数据库SQL中的GROUP BY子句1. 基本用法
基本语法如下: SELECT column1, column2, AGGREGATE_FUNCTION(column3)
FROM table_name
WHERE condition
GROUP BY column1, column2;
在这个语法中, 2. 作用
3. 示例假设你有一个名为 你可以使用以下SQL语句: SELECT salesperson, region, SUM(amount) AS total_sales
FROM sales
GROUP BY salesperson, region;
这个查询将返回每个销售人员在不同地区的总销售额。结果集中的每一行都代表一个销售人员-地区组合的总销售额。 4. 注意事项
对分组后的数据再进行过滤HAVING子句是SQL中用于对分组后的数据进行过滤的关键字。它基于分组后的结果集进行条件筛选,而不是原始数据。因此,HAVING子句通常与GROUP BY子句一起使用。 select deptno, avg(sal) as "平均工资" from emp group by deptno having avg(sal) >2000
连接查询:将两个表或两个以上的表以一定的连接条件连接起来,从中检索满足条件的数据
习题1:输出每个员工的姓名 部门编号 薪水 和薪水登记
习题2:查找每个部门的编号,该部门所有员工的平均工资,平均工资的等级
|
Python
|
学习笔记 -317


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/900448.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
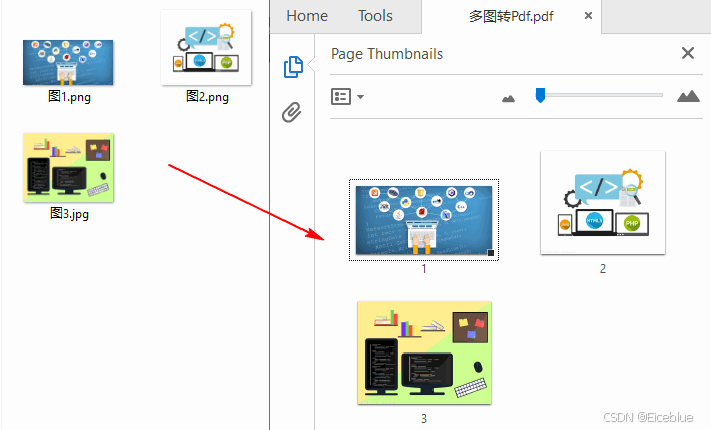
通过C#转换图片到PDF文档
将图片(JPG、PNG)转换为PDF文件可以帮助我们更好地保存和分享图片。此外,PDF文件还具有强大的安全特性,将图片转换为PDF后,我们可以通过设置密码来文件内容不被泄露。本文将介绍如何将JPG/PNG图片转换为PDF文档。C# 将单张图片转换为PDF文档
C# 将多张图片转换到一个PDF文…
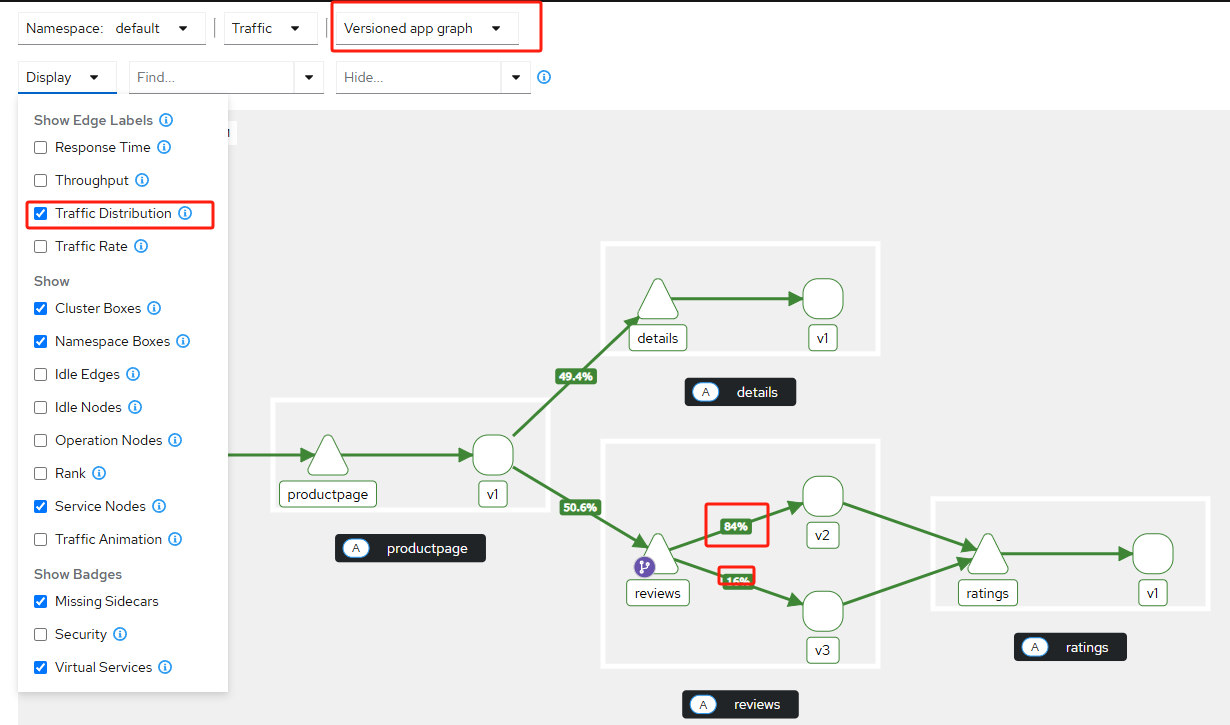
使用Istio灰度发布
目录灰度发布1. Istio1.1 Istio介绍1.2 Istio是如何工作的2. 安装Istio2.1 环境2.2 得到二进制文件2.3 安装istio3. 部署bookinfo模拟业务3.1 v1页面3.2 v2页面3.3 v3页面4. 模拟灰度发布4.1 业务版本v24.2 灰度发布到v3版本5. Kiali5.1 安装普罗米修斯5.2 修改svc类型
灰度发布…


