Groq软件定义的横向扩展张量流多处理器-从芯片到系统架构概述
1.大纲
1)张量流处理器(TSP)背景
2)软件定义的硬件和确定性执行
3)TSP微架构
4)系统封装、拓扑、路由和流控制
5)小结
2.软件定义方法
1)软硬件协同设计并不是什么新鲜事
2)重新检查硬件软件接口
① 静态-动态接口:在编译时(静态)与执行时(动态)的执行操作。此接口由运行时层管理。
② 硬件-软件接口:编译器可见的架构状态,以便能够推理正确性并提供可预测的性能。
3)计算图中的节点表示运算符,边是操作数和结果。
① 运算符仅在所有输入操作数都可用时才开始启动。
4)机器学习模型非常适合这种静态分析和确定性执行。
软硬件协同、接口框架,如图9-9所示。
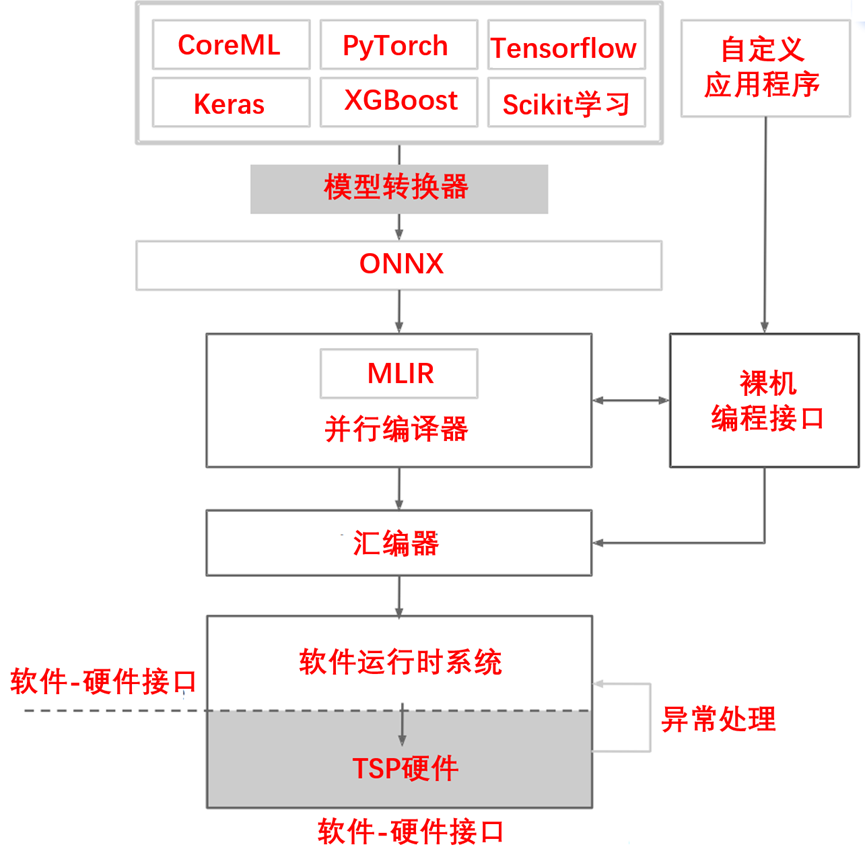
图9-9 软硬件协同、接口框架
3.设计决策
1)将硬件构建为高效的编译器目标。
2)整个设计选择需要适应确定性的设计理念。
3)硬件必须使用编译器和运行时接口,促进推理程序的执行。
① 必须很好地理解内存一致性模型——不允许对内存引用重新排序。
② 没有仲裁者、交叉杆、重放机制、缓存等反应性组件。
③ 软件必须能够访问系统可见的机器状态,以便用其上执行的指令拦截数据(操作数)。
4)编译器能识别片上每个张量的确切位置。
5)编译器同步布局操作数的到达和使用指令。生产者-消费者流编程模型,可用一组流寄存器文件来跟踪芯片的每个张量的状态。
4.避免芯片级别的复杂性
1)传统CPU增加了功能和复杂性。
2)需要动态分析来了解深度学习模型的执行时间和吞吐量特征。
3)推理预测性执行和无序退役,以提高指令级并行性——增加尾部延迟。
4)通过缓存层次结构的隐式数据流,引入了复杂性和不确定性。
① 例如,DRAM→L3→L2→L1→GPR,以隐藏DRAM访问延迟和压力,而不是能量或硅片效率。
5)TSP通过流编程简化数据流,可大规模预测性能。
6)大型单层SRAM缓存与确定性延迟。
7)在空间和时间上明确分配张量,解锁海量内存并发性,并在多个维度上实现计算灵活性:
① 设备、半球、内存片、存储体、地址偏移。
5. 避免系统级别的复杂性
1)仓储级计算机(WSC)和超级计算机。
①扩展到20K+节点。
②异构(SmartNIC、CPU、GPU、FPGA)。
③延迟差异限制了应用程序的规模。
④与网络直径有关。
⑤全局自适应路由很复杂(乱序消息、故障、热点、路由/负载不平衡、拥塞)。
2)软件定义的网络。
①编译器控制Groq C2C网络中的传输模式。
②片上自适应路由,以减少延迟方差并降低缓冲区占用率。
3)扩展到现有拓扑,没有陷阱。
①高基数交换机,以增加每个节点/交换机上的引脚带宽。
②低直径网络拓扑结构(例如,Dragonfly、扁平Butterfly、HyperX)。
数据包延迟分布,如图9-10所示。
1K节点网络中中间级交换机的最大缓冲入口,如图9-11所示。
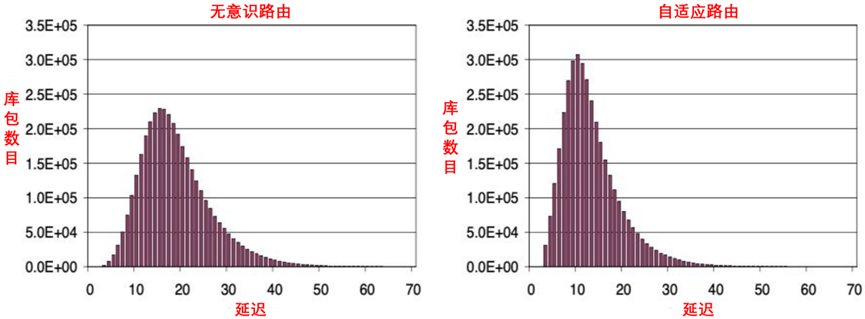
图9-10数据包延迟分布
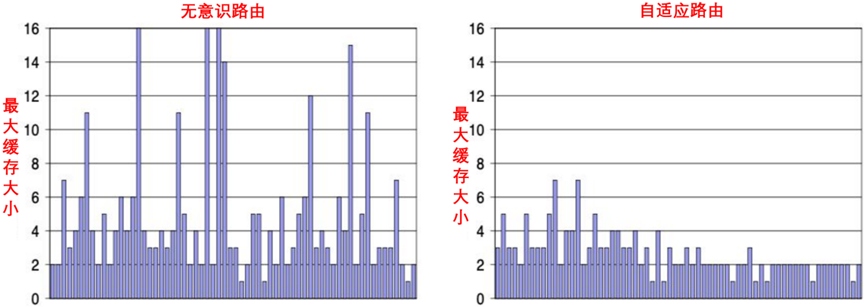
图9-11 1K节点网络中中间级交换机的最大缓冲入口