一种新的图像生成范式正在崛起,它不再依赖传统的扩散过程,而是用语言的方式“写”出图像。
2025年3月,OpenAI 在更新 GPT-4o 的同时,低调上线了其“原生图像生成”功能。这一功能被嵌入到 GPT-4o 的多模态架构中,与文本、音频等能力无缝协同,带来了显著提升的图像生成质量、可控性和交互能力。
本文将从技术角度,解析 GPT-4o 图像生成的核心机制,及其与传统扩散模型(如 Stable Diffusion)的本质区别。
一、扩散模型 vs 自回归模型(diffusion model vs autoregressive model)
目前主流的图像生成技术多基于扩散模型(diffusion models),其典型代表包括 DALL·E 2、Stable Diffusion、Midjourney 等。这类模型的生成过程为:
噪声 + 去噪 ➝ 一步步“复原”出图像。
但这种方式有几个长期存在的痛点:
- ⏳ 推理速度慢(slow inference)
- ❌ 文本控制弱(weak text-image alignment)
- 🔁 上下文无法连续建模(no contextual continuity)
GPT-4o:自回归图像生成(autoregressive image generation)
其基本逻辑与语言模型相似:
将图像离散化为 token,再一块一块按顺序生成图像。
二、图像 Token 化(Tokenization):让图像“语言化”的关键
模型首先需要将图像转换为 token,通常使用 图像 tokenizer(image tokenizer),如:
- VQ-VAE(vector quantized variational autoencoder)
- DALL·E tokenizer
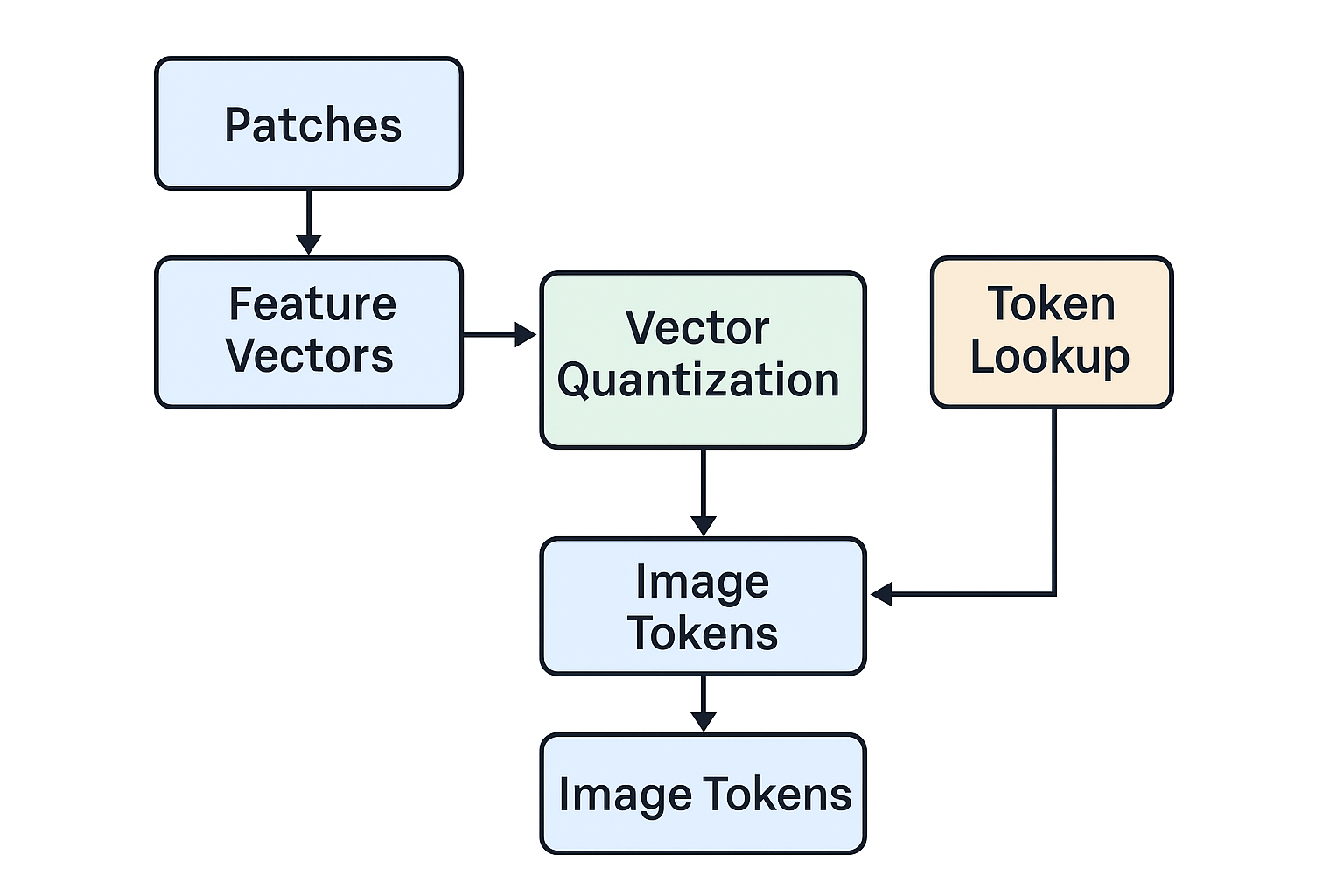
🧱 图像 Token 生成流程:Patch ➝ Token
- 划分 patch(image patches)
- 编码为向量(vector representation)
- 量化为 token(vector quantization ➝ image token)
🔁 Token 解码(Image Decoding):从“语言”回到图像的过程
生成图像后,还需将 token 还原为图像(image reconstruction)。
流程:
- Token lookup(查表找 embedding)
- 恢复 patch 网格(grid reconstruction)
- 每个 patch 解码为图像块(CNN/VAE decoder)
