Transformer
结构分为几个部分embedding,encoder,decoder以及output
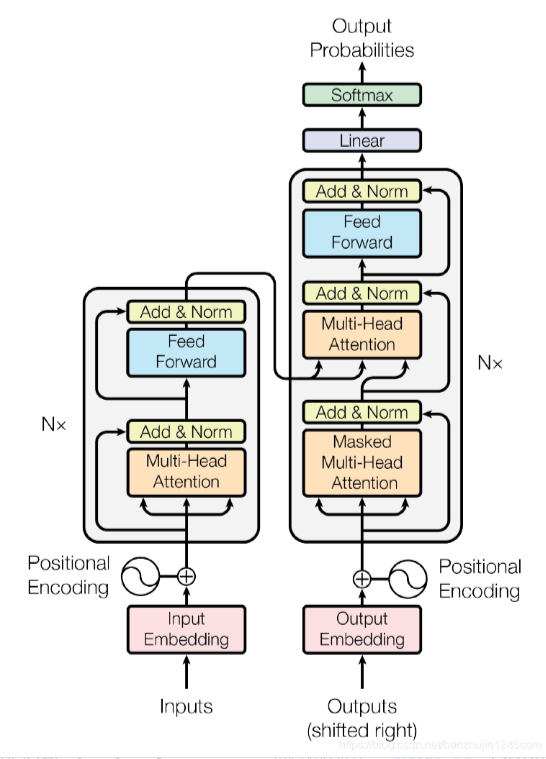
1.embedding block
作为对于模型输入的处理,首先将模型的输入进行向量化;
如输入为“我想要吃一个苹果。”-->X: [[0,0,0,1,2,222,....], [2,2,3,4,5,...], [3,4,5,6,....], []....];
接着经过positional encoder,因为 Transformer 没有循环结构(不像 RNN 有序列依赖),所以必须用位置编码(Positional Encoding)添加顺序信息;
公式一般如下:
PE(pos,2i)=sin(pos/100002i/d) / PE(pos,2i+1)=cos(pos/100002i/d)
将得到的PE和X直接相加得到能够送入encoder的带有位置信息的X;
2.encoder
2.1MHA多头注意力机制
在这里我们设置是三个可训练矩阵Wk,Wv,Wq,通过这三个矩阵分别将embedding block得到的X映射成K,Q,V三个向量。
接着利用下面公式:
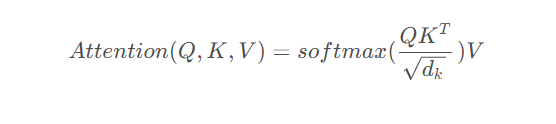
将当前需要处理的一个向量X 映射成了包含向量表内所有相关信息加权的新向量Z;
处理逻辑大概是,首先将每个query向量和key向量求点积,得到一个数值相似度(cosine similarity)也叫得分表,并除以sqrt(dk)[key的维度]使得梯度稳 定;随即将这个最终稳定的得分softmax归一化,计算出每个向量对于其他某一个向量的影响权重,最后利用这个权重分别与每个向量的value加权求和得 到最终的Z;
eg. "我吃苹果" 当处理"我"时,K我*Q我,K我*Q吃,K我*Q苹,K我*Q果 分别得到一个分数,再将分数归一化处理会得到0.82,0.11,0.01,0.06的权重。
接着有Z=0.82*V我+0.11*V吃+0.01苹+0.06*V果,Z为最终带有加权所有信息的向量。
而此处还有个问题就是为什么叫多头,多头则是将好几个上述的注意力模块。并行的处理得到z1,z2,z3...在用cat拼接后得得到一个大Z,并将Z重新通过
W矩阵压缩回原有维度,这是为了能让每一个头关注到不同的重点,比如有的关注词性有的关注频度..
2.2.add&norm
ADD是残差处理,原理是将 Z = X + Z;防止梯度爆炸和信息丢失;
norm是归一化让数值稳定更好收敛;
2.3.FFN
线性变换+relu+线性变换回原维度;使得模型增加非线性能力,能学习到更多特征。
H=max(0,XW+b); Y=HW'+b'
而模型加了两个ADD&NORM大概目的在于:

3.decoder
这里是一个自回归模型,将自己模型的输出作为下一步的输入的一部分。而decoder其中也有MHA并且是两个MHA,区别在于decoder的输入Y经过的第一个 MHA的是加mask以防止模型提前知道答案再回答问题。
如X="我吃苹果",当encoder给decoder部分的输出是"吃"的Z向量时,decoder此时只能够知道它此前的已经输出过的信息为"I"而后续的"eat apple"是模型不应 该知道的所以需要一个mask给这部分内容消掉。
而第二个MHA则是调用masked-MHA得到的Q向量以及encoder得到的KV,来实现将X的信息等待decoder来选择以调整关注点。
4.LinearLayer
最简单的将decoder的预测全连接再softmax计算概率;得到下一个token的概率分布;得到最终的概率分布后利用其他手段 如temperature采样或者干脆贪心选择概率最高的得到文本类型的输出。