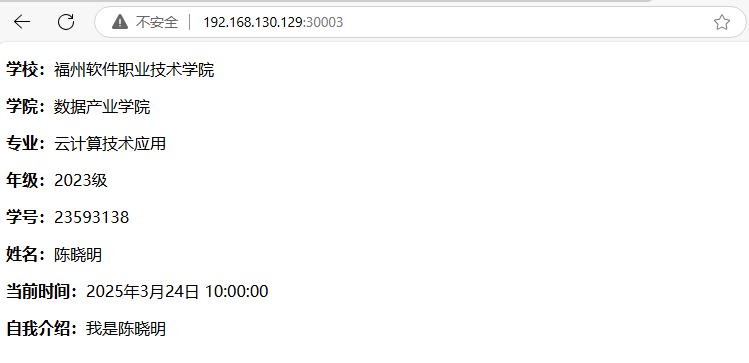
正则中的元字符
在正则表达式里,元字符是具备特殊含义的字符,它们并非代表自身字面意义,而是用于定义匹配模式的规则。以下为你介绍常见的元字符及其作用:
字符匹配类元字符
.:匹配除换行符之外的任意单个字符。例如,正则表达式 a.c 可以匹配 abc、a1c、a@c 等字符串,但无法匹配 a\nc。
\d:匹配任意一个数字字符,等价于 [0-9]。比如,正则表达式 \d 能匹配 0 到 9 中的任意一个数字。
\D:匹配任意一个非数字字符,是 \d 的取反,等价于 [^0-9]。
\w:匹配任意一个字母、数字或下划线字符,等价于 [a-zA-Z0-9_]。例如,正则表达式 \w 可以匹配 a、5、_ 等字符。
\W:匹配任意一个非字母、数字或下划线的字符,是 \w 的取反,等价于 [^a-zA-Z0-9_]。
\s:匹配任意一个空白字符,包括空格、制表符、换页符等,等价于 [ \t\n\r\f\v]。
\S:匹配任意一个非空白字符,是 \s 的取反,等价于 [^ \t\n\r\f\v]。
数量限定类元字符
*:匹配前面的元素零次或多次。例如,正则表达式 ab* 可以匹配 a、ab、abb 等字符串。
+:匹配前面的元素一次或多次。比如,正则表达式 ab+ 可以匹配 ab、abb 等字符串,但不能匹配 a。
?:匹配前面的元素零次或一次。例如,正则表达式 ab? 可以匹配 a 或 ab。
{n}:匹配前面的元素恰好 n 次。例如,正则表达式 a{3} 只能匹配 aaa。
{n,}:匹配前面的元素至少 n 次。例如,正则表达式 a{2,} 可以匹配 aa、aaa、aaaa 等字符串。
{n,m}:匹配前面的元素至少 n 次,最多 m 次(n 和 m 为非负整数,且 n <= m)。例如,正则表达式 a{2,3} 可以匹配 aa 或 aaa。
位置类元字符
^:匹配字符串的开头。例如,正则表达式 ^abc 只有在字符串以 abc 开头时才能匹配成功。
$:匹配字符串的结尾。例如,正则表达式 abc$ 只有在字符串以 abc 结尾时才能匹配成功。
\b:匹配单词边界,即单词字符(\w)和非单词字符(\W)之间的位置。例如,正则表达式 \bcat\b 可以匹配句子 “I have a cat.” 中的 cat,但不能匹配 “category” 中的 cat。
\B:匹配非单词边界,与 \b 相反。
分组和引用类元字符
():用于创建捕获组,将多个字符组合成一个整体,同时可以捕获匹配到的内容,方便后续引用。例如,正则表达式 (ab)+ 可以匹配 ab、abab 等字符串,并且可以通过捕获组提取出每次匹配的 ab。
|:表示或的关系,用于匹配多个模式中的任意一个。例如,正则表达式 a|b 可以匹配 a 或者 b。