ResNet-152 模型在渴望模式下的性能评估
为了预热 GPU,在进行 20 次额外迭代以获取模型的平均推理时间之前,先运行 ResNet-152 模型 10 次。
n_warmup = 10
n_test = 20
dtype = torch.bfloat16
inference_time=[]
mode=[]
t_warmup, _ = timed(lambda:model(input_batch), n_warmup, dtype)
t_test, output = timed(lambda:model(input_batch), n_test, dtype)
print(f"平均推理时间resnet152(warmup): dt_test={t_warmup} ms")
print(f"平均推理时间resnet152(test): dt_test={t_test} ms")
print_topk_labels(output, 5)
inference_time.append(t_test)
mode.append("eager")
输出:
resnet152的平均推理时间(warmup): dt_test=164.6312952041626 ms
resnet152的平均推理时间 (test): dt_test=18.761909008026123 ms
Samoyed 0.80078125
Pomeranian 0.0791015625
white wolf 0.037353515625
keeshond 0.0257568359375
Arctic fox 0.022705078125
5.1.3 ResNet-152 模型在 torch.compile(default) 模式下的性能评估
要将 torch.compile 应用于 ResNet-152,可以按照下面的代码进行封装。
1)mode:使用 default 编译模式,这是性能和开销之间的良好平衡。
2)fullgraph:如果为 True,torch.compile()要求整个函数都能捕获到一个单一的图中。如果这不可能,则会引发错误。
#使用torch._dynamo.reset()清理工作区
torch._dynamo.reset()
model_opt1 = torch.compile(model, fullgraph=True)
t_compilation, _ = timed(lambda:model_opt1(input_batch), 1, dtype)
t_warmup, _ = timed(lambda:model_opt1(input_batch), n_warmup, dtype)
t_test, output = timed(lambda:model_opt1(input_batch), n_test, dtype)
print(f"编译时间: dt_compilation={t_compilation} ms")
print(f"平均推理时间compiled resnet152(warmup): dt_test={t_warmup} ms")
print(f"平均推理时间compiled resnet152(test): dt_test={t_test} ms")
print_topk_labels(output, 5)
inference_time.append(t_test)
mode.append("default")
输出:
编译时间: dt_compilation=24626.18637084961 ms
编译的平均推理时间resnet152(warmup): dt_test=15.319490432739258 ms
编译的平均推理时间resnet152(test): dt_test=15.275216102600098 ms
Samoyed 0.80078125
Pomeranian 0.0791015625
white wolf 0.037353515625
keeshond 0.0257568359375
Arctic fox 0.022705078125
ResNet-152 模型在 torch.compile(reduce-overhead)模式下的性能评估
reduce-overhead 模式利用 CUDA图表来减少内核启动的开销,改善整体延迟。
torch._dynamo.reset()
model_opt2 = torch.compile(model, mode="reduce-overhead", fullgraph=True)
t_compilation, _ = timed(lambda:model_opt2(input_batch), 1, dtype)
t_warmup, _ = timed(lambda:model_opt2(input_batch), n_warmup, dtype)
t_test, output = timed(lambda:model_opt2(input_batch), n_test, dtype)
print(f"编译时间: dt_compilation={t_compilation} ms")
print(f"平均推理编译时间resnet152(warmup): dt_test={t_warmup} ms")
print(f"平均推理编译时间resnet152(test): dt_test={t_test} ms")
print_topk_labels(output, 5)
inference_time.append(t_test)
mode.append("reduce-overhead")
输出:
编译时间: dt_compilation=18916.11909866333 ms
编译的平均推理时间resnet152(warmup): dt_test=39.9461030960083 ms
编译的平均推理时间resnet152(test): dt_test=5.042397975921631 ms
Samoyed 0.80078125
Pomeranian 0.0791015625
white wolf 0.037353515625
keeshond 0.0257568359375
Arctic fox 0.022705078125
5.1.4 ResNet-152模型在torch.compile(最大自动调谐)模式下的性能评估
最大自动调谐模式利用基于Triton的矩阵乘法和卷积运算。它默认启用CUDA图。
torch._dynamo.reset()
model_opt3 = torch.compile(model, mode="最大自动调谐", fullgraph=True)
t_compilation, _ = timed(lambda:model_opt3(input_batch), 1, dtype)
t_warmup, _ = timed(lambda:model_opt3(input_batch), n_warmup, dtype)
t_test, output = timed(lambda:model_opt3(input_batch), n_test, dtype)
print(f"编译时间: dt_compilation={t_compilation} ms")
print(f"编译的平均推理时间resnet152(warmup): dt_test={t_warmup} ms")
print(f"编译的平均推理时间resnet152(test): dt_test={t_test} ms")
print_topk_labels(output, 5)
inference_time.append(t_test)
mode.append("最大自动调谐")
输出:
AUTOTUNE convolution(1x64x56x56, 256x64x1x1)
triton_convolution_49 0.0238 ms 100.0%
triton_convolution_48 0.0240 ms 99.3%
convolution 0.0242 ms 98.7%
triton_convolution_46 0.0325 ms 73.4%
triton_convolution_52 0.0326 ms 73.0%
triton_convolution_53 0.0331 ms 72.0%
triton_convolution_47 0.0333 ms 71.6%
triton_convolution_50 0.0334 ms 71.3%
triton_convolution_51 0.0341 ms 70.0%
triton_convolution_42 0.0360 ms 66.2%
SingleProcess AUTOTUNE takes 64.3134 seconds
...
