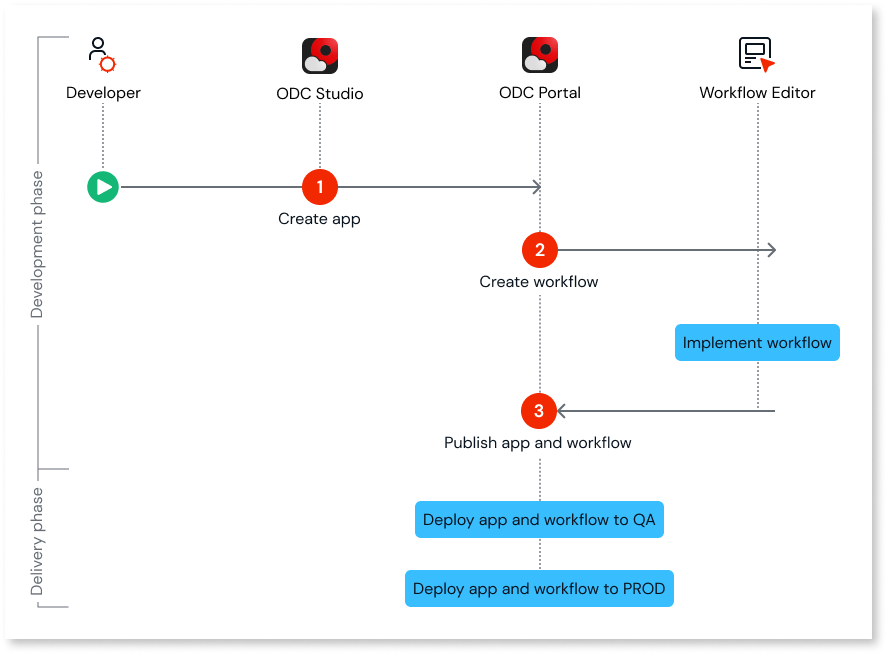
1. LLM 推理阶段概述:
- Prefill 阶段(预填充):
- 此阶段是 LLM 推理的初始阶段,负责处理输入的提示(prompt)。
- 其主要任务是将输入的文本转换为模型可以理解的内部表示,即 Key/Value (KV) 缓存。
- Prefill 阶段的计算量通常较大,尤其是在处理长提示时。
- Decode 阶段(解码):
- 此阶段是 LLM 推理的生成阶段,负责根据 Prefill 阶段生成的 KV 缓存,逐一生成后续的 token。
- Decode 阶段是一个迭代的过程,每次生成一个 token,并将其添加到已生成的序列中,直到达到预定的生成长度或生成结束符。
- Decode 阶段的显存消耗通常较大,因为 KV 缓存会随着生成过程不断增长。
2. Prefill 阶段详解:
- 作用:处理输入提示,生成 KV 缓存
- Prefill 阶段接收用户输入的文本提示,并将其分解为 token。
- 对于每个 token,模型都会计算其 Key 和 Value 向量,这些向量被存储在 KV 缓存中。
- KV 缓存是后续 Decode 阶段的基础,它允许模型快速访问先前处理过的信息。
- 工作原理:完整序列处理,KV 缓存生成
- 在 Prefill 阶段,模型会一次性处理整个输入序列,并为序列中的每个 token 计算 KV 向量。
- 这种完整序列处理的方式可以充分利用 GPU 的并行运算能力,提高处理效率。
- 资源消耗:计算密集型,GPU 算力需求高
- Prefill 阶段涉及大量的矩阵运算,因此对 GPU 的算力要求非常高。
- 长的输入序列会增加计算量,导致更长的处理时间,同时也会增加 GPU 显存的压力。
- 优化技术:
- Chunked Prefills(分块预填充):
- 将长的输入序列分割成小的 chunk,分批次放入模型中计算。
- 优点:降低 GPU 显存压力,处理更长的输入序列。
- 优化点:合理设置 chunk 大小,平衡显存消耗和计算效率。
- KV 缓存压缩:
- 降低 KV 缓存的大小,减少显存占用和带宽需求。
- 优化点:使用量化、剪枝等技术,在保证模型性能的前提下,压缩 KV 缓存。
- 算子融合(Operator Fusion):
- 将多个连续的运算操作合并为一个操作,减少显存存取和运算开销。
- 优化点:针对特定的模型架构和硬件平台,设计高效的融合算子。
- 硬件加速:
- 利用专用的硬件加速器(如 GPU、TPU),提高矩阵运算的效率。
- 优化点:选择适合 LLM 推理的硬件平台,并充分利用其硬件特性。
- 优化注意力机制:
- 注意力机制是 Prefill 阶段的主要计算瓶颈。
- 优化点:使用稀疏注意力、线性注意力等技术,降低注意力机制的计算复杂度。
- Chunked Prefills(分块预填充):
3. Decode 阶段详解:
- 作用:根据 KV 缓存,逐一生成 token
- Decode 阶段利用 Prefill 阶段生成的 KV 缓存,逐个生成后续的 token。
- 对于每个新生成的 token,模型会根据 KV 缓存中的信息,计算其生成概率。
- 工作原理:基于 KV 缓存推理,词汇表输出,KV 缓存更新
