字符级语言模型的优缺点见下
好处:不用担心\(\left<\text{UNK}\right>\)的出现
坏处:最终的序列要长的多;训练也要复杂得多(对内存和速度的要求都要高得多)
现如今,人们一般使用单词级RNN,但是也有特殊情况会使用字符级RNN
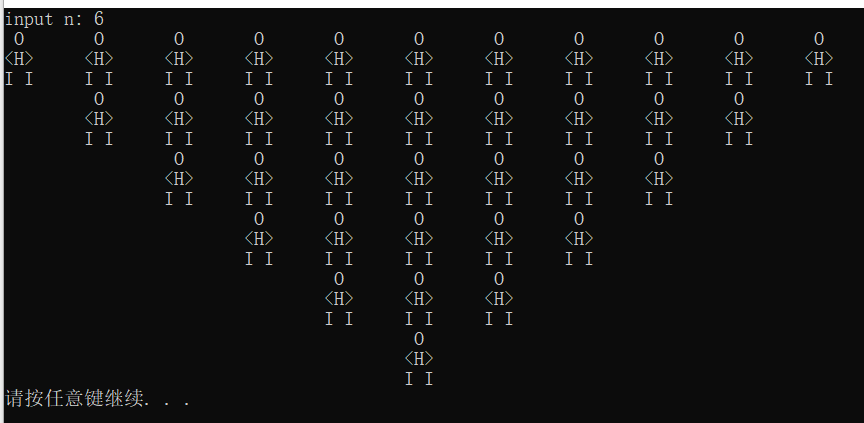
在训练了一个RNN后,我们可以利用这个RNN采样,去大概看一下他学会了些什么
采样步骤
- 选择第一个单词/字符作为第一个输入
- 对当前的输入,用RNN生成一个分步,再在这个分布里面随机采样一个单词/字符作为下一个输入(例如利用
numpy.random.choice),重复此步骤 - 如果\(\left<\text{EOS}\right>\)是词典中的一部分,那么当采样到结束标记时就可以停止采样了;否则,可以规定一个输出单词的数量,如\(20\)个或者\(100\)个什么的
注意,如果我们的词典中有\(\left<\text{UNK}\right>\),我们是有可能生成这个单词/字符的。一种解决方法就是拒绝这个标记,重新取样,或者不介意的话就不管
效果如下