内容有点太多,先截图一份 contents

-
对 transformers 结构的重刻划
一种常见的 decoder only 的 transformer 结构如下。
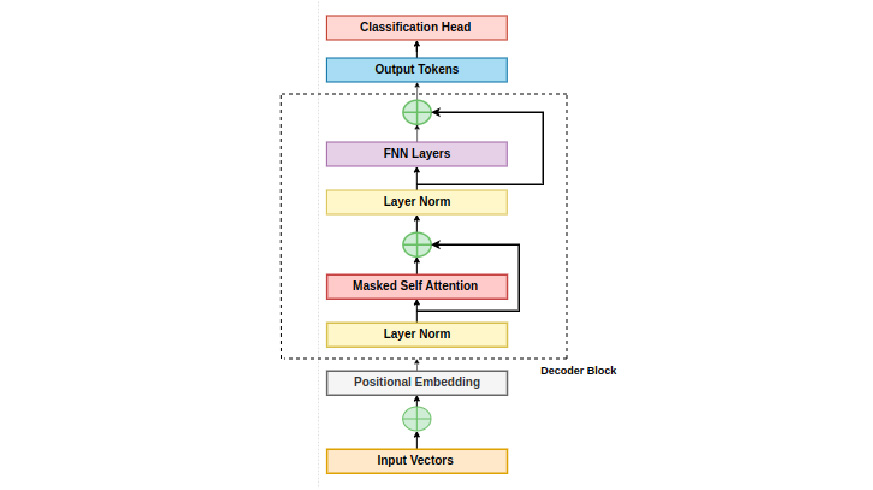
但是我们可以把这个 residual stream 的线抻直,将这个过程视为 transformer layer 对 residual stream 中所包含的语义信息的增改。参考原文中这张图片:

具体来说,transformer layer 通过 \(W_Q/W_K/Q_V\) 等投影,从 residual stream 中读取信息,处理(计算 attention/ 进行激活)后通过 \(W_O\) projection 将信息写回 residual stream。MLP 层类似, LLaMA 模型使用了 up/down projection 来进行读写。
信息的读写有这样一种刻画方式,比如 MLP layer 将某个 residual stream 中的某个信息删除,设若这个信息对应的向量是 \(v\),那么 MLP 的矩阵有一个特征值为 \(-1\),对应的特征向量就是 \(v\),那么这就将 residual stream 中的该向量删除了。和删除相类似的是复制,那么某信息向量和矩阵的特征值 1 对应的特征向量的很相似,那么这个矩阵对该信息的影响就几乎是复制了一遍。(原文里面研究方法好像是,把输入和输出的 context 向量求夹角,如果是很大的钝角,便可以理解成“删除作用”)
考虑 multihead self attention 中的每个 head(常见的 multihead 合并方式是将所有 attention(Q,K,V) 的计算结果 concat 起来后使用 \(W_O\) 投影,这个过程也可以等价表述成,每个 attention head \(h\) 通过 \(W_O^h\) 进行投影,然后不同 head 的结果相加)的行为,它其实可以分成 per token calculation 和 inter token calculation。也即 \(W_O,W_V\) 作用于每个 token,而 \(soft\max\left(\dfrac{q^Tk}{\sqrt d_k}\right)\) 刻画了 token 之间的信息。
这样的计算行为的性质是,每个 attention head 从 residual stream 中(读写的方式 & 读写的内容)和(在 token 间处理信息的方式)是相互独立的。这给了我们机会去分别研究 \(x^TW_Q^TW_Kx\) 和 \(W_OW_V\) 两个部分。
原文中有 conceptal takeways 的部分,使用 chat.qwen.ai 翻译如下。
-
注意力头可以被视为独立的操作,每个操作输出的结果会被添加到残差流中。注意力头通常被描述为一种交替的“拼接和乘法”公式,以提高计算效率,但这在数学上是等价的。

-
仅注意力模型可以写成一系列可解释的端到端函数,将标记映射到对数概率的变化。这些函数对应于模型中的“路径”,并且如果冻结了注意力模式,则它们是线性的。
-
Transformer具有大量的线性结构。仅仅通过分解求和并相乘矩阵链,就可以学到很多东西。
-
注意力头可以理解为有两个主要的独立计算:QK(“查询-键”)电路计算注意力模式,以及OV(“输出-值”)电路计算每个标记如何影响输出(如果被关注的话)。
-
键、查询和值向量可以被视为低秩矩阵 ( W_Q^T W_K ) 和 ( W_O W_V ) 计算中的中间结果。不参考它们来描述Transformer可能是有用的。
-
注意力头的组合极大地提高了Transformer的表现力。注意力头有三种不同的组合方式,分别对应于键、查询和值。键和查询的组合与值的组合非常不同。
-
Transformer的所有组件(标记嵌入、注意力头、MLP层和解嵌入)通过读取和写入残差流的不同子空间相互通信。与其分析残差流向量,将残差流分解为所有这些不同的通信通道可能更有帮助,这些通道对应于模型中的路径。
\(W_OW_V\) 实现了复制,即对 [...b...a] context 预测 next token 为 b'。 这里的 b' 和 b相等或者相近。下图中的 source token 对应 [....b...a] 中的 b,destination token 对应 a,out token 对应 b',example skip Tri-grams 就是把这些词拼起来后的得到的小短句。

