在数据可视化的世界里,柱状图是一种直观且强大的工具,用于展示数据的分布、比较和趋势。
从基础的柱状图出发,我们可以进一步探索更复杂的图表类型,如分组柱状图和堆积柱状图,它们在处理多维数据和复杂关系时具有独特的优势。
本文将深入探讨如何使用Plotly库绘制这些高级柱状图,掌握这些技巧将使你在数据可视化领域更加得心应手。
1. 分组柱状图绘制
1.1. 柱状图数据结构
分组柱状图用于比较多个组之间的数据,每个组内又包含多个子组。
这种图表在分析不同类别之间的对比以及同一类别内部的细分对比时非常有用。
例如,比较不同地区的产品销量,同时展示每个地区的不同产品线的销售情况。
在数据结构设计上,需要将数据组织成适合分组柱状图的形式。
通常,这涉及到将每个组的数据存储在一个单独的列表或数组中,然后将这些列表组合成一个更大的数据结构,如字典或二维数组。
分组逻辑的关键在于如何在图表中区分不同组的数据,这通常通过颜色、位置或其他视觉属性来实现。
1.2. 代码示例
使用 Plotly 绘制分组柱状图的基本代码如下:
import plotly.express as px
import pandas as pd# 示例数据
data = pd.DataFrame({"季度": ["Q1", "Q2", "Q3", "Q4"],"产品A": [150, 180, 200, 160],"产品B": [120, 140, 170, 130],"产品C": [80, 90, 110, 100],}
)# 绘制分组柱状图
fig = px.bar(data,x="季度",y=["产品A", "产品B", "产品C"],barmode="group", # 关键参数:分组模式title="各季度产品线销量对比",
)
fig.show()
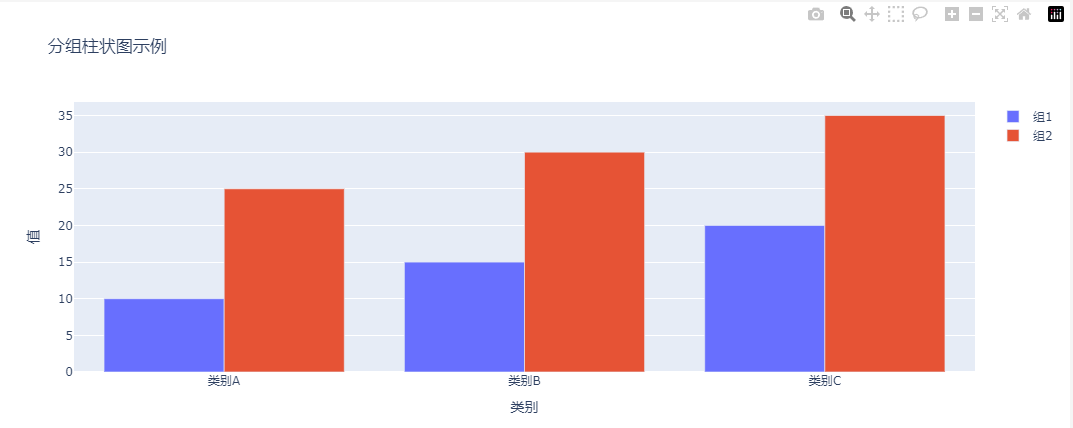
在上述代码中,barmode='group' 是实现分组效果的关键参数。
运行代码后,看到两个组的柱状图并排显示在每个类别下,清晰地展示了不同组之间的数据对比。
1.3. 颜色与图例
颜色在分组柱状图中起着至关重要的作用,它帮助我们快速区分不同组的数据。
通过自定义颜色方案,可以使图表更加美观和易读。
例如,可以使用不同的颜色代表不同的组,或者根据数据值的大小使用渐变颜色。
图例则是确保读者能够正确理解图表的关键。
我们需要确保图例清晰地展示每个组的名称和对应的颜色,避免混淆。
Plotly中可以通过设置 legend 参数来自定义图例的位置、标题等属性。
# 定义颜色
colors = ['rgb(31, 119, 180)', 'rgb(255, 127, 14)']# 创建分组柱状图
fig = go.Figure()
fig.add_trace(go.Bar(x=categories, y=group1, name='组1', marker_color=colors[0]))
