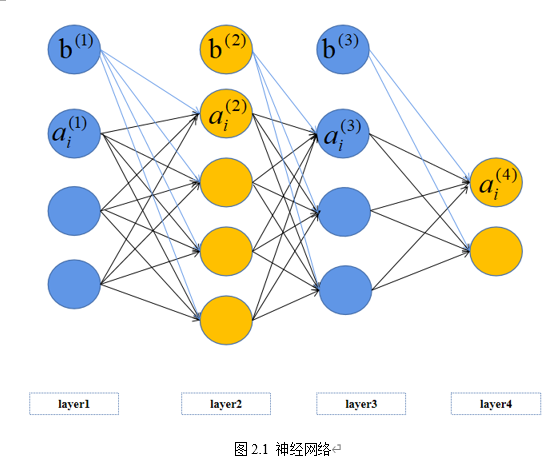
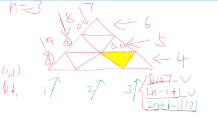
反向传播算法,简称BP算法,是多层神经元网络常用的学习算法之一,它建立在梯度下降算法的基础上。BP算法的完整学习过程由正向传播过程和反向传播过程组成。反向传播的过程是利用梯度下降算法,最小化代价函数 的过程。假设使用如图2.1所示的神经网络,该网络有一个输出层、两个隐藏层和一个输入层。在网络的前向传播过程中,神经元的计算如公式(2-1)和公式(2-2)所示。
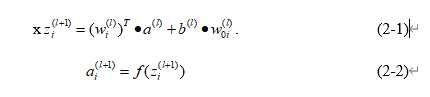
式中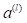 为来自神经网络第l层的输入,w为权重矩阵,b为第l层的偏置项,f为激活函数,这里选择sigmoid激活函数,z为在第 +1层第i个位置的输出。经过类似的多层神经网络,可以得到最终的输出 ,L指代网络的输出层。
为来自神经网络第l层的输入,w为权重矩阵,b为第l层的偏置项,f为激活函数,这里选择sigmoid激活函数,z为在第 +1层第i个位置的输出。经过类似的多层神经网络,可以得到最终的输出 ,L指代网络的输出层。
接着需要计算样本实际值和输出值之间的误差,这里使用的损失函数为softmax损失函数,如公式(2-3)和公式(2-4)所示。
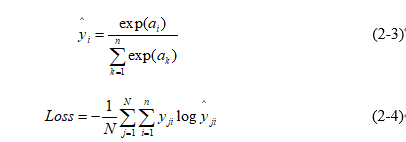
其中公式(2-3)为softmax激活函数,a为第i个输出值,N为训练时batch的大小,n为样本的类别数,a为输出值,y为真实值,一般而言log函数的底值为e。通过公式(2-3)和公式(2-4),可以计算出最终的代价J,并利用代价函数来优化权重参数。
反向传播的过程是利用梯度下降算法,使代价函数 最小或者达到预期值的过程。反向传播的过程需要计算损失 对各个神经元权重的偏导数,将这些偏导数作为代价函数对权重的梯度,并利用这些梯度来修改权重。首先我们需要计算J关于输出值a的偏导数,这个偏导数可以作为预测值和实际值的误差δ。求导过程可以分解为公式(2-5),其中f为softmax函数,a为输出值,y为真实值。
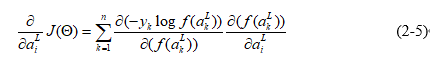
计算softmax函数关于 的偏导数,需要分开讨论。
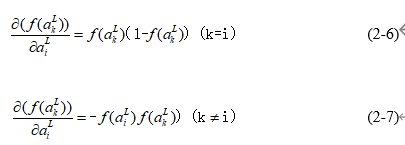
当k=i时,偏导数结果如公式(2-6)所示;当k≠ i时,偏导数结果如公式(2-7)所示。最终偏导数的结果为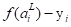 ,记为
,记为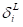 ,即第i个输出值与实际值的误差。接着我们可以通过链式求导法则逐层推导神经网络的偏导数。求代价函数关于a的偏导数的公式如(2-8)所示。
,即第i个输出值与实际值的误差。接着我们可以通过链式求导法则逐层推导神经网络的偏导数。求代价函数关于a的偏导数的公式如(2-8)所示。
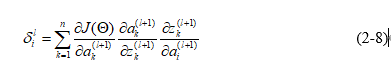
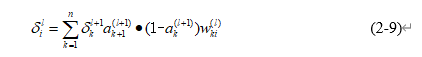
其中,偏导数第一部分求出,即关于第(l+1)层元素的偏导数。偏导数的第二部分为sigmoid函数关于z的偏导数,如果第(l+1)层没有使用激活函数,则该部分可以舍去,sigmoid函数关于z的偏导数计算公式为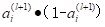 ,a为第(l+1)层的输出。第三部分记为对应的权重参数。进而可以得到公式(2-9)。
,a为第(l+1)层的输出。第三部分记为对应的权重参数。进而可以得到公式(2-9)。
像这样,我们可以求出代价函数关于所有层元素的偏导数。使用同样的方法,可以求出关于权重的偏导数,如公式(2-10)所示。
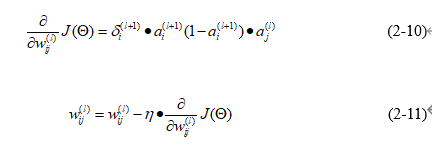
为第(l+1)层第i个输出值 和第(l)层第j个输出值a之间的权重,最后可以使用求得的偏导数更新权重,如公式(2-11)所示,其中n为学习率。