Action-Value Functions 动作价值函数
折扣回报(Discounted Return)
折扣回报 Ut 是从时间步 t 开始的累积奖励,公式为: 
-
Rt 是在时间步 t 获得的奖励。
-
γ 是折扣因子(0<γ<1),用于减少未来奖励的权重。这是因为未来的奖励通常不如当前奖励重要,例如在金融领域,未来的收益通常会因为通货膨胀等因素而贬值。
动作价值函数 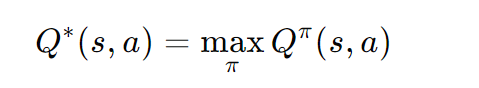
这个函数表示在所有可能的策略中,从状态 s 开始并采取动作 a 的最大预期折扣回报。它是强化学习的目标,即找到最优的 Q 函数。
深度Q网络(Deep Q-Network, DQN)
DQN是一种使用深度学习来近似 Q∗(s,a) 的方法。它的核心思想是通过神经网络来学习 Q 函数,从而能够处理复杂的、高维的状态空间(例如图像)。
- 神经网络结构:
- 输入:状态 s(例如游戏的屏幕截图)。
- 输出:每个动作 a 的 Q 值。
- 网络结构:
- 卷积层(Convolutional Layer):用于处理图像输入,提取图像的特征。
- 全连接层(Dense Layer):用于计算每个动作的 Q 值。
- 输出层:输出每个动作的 Q 值,例如:
- Q(s,"left";θ)=2000
- Q(s,"right";θ)=1000
- Q(s,"up";θ)=3000
- 选择动作: 在给定状态 s 下,选择 Q 值最高的动作:

这个动作被认为是最优的,因为它对应于最高的预期折扣回报。
时序差分学习(Temporal Difference, TD Learning)---用于训练DQN
TD学习是一种用于更新 Q 函数的方法,它通过逐步更新 Q 值来逼近 Q∗(s,a)。TD学习的核心思想是利用当前的 Q 值和新的奖励信息来更新旧的 Q 值。
-
TD目标(TD Target):
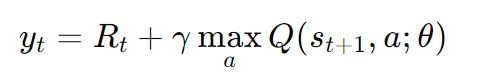
这个目标值是当前奖励 Rt 加上下一个状态 st+1 的最大 Q 值的折扣。它表示了从当前状态 st 开始并采取动作 at 的预期折扣回报。
-
TD误差(TD Error):

TD误差是当前 Q 值与TD目标之间的差异。如果 Q 值过高,则误差为正;如果 Q 值过低,则误差为负。
-
更新 Q 值:

其中,α 是学习率。这个更新规则通过减少TD误差来逐步调整 Q 值,使其更接近 Q∗(s,a)。
DQN的应用

DQN在许多游戏中表现出色,例如Breakout。以下是DQN在游戏中的应用步骤:
- 观察状态 st:获取当前状态,例如游戏的屏幕截图。
- 选择动作 at:根据 Q(st,a;θ) 选择 Q 值最高的动作。
- 执行动作:在环境中执行动作 at,获得新的状态 st+1 和奖励 Rt。
- 计算TD目标:根据新的状态和奖励计算TD目标 yt。
- 更新网络参数:根据TD误差更新 Q 网络的参数 θ。
详细解释
为了更好地理解TD学习,我们可以通过一个具体的例子来说明。假设你正在玩一个游戏,目标是从纽约开车到亚特兰大。你使用一个模型 Q(w) 来估计从纽约到亚特兰大的时间成本,模型的估计值为1000分钟。
-
第一步:你从纽约出发,模型预测从纽约到亚特兰大的时间为1000分钟。
-
第二步:你到达华盛顿特区(DC),实际花费了300分钟。此时,你获得了新的信息:从纽约到DC的实际时间为300分钟。
-
第三步:你更新模型的估计值。假设从DC到亚特兰大的估计时间为600分钟,那么从纽约到亚特兰大的新估计值为:
300+600=900分钟
这个新估计值900分钟比原来的1000分钟更接近真实值。
-
第四步:你计算TD误差:
δ=1000−900=100
这个误差表示模型的预测值比实际值高了100分钟。
-
第五步:你根据TD误差更新模型的参数 w,使模型的预测更准确。
通过这种方式,TD学习可以在不需要完整轨迹的情况下逐步更新 Q 函数,从而提高学习效率。