探秘Transformer系列之(17)--- RoPE
- 探秘Transformer系列之(17)--- RoPE
- 文章总表
- 0x00 概述
- 0x01 总体思路
- 1.1 注意力机制回顾
- 1.2 思路分析
- 1.3 结果展示
- 1.4 问题
- 0x02 原理推导
- 2.1 f()函数
- 2.2 目标
- 2.3 推导
- 调整视角
- 从二维向量到复数
- 从复数到极坐标
- 下一步思路
- 引入绝对位置信息
- 旋转矩阵
- 绝对位置编码
- 找到相对位置信息
- 找到交互
- 找到内积
- 把位置信息融入内积
- 小结
- 调整视角
- 2.4 正式定义
- f()引入绝对信息
- g()函数验证相对信息
- 右面等式
- 左边等式
- 高维度
- 2.5 总结
- 0x03 性质
- 3.1 相关性
- 3.2 周期性
- 3.3 \(\beta\)进制
- 3.4 对称性
- 3.5 频域
- 3.6 高频低频
- 3.7 远程衰减
- 表现
- 论证
- 基数
- 平滑性
- 3.8 外推
- 0x04 实现
- 4.1 基础Torch知识
- 4.2 在Transformer中的位置
- 4.3 llama3
- 总体
- 准备旋转矩阵
- 实现
- 调用
- 4.4 rotate_half
- GPT-J sytle
- GPT-NeoX style
- 0xFF 参考
文章总表
全部文章列表在这里 探秘Transformer系列之文章列表,后续每发一篇文章,会修改这里。
0x00 概述
RoPE编码来自苏神的工作Roformer, 它是目前LLM中广受欢迎使用的PE编码方式之一。
Transformer论文使用了Sinusoidal位置编码,其是加性编码,即词嵌入与编码位置相加。每个位置的嵌入向量是固定的,不考虑其与其他位置的关系。Sinusoidal位置编码希望引入相对位置关系(任意位置的位置编码都可以表达为一个已知位置的位置编码的关于距离的线性组合),但不是很成功,模型只能在一定程度上感知相对位置。位置编码常见的改进思路是以三角式位置编码公式为基础,调整自注意力计算偏置。而RoPE抛弃了位置编码常见的改进思路,即以三角式位置编码公式为基础,通过旋转矩阵、复数乘法、欧拉公式等技巧,既能以自注意力矩阵偏置的形式,反映两个token的相对位置信息,又能拆解到特征序列上,通过直接编码token的绝对位置实现,兼顾绝对位置编码和相对位置编码的优势。
RoPE没有修改Attention的结构,反而像绝对位置编码一样在输入层做文章,对输入向量直接进行改造,即对两个输入token形成的Query和Key向量做一个旋转变换,使得变换后的Query和Key带有位置信息,进一步使得Attention的内积操作不需要做任何更改就能自动感知到相对位置信息。换句话说,RoPR的出发点和策略是相对位置编码思想,但是实现方式却用的是绝对位置编码。
0x01 总体思路
我们首先看看对于三角函数编码的修改思路或者痛点,具有两点。
-
在前面章节的分析中,我们已经知道attention层的计算( \(𝑞_𝑡^𝑇𝑘_{𝑡+Δ𝑡}\) )会破坏掉输入层位置编码的优良性质,那么我们自然而然会想到:如果直接在attention层中融入位置信息,也就是直接把位置编码作用于 \(𝑞_𝑡^𝑇𝑘_{𝑡+Δ𝑡}\),这样不就能维持位置编码优良性质不变嘛。
-
三角函数编码是将位置信息直接添加到 token 嵌入中。有人认为这样其实是在用位置信息污染语义信息,应该尝试在不修改规范的情况下对信息进行编码。
因此我们先回顾下注意力机制。
1.1 注意力机制回顾
注意力机制的关键之处在于通过向量的内积得到了自注意力矩阵元素 \(A_{m,n}\)。比如,计算第 m 个词嵌入向量 \(x_m\) 对应的自注意力输出结果,就是\(q_m\)和其他所有的\(k_n\)都会计算一个注意力分数,再将注意力分数乘以对应的\(v_n\),然后求和得到输出向量\(o_m\)。具体公式展开如下:
1.2 思路分析
从上面公式可以看到,一个 token 对另一个 token 的影响是由 \(QK^T\) 点积来决定的,或者说,注意力分数其实就是两个特征向量之间的内积。这是我们应该关注位置编码的地方。因此我们来看看点积的表示:\(\vec{a}\vec{b} = |\vec{a}|\vec{b}|cos\theta\),从中有两点洞察:
- 可以通过增加或减小两个向量之间的夹角来调整两个向量的点积结果。
- 旋转对向量的范数完全没有影响,这个范数也许可以编码 token 的语义信息。
因此只需要在进入注意力机制之前,对Query和Key向量进行绝对位置编码改造即可,跟Value没有关系。这样就可以把位置编码的信息直接引入 \(𝑞_𝑚^𝑇𝑘_𝑛\) 中,这也就意味着,我们希望根据|n-m|的结果,给这个内积计算一定的惩罚:
- 当|n-m|较小时,我们希望拉进近\(𝑞_𝑚,𝑘_𝑛\)的距离。
- 当|n-m|较大时,我们希望拉远\(𝑞_𝑚,𝑘_𝑛\)的距离。
我们来看看论文中展示如何寻找到解决方案的。RoPE的出发点是“通过绝对位置编码的方式实现相对位置编码”,即编码时使用绝对位置,但是其点积结果反应相对位置。从数学角度就是找到合适的位置编码函数 f,使得如下公式成立。
用通俗语言来解读,就是对m位置的q和n位置的k进行加工,使得加工后的\(qk^T\)在计算注意力分数时,会隐含m-n这个相对位置信息。我们再用论文的公式来进一步解释。RoPE希望把 \(𝑓_𝑞\) 和 \(𝑓_𝑘\) 的内积操作,编码成一个函数g,g的自变量包括两个token \(𝑥_𝑚\) 和 \(𝑥_n\) 以及其相对位置m-n。⟨⟩ 表示 \(𝑓_𝑞\) 和 \(𝑓_𝑘\) 进行内积操作。
因为函数g的性质,所以 \(𝑓_𝑞\) 和 \(𝑓_𝑘\) 的内积也会蕴含相对位置m-n。然后使得当两个词相对位置近时(m-n小),内积可以大一点。两个词相对位置远的时候(m-n大),内积可以小一点。这样就在不对注意力结构进行改造的前提下,将显式的相对位置信息融入自注意力计算中,使得Attention内积能够自动感知到相对位置信息,达到了以绝对位置编码的形式实现相对位置编码的目的。
注意,这里只有 \(f_q(x_m,m), f_k(x_n,n)\)是需要求解的函数。而对于 g,我们要求是表达式中有 \(x_m, x_n, m-n\),也可以说是\(q_m, k_n\)的内积会受相对位置 𝑚−𝑛 影响。
1.3 结果展示
我们再看看RoPE是否满足了“通过绝对位置编码的方式实现相对位置编码”。
-
注入绝对位置信息。对于t位置的\(q_t\)和 s位置的\(k_s\),RoPE首先将\(q_t\)和 \(k_s\)在特征维度方向上两两维度一组,每两个维度构成一个复数,对应复平面中的一个向量。然后将这些向量与复数旋转矩阵的对应位置相乘,通过将一个向量旋转某个角度来为这个向量注入绝对位置信息。即,给位置为m的向量\(q_m\)乘上矩阵\(R_m\),给位置为n的向量\(k_n\)乘上矩阵\(R_n\),分别得到新的位置向量。
\[f(q,m) = R_mq = \begin{pmatrix} cos m\theta & -sin m\theta \\ sin m\theta & cos m\theta \end{pmatrix} \begin{pmatrix} q_0 \\ q_1 \end{pmatrix} \\ f(k,n) = R_nk = \begin{pmatrix}cos n\theta & -sin n\theta \\sin n\theta & cos n\theta\end{pmatrix} \begin{pmatrix} k_0 \\ k_1 \end{pmatrix} \] -
得到相对位置信息。用变换后的Q,K序列做注意力计算,通过公式展开后,就可以在注意力计算中得到相对位置信息。\((R_mq_m)^T(R_nk_n) = q_m^TR_m^TR_nk_n = q_m^TR_{n-m}k_n\)。即位置为m的向量q和位置为n的向量k可以通过点积来计算二者的注意力分数,即旋转前的注意力分数与旋转后的 注意力分数的差值仅与相对位置有关。
简略证明如下。假设\(R_n\)是旋转矩阵。
即
\(R_m\)是一个正交矩阵,它不会改变向量的模长,因此通常来说它不会改变原模型的稳定性。
1.4 问题
我们目前有几个问题值得思考。
- 论文中提到了函数f(),f()是怎么实现的?
- 为什么这样转换可以嵌入Token的位置信息?
- 这样转换为啥具有外推性?为啥说与三角函数PE思想有相似?
