RAG
前提准备:
- 配置ollama环境并下载模型
知识点总结:
- 解析PDF并提取文本,然后可以查询该存储的关键信息。
安装环境依赖
pypdf
faiss-gpu # GPU 环境下可以安装 faiss-cpu-1.10.0
langchain
langchain_community
tiktoken
langchain-openai
langchainhub
导入库
import os
import sys
sys.path.append(os.path.abspath(os.path.join(os.getcwd(), '..')))
# Add the parent directory to the path since we work with notebooks
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
PDF文本去噪
def replace_t_with_space(list_of_documents):for doc in list_of_documents:doc.page_content = doc.page_content.replace('\t', ' ') # Replace tabs with spacesreturn list_of_documents
embedding
from enum import Enum
# Enum class representing different embedding providers
class EmbeddingProvider(Enum):OPENAI = "openai"COHERE = "cohere"AMAZON_BEDROCK = "bedrock"OLLAMA = "ollama"
def get_langchain_embedding_provider(provider: EmbeddingProvider, model_id: str = None):if provider == EmbeddingProvider.OPENAI:from langchain_openai import OpenAIEmbeddingsreturn OpenAIEmbeddings()elif provider == EmbeddingProvider.COHERE:from langchain_cohere import CohereEmbeddingsreturn CohereEmbeddings()elif provider == EmbeddingProvider.OLLAMA:from langchain_community.embeddings import OllamaEmbeddingsreturn OllamaEmbeddings(base_url="http://127.0.0.1:11434", model="smartwang/bge-large-zh-v1.5-f32.gguf")elif provider == EmbeddingProvider.AMAZON_BEDROCK:from langchain_community.embeddings import BedrockEmbeddingsreturn BedrockEmbeddings(model_id=model_id) if model_id else BedrockEmbeddings(model_id="amazon.titan-embed-text-v2:0")else:raise ValueError(f"Unsupported embedding provider: {provider}")
PDF解析并构建知识库
from langchain_community.vectorstores import FAISS
def encode_pdf(path, chunk_size=1000, chunk_overlap=200):# Load PDF documentsloader = PyPDFLoader(path)documents = loader.load()# Split documents into chunkstext_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap, length_function=len)texts = text_splitter.split_documents(documents)cleaned_texts = replace_t_with_space(texts)# Create embeddings (Tested with OLLAMA、OpenAI and Amazon Bedrock)embeddings = get_langchain_embedding_provider(EmbeddingProvider.OLLAMA)#embeddings = get_langchain_embedding_provider(EmbeddingProvider.OPENAI)#embeddings = get_langchain_embedding_provider(EmbeddingProvider.AMAZON_BEDROCK)# Create vector storevectorstore = FAISS.from_documents(cleaned_texts, embeddings)return vectorstore
path = "data/rag.pdf"
chunks_vector_store = encode_pdf(path, chunk_size=1000, chunk_overlap=200)
Retriever构建
chunks_query_retriever = chunks_vector_store.as_retriever(search_kwargs={"k":2})
知识库检索
def retrieve_context_per_question(question, chunks_query_retriever):docs = chunks_query_retriever.get_relevant_documents(question)# Concatenate document content# context = " ".join(doc.page_content for doc in docs)context = [doc.page_content for doc in docs]return context
调用
test_query = "介绍一下OpenAI"
context = retrieve_context_per_question(test_query, chunks_query_retriever)
# 展示检索结果
def show_context(context):for i, c in enumerate(context):print(f"Context {i + 1}:")print(c)print("\n")
show_context(context)
LLMsProvider定义
from enum import Enum
# Enum class representing different LLMs providers
class LLMsProvider(Enum):OPENAI = "openai"OLLAMA = "ollama"
def get_langchain_llms_provider(provider: LLMsProvider, model_id: str = None):if provider == LLMsProvider.OPENAI:from langchain_openai import ChatOpenAIimport osfrom dotenv import load_dotenv# Load environment variables from a .env fileload_dotenv()# Set the OpenAI API key environment variable (comment out if not using OpenAI)if not os.getenv('OPENAI_API_KEY'):os.environ["OPENAI_API_KEY"] = input("Please enter your OpenAI API key: ")else:os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')return ChatOpenAI(temperature=0, model_name="gpt-4-turbo-preview")elif provider == LLMsProvider.OLLAMA:from langchain_openai import ChatOpenAIreturn ChatOpenAI(api_key="token",base_url="http://127.0.0.1:11434/v1",model="qwen2.5:1.5b")else:raise ValueError(f"Unsupported LLMs provider: {provider}")
LLMs回复
from langchain_core.pydantic_v1 import BaseModel, Field
class QuestionAnswerFromContext(BaseModel):answer_based_on_content:str = Field(description="Generates an answer to a query based on a given context.")
