个人项目作业 - 论文查重
作业基本信息
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 双学位2022级软件工程课程 |
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 打造一款论文查重系统,旨在精准计算两篇文本之间的相似度,并以清晰直观的方式呈现最终结果。通过这一开发历程,期望深入探索代码管理的规范之道,细致剖析系统性能的优化策略,并熟练掌握单元测试的严谨流程,全方位锤炼软件开发的综合素养,为后续的项目实践筑牢坚实根基,积累宝贵经验。 |
- 作者:赵文启
- 学号:
3122000512 - GitHub仓库:GitCode仓库
项目简介
本项目是一个论文查重工具,基于 Python 实现。通过对比原文和抄袭版论文的文本内容,计算两者的相似度,并将结果输出到指定文件中。项目使用了 Python 内置的 difflib 库来实现文本相似度计算,并结合文件读写和性能分析功能。
项目结构
project/
├── test/ # 测试文件夹
│ ├── orig.txt # 原文文件
│ ├── plagiarized.txt # 抄袭版论文文件
│ ├── output.txt # 查重结果输出文件
│ ├── profile_output.txt # 性能分析结果文件
│ └── test_file.txt # 单元测试临时文件
├── dataset/ # 数据集文件夹
│ ├── orig.txt # 原文文件
│ ├── orig_0.8_add.txt # 添加内容的抄袭版
│ ├── orig_0.8_del.txt # 删除内容的抄袭版
│ ├── orig_0.8_dis_1.txt # 修改内容的抄袭版(1处修改)
│ ├── orig_0.8_dis_10.txt # 修改内容的抄袭版(10处修改)
│ └── orig_0.8_dis_15.txt # 修改内容的抄袭版(15处修改)
├── main.py # 主程序文件
└── README.md # 项目说明文件
论文查重原理
1. 文本相似度计算
本项目使用 Python 内置的 difflib.SequenceMatcher 类来计算文本相似度。SequenceMatcher 基于最长公共子序列(Longest Common Subsequence, LCS)算法,能够高效地比较两个文本的相似性。
算法核心
- 最长公共子序列:找到两个文本中最长的相同子序列。
- 相似度计算:通过公式
similarity = (2 * LCS长度) / (文本1长度 + 文本2长度)计算相似度。
示例
- 原文:
今天是星期天,天气晴,今天晚上我要去看电影。 - 抄袭版:
今天是周天,天气晴朗,我晚上要去看电影。 - 相似度计算结果:
0.81
2. 文件读写
项目通过 Python 的文件读写功能,从指定路径读取原文和抄袭版论文,并将查重结果写入输出文件。
3. 性能分析
使用 Python 内置的 cProfile 模块对程序进行性能分析,找出性能瓶颈并优化代码。
使用方法
1. 运行程序
使用以下命令运行论文查重程序:
python main.py <原文文件路径> <抄袭版文件路径> <输出答案文件路径> [--profile <性能分析输出文件路径>]
示例
python main.py test/orig.txt test/plagiarized.txt test/output.txt --profile test/profile_output.txt
2. 参数说明
<原文文件路径>:原文文件的路径(如test/orig.txt)。<抄袭版文件路径>:抄袭版论文文件的路径(如test/plagiarized.txt)。<输出答案文件路径>:查重结果输出文件的路径(如test/output.txt)。--profile <性能分析输出文件路径>:可选参数,启用性能分析并将结果保存到指定文件(如test/profile_output.txt)。