AUTOTUNE convolution(1x256x14x14, 1024x256x1x1)
triton_convolution_538 0.0285 ms 100.0%
triton_convolution_539 0.0290 ms 98.3%
convolution 0.0299 ms 95.2%
triton_convolution_536 0.0398 ms 71.5%
triton_convolution_542 0.0400 ms 71.2%
triton_convolution_543 0.0406 ms 70.1%
triton_convolution_537 0.0411 ms 69.3%
triton_convolution_540 0.0443 ms 64.3%
triton_convolution_541 0.0464 ms 61.4%
triton_convolution_532 0.0494 ms 57.6%
SingleProcess AUTOTUNE takes 15.0623 seconds
...
AUTOTUNE addmm(1x1000, 1x2048, 2048x1000)
bias_addmm 0.0240 ms 100.0%
addmm 0.0240 ms 100.0%
triton_mm_2176 0.0669 ms 35.9%
triton_mm_2177 0.0669 ms 35.9%
triton_mm_2174 0.0789 ms 30.4%
triton_mm_2175 0.0789 ms 30.4%
triton_mm_2180 0.0878 ms 27.3%
SingleProcess AUTOTUNE takes 8.4102 seconds
编译时间: dt_compilation=820945.9936618805 ms
编译的平均推理时间resnet152(warmup): dt_test=41.12842082977295 ms
编译的平均推理时间resnet152(test): dt_test=5.32916784286499 ms
Samoyed 0.796875
Pomeranian 0.083984375
white wolf 0.037353515625
keeshond 0.025634765625
Arctic fox 0.0225830078125
可以看到Triton正在自主优化矩阵乘法和卷积操作。相比于其他模式,这个过程需要极长的时间。可以在这里将编译时间与之前测试的模式进行比较。
虽然使用了Triton调优,但在这种情况下,最大自动调谐模式并没有显著增强性能,和 reduce-overhead模式相比没有明显优势。表明在测试平台上,ResNet-152的瓶颈并不主要在于矩阵乘法或卷积操作。
5.1.5 比较从上述四种模式获得的推理时间
import matplotlib.pyplot as plt
# 绘制条形图
plt.bar(mode, inference_time)
print(inference_time)
print(mode)
# 添加标签和标题
plt.xlabel('mode')
plt.ylabel('推理时间 (ms)')
plt.title('ResNet-152')
# 显示绘图
plt.show()
输出:
[18.761909008026123, 15.275216102600098, 5.042397975921631, 5.32916784286499]
['eager', 'default', 'reduce-overhead', '最大自动调谐']
如图5-2所示,torch.compile显著提升了ResNet-152在AMD MI210与ROCm上的性能,达到了*3.5*倍以上的提升。
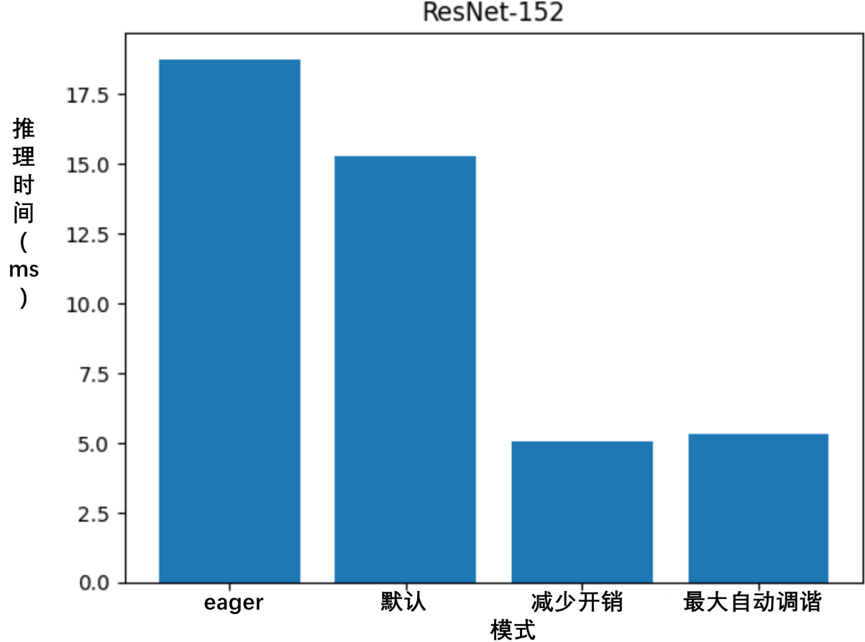
图5-2 torch.compile提升ResNet-152在AMD MI210与ROCm上的性能




![[AI/AIGC/GPT] 提示词工程1概述篇](https://blog-static.cnblogs.com/files/johnnyzen/cnblogs-qq-group-qrcode.gif?t=1679679148)