0x02 原理推导
下面就是要找到一个改造函数f,使得这个恒等变换g成立。我们依据RoFormer论文思路来继续分析。
2.1 f()函数
首先,把“给输入词嵌入添加位置信息,然后转换为q、k、V” 这个过程定义为函数f(),得到如下公式:
其次,我们对公式中的标记做深入分析。
-
\(x_m\),\(x_n\) :输入中所在位置分别为m,n的二维行向量,即未加入位置编码的原始词向量,并非是word embedding,则是token embedding。
-
\(q_m\):第m个token对应的词向量\(x_m\)集成位置信息m之后,转换出来的query向量。
-
\(k_n\):第n个token对应的词向量\(x_n\)集成位置信息n之后,转换出来的key向量。
-
\(v_n\):第n个token对应的词向量\(x_n\)集成位置信息n之后,转换出来的value向量。
-
\(f()\):给x向量加上位置信息,变成 q, k, v 的函数。基于 transformer 的位置编码方法都是着重于构造一个合适的 \(f_{q,k,v}\) 。
可以看到,RoPE算法的关键就是如何构建这个转换函数f(),该f()在给词向量引入绝对位置信息的同时,让\(q_mk_n^T\)中也具备相对位置信息。我们接下来就看看这个f()的来龙去脉。
2.2 目标
本节我们用反推方式来进行分析。
首先来看看f()期望达成的目标。我们希望对于\(q_mk_n^T = f_q(x_m, m)(f_k(x_n, n))^T\)来说,虽然这个计算的输入是向量\(x_m\)和\(x_n\),以及绝对位置m和n,但是我们希望这个计算的结果只依赖于向量\(x_m\)和\(x_n\)本身,以及向量\(x_m\)和\(x_n\)之间的相对距离(m-n),而不依赖其绝对位置m和n。
其次,为了更方便的推导,接下来引入一个函数g()来进行演绎。我们希望\(q_mk_n^T = f_q(x_m, m)(f_k(x_n, n))^T= g(x_m,x_n,m-n)\),最终推导的g函数公式里面只有相对距离,没有绝对位置m和n。即,假定 query 向量 \(q_m\)和 key 向量\(k_n\)之间的内积操作可以被一个函数 g 表示,该函数 g 的输入是词嵌入向量 \(x_m\),\(x_n\)和它们之间的相对位置 m - n:
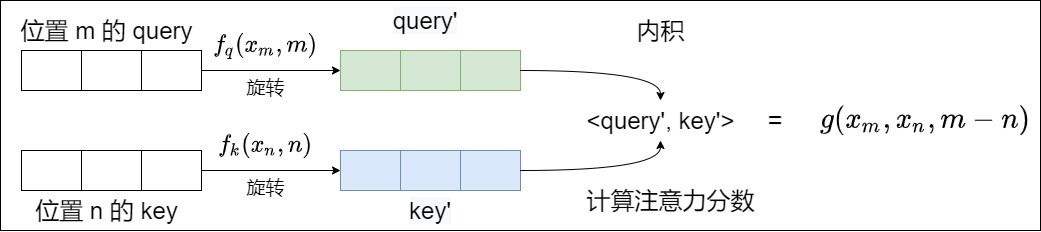
g 可以理解为一个核函数,让本来直接通过f()的运算("语义信息加上绝对位置信息"结果的点积),变成用g来解释(语义信息加上相对位置信息)。后续我们可以看到,g是通过极坐标(把相对距离转换成为角度)来解释点积。具体如下图所示。

引入 g 函数只是为了方便推导,本质目标还是寻找一个f函数,即希望可以找到一个具有良好性质的f()函数,将显式的相对位置依赖性纳入自注意公式中,即找到一种q、k向量的编码方式f(),使得编码后的\(q_m\)和\(k_n\)的点积可以由 \(x_m, x_n\) 和 m - n 表示出来(点积可以用词向量加上相对位置信息表示)。
2.3 推导
既然知道目标,我们就一步一步来推导f()。
先忽略f()中输入参数中的绝对位置参数,假设f()函数就是简单的把原始token embedding返回。此处f()将\(W^K, W^Q, W^V\)的权重矩阵操作过程也包含进去了。
我们看看如何给上面的初版f()函数逐步增加功能。
调整视角
我们要调整视角来看。
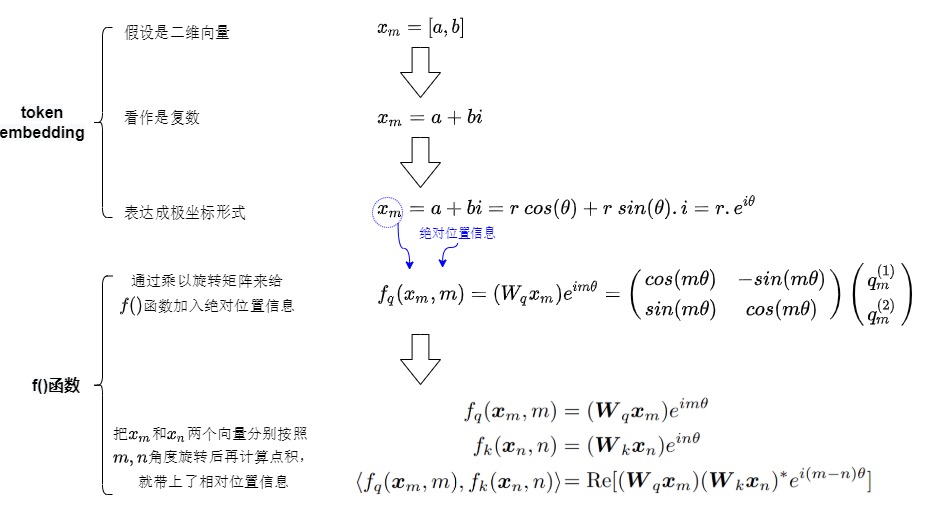
从二维向量到复数
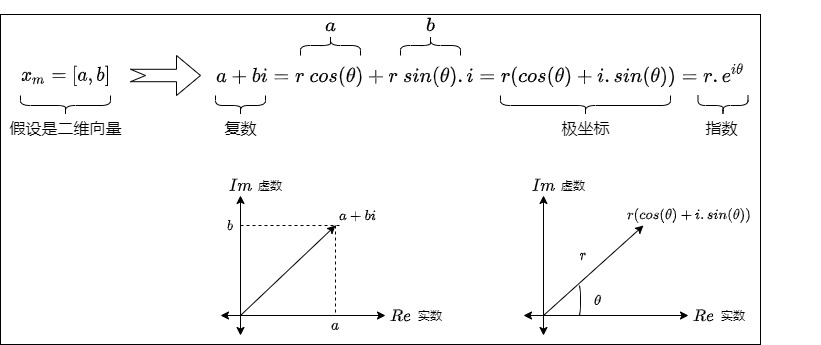
简单起见,我们先假设\(x_m\),\(x_n\)是二维行向量,即先假设输入向量是二维的。比如\(x_m\)是[a,b]。既然是二维,而一个复数等价于复平面上一个二维向量,那么我们可以将它当作复数来考虑。于是我们把\(x_m\)转换为\(a+bi\)。为何引入复数?这是因为平面旋转虽然用矩阵看起来很直观,但用复数表示更优雅。
从复数到极坐标
欧拉公式建立了指数函数,三角函数和复数之间的桥梁,一些三角函数用指数形式很容易解决和理解。比如,x表示任意实数,e是自然对数的底数,i是复数中的虚数单位,则依据欧拉公式有:
该表达式的意义是:为实部为cosx,虚部为sinx的一个复数可以表示成为一个指数形式。
依据欧拉公式,我们可以把二维向量的复数进而用极坐标来表示。$$a + bi = r\ cos(\theta) + r \ sin(\theta) . i = r(cos(\theta) + i.sin(\theta)) = r . e^{i \theta}$$。这里:
- \(cos(\theta) + i.sin(\theta)\) 是通过复平面的坐标来描述单位圆上的点。当 θ 从 0 到 2π 变化时,复数 $𝑒^{𝑖𝜃} $描述了单位圆的完整一圈。
- \(e^{i\theta}\)是通过单位圆的圆周运动来描述单位圆上的点。通过复数的指数形式,我们可以将复数看作是复平面上围绕原点旋转的单位向量。
- 对于 \(r\cdot e^{i\theta}\),r是语义,\(\theta\)是位置。
三个表现形式表达了同样的信息:将二维向量逆时针旋转角度\(\theta\)。即,一个二维向量\((x_{even}, x_{odd})\)可以当成复数\(x_{even} + i·x_{odd}\),然后乘上\(e^{i\theta}\)就能实现旋转。这样复杂的旋转从复数角度来看就是单纯地给相位加个角度。
因此,\(x_m\)和\(x_n\)是可以用极坐标来表示的,即用角度+长度来表示,这样就可以把位置信息和语义信息分离开。
下一步思路
所以,我们下面要分成两条路线来看看从指数形式如何思考。
-
如何给f()函数加上绝对位置信息?这是极坐标转换的结果。
-
f()函数如何交互才能够把相对位置信息变成相对位置信息?这是棣莫弗公式完成的功效。
然后再把这两个路线合并起来。
引入绝对位置信息
依据欧拉公式,一个复数乘以\(e^{i\theta}\)等价于其对应的二维向量逆时针旋转 \(\theta\)角度;也就是乘以旋转矩阵。为何RoPE要旋转旋转操作呢?其它映射难道不行嘛?比如用线性变化把原来不同位置上的embedding向量分别映射到新的向量空间。其实主要是因为旋转是一种不会破坏原来向量几何特性的线性变换。长度不变,夹角不变,这对注意力用点积来衡量相似度特别有用。
旋转矩阵
我们先简单复习一下旋转矩阵(Rotation matrix)。在二维空间中,存在一个旋转矩阵 \(R(\theta)\) ,当一个二维向量左乘旋转矩阵时,该向量即可实现弧度为 \(\theta\)的逆时针旋转操作。旋转矩阵就是,别的向量乘以它,就可以改变向量的方向,但不改变大小和手性。
物理意义是:\(XR(\theta)\)是对X进行逆时针旋转\(\theta\)。具体证明如下。
也可以参见下图。
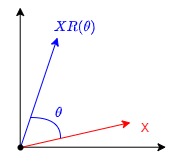
旋转矩阵几个主要特性如下:
- 保持模长:旋转不会改变向量的模长(长度),这对于点积计算中的数值稳定性至关重要。
- 保持相对角度:旋转不会影响对两个向量的夹角。如果向量 𝑥1和 𝑥2在空间中的夹角为 𝜃,那么经过旋转后,夹角仍然是 𝜃。这对于注意力机制中通过点积衡量相似性尤其重要。
- 自然嵌入相对位置关系:旋转引入的角度差 \(Δ𝜃=𝜃_{𝑝,𝑖}−𝜃_{𝑞,𝑖}\)隐含了位置 𝑝和 𝑞的距离 𝑝−𝑞,这种关系直接体现在点积的结果中。
旋转矩阵还有两个性质也需要留意。
- 正交性:旋转矩阵的转置等于其逆矩阵。\(R(\theta)^T = R(-\theta)\)
- 可加性:先绕角度\(\theta_1\)旋转,再绕角度\(\theta_2\)旋转,则相当于绕角度\(\theta_1 + \theta_2\)旋转,即\(R(\theta_1)R(\theta_2) = R(\theta_1 + \theta_2)\)。
绝对位置编码
旋转矩阵的性质恰恰满足了我们编码绝对位置信息的要求。把token embedding绕原点旋转一定的角度之后,且这个选择的角度与绝对位置数值相关(比如是\(m\theta\)),我们就在嵌入向量中引入了角度信息,也就把绝对位置引入了f()函数。具体如下图所示。\(R_m\)是一个旋转矩阵,f()函数表示在保持向量模长的同时,将其逆时针旋转\(m\theta\),这意味着只要将向量旋转某个角度,就可以实现对该向量添加对应的绝对位置信息。
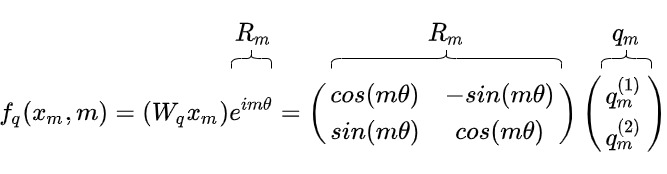
我们再进一步解释:
- 𝜃 是一个非零的常数,\(q_𝑚^{(1)}\) 是q向量的第一维度,m是位置。
- 给 \(q_m\)乘这个旋转矩阵,从几何意义来看,就是给 逆\(q_m\)时针旋转其索引的 𝜃 倍数。该操作只改变方向,不会改变q的模长。
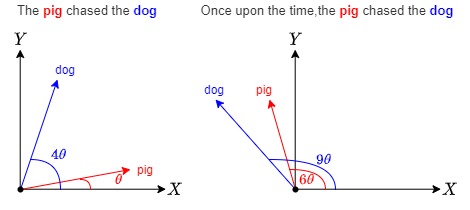
举例如下:
- dog:单词dog在第0位,不进行旋转
- The dog:单词dog在第1位,旋转角度θ
- The pig chased the dog:单词dog在第4位,旋转角度4θ
- Once upon the time, the ping chased the dong:单词dong在第9位,旋转角度为9θ.