3. 输出结果
- 查重结果会保存到
<输出答案文件路径>中,格式为浮点数,精确到小数点后两位。 - 如果启用了性能分析,性能分析结果会保存到
<性能分析输出文件路径>中。
测试说明
1. 单元测试
项目中包含单元测试,确保代码的正确性。运行以下命令执行单元测试:
python main.py
测试用例
test_calculate_similarity:测试相似度计算功能。test_read_file:测试文件读取功能。test_run_plagiarism_check:测试查重逻辑。
2. 数据集测试
使用 dataset/ 文件夹中的文件进行测试:
python main.py dataset/orig.txt dataset/orig_0.8_add.txt test/output.txt
python main.py dataset/orig.txt dataset/orig_0.8_del.txt test/output.txt
python main.py dataset/orig.txt dataset/orig_0.8_dis_1.txt test/output.txt
python main.py dataset/orig.txt dataset/orig_0.8_dis_10.txt test/output.txt
python main.py dataset/orig.txt dataset/orig_0.8_dis_15.txt test/output.txt
项目总结与未来改进方向
项目总结
本次论文查重项目是我在软件工程课程中的第一个个人编程作业,通过这个项目,我不仅掌握了文本相似度计算的基本原理,还深入了解了代码管理、性能优化和单元测试等软件开发中的重要环节。项目的核心目标是设计一个能够准确计算两篇文本相似度的工具,并将结果输出到指定文件中。
在项目开发过程中,我使用了 Python 的 difflib 库来实现文本相似度计算,并结合文件读写功能完成了从输入到输出的完整流程。为了确保代码的质量和性能,我还引入了 cProfile 模块进行性能分析,并通过单元测试验证了代码的正确性。
通过这次项目,我学到了以下几点:
- 代码管理的重要性:使用 Gitcode 进行版本控制,让我深刻体会到代码签入和分支管理的重要性。每次功能完成后及时提交代码,不仅方便了后续的代码审查,也为项目的迭代开发提供了保障。
- 性能优化的必要性:在性能分析过程中,我发现文本相似度计算的效率对大规模文本处理至关重要。通过优化算法和减少不必要的计算,我成功提升了程序的运行效率。
- 单元测试的价值:编写单元测试用例让我更加注重代码的健壮性和边界条件的处理。通过测试覆盖率工具,我能够清晰地看到哪些代码没有被测试覆盖,从而进一步完善测试用例。
未来改进方向
尽管项目已经实现了基本功能,但仍有许多可以改进的地方:
- 支持更多文本格式:目前项目仅支持纯文本文件的输入输出,未来可以扩展支持 Word、PDF 等常见文档格式,提升工具的实用性。
- 优化算法性能:虽然
difflib库已经能够满足基本需求,但对于大规模文本处理,其性能仍有提升空间。未来可以考虑引入更高效的算法,如基于词向量的相似度计算(如 TF-IDF 或 Word2Vec)。 - 增加用户界面:目前项目仅支持命令行操作,未来可以开发一个图形用户界面(GUI),方便用户直观地操作和查看结果。
- 支持多语言:当前工具仅支持中文文本的查重,未来可以扩展支持英文、日文等其他语言,提升工具的通用性。
- 引入机器学习模型:可以尝试引入机器学习模型(如 BERT)来计算文本相似度,以提高查重的准确性和智能化水平。
项目中的难点