- 拼接还原整张图(final image reconstruction)
🧠 Why Reconstruction Matters?为什么“重建能力(reconstruction ability)”至关重要?
重建能力指的是:
模型是否能准确将 token 表示还原为高质量图像(high-fidelity image reconstruction)。
体现:
- 局部重写(local token rewriting)
- 上下文一致性(contextual consistency)
- 图文语义对齐(semantic alignment)
技术支撑:
- 多尺度建模(multi-scale modeling)
- 视觉词表(visual vocabulary)
- 强化损失函数(reconstruction + CLIP loss)
三、多模态统一建模(Multimodal Joint Training)
GPT-4o 使用统一的 Transformer 架构,将文本、图像、音频统一映射到 共享语义空间(shared embedding space),支持多模态推理和生成。
四、对话式图像生成(interactive image generation)
支持连续对话式修改图像内容,保持上下文一致:
例:
- “画一只柴犬在沙滩上”
- “把天空换成晚霞”
- “再加一只飞翔的海鸥”
无需重画,模型只修改 token 子集 ➝ 重建输出。
五、挑战与优化(challenges & improvements)
| 技术难点 | GPT-4o 的可能应对方式 |
|---|---|
| token 数量过大 | 稀疏 token grid |
| 长程依赖弱 | 多尺度生成、多段式组织 |
| 图文一致性差 | 引入 CLIP-style loss |
| 解码质量弱 | 更强的 decoder 网络结构 |
六、安全与合规(Safety & Policy Control)
包括:
- 聊天模型前置过滤(prompt filtering)
- 输出监控(output blocking)
- 多模态审核器(multimodal auditor)
- 未成年人保护机制(age-based policy)
七、总结:通向“通用生成模型(universal generative model)”的拼图之一
GPT-4o 图像生成展示了通用范式的雏形:
使用统一架构 ➝ 处理多模态输入 ➝ 生成高质量、多轮可控的输出。
✅ 高度集成
✅ 上下文一致
✅ 可交互
✅ 可扩展
一句话总结:
GPT-4o 把“画图”变成了“写图”,正在重塑图像生成的技术范式。