找到相对位置信息
到目前位置,f()拥有了如下功能:在用复数和指数视角下,通过给向量乘以一个和绝对位置信息有关的旋转矩阵,给向量注入了绝对位置信息,得到了新的\(q_m\)和\(k_n\)。我们再看看f()这个功能是否好用,即是否可以依据绝对位置信息来导出相对位置信息。
找到交互
我们先看看在目前视角(复数和指数)下如何进行交互。这个基础是棣莫弗公式:两个复数相乘可以转成用极坐标表达的旋转半径相乘,再变成旋转角度的相加。假设\(\alpha,\beta\)是\(x_m,x_n\)的弧度表示。‘则交互如下。
找到内积
但是,我们的目标是\(q_mk_n^T\),这是内积,并非相乘。我们继续研究会发现,依据复数乘法性质,一个复数A(a+bi)的共轭乘以另外一个复数B(c+di),结果的实部等于A和B的内积,结果的虚部等于A和B的外积。即,第一个复数的共轭乘以第二个复数的运算,正好符合内外积运算的要求,内积取实部,外积取虚部。
注:
- 复数z的坐标表示为z=a+bi,其中a是复数的实部,b是复述的虚部,z的共轭复数是a-bi,即实部不变,虚部取相反数。
- 两个复数相乘直接展开相乘即可,z1=a+bi,z2=c+di,则z1×z2=(ac-bd)+(bc+ad)i。
把位置信息融入内积
接下来看看如何把绝对位置信息融入到内积,变成相对位置信息。下面公式中,<>表示内积计算,∗ 是共轭复数,R[∗] 表示 ∗ 的实部,右端的乘法是普通的复数乘法。公式的意思就是说:如果把二维向量当复数看待时,两个二维向量的内积等于一个复数与另一个复数的共轭的乘积的实部。
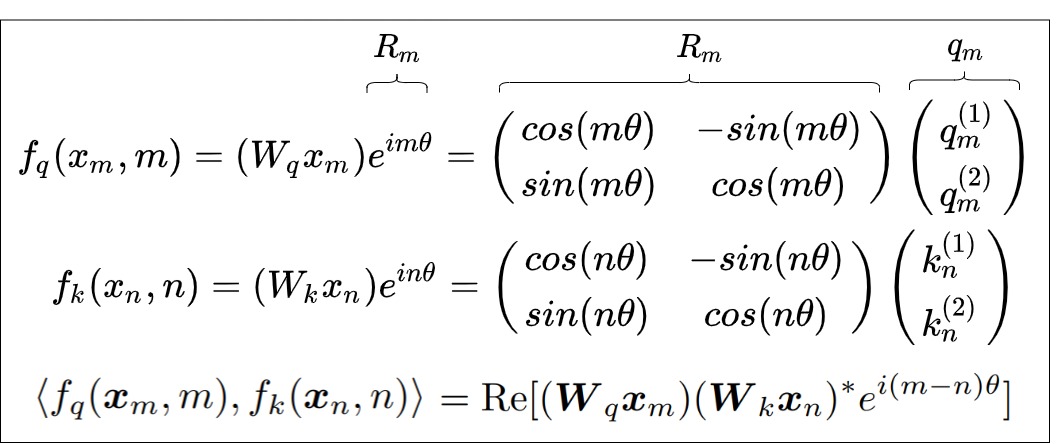
小结
我们总结推导步骤如下图:
- 先将\(x_m\),\(x_n\)转化为对应的复数形式\(x_m\),\(x_n\),也可以表达成极坐标形式;
- 应用旋转变换,得到新的复数形式\(x_m\),\(x_n\)。具体是将\(x_m\),\(x_n\)分别乘以\(e^{imθ}\),\(e^{inθ}\),变成\(x_me^{imθ}\),\(x_ne^{inθ}\),那么就相当于给\(x_m\), \(x_n\),配上了绝对位置编码(显式地依赖绝对位置m,n),即得到了\(q_m\),\(k_n\)。即,对\(x_m\)施加复数乘法后的结果向量\(q_m\),\(k_n\),就是\(x_m\)经过矩阵旋转之后的向量。
- 通过复数操作来计算 query 和 key 之间的内积,得到自注意力的计算结果。具体而言,因为\(q_m\),\(k_n\)已经是复数,我们将\(q_m\)的共轭乘以\(k_n\),将结果取实部,就得到了RoPE编码后的自注意力矩阵元素 \(A_{m,n}\)。\(<(W_qx_m)e^{im\theta},(W_kx_n)e^{in\theta}> = Re[(x_me^{im\theta})(x_ne^{in\theta})^*] = Re[x_mx_n*ei^{(m-n)\theta}]\),我们会发现,内积只依赖于相对位置m−n,这就巧妙地利用到复数的幅角相加性质来将绝对位置与相对位置融合在一起了。
\(x_m\)和\(x_n\)两个向量一开始只有绝对位置信息,把\(x_m\)和\(x_n\)两个向量分别按照m,n角度进行旋转之后,再来计算点积(让绝对位置信息做交互),向量内积就自动带上了相对位置信息。
2.4 正式定义
既然推导完毕,我们来正式看看f()和g()函数的解读,也就是把上面的推导再详细梳理下。
f()引入绝对信息
f()定义如下,可以理解为f()的作用是把两个输入参数(绝对位置信息m和词信息\(x_m\))分开放在极坐标的两部分,分别经由以长度和角度来表示。
我们来仔细推导下。
首先,\(W_q\) 是二维矩阵,\(x_m\)是二维向量,\(W_qx_m\)相乘的结果也是二维向量\(q_m\)。
然后,把\(q_m\)解读为复数形式,这样可以后续更好的处理,即通过复数乘法来执行旋转操作。
将\(e^{im\theta}\)也用复数表示。\(e^{i\theta}\)表示以单位圆上,幅度为\(m\theta\)为终点的向量。\(e^{im\theta} = cos(m\theta) + i\ sin(m\theta)\)。
因此,
就是两个复数相乘
接下来,重新将f(x) 表达为实数向量形式
这其实就是query向量乘以一个旋转矩阵\(R_m\),即把位置信息加入了进来,但是把绝对位置信息和词信息抽离开。放在极坐标的两部分。
具体参见下图。
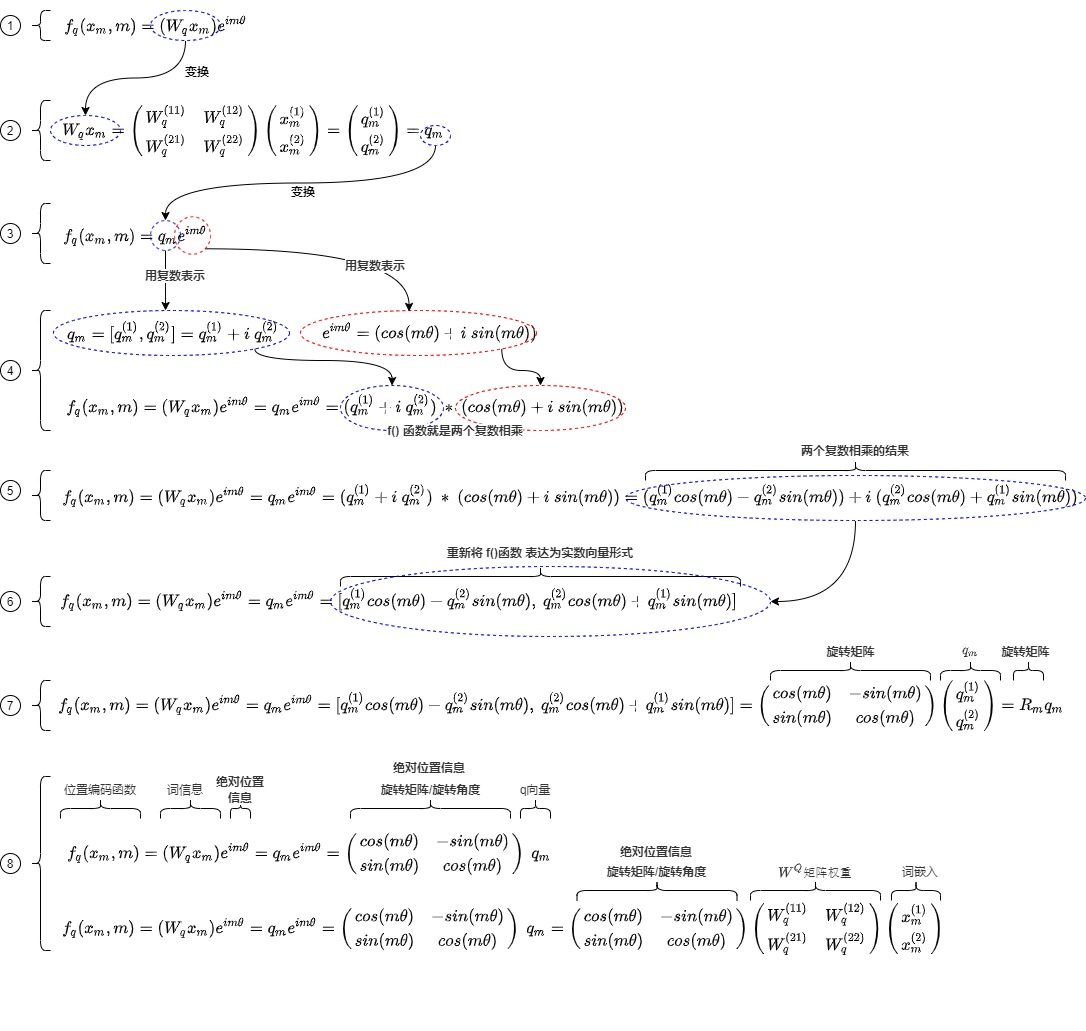
以上推导了f()函数的作用是把绝对位置信息加入到了词嵌入中,我们来看看f()的点积如何引入相对位置信息,即,用g()来论证我们构造的f()是正确的。
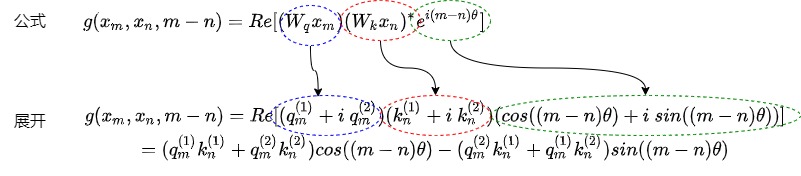
g()函数验证相对信息
我们希望验证的是:得到f函数之后,我们经由f()函数构造了query 向量\(q_m\) 和 key 向量\(k_n\),两个向量之间的内积操作可以被一个函数 g 表示,该函数 g 的输入是词嵌入向量 \(x_m\)、\(x_n\)和它们之间的相对位置 m - n。这样就证明f()的有效性:通过绝对位置信息来表达相对位置信息。位置信息是高维向量,用极坐标表示位置信息,相对位置 m - n 在极坐标中就是他们的夹角(即从m旋转一定角度到n),这样就把位置信息变成了角度信息。
用数学公式表达如下。
已知
要论证
Re[x]表示一个复数x的实部,\((W_kx_n)^*\)表示复数\(W_kx_n\)的共轭。
接下来证明 $ \langle f_q(x_m,m),f_k(x_n,n)\rangle = Re[(W_qx_m)(W_kx_n)^* e^{i(m-n)\theta}] $左右相等即可。
右面等式
先推导Re[]内部的信息。
继续推导
用图例表示如下。
左边等式
左边等式展开如下。
可以看到等式左右是相等的。具体也可以如下图所示。
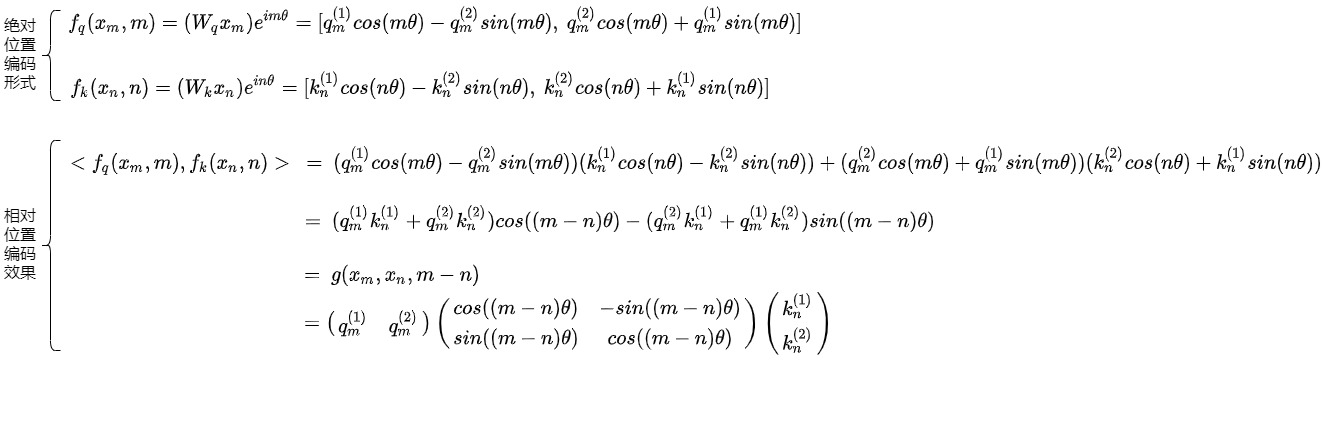
因此,RoPE 完成了其预期的目的。
- 添加绝对位置信息。添加绝对位置编码是通过使用旋转矩阵来完成的,即通过一个基于位置的旋转矩阵将每个位置的嵌入旋转到一个新的位置。
- 得到相对位置信息。可以使得两个token的编码,经过内积变换(self-attn)后,得到的结果,受它们位置的差值,即相对位置影响。即将显式的相对位置依赖性纳入自注意公式中。\(q_m\)和\(k_n\)之间的内积仅由\(q_m\)和\(k_n\),距离\(|i-j|\)的值决定。
高维度
迄今为止,我们讨论的是二维向量,而位置编码通常是高维向量,这种情况下我们如何处理?RoPE 没有尝试在一个旋转操作中编码所有位置信息,而是将同一维度内的组件配对并旋转它们(否则混合使用 x 和 y 偏移量信息)。通过独立处理每个维度,RoPE 保持了空间的自然结构,而且可以根据需要推广到任意多个维度。
我们仔细分析以下。
- 首先,我们看看如何用对角阵在正交的子空间上施加不同的行变换,假设有两个方阵A,B,设\(X=(X^1,X^2)\),则变化如下。
- 其次,内积满足线性叠加性,任意偶数维的RoPE都可以表示为二维情形的拼接。