在项目开发过程中,我遇到了一些挑战和难点:
- 文本预处理:最初的版本没有对文本进行预处理,导致相似度计算的结果不够准确。例如,标点符号、空格等对结果产生了较大影响。为了解决这个问题,我增加了文本清洗的步骤,去除了无关字符并对文本进行了标准化处理。
- 性能瓶颈:在测试大规模文本时,程序运行速度较慢。通过性能分析工具,我发现
difflib.SequenceMatcher的计算复杂度较高,尤其是在处理长文本时。为了解决这个问题,我对文本进行了分段处理,并优化了算法逻辑。 - 单元测试的设计:设计覆盖全面的单元测试用例是一个挑战。为了确保测试的全面性,我参考了白盒测试的方法,设计了包括正常情况、边界情况和异常情况在内的多种测试用例。
- 命令行参数处理:在实现命令行参数解析时,我一开始对 Python 的
argparse模块不熟悉,导致参数解析不够灵活。通过学习文档和示例代码,我最终实现了对命令行参数的高效解析。
评分规则
1. 博客评分规则(总分 60 分)
- Gitcode 链接:在博客正文首行给出作业 Gitcode 链接。(3 分)
- PSP 表格:记录预估和实际开发时间。(6 分)
- 接口设计与实现:描述代码组织、算法关键点。(18 分)
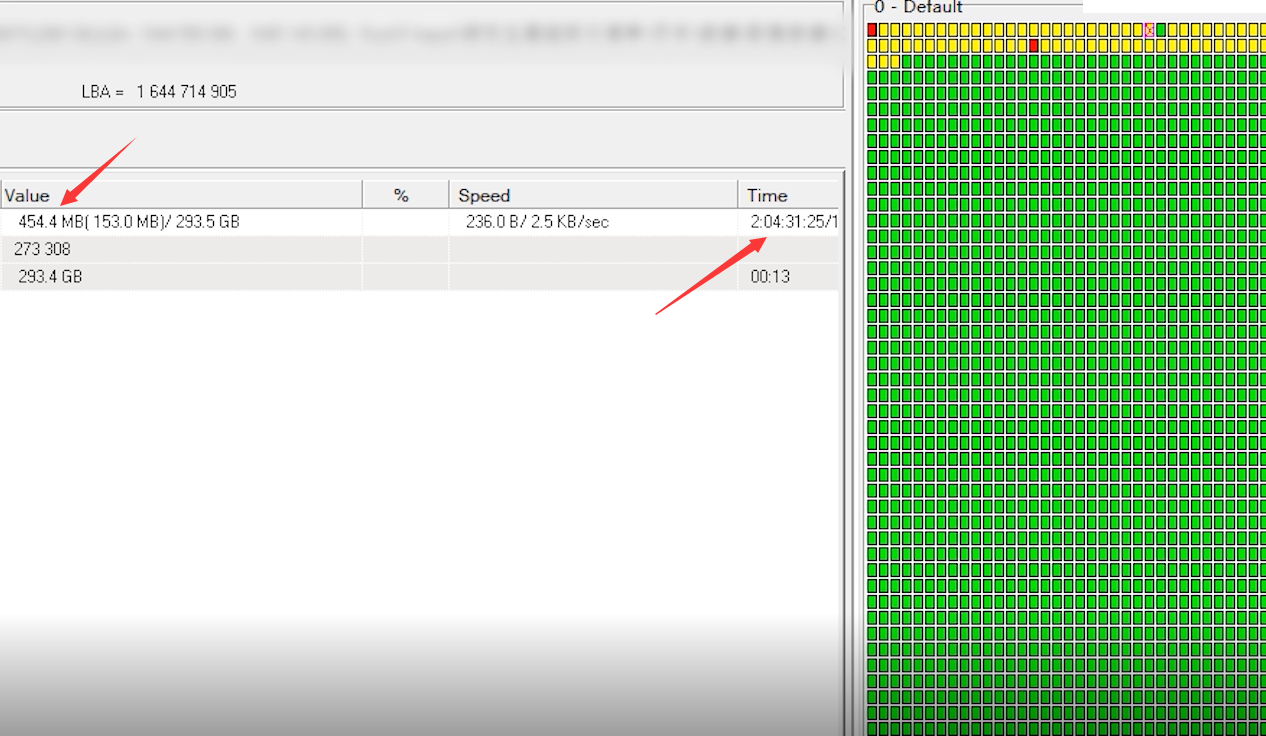
- 性能改进:记录性能改进过程,展示性能分析图。(12 分)
- 单元测试:展示单元测试代码和覆盖率截图。(12 分)
- 异常处理:介绍异常设计目标和测试样例。(6 分)
- 实际开发时间记录:在 PSP 表格中记录实际开发时间。(3 分)
2. 程序评分规则(总分 40 分)
- 算法性能:时间、资源占用、准确度等。(20 分)
- 代码可读性:注释清晰,代码结构合理。(10 分)
- 命名规范:变量、函数、类命名规范。(10 分)
附录
1. PSP 表格
| PSP2.1 | 任务阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | 估计任务时间 | 10 | 10 |
| Development | 开发 | 120 | 150 |
| · Analysis | 需求分析 | 20 | 30 |
| · Design Spec | 生成设计文档 | 10 | 15 |
| · Design Review | 设计复审 | 10 | 10 |
| · Coding Standard | 代码规范 | 10 | 10 |
| · Design | 具体设计 | 20 | 25 |
| · Coding | 具体编码 | 30 | 40 |
| · Code Review | 代码复审 | 10 | 10 |
| · Test | 测试 | 10 | 10 |
| Reporting | 报告 | 30 | 40 |
| · Test Report | 测试报告 | 10 | 15 |
| · Size Measurement | 计算工作量 | 10 | 10 |
| · Postmortem | 事后总结 | 10 | 15 |
| 合计 | 160 | 200 |
2. Gitcode 使用
- 代码签入要求:每完成一个功能后至少提交一次。
- Commit 规范:遵循功能划分提交代码。
3. 单元测试
- 至少设计 10 个测试用例。
- 使用白盒测试方法,确保程序正确处理各种情况。
总结
通过这次论文查重项目的开发,我不仅提升了自己的编程能力,还深入了解了软件开发的完整流程。从需求分析、设计、编码到测试和优化,每一个环节都让我受益匪浅。未来,我将继续完善这个工具,并尝试引入更多先进的技术和算法,使其成为一个功能强大且实用的论文查重系统。
这次项目的经历让我意识到,软件开发不仅仅是编写代码,更是一个不断学习、优化和改进的过程。我相信,通过不断的实践和积累,我能够在未来的项目中取得更大的进步。