一、回顾💛
谈谈volatile关键字用法
volatile能够保证内存可见性,会强制从主内存中读取数据,此时如果其他线程修改被volatile修饰的变量,可以第一时间读取到最新的值。
二、💙
HashMap线程不安全没有锁,HashTable线程更加安全,关键方法都提供了synchronized,CocurrrentHashMap是线程安全的hash表
HashMap是在方法中直接加上synchronized,就相当于针对this(当前对象)加锁,
HashTable——全局锁,会安全,但是缺点就是有巨大的锁开销,会形成阻塞等待
HashTable<String,String>ht=......;
hs.set("aaa","111")
任意的针对ht对象的操作,都会涉及针对this的加锁,此时如果多个线程想操作ht,就一定会触发激烈的锁竞争,最后都只能一个一个排着队,依次执行——并发
所以会出现CocurrentHashMap
我们学过的哈希表的二次探测,真实hash表基本不会出现,而是采用链表的方式(哈希桶),如果修改操作是像下图这样,针对两个不同的链表进行修改,是否存在线程安全问题->当然不会
但是假如说是扩容,就可能会有影响了,但是扩容是很有重量级的操作,把整个的哈希表都需要重新搬运一遍,这样锁的开销也就微乎其微。
那么有人也会问-假如上面那种是不是说明这种我就完全不需要加锁了,反正也是没有线程安全问题,但是也不行,因为下图这种,假如说去插入两个在同一个链表的位置,又会涉及到线程的安全问题——解决方法每个链表都安排一把锁-这样开销就会小很多,这样第二个操作就会陷入阻塞等待,因为第一个正在修改,这样这个问题就解除了。
一个hash表上链表个数这么多,两个线程正好在同时修改一个链表的操作本身就概率比较低,整体锁的开销大大降低了,这么修改也就不会有这么多的线程阻塞。
此时可能此时有人问,该怎么给每个线程加锁呢——由于synchronized随意对象都可以加锁,所以可以简单使用每个链表的头节点使用。
这也就是我们的改进
1.ConcurrentHashMap减小了锁的粒度,每个链表有一把锁,大部分情况下都没有涉及锁冲突。
2.广泛使用了CAS操作,size++,这样的操作也不会存在锁冲突
3.写操作进行了加锁(链表级)读操作,不加锁了就——如果有一个线程读,一个线程写会有问题吗,最多就是修改的一瞬间,读到一个旧版本/新版本的数据,不确定而已,通过一些精密的操作,保证不会读“半个数据”(有新有旧)
4.针对扩容操作进行优化,渐进式扩容
HashTable一旦触发扩容,就会一口气完成所有元素的搬运,这个过程非常耗时间,我们的大部分请求会很顺畅,但是突然一个请求会卡很久——而且并不好确认哪里的问题,因为这个触发概率很小,很气。
所以这个改进——化整为零,当需要扩容时,创建一个更大的数据,然后把旧的数据逐渐往新的数据哈桑搬运,会出现一段时间——新,旧数组共同存在的时间——
1.新增数据,就往新数组上插入
2.删除数据,把旧的数组上的数据删除掉即可
3.查找元素,新旧数据都要查
4.修改元素,统一把这个元素放到新的数组上
与此同时,每个操作都会触发一定到搬运,每搬运一次,就可以保证整体时间不是很大,积少成多之后,逐渐完成搬运了,也就可以把之前的旧的数组销毁了
上面说的是HashTable和ConcurrentHashMap的区别
HashMap和ConcurrentHashMap的区别,就是线程安全和不安全的区别。
treeMap和hashMap区别——哈希表和红黑树之间的区别
面试有可能问一手
ConcurrentHashMap的分段锁
Java8之前,ConcurrentHashMap的分段锁区别
Java8之后就没有分段锁了
ConcurrentHashMap的分段锁确实可以提高效率,但是不如一个链表一把锁效率更高,而且分段锁的维护更加麻烦。