于是我们可以把每个向量(Key或者Query)两维度一组切分,分成元素对\({(q^1,q^2),(q^3,q^4),...}\),每对都解释为二维向量。这样就把原始的空间切分为一个个独立正交的二维子空间。然后RoPE以角度\(\theta_i\)对每个二维向量(维度对\((q_i,q_{i+1})\))在每个子空间上面分别进行独立的旋转,其他的子空间不动。旋转角的取值与三角式位置编码相同,即采样频率 \(\theta\) 乘上token下标(\(m\theta_i = m \times base^{-2i/d}\))。旋转完再做内积,将所有切分拼接,就得到了含有位置信息的特征向量。
因为每一组都满足一个函数g(带有相对关系m-n),最后他们相加,也一定会满足g函数。
这里 \(\theta_i=10000^{−2i/d}\) ,𝑖=0,1,2,...,𝑑/2−1,沿用了 Transformer 最早的 Sinusoidal 位置编码的方案。因为每个位置旋转的角度不一样, $𝜃_𝑖 $从0到d/2-1是单调递减的,频率是递减的过程,所以它可以带来一定的远程衰减性。
如果加入\(x_m\)和\(W_{q,k}\),则具体如下:
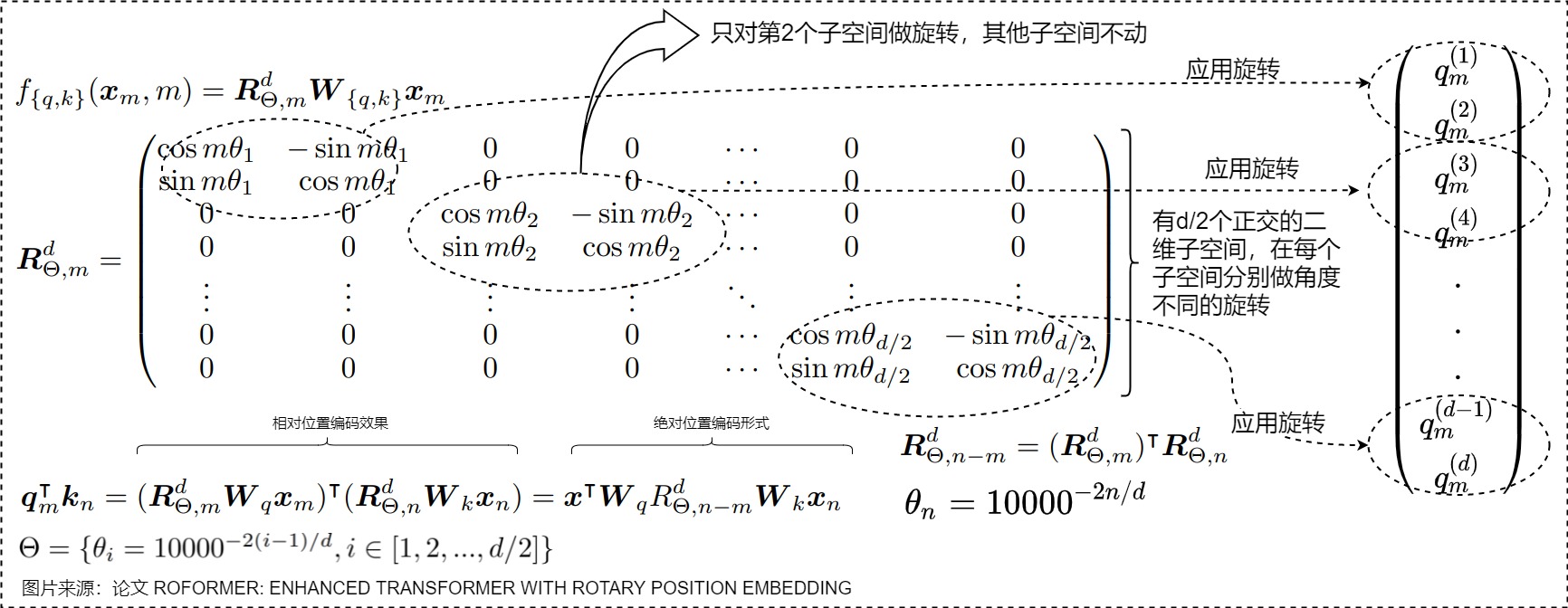
\(𝑅^d_{𝜃,𝑚}\) 是一个正交矩阵,它不会改变向量的模长,因此通常来说它不会改变原模型的稳定性。另外,因为\(R_m\)的稀疏性,直接用矩阵乘法实现会很浪费算力,所以在实践中推荐使用如下图所示的计算方式。其中\(\bigotimes\)是逐位对应相乘。
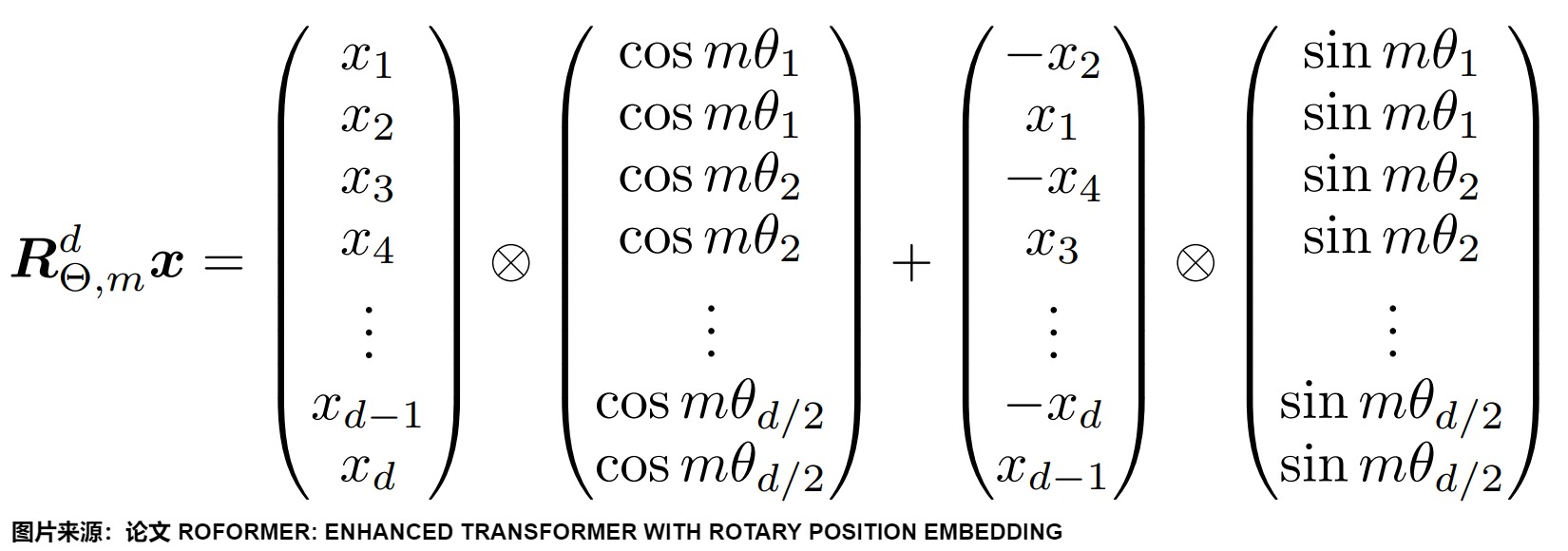
可以看出RoPE形式上和Sinusoidal位置编码有点相似,只不过Sinusoidal位置编码是加性的,而RoPE可以视为乘性编码,即给位置 m 的 Query 高维向量 \(q_m\) 乘上矩阵 \(R_m\)。这对应着向量在各个子维度上的旋转,所以叫做旋转位置编码。因为在独立的二维子空间做不同角度的旋转。你可以将其想象成一个逆时针的时钟系统,带有时针分针秒针还有更细粒度的针。靠前的 pair 表示的粒度越大。或者说,RoPE通过不同频率的三角函数有效区分了长程和短程。
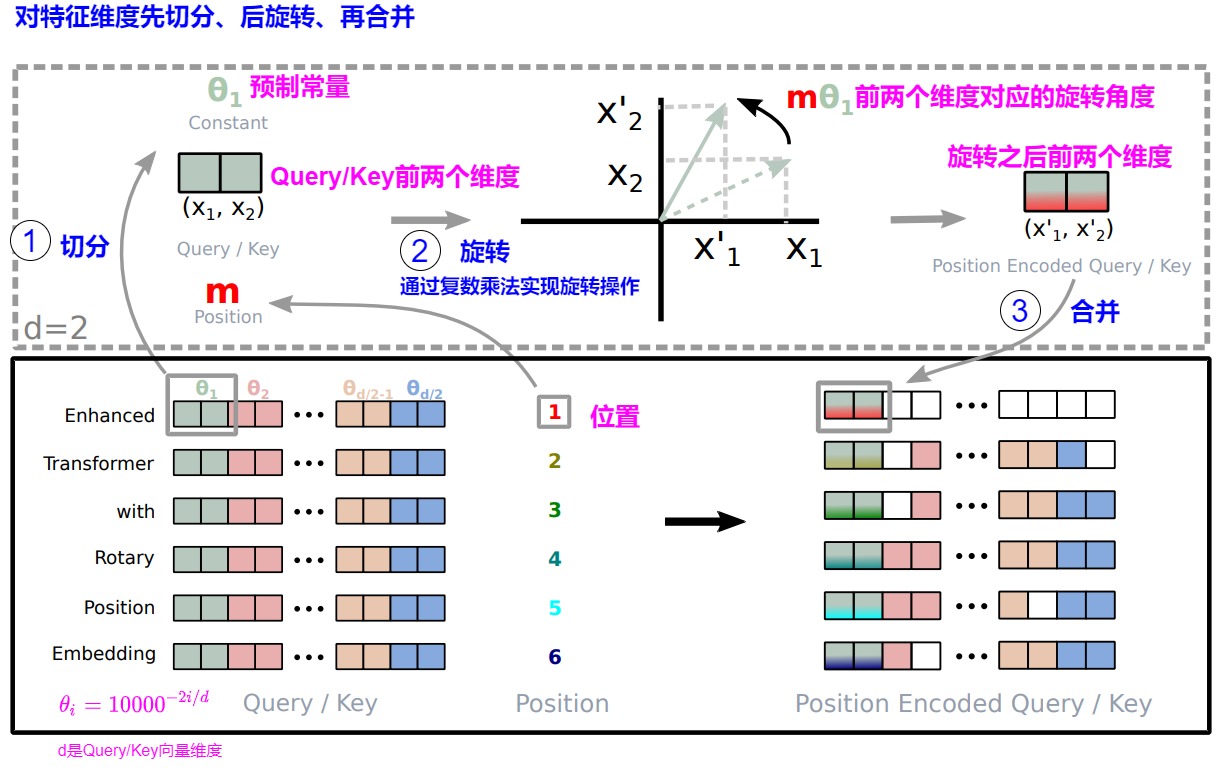
我们再使用论文的图进行阐释。
- 对于位置为m的d维q向量,我们将单词的词向量大小设定为2的倍数,即按照维度两两一组切分,每对都解释成为一个二维向量。
- 第i组(即向量中的2i,2i+1元素)的旋转角度为\(mθ_i\),\(θ_i\)与i以及词向量的hidden size有关,是一个这是一个从1渐变到接近于0的函数,因此,前面维度的𝜃𝑖旋转的更快,后面的旋转的更慢。
- 然后对切分后的每个二维向量旋转。
- 旋转完成后将所有切分拼接,就得到了含有位置信息的特征向量。
2.5 总结
正弦位置编码其实就是一种想要通过绝对位置编码表达相对位置的位置编码。但是由于投影矩阵的存在,这种能力被破坏了。这样,虽然原始transformer中的正弦位置编码实际上没有起到它应有的效果。
RoPE的思想和正弦位置编码有一定相似性,都尝试在编码过程中将相对位置信息考虑进去、位置变换的过程都利用三角函数转换公式、在二维平面上进行位置转换和旋转形式一致。
两者不同的是:
-
三角函数PE是直接计算每个绝对位置向量后,在输入时把绝对位置向量与Token向量相加。或者说,是采用相加的形式将位置编码融入到词向量中。
-
RoPE是在投影之后,注意力计算前做旋转。即RoPE可以看成是将三角函数PE计算的位置向量分别与输入经过三个权重矩阵的query、key后的矩阵进行一个转换操作。是将原始query、key向量改造成一个带有位置信息的新向量,位置信息由参数m和θ进行表征,其中m为token在句子中的位置,θ的下标和向量中各元素的位置直接相关。
注意,不能在投影前旋转,因为那样就无法合并m-n了。可能就是因为在投影之后做旋转,所以RoPE才避免出现了正弦位置编码的问题。另外,在RoPE中采用的是类似哈达马积的乘积形式。
-
由于三角函数的性质,导致三角函数PE本身就具备表达相对距离的能力,而RoPE位置编码本身不能表达相对距离,需要结合Attention的内积才能激发相对距离的表达能力。

或者说,相对于三角函数PE,RoPE更深入将位置信息嵌入到模型结构中。从形式上看它有点像乘性的绝对位置编码,通过在q,k中施行该位置编码,那么效果就等价于相对位置编码。而如果还需要显式的绝对位置信息,则可以同时在v上也施行这种位置编码。
在苏神的文章Transformer升级之路:12、无限外推的ReRoPE?中指出:RoPE 形式上是一种绝对位置编码,但实际上给 Attention 带来的是相对位置信息,即如下的Toeplitz矩阵。这种形式的bias让我们想起了ALiBi,它并没有作用在 embedding 上,而是直接作用在了 Attention 上,通过这种构造方式既实现了远程衰减,又实现了位置的相对关系。
总的来说,RoPE通过绝对位置的操作,可以达到绝对位置的效果,也能达到相对位置的效果。这样一来,我们得到了一种融绝对位置与相对位置于一体的位置编码方案。
最后总结结合 RoPE 的 self-attention 操作的流程如下:
- 首先,对于
token序列中的每个词嵌入向量,都计算其对应的 query 和 key 向量; - 然后在得到 query 和 key 向量的基础上,对每个
token位置都计算对应的旋转位置编码; - 接着对每个
token位置的 query 和 key 向量的元素按照两两一组应用旋转变换; - 最后再计算
query和key之间的内积得到 self-attention 的计算结果。计算内积后,绝对位置信息不复存在,仅留下相对位置信息。
此外,RoPE 仅应用于查询(Query)和键(Key)的嵌入,不适用于值(Value)的嵌入。
0x03 性质
本节来学习RoPE的一些主要特性以及业界思考。
3.1 相关性
旋转编码 RoPE 有如下特点:
- 计算\(qk^T\)点积时,保留了词语的相对位置信息(不会因词语的绝对位置发生改变),这样可以有效地保持位置信息的相对关系。
- 相邻位置的编码之间有一定的相似性,即便在旋转后,相邻的位置仍然会有相似的嵌入。而距离较远的编码之间有一定的差异性。这样可以增强模型对位置信息的感知和利用。
- 语义相似的Token平均来说获得更多的注意力。即,当 k和q相近时,不管它们的相对距离n-m多大,其注意力 \(q^TR_{n-m}k\)平均都应该更大,至少要比随机的两个token更大。
3.2 周期性
因为旋转一圈的弧度是\(2\pi\) ,所以RoPE中的向量旋转就像时钟一样,每组分量的旋转都具有周期性。因为每组分量的旋转弧度都随着位置索引的增加而线性增加,所以越靠后的分组,它的正弦函数的周期越大、频率越低,它的旋转速度越慢。整体频率可以对应到低频,以及高频上。
所以我们接下来就有一个问题:随着位置的增大,旋转角度是否会重复?具体解答如下。
- 在任意第k个子空间,只要\(\theta_k\)公式中不含有\(\pi\),那么就不会出现周期性重复。
- 如果每个子空间都不会出现周期性重复,整体更不会重复。
3.3 \(\beta\)进制
苏神认为RoPE是β进制编码,原文如下。
位置n的旋转位置编码(RoPE),本质上就是数字n的β进制编码!
