模板编译整体流程
首先我们看一下什么是编译?
所谓编译(Compile),指的是将语言 A 翻译成语言 B,语言 A 就被称之为源码(source code),语言 B 就被称之为目标代码(target code),这个事情谁来做?编译器来做。编译器你也不用想得那么神秘,就是一段程序而已。
完整的编译流程一般包含以下几个步骤:
- 词法分析:就是负责将源码拆解成一系列的词法单元(token)
- 语法分析:将上一步所得到的词法单元组成一颗抽象语法树
- 语义分析:主要就是根据上一步所得到的抽象语法树,进行深度遍历,检查语法规则是否符合要求
- 中间代码生成
- 优化
- 目标代码生成
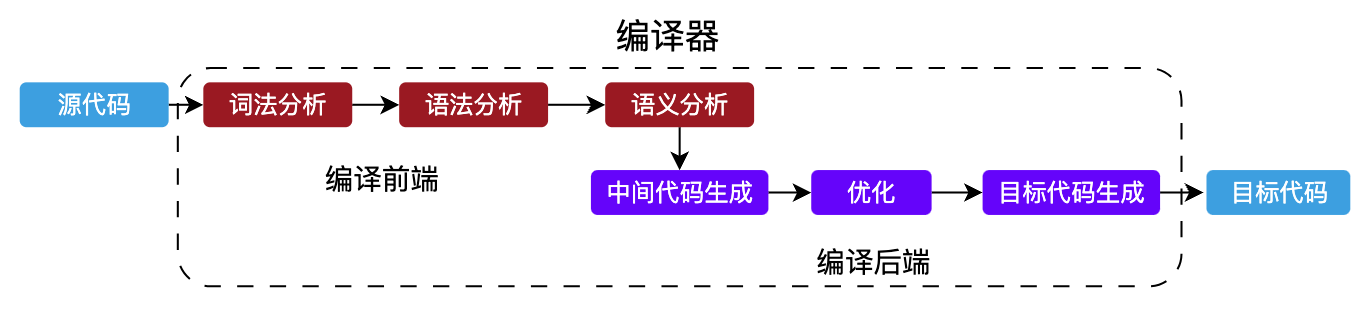
上面的步骤,如果从大的方面去分,那么可以分为 编译前端 和 编译后端。
- 编译前端:所谓编译前端,它通常是和目标平台无关的,仅仅是负责分析源代码
- 编译后端:通常与目标平台有关系
回到 Vue,在 Vue 的模板里面就涉及到了编译的操作:
<template><div><h1 :id="someId">Hello</h1></div>
</template>
编译后的结果是什么?编译后的结果就是渲染函数
function render(){return h('div', [h('h1', {id: someId}, 'Hello')])
}
注意这里,整个编译过程并非一蹴而就,而是经历了一个又一个的步骤,一点一点转换而来的。
整体来讲,整个编译过程如下图:

在编译器内部,实际上又分为了三个东西:
- 解析器:负责将模板解析为对应的模板抽象语法树
- 转换器:负责将上一步所得到模板抽象语法树转为 JS 抽象语法树
- 生成器:负责将上一步所得到的 JS 抽象语法树生成目标代码
通过上面的图,我们还会发现一个很重要的东西,那就是 AST 扮演了非常重要的角色。
AST
什么是 AST 呢?