另一个有力的证明是对某个 attention head number=12 的单层模型 12 个 attention head 中 \(W_OW_V\) 矩阵的特征值归一化并(即每个 \(\lambda_i\) 做 \(\dfrac{\lambda_i}{|\lambda_i|}\))可视化图片,发现其中有 10 个矩阵的特征值(均为复数)的在坐标系上的 (1,0) 周围密集分布
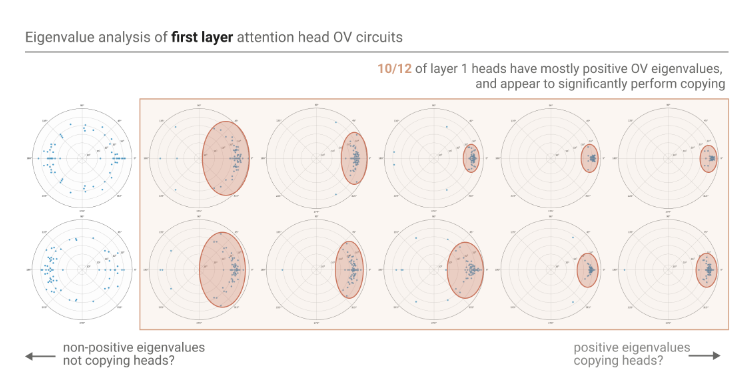
\(W_QW_K\) 实现了在前缀中,对当前 token 的 embedding/hidden_state 相似 token 的搜索。即 [ab...a] 可以 predict 得到 b
-
这篇文章通过对 0/1/2 layer(s) attention-only transformer 的计算过程进行研究,得出如下这么几个结论(或猜想)
-
零层Transformer模型双元语法统计。双元语法表可以直接从权重中访问。
\(Output = W_{unemb}W_{emb}x\) 实现了通过第 \(n-1\) 词预测第 \(n\) 个词,且第 \(n\) 个词的预测只和第 \(n-1\) 个词有关
-
单层注意力模型是双元和“跳过三元”(形式为“A...B C”的序列)模型的集合。双元和跳过三元语法表可以直接从权重中访问,而无需运行模型。这些跳过三元语法出乎意料地具有很强的表现力,包括实现一种非常简单的上下文学习。
通过 Residual stream 建模,容易发现单层 attention-only transformer 包含 0 层 transformer,也就是 bigram。skip-trigram 也不难理解,Q 和 K 的组合实现了 token 之间的通信,\(W_O,W_V\) 实现了对 next token 的表征。
-
两层注意力模型可以使用注意力头的组合实现更复杂的算法。这些组合算法也可以直接从权重中检测到。值得注意的是,两层模型使用注意力头的组合来创建“归纳头”,这是一种非常通用的上下文学习算法。
没看懂乱写的警告两层 attention 中的第二层复合了第一层的运算:在做 qkv projection 时,可以表达为 \(W_{Q/K/V}(x_0 + h_1(x_0))\)。原文管 \(W_{Q} h_1(x_0)\) 为 q-composition,类似有 k-,v- composition。这几个 composition 提升了模型的表达效果(不过 v-composition 意义不大,因为在没有 activation 的情形下,叠加线性映射没有意义)。通过张量积的工具我们能把整个的计算流程表达如下。
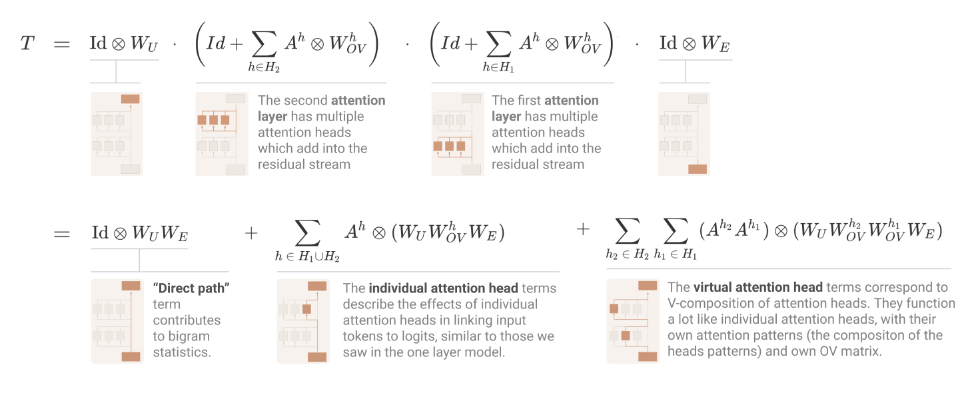
值得指出的是,q side residual stream 和 k side residual stream 并不是一个 residual stream,一个是最后一个 token 的残差流,另一个是前 n-1 个 token 中的某个的残差流。
我们称 q-compostion 和 k-composition 两个机制构成的结构为 induction head,它应该实现:

我的理解是,做 next token prediction 时,induction head 的结构使得 q-vector 的点乘实现了“查询前缀中相似度较高的词”的功能。原文章还给出了一些可视化的例子,以及一些检查理论合法性的算法。
-
单层和两层注意力模型使用非常不同的算法来进行上下文学习。两层注意力头使用定性上更复杂的推理时算法——特别是,一种特殊的注意力头,我们称之为“归纳头”,用于进行上下文学习,形成一个对于更大模型而言至关重要的过渡点。
anthropic 认为深入研究 induction head 的工作范式,可以为研究层数更多,结构更复杂的语言模型的 in-context learning ability 奠定基础