对于一个10进制的数字n,如果希望得到其的β进制表示的(从右往左数)第m位数字,方法是
也就是先除以\(β^{k-1}\)次方,然后求模(余数)。而RoPE可以改写为
其中,\(β=10000^{2/d}\)。模运算的最重要特性是周期性,cos,sin刚好也是周期函数。所以,除掉取整函数这个无关紧要的差异外,RoPE(或者说Sinusoidal位置编码)其实就是数字n的β进制编码!
3.4 对称性
对照三角函数编码性质,对于RoPE编码,位置m的token A对于位置n的Token B的注意力影响,和位置为2n-m上的token C对于Token B的注意力影响一样。尤其当位置m的Token与位置2n-m的Token相同时,有如下表达式
这证明RoPE编码也是符合对称性,没有学习到方向的差异。
3.5 频域
\(\theta\)的大小决定了对应维度的单调性,也赋予了这些维度上的参数不同的学习倾向。\(\theta\) 就对应到了傅里叶变换中的频率这一概念。\(\theta\) 较大时,注意力计算结果仅在相对距离 t−s 较小时保持一致的单调性,之后陷入波动,本质上就是高频信号; \(\theta\) 较小时,注意力计算结果能在相对距离 t−s 较大时仍然能保持一致的单调性,波动较为平缓,本质上就是低频信号。
论文“SCALING LAWS OF ROPE-BASE"指出,如果用\(q_tk_s\)表示 s 位置的token对 t 位置token的语义相似度,\(q_tk_s\)是一个二维时域信号,有 t,s 两个时域维度。语义相似度 \(q_tk_s\) 就是由不同频域维度上的语义相似度分量\(q_t^{(n)}k_s^{(n)}\)组合而成的,每个维度对应一个频段 \(\theta_n\) ,高频分量对应局部语义影响,低频分量对应长上下文语义影响。从频域到时域,最朴素的转换方式就是傅里叶逆变换,通过\(e^{i(s-t)\theta_n}\)将不同频段的分量组合。由于是为了获取 s 位置对 t 位置的位置信息,所以变换对象是 \(q_t^{(1)}k_s^{(1)}...q_t^{(d)}k_s^{(d)}\),变换的目标维度是原始二维时域的对角线方向,即 s−t 方向。
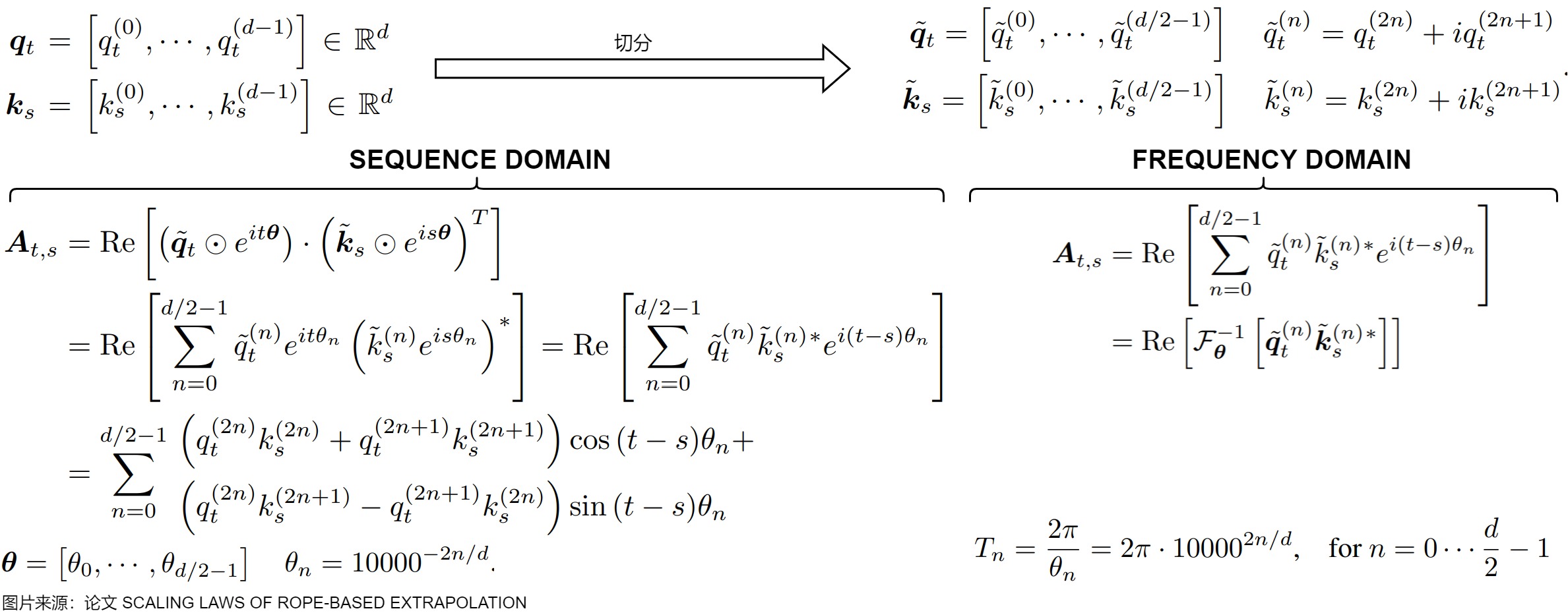
论文“Round and Round We Go! What makes Rotary Positional Encodings useful?”也揭示了RoPE不同频率成分在模型学习中的作用:高频用于位置注意力,低频用于语义注意力。
我们可以计算出每个维度的ROPE对应的波长(Wavelength)是\(\lambda_d = \frac{2\pi}{\theta_d} = 2𝜋𝑏^{\frac{2d}{|D|}}\),,其中 |D| 是维度的总数,b是base。波长描述了嵌入在该维度上完成一次完整旋转(2π)所需的标记数量。波长与RoPE嵌入的频率有关,且在不同维度上可能有所不同。
当给定一个长度L,有的维度会出现周期比L更长,可以假设,当出现这个情况的时候,所有的位置都能获得一个唯一的编码,也就是绝对位置都保留了下来。反之,周期比较短的维度只能保留相对位置信息。
3.6 高频低频
RoPE中,向量旋转就像时钟一样,因为旋转一圈的弧度是\(2\pi\),所以每组分量的旋转都具有周期性。RoPE以角度\(\theta_i\)对每个二维向量(维度对\((q_i,q_{i+1})\))分别进行旋转,旋转角的取值与三角式位置编码相同,即采样频率 \(\theta\) 乘上token下标(\(m\theta_i = m \times base^{-2i/d}\)),旋转完将所有切分拼接,就得到了含有位置信息的特征向量。这里 \(\theta_i=10000^{−2i/d}\) ,沿用了 Transformer 最早的 Sinusoidal 位置编码的方案。它可以带来一定的远程衰减性。每个位置旋转的角度不一样。
在周期函数中,如\(sin(\omega x)\) ,\(\omega\) 越大,频率越大。在RoPE中,\(\omega\)随维度变量 k 增加,\(b^{-2k/d}\)减小,从而频率降低。
我们可得:位置编码的低维对应高频,高维对应低频。对于每组分量,它的旋转弧度随着位置索引的增加而线性增加。越靠后的分组,它的旋转速度越慢,正弦函数的周期越大、频率越低。
-
高频:是RoPE的位置向量,i 比较小(前面的维度), 𝜃𝑖 较大的时候,周期短,频率高。
-
低频: 是RoPE的位置向量,i 比较小(后面的维度),𝜃𝑖 较小的时候,周期长,频率低。
NTK-RoPE、YaRN的作者Bowen Peng认为:高频学习到的是局部的相对距离,低频学习到的是远程的绝对距离。高频低频两者都很重要,它们之间更像是一种层次的关系;用进制类别来看,低频对应的就是高位,如果只保留低位而去掉高位,那么结果就相当于求模(余数),无法准确表达出位置信息来。

3.7 远程衰减
远程衰减基于一个很朴素的假设:相对距离越远,则彼此之间的关联度越低,依赖度越低。如果位置编码具有远程衰减特性,则可以让位置相近的Token平均来说获得更多的注意力。
表现
RoPE也呈现出远程衰减的性质,具体表现为:对于两个词向量,若它们之间的距离越近,则它们的内积分数越高,反之则越低。即,位置 m 的 Query 向量 \(q_m\) 与位置 n 的 Key 向量 \(k_n\) 相对距离越远( |n−m| 越大), \((R_mq_m)^T(R_nk_n))\) 越小。从下图可以看到,随着相对距离的变大,内积结果有衰减趋势。
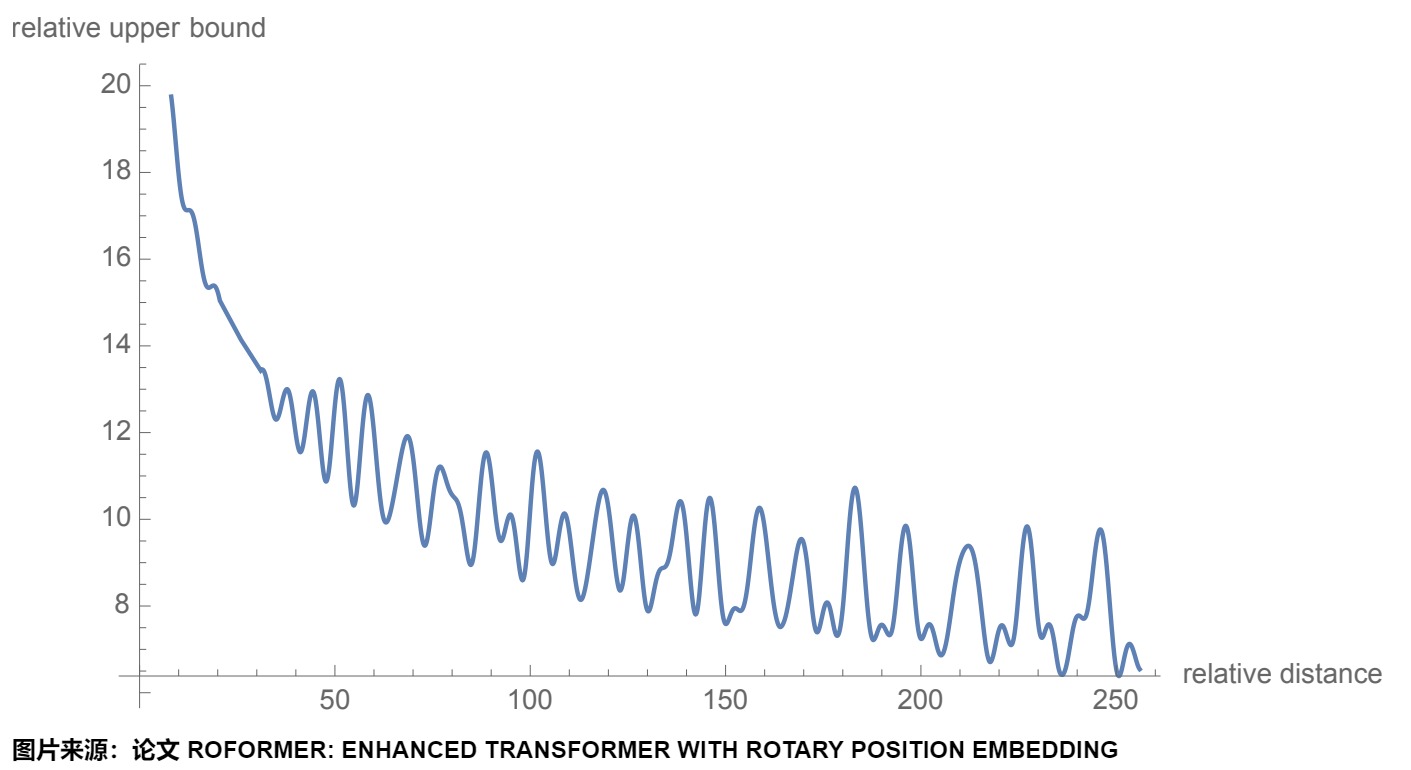
从图上也可以看出,在衰减曲线后期会产生很大波动,产生了U形状的注意力模式。对比图如下。
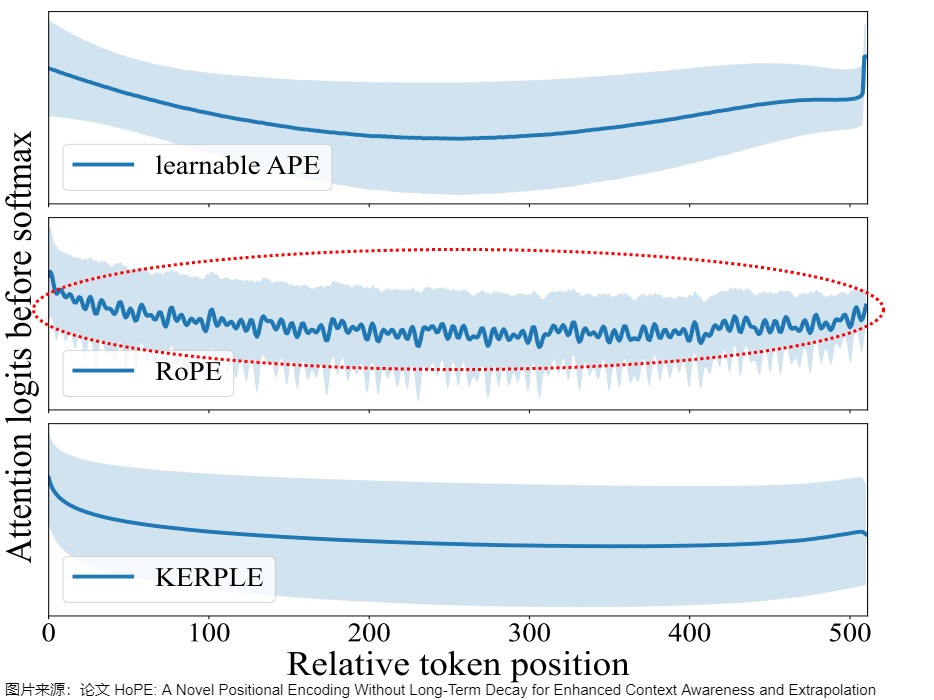
论文”HoPE: A Novel Positional Encoding Without Long-Term Decay for Enhanced Context Awareness and Extrapolation"对此进行了细致的分析,发现在RoPE中,U形状的注意力模式是由特定学习到的组件(learned components)造成的,这些组件也是限制RoPE表达能力和外推能力的关键因素。具体参见下图。
- (a) 表示将RoPE分解为组件(Comps)进行分析(见图上红圈方程式)。上部子图显示了每个组件对整体注意力逻辑的贡献。我们用红色突出显示了一些具有突出模式(patterns)的组件,即“激活”组件,用蓝色突出显示了低频组件。下部子图展示了整体注意力逻辑,以及“激活”组件的组合效应。
- (b) 给出了训练期间RoPE不同组件的方差(VAF)。
- (c) 揭示了外推中的OOD现象是由“激活”组件引起的。两个上部的子图显示了第一层的注意模式,下部的子图则显示了后续层的异常模式。
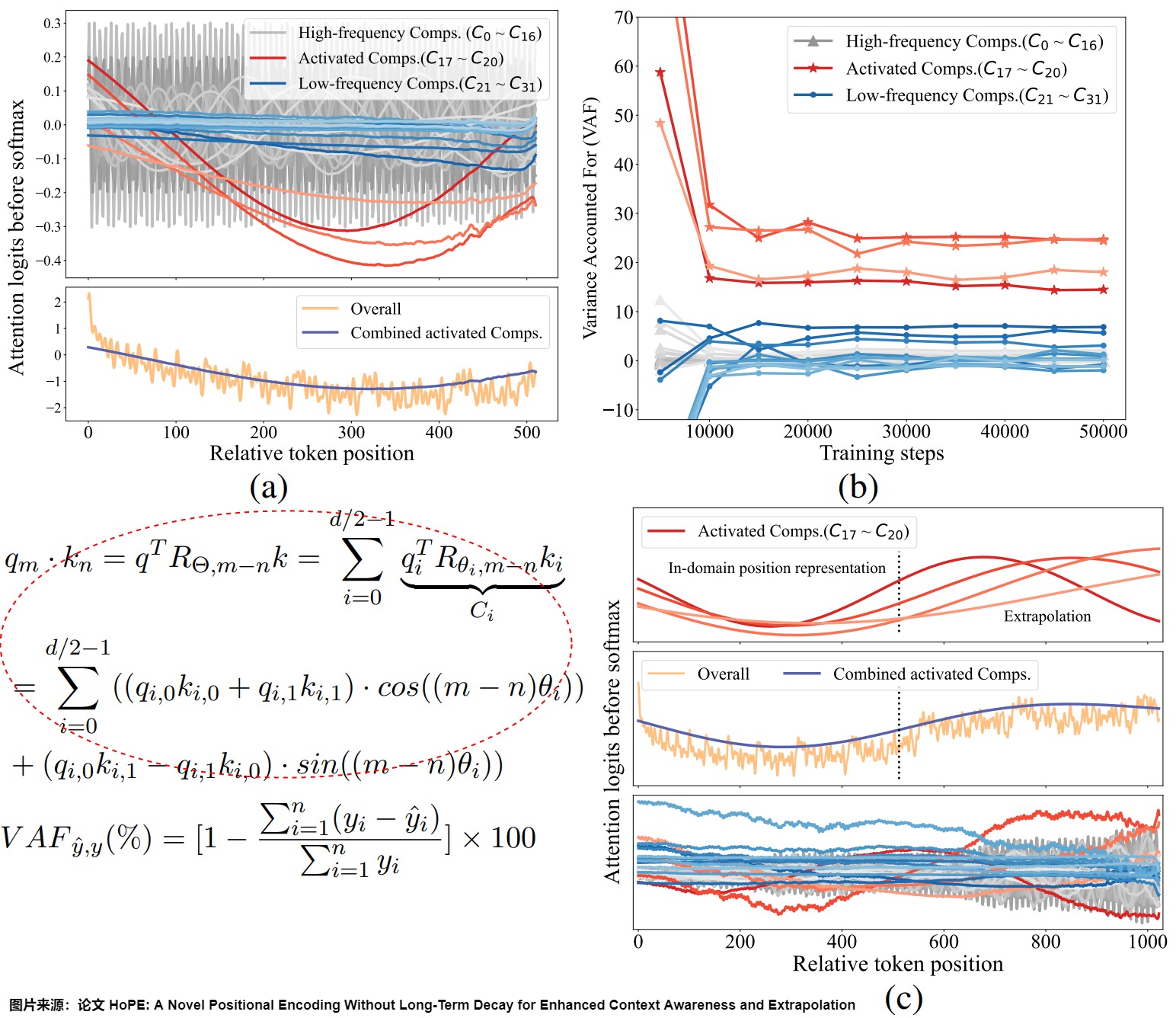
基于这些发现,该论文提出了一种新的位置编码方法——High-frequency rotary Position Encoding(HoPE)。HoPE通过去除RoPE中的位置依赖组件,保留高频信号,从而理论上也打破了长期衰减的原则。
能否设计不振荡的位置编码?很难,位置编码函数如果不振荡,那么往往缺乏足够的容量去编码足够多的位置信息,也就是某种意义上来说,位置编码函数的复杂性本身也是编码位置的要求。
论证
我们接下来对远程衰减进行论证。
首先,我们用论文中的推导来看,具体参见下图。

其次,有研究人员认为下面公式为RoPE的主要功能项。Transformer位置编码(意义) 河畔草lxr
\(C_{RoPE}(t−s)\) 大致随相对距离 t−s 呈现单调减的关系。但是整体偏置的单调减并不意味着每个维度偏置的单调减: \(\theta_n\) 的大小决定了维度 2n−1,2n 的单调性,也赋予了这些维度上的参数不同的学习倾向:
- n 较小时, \(\theta_n\) 较大,趋向于1,仅在相对距离 t−s 较小时保持一致的单调性,之后陷入波动,诱导对应维度刻画较近的位置信息;
- n 较大时, \(\theta_n\) 较小,趋向于0,能相对距离 t−s 较大时仍然保持一致的单调性,诱导对应维度刻画较远的位置信息。
反过来,不同相对位置的语义信息也会反映在不同的特征维度上:
- 在相对距离 t−s 较小时,所有维度的偏置都接近于1,对应自注意力分布更加关注相邻位置的信息;
- 在相对距离 t−s 较大时,多数维度有正有负相互抵消,只有部分维度的偏置较大,如果两个token对应维度的语义特征高度重合则会予以部分强调,否对应自注意力分布趋近于0。这也正是相对偏置的一大优势,即对相对距离较远的语义关联,没有给予绝对的惩罚,而是给予相对的过滤:虽然通过整体偏置抑制较远距离的信息,但是仍然允许某些特征维度上的语义汇集到自注意力计算中。
基数
对于\(\theta_n = 10000^{-2n/d}\),10000这个数决定了 𝜃 的大小,我们称其为基数(base)。base的不同取值会影响注意力远程衰减的程度。因为“随距离衰减”是外推的关键,所以base的性质与大模型的长度外推息息相关,如NTK-Aware Scaled RoPE、NTK-by-parts、Dynamic NTK等长度外推方法,本质上都是通过改变base,从而影响每个位置对应的旋转角度,进而影响模型的位置编码信息,最终达到长度外推的目的。
由于 RoPE 中的 attention 值除了 q,k 本身外,仅和$ R_{n-m} \(因子相关,下面考察\) R_{n-m} $ 因子的特点
那么问题就变成了积分 $\int_0^1 \mathrm{e}^{\mathrm{i}(\mathrm{m}-\mathrm{n}) \cdot 10000^{-\mathrm{t}} }\mathrm{dt} $的渐进估计问题,通过一下函数计算积分值与位置距离的关系就可以分析出不同 base 值的影响。
- base=1,完全失去远程衰减特性。
- base 越小,衰减得越快且幅度也更大。太小的base会破坏注意力远程衰减的性质,例如base=10或100时,注意力分数不再随着相对位置的增大呈现出震荡下降的趋势。