三、 💜
文件IO操作
文件->存储数据的方式
操作系统通过“文件系统”这样的模块来管理硬盘。
文件~不同的文件系统,管理文件的方式都是一致的
通过“目录”构成了N叉树的文件结构
如D盘->tmp->cat.jpg通过这个路线就可以找到确定电脑的唯一一个文件,这个路线就叫做路径。
以盘符开头的路径,也叫做绝对路径,绝对路径是从电脑这里出发找文件的过程。
以···或···开头的路径,叫做绝对路径,相对路径,需要有一个基准目录/工作目录,表示从这个基准目录出发怎么才能找到这个文件
如以D:为基准目录
.白哦是当前所在目录
./tmp/cat.jpg
以D:/tmp为基准
./cat.jpg
..表示当前目录的上一层目录
如果D:/tmp/111为基准(是以tmp开始查找)
../cat.jpg
D:/tmp/111/aaa为基准
../../cat.jpg(也是以tmp开始查找)
文件系统存储的文件具体分为两个大类:
1.文本文件
utf8就是一个大表(实际上)表上数据的集合叫做字符。
2.二进制文件
二进制数据
如何区分呢?
一个最简单的方式判断就是:文件是二进制还是文本,直接使用记事本打开,如果打开之后能看懂,就是文本文件,假如看不懂,就是二进制文件,记事本打开文件,就会尝试把当前数据在码表中查询~
word文档就是二进制文件(功能太多了,属于是“富文本”需要用二进制去组织),后续文本的操作,文本和二进制操作方式完全相同的
文件系统的操作——
1.创建文件
2.删除文件
3.创建目录
通过一个类的使用——java.io.File(IO-Input和output,站在cpu的角度,来看待输入输出。)
通过File对象描述一个具体的文件,File对象可对应一个真实的文件,也可对应一个不存在的文件。
File(String pathname)此处参数字符串表示一个路径,可以是绝对路径,也可以是相对路径

站在操作系统的角度来看,目录也是文件,操作系统中的文件是更为广义的概念,具体里面有很多种不同的类型
1.普通文件(通常见到的文件)
2.目录文件(通常见到的文件夹)<-(高级,文件夹太土鳖的)
1.File file=new File("./test.txt"); //路径随意填写(可以不存在)
2.file.createNewFile()//创建文件(有可能抛异常)
3.file.delete(删除掉文件)
file.deleteOnExit(),(这个是程序退出后再删除,不是立刻删除)有的时候,可能会有这样一个功能,临时文件程序运行的时候,搞一个临时文件,程序结束了,临时文件会自动进行删除。
像是office等生产力软件,都有生产临时文件功能,这个临时文件就自动存储了你当前的编辑状态,如果有人word长期不保存,突然断电关机,此时你在进行重启,由于刚才是非正常关闭,临时文件来不及删除是仍然存在的,office启动就能知道上次是异常关闭,就会提醒你是否要从之前的临时文件恢复未保存的结果。


创建一个目录,
import java.io.File;
import java.io.IOException;public class Demo11 {public static void main(String[] args) throws IOException {File file=new File("./d.txt");//创建文件// file.createNewFile();//删除掉文件// file.deleteOnExit();//创建一层目录mk->make,dir->directory//mkdir()一次只能创建一级目录file.mkdir();// mddirs能创建多极目录file.mkdirs();}
}

文件命名,也可以起到文件移动的效果
以上文件系统操作,都是基于File类完成的。
文件流stream-主要原因,操作系统流
文件内容的操作核心步骤,四个
1.打开文件 fopen
2.关闭文件 fclose
3.读文件 fread
4.写文件 fwrite
JavaIO流是庞大的体系,涉及非常多的类,不同的类有不同的特性,使用方法基本类似。
字节流:InputStream,OutputStream ,后续的一些操作字节的类都是衍生自这两个类,以操作字节为单位(二进制文件)
字符流: Reader Write 操作字符为单位(文本文件)
reader.close:让一个进程打开一个文件,是要从系统中一定的资源(占据进程pcb文件描述符中的一个表项)文件描述符是顺序表(长度有限,不可扩容),如果不释放,就会出现“文件资源泄露”这是很严重的问题,一旦一直打开文件,而不去关闭不用的文件,文件描述符就会被占用满(导致服务器宕机)后续无法打开新的文件)->年终奖消失大法
我们平时可以使用try catch finally {close}但是不够优雅
最好使用try with resources
//这个就如同sychronized一样,自动给你关闭文件,但是这块写的不完全,需要写使用资源的操作 try(Reader reader=new FileReader("d:/test.txt"))read()一次读一个字符<->char(按照Integer来表示,表示两个字符的范围,-1表示已经读取完毕eof了)
可能会有疑问——utf8格式一个字符三个字节,为什么读出字符是两个字节呢
java的char类型是用unicode编码的(一个字符,两个字节),使用完这个方法读取一个字符,java标准库内部会帮我们自动转换!unicode和utf8(一个字符)是不同的。
这个会把读到的内容,填充到参数cbuf是数组中,此处的参数,相当于一个“输出型参数”
char buf[]=new char[1024];
reader.read(buf)//这种写法java中不太常见(c++)使用偏多,通过read,就会把一个本来空的数组,填充上内容
read(char[]cbuf,int off,int len)
多个小文件,都需要读取且需要拼接到一起,就用这个方法,比如三个文件,大小都是100字节
read(cbuf,0,100) read(cbuf,100,100) read(cbuf,200,100)
我们如同下图那样,先读取txt文件,然后在去依次输出这个字符串,读到文件末尾退出