def create_question_answer_from_context_chain(llm):# Initialize the ChatOpenAI model with specific parametersquestion_answer_from_context_llm = llm# Define the prompt template for chain-of-thought reasoningquestion_answer_prompt_template = """For the question below, provide a concise but suffice answer based ONLY on the provided context:{context}Question{question}"""# Create a PromptTemplate object with the specified template and input variablesquestion_answer_from_context_prompt = PromptTemplate(template=question_answer_prompt_template,input_variables=["context", "question"],)# Create a chain by combining the prompt template and the language modelquestion_answer_from_context_cot_chain = question_answer_from_context_prompt | question_answer_from_context_llm.with_structured_output(QuestionAnswerFromContext)return question_answer_from_context_cot_chain
# 大模型回复函数定义
from langchain_core.prompts import PromptTemplate
def answer_question_from_context(question, context, question_answer_from_context_chain):input_data = {"question": question,"context": context}print("Answering the question from the retrieved context...")output = question_answer_from_context_chain.invoke(input_data)answer = output.answer_based_on_contentreturn {"answer": answer, "context": context, "question": question}
大模型回复
# Initialize LLM
llm = get_langchain_llms_provider(LLMsProvider.OLLAMA)
question_answer_from_context_chain = create_question_answer_from_context_chain(llm)
#Note - this currently works with OPENAI only
print(answer_question_from_context(test_query, context, question_answer_from_context_chain))
问题一:
未能正确配置ollama
总结:
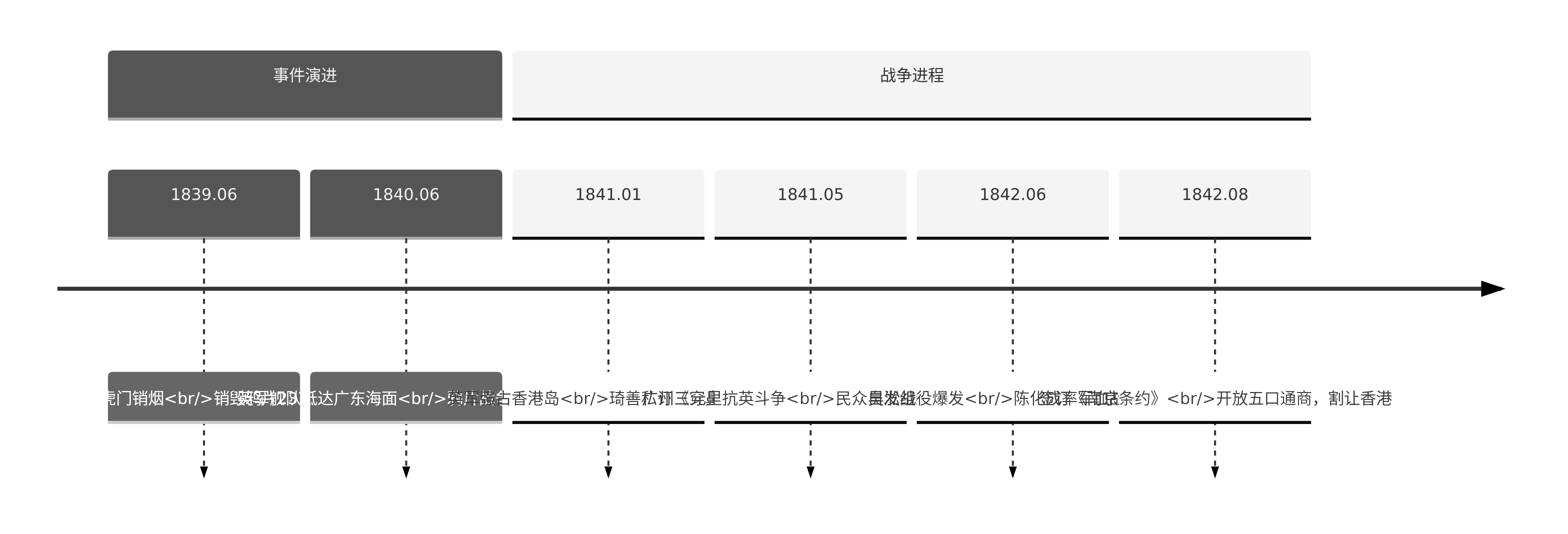
RAG通过检索外部知识源(如文档、数据库)并结合生成模型(如Transformer)来生成答案
RAG通过结合检索增强生成模块,显著提升了模型在知识密集型任务中的表现。
参考连接:https://articles.zsxq.com/id_xjev7q5fszae.html