- base 越大,衰减得越慢且幅度也越小。这也是为什么训练更长的窗口,要把base改大的原因。所以现在业界的主流做法都是窗口变长后,base也要跟着变大做适配。苹果就在其模型中用了很大的基数。输入序列越长,base就需要越大,让未充分训练过的窗口强行衰减变慢,本身也是降低崩的概率的一种方式。
平滑性
另外,embedding维度和衰减曲线的平滑程度成正相关,维度越高,衰减曲线越平滑。外推性的基本前提是函数的“光滑性”。外推性就是局部推断整体,它依赖的就是给定函数的高阶光滑性(高阶导数存在且有界)。但是三角函数编码或RoPE不具备这种性质。它们是一系列正余弦函数的组合,这算是关于位置编码k的高频振荡函数,而不是直线或者渐近趋于直线之类的函数,所以基于它的模型往往外推行为难以预估。
3.8 外推
尽管RoPE可以理论上可以编码任意长度的绝对位置信息,并且通过旋转矩阵(三角计算)来生成超过预训练长度的位置编码,并且RoPE也具有远程衰减特性(“随距离衰减”是外推的关键)。RoPE仍然存在外推问题(length extrapolation problem),即对于基于RoPE的大语言模型,测试长度超过训练长度之后,模型的效果会有显著的崩坏,具体表现为语言建模困惑度急剧攀升。远程衰减属性导致在更长文的外推中,RoPE编码的作用影响也在衰减,效果在逐步变差。
我们将在后面专门写一篇来做具体分析。
0x04 实现
4.1 基础Torch知识
torch.outer
torch.outer(a, b) 计算两个 1D 向量 a 和 b 的外积,生成一个二维矩阵,其中每个元素的计算方式为:result[i,j]=𝑎[i]×𝑏[j]。即,result矩阵的第 i 行、第 j 列的元素等于向量 a 的第 i 个元素与向量 b 的第 j 个元素的乘积。
外积(outer product)是指两个向量 a 和 b 通过外积操作生成的矩阵:𝐴=𝑎⊗𝑏。其中 𝑎⊗𝑏 生成一个矩阵,行数等于向量 𝑎 的元素数,列数等于向量 𝑏的元素数。
torch.matmul
当输入张量的维度大于 2 时,torch.matmul将执行批量矩阵乘法。
torch.polar
torch.polar()函数会构造一个复数张量,用法是torch.polar(abs, angle, *, out=None) → Tensor。其元素是极坐标对应的笛卡尔坐标,绝对值为 abs,角度为 angle。 out=abs⋅cos(angle)+abs⋅sin(angle)⋅j。
torch.repeat_interleave
torch.repeat_interleave()函数会返回一个具有与输入相同维度的重复张量。
torch.view_as_complex
把一个tensor转为复数形式,要求这个tensor的最后一个维度形状为2。
torch.view_as_real
把复数tensor变回实数,可以看做是是刚才操作的逆变换。
4.2 在Transformer中的位置
不同于原始 Transformer 的绝对位置编码,RoPE位于多头注意力机制的内部,直接作用于每个头完成变换的query和key,而且每个头使用相同的RoPE(RoPE的输入参数只有位置和维度,跟头无关),这也意味着在 transformer中的每一层都要加入RoPE。
4.3 llama3
lama中对RoPE的实现采用复数的公式来计算\(f_q(x_m,m) = (W_qx_m)e^{im\theta}\)。该方式速度较快,但不方便后续修改。
具体而言,是把每个向量(Key或者Query)两维度一组切分,分成元素对\({(q^1,q^2),(q^3,q^4),...}\),每对都解释为二维向量。然后RoPE以角度\(\theta_i\)对每个二维向量(维度对\((q_i,q_{i+1})\))分别进行旋转,旋转角的取值与三角式位置编码相同,即采样频率 \(\theta\) 乘上token下标(\(m\theta_i = m \times base^{-2i/d}\)),旋转完将所有切分拼接,就得到了含有位置信息的特征向量。
这里 \(\theta_i=10000^{−2i/d}\) ,沿用了 Transformer 最早的 Sinusoidal 位置编码的方案。它可以带来一定的远程衰减性。每个位置旋转的角度不一样。
总体
其总体代码和公式对应如下图所示。
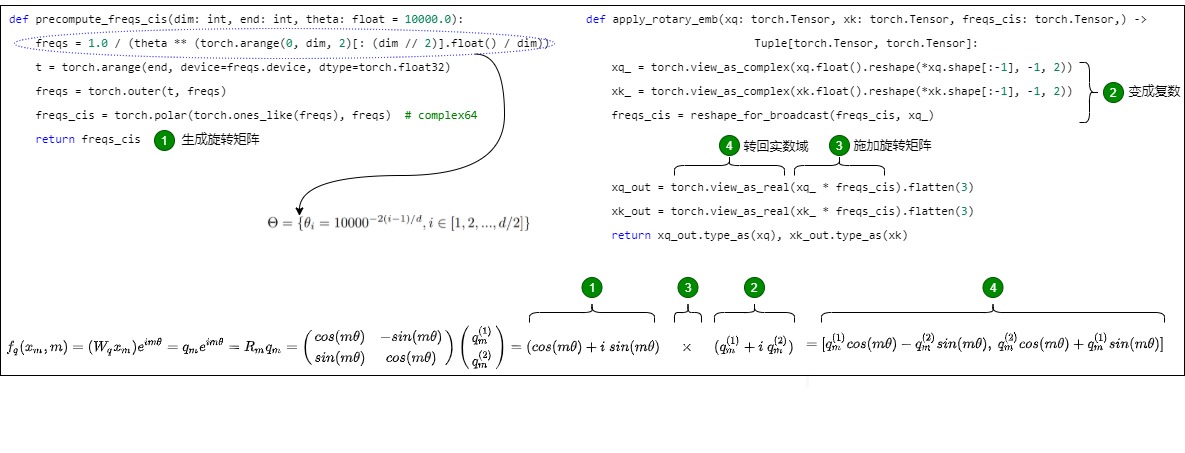
在实现 RoPE 算法之前,需要注意:为了方便代码实现,在进行旋转之前,需要将旋转矩阵转换为极坐标形式,嵌入向量(q、k)需要转换为复数形式。完成旋转后,旋转后的嵌入需要转换回实数形式,以便进行注意力计算。
准备旋转矩阵
precompute_freqs_cis()函数会生成旋转矩阵,即 给定维度预计算频率θ。θ 完全由 Q、K、V 的向量长度 d 决定。位置 m 对应我们的 query 长度,实际代码中由 max_position_embeddings 参数决定,可以理解为模型支持的最长 query 的长度,因此 max 有了,m 的范围也就有了。结合上面的信息,针对一个固定了最长 query 长度 m 和向量维度 d 的 LLM,我们可以提前将其对应的旋转变换矩阵构造完成。
freqs = torch.outer(t, freqs)的矩阵如下。
结合这个 Rd 的变换矩阵,分别执行 cos 和 sin,便可以得到我们计算所需的全位置全维度的变换矩阵。
torch.polar之后的 freqs 如下。
具体代码如下。
# 生成旋转矩阵
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):# 根据维度 d 生成旋转角度θ向量。计算词向量元素两两分组之后,每组元素对应的旋转角度 θ_i,由于是将向量两两旋转应用 RoPE,所以共有 dim/2 个 θ。θ 完全由 Q、K、V 的向量长度 dim 决定# freqs 长度是 dim/2,一半的维度。2表示是偶数这里 θ 完全由 Q、K、V 的向量长度 d 决定,即 dim维度,取0,2,4...等维度freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim)) # 生成 token 序列索引 t = [0, 1,..., seq_len-1],即拿到所有位置对应的ID,就是论文中常说的m或者nt = torch.arange(end, device=freqs.device, dtype=torch.float32)# 计算m * θ。将旋转角度和 `token` 位置索引相乘,即求向量的外积,结果是一个矩阵,该矩阵包含了每个位置和每个维度对应的旋转角度,即每个元素代表位置t在第i维上的旋转角度(频率)freqs = torch.outer(t, freqs) # freqs的形状是 [seq_len, dim // 2],具体参见上面公式。# 将上一步的结果写成复数的形式𝑒^{𝑖𝑚𝜃},模是1,幅角是freqs。freqs_cis的大小为(seqlen, dim//2)# 假设 freqs = [x, y],则 freqs_cis = [cos(x) + sin(x)i, cos(y) + sin(y)i] freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64return freqs_cis
precompute_freqs_cis()函数用如下方式进行调用。
class Transformer(nn.Module):def __init__(self, params: ModelArgs):super().__init__()self.params = paramsself.vocab_size = params.vocab_sizeself.n_layers = params.n_layersself.tok_embeddings = VocabParallelEmbedding(params.vocab_size, params.dim, init_method=lambda x: x)self.layers = torch.nn.ModuleList()for layer_id in range(params.n_layers):self.layers.append(TransformerBlock(layer_id, params))self.norm = RMSNorm(params.dim, eps=params.norm_eps)self.output = ColumnParallelLinear(params.dim, params.vocab_size, bias=False, init_method=lambda x: x)# 预先计算出来选择矩阵,乘以2是为了动态扩展self.freqs_cis = precompute_freqs_cis(params.dim // params.n_heads,params.max_seq_len * 2,params.rope_theta,)
实现
apply_rotary_emb()方法用于将 cos、sin 的旋转矩阵应用到原始的 query 和 key 向量上,这样在 Attention 内积时,就会为 query 和 key 引入位置信息。
