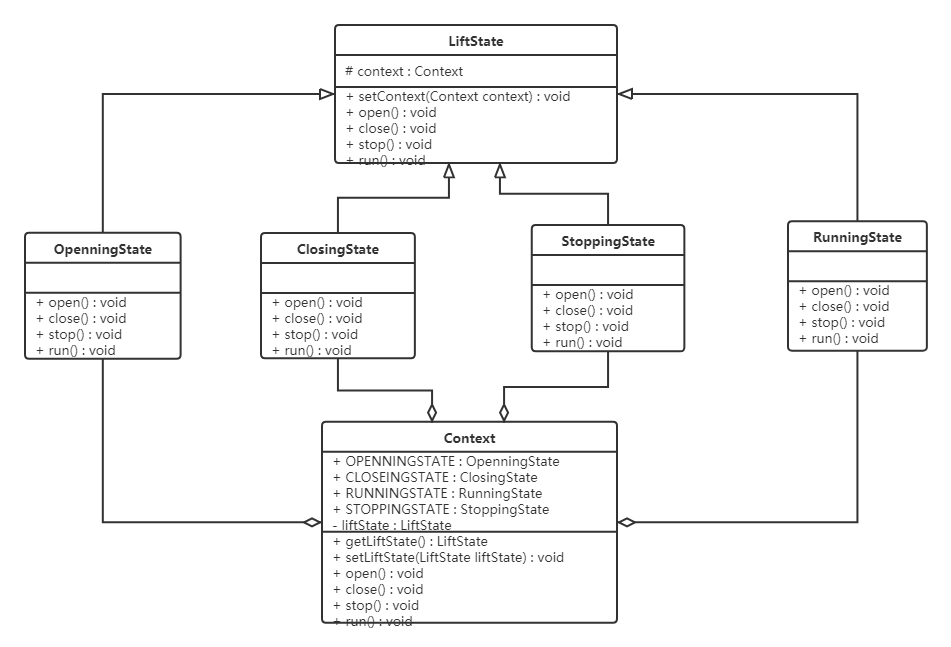
主要组件
- 语音转语音
- 这是一个 Hugging Face 库,我们在
inference-endpoint分支中加入了一些特定于推理端点的文件,该分支很快将合并到主分支。
- 这是一个 Hugging Face 库,我们在
- andito/s2s 或其他任何仓库。这对我们来说不是必需的,因为我们已经在容器创建阶段包含了模型,但推理端点需要一个模型,所以我们传递了一个瘦身后的仓库。
- andimarafioti/语音转语音工具包
- 这是 huggingface/huggingface-inference-toolkit 的分支,帮助我们构建符合我们需求的自定义容器。
构建 web 服务器
为了使用端点,我们需要构建一个小的 WebService 服务。这部分代码位于 speech_to_speech 库 中的 s2s_handler.py 以及我们用于客户端的 speech_to_speech_inference_toolkit 工具包 中的 webservice_starlette.py ,后者被用来构建 Docker 镜像。通常情况下,你只需要为端点编写一个自定义处理程序即可,但由于我们希望实现极低的延迟,因此还特别构建了支持 WebSocket 连接的 WebService 而不是普通的请求方式。乍一听起来可能有些令人望而生畏,但这个 WebService 服务代码只有 32 行!

这段代码将在启动时运行 prepare_handler ,这将初始化所有模型并预热它们。然后,每个消息将会由 inference_handler.process_streaming_data 处理。

这种方法简单地从客户端接收音频数据,将其分割成小块供 VAD 处理,并提交到队列进行处理。然后检查输出处理队列 (模型的语音响应!),如果有内容则返回。所有的内部处理均由 Hugging Face 的 speech_to_speech 库 负责。
自定义处理程序和客户端
WebService 接收并返回音频,但仍然缺少一个重要的部分: 我们如何录制和回放音频?为此,我们创建了一个 客户端,用于连接到服务。最简单的方法是将分析分为与 WebService 的连接以及录音/播放音频两部分。

初始化 WebService 客户端需要为所有消息设置一个包含我们 Hugging Face Token 的头部。在初始化客户端时,我们需要设定对常见消息的操作 (打开、关闭、错误、信息)。这将决定当服务器向我们的客户端发送消息时,客户端会执行什么操作。

我们可以看到,对接收到的消息的反应非常直接,只有 on_message 方法较为复杂。该方法能够理解服务器完成响应后开始“监听”用户的回复。否则,它会将从服务器接收到的数据放入播放队列中。

客户的音频部分有 4 个任务:
- 录制音频
- 提交音频录制文件
- 接收服务器的音频响应
- 播放音频响应
录音是在 audio_input_callback 方法中完成的,它只是将所有片段提交到一个队列。然后使用 send_audio 方法将其发送给服务器。在此过程中,如果没有要发送的音频,则仍然提交空数组以从服务器接收响应。我们之前在博客中看到的 on_message 方法处理来自服务器的响应。随后,音频响应的播放由 audio_output_callback 方法处理。在这里,我们需要确保音频处于我们预期的范围内 (不希望因为错误的数据包而损上某人的耳膜!),并确保输出数组的大小符合播放库的要求。
结论
在本文中,我们介绍了如何使用自定义 Docker 镜像,在 Hugging Face 推断端点上部署语音到语音 (S2S) 流程的步骤。我们构建了一个定制容器来处理 S2S 流程的复杂性,并展示了如何对其进行配置以实现可扩展且高效的部署。Hugging Face 推断端点使得将如语音到语音这类性能密集型应用程序变为现实变得更加容易,无需担心硬件或基础设施管理的问题。
如果您想尝试一下或者有任何问题,请探索以下资源:
- Speech-to-Speech GitHub 仓库
- Speech-to-Speech 推断工具包
- 基础推断工具包
- Hugging Face 推断端点文档
遇到问题或有任何疑问?请在相关 GitHub 仓库中开启讨论,我们将非常乐意帮助您!
英文原文: https://hf.co/blog/s2s_endpoint
原文作者: Andres Marafioti, Derek Thomas, Diego Maniloff, Eustache Le Bihan
译者: smartisan