- Decode 阶段会计算当前 token 的 Query 向量,并使用 Query 向量和 KV 缓存中的 Key 向量计算注意力分数。
- 根据注意力分数和 KV 缓存中的 Value 向量,模型会计算上下文向量,并从词汇表中选择一个最有可能的 token 作为输出。
- 新产生的 token 的 K、V 会被加入到 KV 缓存中,为下一次 decode 做准备。
- 资源消耗:显存密集型,GPU 显存需求高
- Decode 阶段需要频繁读取和更新 KV 缓存,因此对 GPU 的显存带宽和容量有很高的要求。
- 随着生成过程的进行,KV 缓存会不断增长,导致显存消耗不断增加。
- 优化技术:
- KV 缓存管理:
- 高效管理 KV 缓存,减少显存存取和带宽需求。
- 优化点:使用缓存置换策略,及时释放不再使用的 KV 缓存。
- 批次解码(Batch Decoding):
- 同时生成多个序列的 token,提高 GPU 的利用率。
- 优化点:合理设置批次大小,平衡延迟和吞吐量。
- 推测解码(Speculative Decoding):
- 使用一个小的「草稿」模型快速生成多个推测 token,然后使用一个大的「验证」模型验证这些推测。
- 优化点:优化草稿模型和验证模型的协同工作,提高生成效率。
- 连续批次解码(Continuous Batching):
- 动态调整批次大小,充分利用 GPU 的资源。
- 优化点:设计高效的调度器,根据当前 GPU 的负载情况,动态调整批次大小。
- 量化和剪枝:
- 在保证模型性能的前提下,降低模型权重的精度,减少显存占用和运算开销。
- 优化点:选择合适的量化和剪枝策略,平衡模型大小和性能。
- KV 缓存管理:
4. 推理时间计算:
- 总推理时间 = Prefill 阶段时间 + Decode 阶段时间
- 这是最基本的计算公式,它将总推理时间分解为 Prefill 阶段和 Decode 阶段的时间之和。
- 总推理时间 = TTFT + (TPOT * 生成 token 的总数)
- 这个公式更具体地描述了每个阶段的时间如何计算。
- TTFT(Time To First Token)代表生成第一个 token 所需的时间,主要反映了 Prefill 阶段的时间。
- TPOT(Time Per Output Token)代表生成每个输出 token 所需的平均时间,TPOT 乘以生成的 token 总数,就得到了 Decode 阶段的总时间。
5. 资源消耗对比:
- Prefill 阶段:算力密集型
- 主要消耗 GPU 的运算资源,对 GPU 的并行运算能力要求高。
- 长的输入序列会增加 GPU 显存压力。
- Decode 阶段:显存密集型
- 主要消耗 GPU 的显存资源,对 GPU 的显存容量和带宽要求高。
- 生成的 token 越多,消耗的显存越大。
6. 整体优化:
- Prefill-Decode 分离式推论架构:
- 将 Prefill 阶段和 Decode 阶段分离,分别在不同的硬件资源上执行。
- 优化点:根据不同阶段的资源消耗特性,合理分配硬件资源。
- 模型蒸馏:
- 使用一个小的「学生」模型模仿一个大的「教师」模型的行为。
- 优化点:设计有效的蒸馏策略,保证学生模型的性能。
- 硬件和软件协同优化:
- 针对特定的硬件平台,优化模型架构和推理引擎。
- 优化点:充分利用硬件特性,设计高效的软件实现。