# 为了匹配q和k,需要对角度进行扩展
# freqs_cis维度是[seq len, dim/2]
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):ndim = x.ndimassert 0 <= 1 < ndim# 需要确保形状和x的形状匹配,即是(x.shape[1]=seq len, x.shape[-1]=dim/2)assert freqs_cis.shape == (x.shape[1], x.shape[-1])# x的第二维和最后一维保留,其他维度置为1shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]return freqs_cis.view(*shape) # [1,S,1,head_dim//2] def apply_rotary_emb(xq: torch.Tensor,xk: torch.Tensor,freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:"""作用: 将q,k向量分别与旋转向量相乘,得到旋转后的q,k向量q/k_rotated输入: x_q(torch.Tensor): 实际上是权重 W_q * 词嵌入向量值, 来自上一个线性层的输出, 形状为 [batch_size, seq_len, n_heads, head_dim]或者[batch_size, seq_len, dim]x_k(torch.Tensor): 实际上是权重 W_k * 词嵌入向量值, 来自上一个线性层的输出, 形状为 [batch_size, seq_len, n_heads, head_dim]或者[batch_size, seq_len, dim]freqs_cis (torch.Tensor): 频率复数张量, 形状为 [max_seq_len, head_dim]输出: 施加了旋转编码后的q和k""" # 实数域张量转为复数域张量。将一个大小为n的向量xq_两两组合形成复数来计算,需要增加维度,把最后一维变成2,即把最后一维的两个实数作为一个复数的实部和虚部来构建一个复数。 # 计算过程q:[batch_size,atten_heads,seq_len,atten_dim]->q_complex:[b,a_h,s,a_d//2,2]->[b,a_h,s,a_d//2]->[b,a_h,s,a_d//2,2]# [:-1]意思是从第一维到倒数第二维;*是为了展开列表;-1, 2表示把最后一维展开成两维:x/2和2,即最后一维是2; # xq_.shape = [batch_size,atten_heads,seq_len,atten_dim//2,2],如果不考虑多头,则是[batch_size, seq_len, dim // 2, 2]xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2)) # 复数形式张量xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2)) # 复数形式张量# freqs_cis 的形状必须与 xq 和 xk 相匹配,因此我们需要将 freqs_cis 的形状从 [max_seq_len, head_dim] 调整为 [1, max_seq_len, 1, head_dim]。即,旋转矩阵(freqs_cis)的维度在序列长度(seq_len,维度 1)和头部维度(head_dim,维度 3)上需要与嵌入的维度一致。 freqs_cis = reshape_for_broadcast(freqs_cis, xq_)# 通过复数乘法实现向量旋转操作,然后将结果转回实数域。这是幅度不变,角度变换的操作,即把结果恢复成原来的样子,将第三维之后压平,也就是(atten_dim//2,2)->(atten_dim)。位置编码只和向量的序列位置还有向量本身有关,和batch以及注意力头无关,所以只用关注第二维和第四维# xq_out.shape = [batch_size, seq_len, dim]xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)return xq_out.type_as(xq), xk_out.type_as(xk) # 又是实数了
调用
Transformer会调用Transformer层进行RoPE操作。
class Transformer(nn.Module):@torch.inference_mode()def forward(self, tokens: torch.Tensor, start_pos: int):_bsz, seqlen = tokens.shapeh = self.tok_embeddings(tokens)self.freqs_cis = self.freqs_cis.to(h.device)freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]mask = Noneif seqlen > 1:mask = torch.full((seqlen, seqlen), float("-inf"), device=tokens.device)mask = torch.triu(mask, diagonal=1)# When performing key-value caching, we compute the attention scores# only for the new sequence. Thus, the matrix of scores is of size# (seqlen, cache_len + seqlen), and the only masked entries are (i, j) for# j > cache_len + i, since row i corresponds to token cache_len + i.mask = torch.hstack([torch.zeros((seqlen, start_pos), device=tokens.device), mask]).type_as(h)for layer in self.layers:h = layer(h, start_pos, freqs_cis, mask)h = self.norm(h)output = self.output(h).float()return output
TransformerBlock会直接调用到Attention的forward函数。
class TransformerBlock(nn.Module):def __init__(self, layer_id: int, args: ModelArgs):super().__init__()self.n_heads = args.n_headsself.dim = args.dimself.head_dim = args.dim // args.n_headsself.attention = Attention(args)self.feed_forward = FeedForward(dim=args.dim,hidden_dim=4 * args.dim,multiple_of=args.multiple_of,ffn_dim_multiplier=args.ffn_dim_multiplier,)self.layer_id = layer_idself.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)def forward(self,x: torch.Tensor,start_pos: int,freqs_cis: torch.Tensor,mask: Optional[torch.Tensor],):h = x + self.attention(self.attention_norm(x), start_pos, freqs_cis, mask)out = h + self.feed_forward(self.ffn_norm(h))return out
Attention会做如下操作。
def forward(self,x: torch.Tensor,start_pos: int,freqs_cis: torch.Tensor,mask: Optional[torch.Tensor],
):bsz, seqlen, _ = x.shapexq, xk, xv = self.wq(x), self.wk(x), self.wv(x)xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)# attention 操作之前,应用旋转位置编码xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)self.cache_k = self.cache_k.to(xq)self.cache_v = self.cache_v.to(xq)self.cache_k[:bsz, start_pos : start_pos + seqlen] = xkself.cache_v[:bsz, start_pos : start_pos + seqlen] = xvkeys = self.cache_k[:bsz, : start_pos + seqlen]values = self.cache_v[:bsz, : start_pos + seqlen]# repeat k/v heads if n_kv_heads < n_headskeys = repeat_kv(keys, self.n_rep) # (bs, cache_len + seqlen, n_local_heads, head_dim)values = repeat_kv(values, self.n_rep) # (bs, cache_len + seqlen, n_local_heads, head_dim)# Q/K/V 对应维度为 [bsz, seq_len, num_heads, head_dim],transpose 将 seq_len 和 num_heads 的维度调换了,得到的 states 维度为 [bsz, num_heads, seq_len, head_dim]。这个变换是为了将 seq_len x head_dim = 4096 x 8 挪到一起,方便后面的 ⊗ 对位相乘。xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)keys = keys.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)values = values.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)if mask is not None:scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)scores = F.softmax(scores.float(), dim=-1).type_as(xq)output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)return self.wo(output)