LiveGBS国标GB28181国标平台分布式集群部署 以及多服务器动态负载均衡的技术方案在智慧工地、平安城市、智慧交通、智慧城市、交通枢纽、跨区域联网监控视频平台等大型视频流媒体项目如何实现
@目录1、大型容灾GB28181国标流媒体服务1.1、需求背景1.2、高可用分布式方案2、方案详解2.1、 百万路视频接入2.2、几百上千路高并发请求播放2.3、信令服务主备方式
1、大型容灾GB28181国标流媒体服务
1.1、需求背景
大型视频监控平台项目的常见需求高并发
高可用性
容灾备份
跨…

变量、常量及其初始化和命名规范
变量:public class HelloWorld250316 {
//实例变量 从属于对象,如果不自行初始化,这个类型的默认值 0 0.0 u000,布尔类型默认false
//除了基本类型,其余的默认值都是null
String name;
int age;
public static void main(String[] args) {
int a=10;
System.out.println(a…

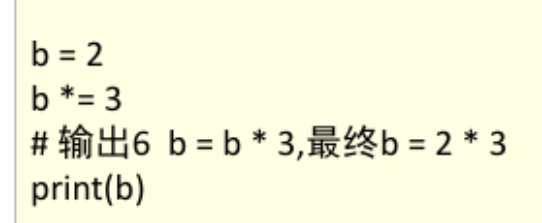
python运算注意点
1、整除// 9//2得出为4,被除数在前。
取余% 9%2得出1
2、round()函数,表示四舍五入,奇进偶不进 例:round(3.5)为4 round(6.5)为6
3、赋值 多变量赋值,直接用,隔开。
赋值加运算(先运算再赋值,也就是先乘2*3=6,直接赋值给b)4、逻辑运算符有一种优化机制,短…
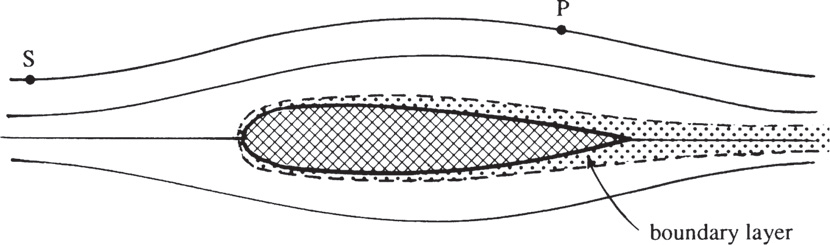
Bernoulli Equation
伯努利方程
伯努利方程并非一个独立的定律,而是在不同条件下由 Navier-Stokes 动量方程(式1)和能量方程(式2)推导而来的。
\[\rho\left(\frac{\partial u_{j}}{\partial t} + u_{i}\frac{\partial u_{j}}{\partial x_{i}}\right)=-\frac{\partial p}{\partial x_{j}}+\rho…

社区演讲-基于.NET 技术栈的研发过程管理和智能化探索
Hi all
2024年11月23日,我作为【项目管理实践探索者大会】专题讲师,给社区分享了主题《基于.NET 技术栈的研发过程管理和智能化探索》
现场参与人数:100+
演讲议题介绍:
体系建设:如何设计一个合适的研发过程管理体系
平台提效:通过.NET技术构建任务驱动+流程驱动,释放研…

halcon 深度学习教程(二)halcon基于深度学习的OCR检测
原文作者:aircraft
原文链接:https://www.cnblogs.com/DOMLX/p/18777081深度学习教程目录如下,还在继续更新完善中
深度学习系列教程目录 本篇非常简单,但是非常好用的OCR识别,传统的OCR识别方法一大堆各种各样的操作,麻烦的要死。halcon 22版本开始支持深度学习OCR,并且…
![[ SpringMVC ] SpringMVC如何通过是否有@RestController注解来判断返回ModelAndView还是Json](https://img2023.cnblogs.com/blog/3480200/202503/3480200-20250317153607367-1361004525.png)
[ SpringMVC ] SpringMVC如何通过是否有@RestController注解来判断返回ModelAndView还是Json
引言之前在面试的遇到面试官问我SpringMVC的执行流程,我那时候回答的是SpringMVC的DispatcherServlet的dodispatch方法找到ControllerMethod之后将返回值通过convert成Json返回响应体,事后想了一下回答的其实并不正确,因为SpringMVC之前学习的时候有使用ModelAndView返回视图,我…

从HR+AI到AI+HR,企业人力资源AI进程已过半
一、人力资源管理智能化应势而上,核心价值受企业管理层肯定
过往各项研究表明,AI 已经被广泛应用于企业经营的各个环节中。根据易路于2023 年发布的《AI 在企业人力资源中的应用白皮书1.0》(以下简称《白皮书1.0》),我们可以明确感受到:AI 已不同程度应用于招聘管理、员工…