fig.add_trace(go.Bar(x=categories, y=group2, name='组2', marker_color=colors[1]))# 设置布局
fig.update_layout(barmode='group',title='分组柱状图示例',xaxis_title='类别',yaxis_title='值',legend=dict(orientation="h",yanchor="bottom",y=1.02,xanchor="right",x=1)
)
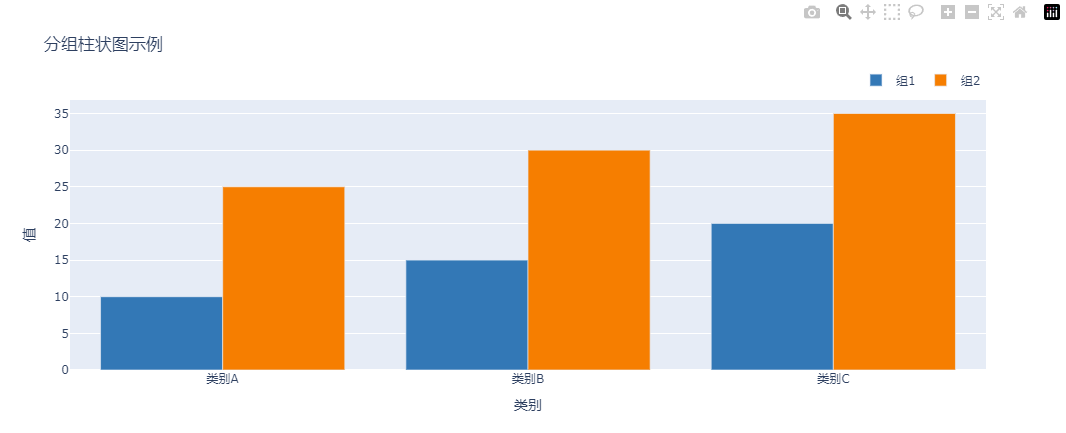
在上述代码中,我们通过以下方式增加了颜色和图例的变化:
- 颜色变化:
- 定义了一个颜色列表
colors,其中包含了两个自定义颜色。 - 在添加每个组的柱状图时,使用
marker_color参数为每个组指定了不同的颜色。
- 图例变化:
- 使用
legend参数来自定义图例的布局。 - 设置
orientation="h"将图例的方向改为水平。 - 调整了图例的位置,使其位于图表的底部右侧。
1.4. 其他技巧
为了增强分组柱状图的信息量,还可以添加数据标签,直接在柱状图上显示具体的数值。
这使得无需通过对比柱状图的高度来估算数值,提高了图表的可读性。
此外,自定义分组间距与柱状宽度可以进一步优化图表的布局,使其更加紧凑或分散,以适应不同的数据量和展示需求。
在处理数据缺失问题时,我们需要考虑如何在图表中优雅地展示缺失值,例如使用特殊的颜色或标记来表示。
group1 = [10, 15, 20]
group2 = [25, 30, 35]# 定义颜色
colors = ['rgb(31, 119, 180)', 'rgb(255, 127, 14)']# 创建分组柱状图
fig = go.Figure()
fig.add_trace(go.Bar(x=categories,y=group1,name='组1',marker_color=colors[0],text=group1, # 添加数据标签textposition='auto' # 设置标签位置为自动
))
fig.add_trace(go.Bar(x=categories,y=group2,name='组2',marker_color=colors[1],text=group2, # 添加数据标签textposition='auto' # 设置标签位置为自动
))# 设置布局
fig.update_layout(barmode='group',title='分组柱状图示例',xaxis_title='类别',yaxis_title='值',bargap=0.2, # 修改分组间距bargroupgap=0.1 # 修改组内柱状间距
)
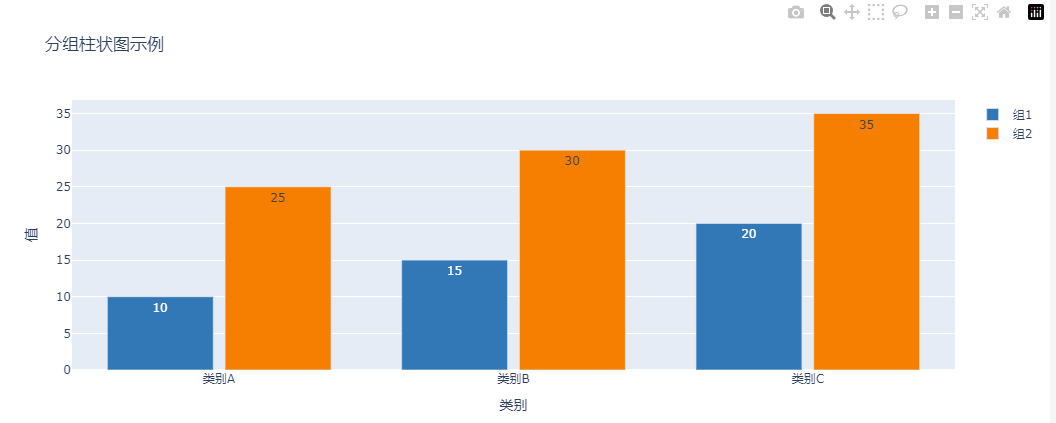
在上述代码中,我们进行了以下修改:
- 添加数据标签:
- 在每个