4.4 rotate_half
rotate_half是RoPE中经常使用的方法,我们专门来分析下。rotate_half() 的作用是将输入张量x的一半隐藏维度进行旋转,即进行语义向量复数化,实现向量乘以虚数i,等价于向量逆时针旋转90度。
上述式子继续推导,合并cos和sin就可以发现,\(q_t\)旋转后的结果就是\(q_t\)乘上cos,再加上\(q_t\)翻转维度并取反一维后乘上sin的结果,因此程序里实现叫rotate_half。
rotate_half其实有两种实现方式。我们首先看看其中一种。具体来说,它将输入张量的后半部分(划为虚部)取负,然后与前半部分(划为实部)拼接,从而实现旋转操作。其流程如下:
- 分割张量:假设输入张量x的形状为[batch_size, num_attention_heads, seq_len, head_size],函数首先将张量x分割成两部分:x1和x2。x1包含前半部分,x2包含后半部分。
- 旋转操作:将x2取负,然后将x2与x1拼接在一起。这样,原始张量的后半部分被旋转到了前半部分的位置,实现了旋转效果。
- 拼接:最后,将取负后的x2与x1在最后一个维度上拼接,形成最终的旋转位置嵌入张量。
具体代码对应如下。
# 后半部分和前半部分进行了交换,并且将后半部分的符号取反。
# 这个函数很好理解,就是将原始向量从中间劈开分为 A、B 两份,然后拼接为 [-B, A] 的状态:比如 [q0,q1,q2,q3,q4,q5,q6,q7] -> [-q4,-q5,-q6,-q7,q0,q1,q2,q3]
def rotate_half(x):"""Rotates half the hidden dims of the input."""# 前64个embedding位置 x=[batch_size, num_heads, seq_len, emb_size] => [batch_size, num_heads, seq_len, emb_size/2]x1 = x[..., : x.shape[-1] // 2] # 后64个embedding位置 x=[batch_size, num_heads, seq_len, emb_size] => [batch_size, num_heads, seq_len, emb_size/2]x2 = x[..., x.shape[-1] // 2 :] # 后64embedding位置取负号,和前64embedding位置拼接return torch.cat((-x2, x1), dim=-1)def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):cos = cos.unsqueeze(unsqueeze_dim)sin = sin.unsqueeze(unsqueeze_dim)q_embed = (q * cos) + (rotate_half(q) * sin)k_embed = (k * cos) + (rotate_half(k) * sin)return q_embed, k_embed
将 rotate_half() 代入到 apply_rotary_pos_emb(),以 q=[x1,x2] 为例:
q_embed = [x1, x2] * cos + [-x2, x1] * sin = [x1 * cos - x2 * sin, x2 * cos + x1 * sin]
具体参见下图。这里的负号,对应和角公式中的负号。计算旋角 \(m\theta\) 的过程此处省略。

然而,上面的代码是HuggingFace的Transformer库的实现,和RoPE论文公式有些许差异,具体为元素位置排列上的差异,在论文中q0的结果是q0和q1这一对元素经过三角函数变换而成的,但是在实际公式中q0是由q0和\(q_{d/2+1}\)这一对形成的。
-
HuggingFace:\([-q_4,-q_5,-q_6,-q_7,q_0,q_1,q_2,q_3]\)
-
论文:\([-q_1, q_0, -q_2, q_3,....q_{n-1}, q_{n-2}]\)
具体近似如下。
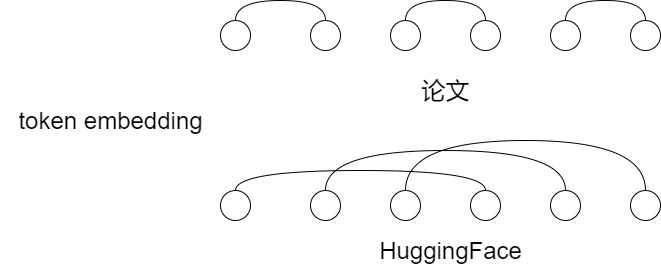
其实,这涉及到两个对特征维度进行切分的不同的实现。
按照RoPE论文的思路,就是GPT-J style。实现过程中对特征向量的奇偶维度进行rotate_half操作,相邻两维度一组( ⊙ 表示对应位相乘,对 \(k_s\) 的操作相同)。
由于对奇偶维度旋转需要将维度两两交错,实现较为复杂,后来的研究人员提出,直接将特征维度一切二,这种实现方式称为GPT-NeoX style,实现过程中对特征向量的前后各半进行rotate_half操作。GPT-J style 和 GPT-NeoX style 是等价的,可以互相转化的:GPT-J style中的奇数维度对应GPT-NeoX style的前一半维度,GPT-J style中的偶数维度对应GPT-NeoX style的后一半维度。将GPT-J style的奇数维度抽出来整体拼接在偶数维度之前,就会得到GPT-NeoX style的结果。
两种实现方式只是对应的R矩阵不同,最终都可以实现绝对位置实现相对位置编码的目的。对最终的结果没有影响。因为RoPE对原始向量的改造本质上是以一对元素为单位经过旋转矩阵运算,将所有对的结果进行拼接的过程,而到底是选择连续的元素作为一对,还是其他的挑选方式都是可以的,只要是embedding维度为偶数,且挑选的策略为不重复的一对,最终Attention的内积结果都能感知到相对位置信息,因为Attention满足内积线性叠加性,至于谁和谁一组进行叠加并不重要。
GPT-J sytle
是和原始论文和博客一样,使用的相邻两个为一组。
GPT-NeoX style
不是相邻两个元素为一组,而是 𝑞0 和 \(𝑞_{𝑑/2−1}\) 为一组。
在FlashAttention的源码中就实现了GPT-J sytle 和 GPT-NeoX style的RoPE。
https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/layers/rotary.py
def rotate_half(x, interleaved=False):if not interleaved:x1, x2 = x.chunk(2, dim=-1)return torch.cat((-x2, x1), dim=-1)else:x1, x2 = x[..., ::2], x[..., 1::2]return rearrange(torch.stack((-x2, x1), dim=-1), '... d two -> ... (d two)', two=2)def apply_rotary_emb_torch(x, cos, sin, interleaved=False):"""x: (batch_size, seqlen, nheads, headdim)cos, sin: (seqlen, rotary_dim / 2)"""ro_dim = cos.shape[-1] * 2assert ro_dim <= x.shape[-1]cos = repeat(cos, 's d -> s 1 (2 d)')sin = repeat(sin, 's d -> s 1 (2 d)')return torch.cat([x[..., :ro_dim] * cos + rotate_half(x[..., :ro_dim], interleaved) * sin, x[..., ro_dim:]], dim=-1)
0xFF 参考
Base of RoPE Bounds Context Length Xin Men etc.
LLM时代Transformer中的Positional Encoding MrYXJ
LLM(廿三):LLM 中的长文本问题 紫气东来
LLaMA中的旋转位置编码(RopE)实现解读 qwdjiq
Long LLM第二篇——why RoPE? 王焱
ROUND AND ROUND WE GO! WHAT MAKES ROTARY POSITIONAL ENCODINGS USEFUL?
RedHerring RedHerring
RoPE外推的缩放法则 —— 尝试外推RoPE至1M上下文 河畔草lxr
RoPE旋转位置编码深度解析:理论推导、代码实现、长度外推 JMXGODLZ
Transformer位置编码(基础) 河畔草lxr
Transformer位置编码(改进) 河畔草lxr
Transformer升级之路:10、RoPE是一种β进制编码
Transformer升级之路:15、Key归一化助力长度外推 苏剑林
Transformer升级之路:16、“复盘”长度外推技术
Transformer升级之路:2、博采众长的旋转式位置编码
Transformer改进之相对位置编码(RPE) Taylor Wu
https://arxiv.org/pdf/2104.09864.pdf
llama源代码逐行分析 bookname
qwen源码解读3-解读QWenAttention模型的调用 programmer
transformers 库提供的 llama rope 实现
中文语言模型研究:(1) 乘性位置编码 PENG Bo
位置编码算法背景知识 Zhang
千问Qwen2 beta/1.5模型代码逐行分析(一) bookname
浅谈LLM的长度外推 uuuuu
深入剖析大模型原理 — Qwen Blog
羡鱼智能:【OpenLLM 009】大模型基础组件之位置编码-万字长文全面解读LLM中的位置编码与长度外推性(上)
羡鱼智能:【OpenLLM 010】大模型基础组件之位置编码-万字长文全面解读LLM中的位置编码与长度外推性( 中)
让研究人员绞尽脑汁的Transformer位置编码 - 科学空间|Scientific Spaces
LLM:旋转位置编码(RoPE)的通俗理解 莲子
Effective Long-Context Scaling of Foundation Models
HoPE: A Novel Positional Encoding Without Long-Term Decay for Enhanced Context Awareness and Extrapolation