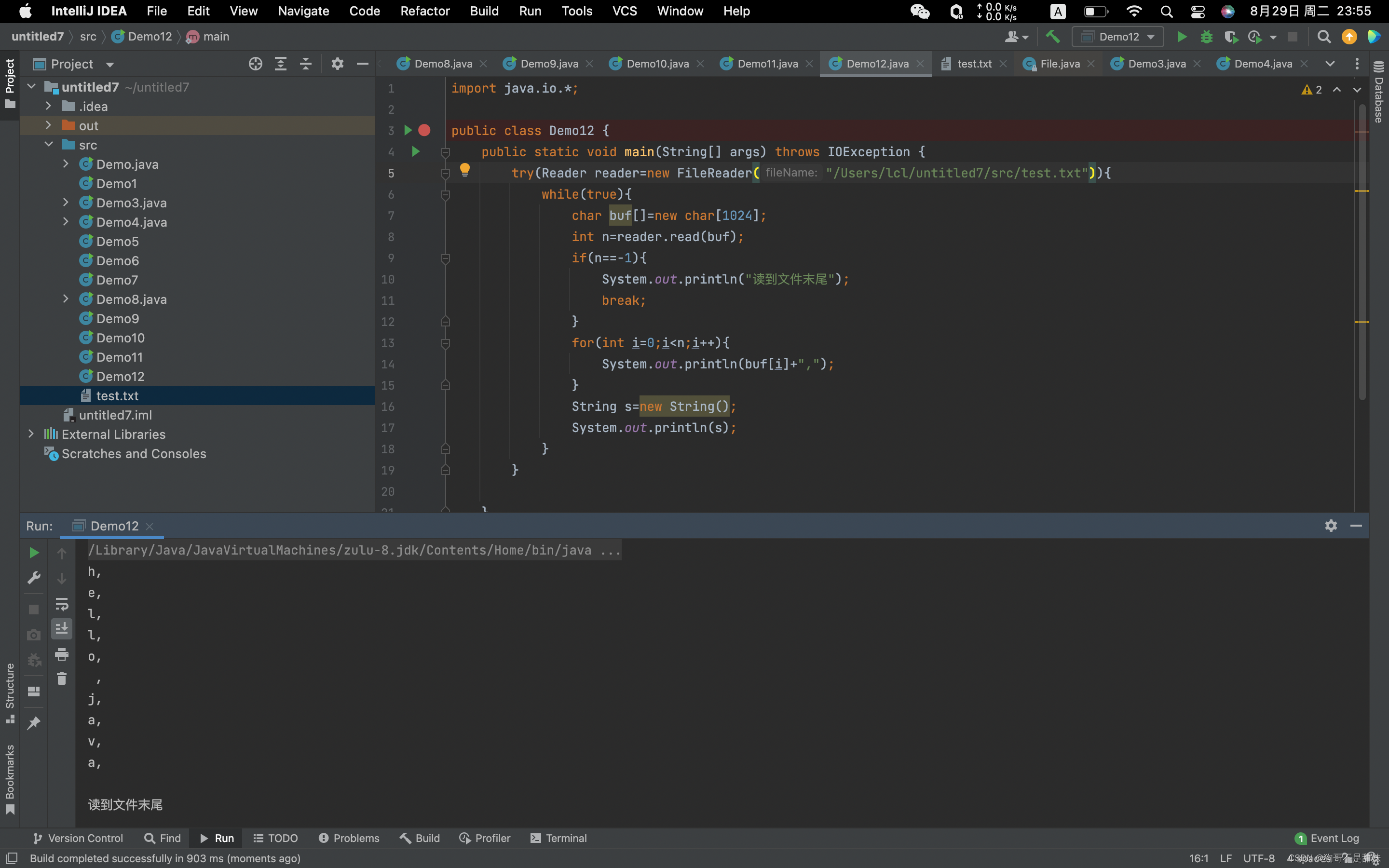
import java.io.*;public class Demo12 {public static void main(String[] args) throws IOException {try(Reader reader=new FileReader("/Users/lcl/untitled7/src/test.txt")){while(true){char buf[]=new char[1024];int n=reader.read(buf);if(n==-1){System.out.println("读到文件末尾");break;}for(int i=0;i<n;i++){System.out.println(buf[i]+",");}
//String构造方法内部,默认是utf8(但是你可以让他变成gbk
String s=new String(0,n,"gbk");String s=new String();System.out.println(s);}}}
}
read(byte[]b)->一次读若干字节,填满数组的一部分
Scanner一视同仁,只是把当前读到的字节数据进行转换~(不关心这个数据来自于标准输入,还是来自文件或者网卡)
以前学过的Scanner只是读文本文件的,不适合读二进制文件,在标准库中,还提供了一些具体工具类,辅助更方便的读写二进制文件。
import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; import java.util.Scanner;public class Demo13 {public static void main(String[] args) throws IOException {try(InputStream inputStream=new FileInputStream("/Users/lcl/untitled7/src/test.txt")){Scanner scanner=new Scanner(inputStream); //第一段到空格之前的字符串,读取test文件读取数据String s= scanner.next();;System.out.println(s);String s1= scanner.next();;System.out.println(s1); 第二段空格之前,相当于读取一个词String s2= scanner.next();;System.out.println(s2);}} }输出,使用方法和输入十分相似——
关键的操作是write,write之前要打开文件,用完需要关闭文件,输出流对象(无论字节流还是字符流)会打开文件之后,清空文件内容!正如我们之前那么写的i,变成了我喜欢你



