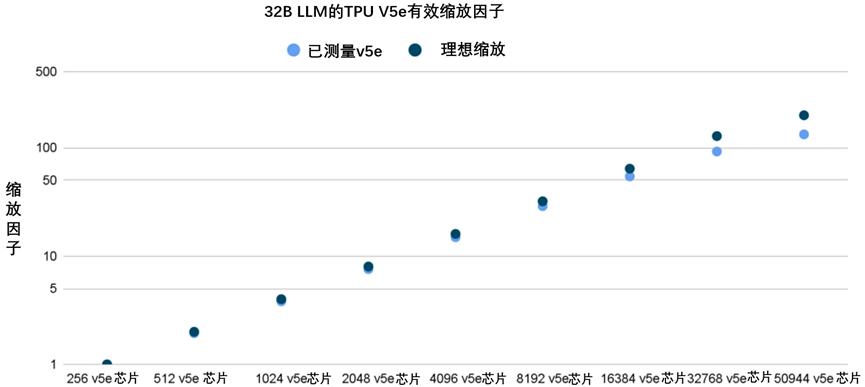
为什么要将式\((8.29)\)的循环计算去除变成式\((8.32)\)?直接对式\((8.29)\)进行递推计算不可以吗?
在循环神经网络(RNN)中,将式(8.29)的递归计算展开为式(8.32)的显式求和形式,主要有以下原因:
1. 揭示梯度传播的长期依赖问题
式(8.29)的递归形式为:
\[a_t = b_t + c_t a_{t-1},
\]
而展开后的式(8.32)为:
\[a_t = b_t + \sum_{i=1}^{t-1} \left( \prod_{j=i+1}^t c_j \right) b_i.
\]
通过显式展开,可以清晰地看到:
- 梯度是多个时间步的累积:每个 \(b_i\) 的贡献被乘以一系列 \(c_j\) 的连乘积(即 \(\prod_{j=i+1}^t c_j\))。
- 梯度消失/爆炸的根源:若 \(c_j\) 的值长期大于1(梯度爆炸)或小于1(梯度消失),连乘积会指数级放大或衰减。例如:
- 若所有 \(c_j = 0.9\),则 \(\prod_{j=1}^{10} c_j \approx 0.35\),梯度显著衰减。
- 若所有 \(c_j = 1.1\),则 \(\prod_{j=1}^{10} c_j \approx 2.59\),梯度急剧增长。
这种显式表达直接暴露了 RNN 难以处理长期依赖的本质问题,为后续改进模型(如 LSTM、GRU)提供了理论依据。
2. 避免递归计算的数值不稳定
直接对式(8.29)进行递推计算在理论上是可行的,但在实践中存在以下问题:
- 计算图的深度过大:反向传播时,梯度需沿时间步逐层传递。若时间步数 \(t\) 很大(如 \(t=1000\)),计算图的深度会导致内存占用和计算量激增。
- 数值不稳定性:递归计算会反复乘以 \(c_t\),数值误差可能累积(如浮点精度问题),导致梯度计算不准确。
3. 为优化算法提供分析基础
展开后的形式(式(8.32))能更直观地指导优化策略,例如:
- 梯度裁剪:显式连乘积可帮助识别梯度爆炸的临界点,从而合理裁剪梯度。
- 截断反向传播(Truncated BPTT):通过限制求和范围(如只考虑最近 \(k\) 个时间步),降低计算复杂度,同时缓解梯度消失/爆炸。
示例:梯度消失的直观分析
假设 \(c_j = \sigma < 1\)(如 Sigmoid 激活函数的导数),则:
\[\prod_{j=i+1}^t c_j = \sigma^{t-i}.
\]
当 \(t-i\) 较大时,\(\sigma^{t-i} \approx 0\),导致较早时间步(如 \(i \ll t\))的梯度贡献几乎为零。这种显式表达清晰地表明,RNN 难以捕捉远距离依赖关系。
总结
将递归形式展开为显式求和的主要目的是:
- 理论分析:明确梯度传播的数学性质,揭示长期依赖问题的根源。
- 工程优化:为设计稳定、高效的训练策略(如梯度裁剪、模型结构改进)提供依据。
- 数值稳定性:避免递归计算中潜在的误差累积和计算资源浪费。
直接递推计算虽在形式上简洁,但无法直观反映梯度传播的动态特性,也难以指导实际优化。因此,显式展开是分析 RNN 梯度问题的关键步骤。