go.Bar中添加了text参数,将其设置为对应的数据值。 - 使用
textposition='auto'参数,使数据标签自动显示在柱子上方。
- 修改分组间距与柱状宽度:
- 使用
bargap=0.2参数修改了分组间距,值越小,分组之间的间距越小。 - 使用
bargroupgap=0.1参数修改了组内柱状间距,值越小,组内柱子越紧凑。
2. 堆积柱状图绘制
2.1. 数据结构
堆积柱状图将多个数据系列堆叠在同一个柱状图中,用于展示部分与整体的关系。
它适用于分析数据的构成比例和累计效果。
例如,展示不同产品的销售额占总销售额的比例,以及随着时间的推移这些比例的变化情况。
在数据结构设计上,堆积柱状图需要将每个数据系列的值按照类别进行累加,以便正确地堆叠在柱状图中。
堆积逻辑的核心在于如何计算每个数据系列在堆叠中的位置和高度,这通常通过累加前面所有系列的值来实现。
2.2. 代码示例
使用 Plotly 绘制普通堆积柱状图的基本代码如下:
import plotly.graph_objects as go# 示例数据
categories = ["类别A", "类别B", "类别C"]
series1 = [10, 15, 20]
series2 = [25, 30, 35]# 创建堆积柱状图
fig = go.Figure()
fig.add_trace(go.Bar(x=categories, y=series1, name="系列1"))
fig.add_trace(go.Bar(x=categories, y=series2, name="系列2"))# 设置布局
fig.update_layout(barmode="stack",title="普通堆积柱状图示例",xaxis_title="类别",yaxis_title="值",
)# 显示图表
fig.show()
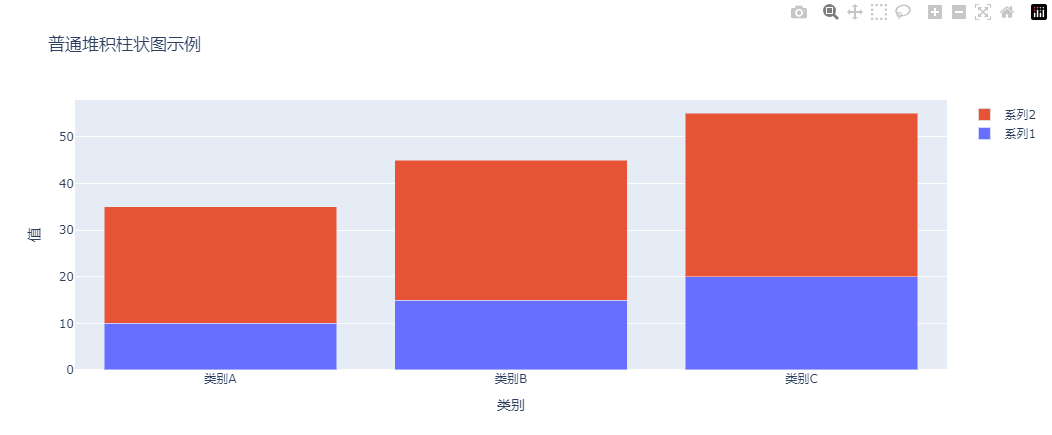
在代码中,barmode='stack' 是实现堆积效果的关键参数。
运行代码后,我们将看到两个数据系列堆叠在每个类别下的柱状图中,直观地展示了数据的累计效果。
2.3. 百分比堆积柱状图
百分比堆积柱状图是堆积柱状图的一种变体,它将每个柱状图的高度标准化为100%,用于更清晰地展示数据的构成比例。
通过将绝对值转换为百分比,我们可以更容易地比较不同类别中各数据系列的相对占比。
# 百分比堆积柱状图
import plotly.graph_objects as go# 示例数据
categories = ["类别A", "类别B", "类别C"]
series1 = [10, 15, 20]
series2 = [25, 30, 35]# 计算每个类别的总值
total = [s1 + s2 for s1, s2 in zip(series1, series2)]# 将数据转换为百分比