但是我们假如想在他的后面去写,而不去自动删除,该怎么做呢,可以追加写,此时就不进行清空操作。OutputStream使用方式完全一样,只不过write方法不能支持“字符串参数”。,只能按照字节或者字节数组写入。

Scanner搭配InputStream可以简化代码效果(可以不像我们之前那么一点一点读)
PrintWriter(sout,点击里面的out,她就是这个类,使用一系列方法printf,println)搭配OutputStream
经典面试题,写个代码递归目录
深度优先-DFS(先中后序,递归)
广度优先-BFS(层序)
import java.io.File; import java.util.Scanner;public class Demo15 {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);System.out.println("请输入搜索的根目录");File rootPath = new File(scanner.next());System.out.println("请输入删除的关键词");String word = scanner.next();if (!rootPath.isDirectory()) {System.out.println("路径不合法");return;}scanDir(rootPath, word);scanner.close();}public static void scanDir(File currentDir, String word) {//先列出当前目录包含哪些内容File[] files = currentDir.listFiles();if (files == null || files.length == 0) {//空目录/非法目录return;}for (File f : files) {System.out.println(f.getAbsolutePath());if (f.isFile()) {//3看当前文件是普通文件,看文件名字,是否包含word,来决定是否删除dealFile(f, word);} else {//4假如是当前文件是目录文件(文件夹)就再次递归,直到找到文件。scanDir(f, word);}}}private static void dealFile(File f, String word) {//是根据文本的是名字删除,假如不存在就返回if (!f.getName().contains(word)) {return;}//打印删除文件的路径System.out.println("要删除的文件:" + f.getAbsolutePath());f.delete();} }2.进行普通文件的复制,把一个文件复制成另一个文件
在这之前我们先要想一个问题,读文件一次读1024好,还是20480好?
每次read都是访问硬盘,此时把buffer(接受的数组)变大,就能降低访问硬盘次数提高效率,buffer大的前提,空间需要充足
import java.io.*; import java.util.Scanner;public class Demo16 {public static void main(String[] args) throws IOException {System.out.println("请输入复制的文件路径");Scanner scanner = new Scanner(System.in);String src = scanner.next();File srcFile = new File(src);if (!srcFile.isFile()) {System.out.println("源文件不存在或者不是一个文件");return;}System.out.println("请输入复制目标文件路径");String dest = scanner.next();File destFile = new File(dest);//不要求目标文件本身存在,但要保证目标文件所在的目录所在。//假设目标文件写作d:/tmp/cat2.jpg,就需保证d:tmp目录所在if (!destFile.getParentFile().isDirectory()) {System.out.println("您的路径非法");return;} //输入流,输出流,按照字节流方式去打开这个文件try (InputStream inputStream = new FileInputStream(srcFile);OutputStream outputStream = new FileOutputStream(destFile)) {while(true){byte[] buffer = new byte[1024];int n = inputStream.read(buffer);System.out.println("n=" + n);if (n == -1) { //读完事了System.out.println("读到eof,结束"); break;} //从0开始,写n这么长outputStream.write(buffer, 0, n);}}}}