series1_percent = [(s1 / t) for s1, t in zip(series1, total)]
series2_percent = [(s2 / t) for s2, t in zip(series2, total)]# 创建百分比堆积柱状图
fig = go.Figure()
fig.add_trace(go.Bar(x=categories,y=series1_percent,name="系列1",text=[f"{p*100:.1f}%" for p in series1_percent], # 添加百分比标签textposition="inside", # 设置标签位置为柱子内部)
)
fig.add_trace(go.Bar(x=categories,y=series2_percent,name="系列2",text=[f"{p*100:.1f}%" for p in series2_percent], # 添加百分比标签textposition="inside", # 设置标签位置为柱子内部)
)# 设置布局
fig.update_layout(barmode="stack",title="百分比堆积柱状图示例",xaxis_title="类别",yaxis_title="百分比",yaxis=dict(tickformat=".0%"), # 设置y轴刻度格式为百分比legend=dict(orientation="h", yanchor="bottom", y=1.02, xanchor="right", x=1),
)# 显示图表
fig.show()
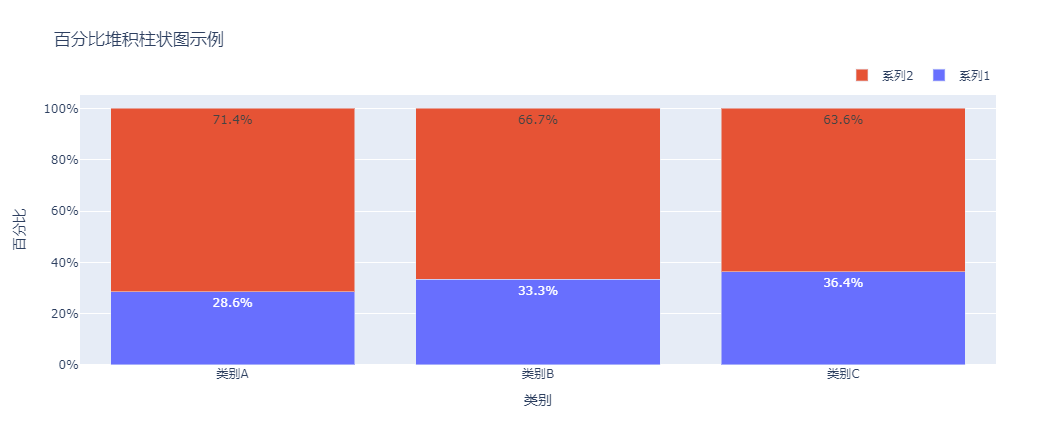
代码调整说明:
- 数据预处理:
- 计算了每个类别的总值。
- 将每个系列的数据转换为占其所在类别总值的百分比。
- 添加百分比标签:
- 在每个
go.Bar中添加了text参数,显示每个数据点的百分比。 - 使用
textposition='inside'将标签显示在柱子内部。
- 布局调整:
- 设置了
yaxis=dict(tickformat='.0%'),使y轴的刻度显示为整数百分比格式。
3. 分组与堆积柱状图的对比
分组柱状图和堆积柱状图在视觉效果和应用场景上存在显著差异。
分组柱状图更侧重于比较不同组之间的数据,强调组间的对比关系;
而堆积柱状图则更侧重于展示数据的构成和累计效果,强调部分与整体的关系。
在实际应用中,选择哪种图表类型取决于你的分析目标和数据特点。
如果需要比较不同类别之间的差异,分组柱状图可能是更好的选择;
如果需要分析数据的构成比例和累计趋势,堆积柱状图则更为合适。
4. 总结
本文主要介绍了分组柱状图和堆积柱状图的绘制技巧,理解它们在复杂数据分析中的应用场景和价值。
此外,在处理大数据量时,性能优化是必不可少的。
可以采用数据采样、简化图表元素等方法来提高绘图效率。
图表美化方面,通过调整布局、颜色和标签等元素,可以使图表更加专业和美观。