所谓 AST,英语全称 Abstract Syntax Tree,翻译成中文,就是抽象语法树。
什么又叫抽象语法树?这里我们可以采用分词方式。分为 抽象、语法、树。
先来说树。树的话是数据结构里面的一种,用于表示层次关系的集合。树的基本思想将数据组织成分层结构,每个节点有一个父节点和零个或者多个子节点。
例如:
A/ \B C/ \ \
D E F
上面就是一个树结构,上面的树是一个完全二叉树。
树的结构的这种特点就让它在搜索、排序、存储以及表示层次这些需求方面有广泛的应用,常见的应用场景文档对象模型(DOM)、路由算法、数据库索引等,在这里,我们的抽象语法树,很明显也是一种树结构。
接下来语法树就非常好理解。
var a = 42;
var b = 5;
function addA(d) {return a + d;
}
var c = addA(2) + b;
上面的代码,对于 JS 引擎而言,其实就是一段字符串:
'var a = 42;var b = 5;function addA(d){return a + d;}var c = addA(2) + b;'
JS 引擎首先第一步是遍历上面的字符串,将源码字符串拆解为一个一个的词法单元(词法分析),词法单元又被称之为 token,它是最小的词法单元,词法单元一般就是关键字、操作符、数字、运算符。
例如上面的代码,在进行了词法分析后,会得到如下的 token:
Keyword(var) Identifier(a) Punctuator(=) Numeric(42) Punctuator(;) Keyword(var) Identifier(b) Punctuator(=) Numeric(5) Punctuator(;) Keyword(function) Identifier(addA) Punctuator(() Identifier(d) Punctuator()) Punctuator({) Keyword(return) Identifier(a) Punctuator(+) Identifier(d) Punctuator(;) Punctuator(}) Keyword(var) Identifier(c) Punctuator(=) Identifier(addA) Punctuator(() Numeric(2) Punctuator()) Punctuator(+) Identifier(b) Punctuator(;)
接下来下一步,就是根据这些 token,形成一颗树结构(语法分析):
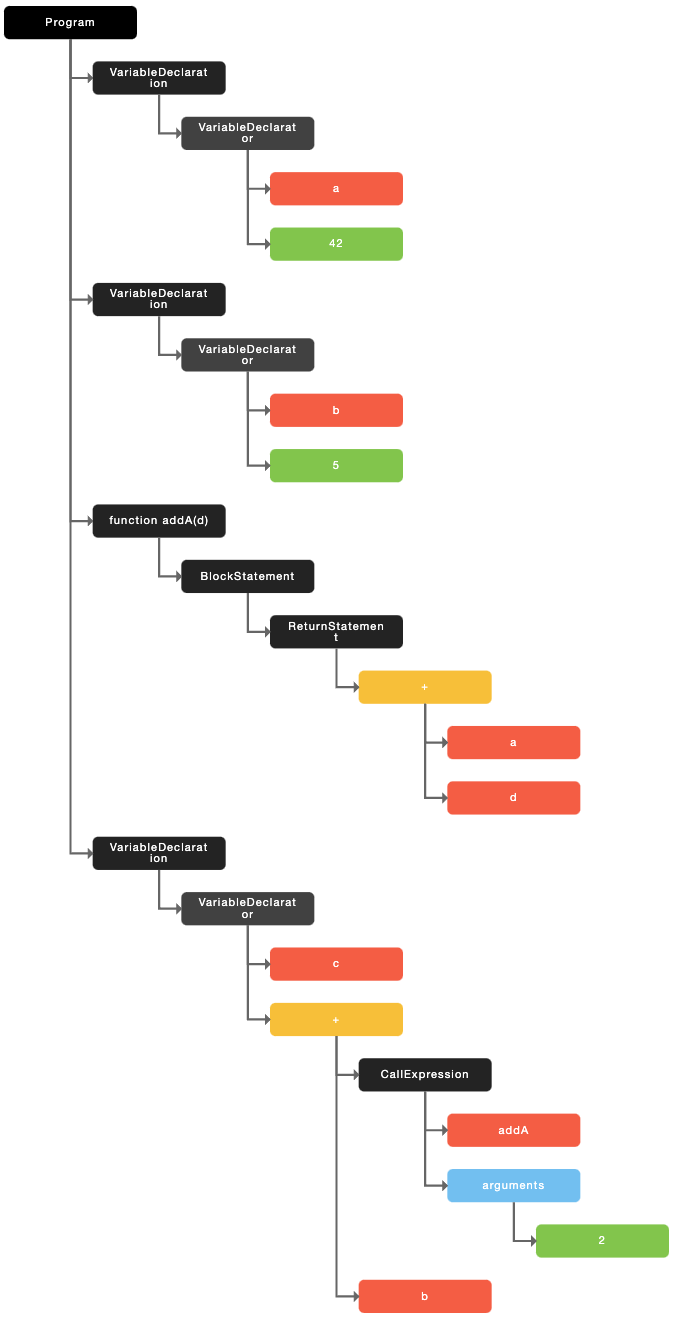
可以在 https://www.jointjs.com/demos/abstract-syntax-tree 或者 https://astexplorer.net/ 看到代码的抽象语法树。
目前我们已经搞懂什么是语法树。
为什么叫做 抽象 语法树 ?
抽象在计算机科学里面,是一种非常重要的思想。这里的抽象和现实生活中的抽象的说法是有区别。现实生活中的抽象往往是指“模糊、含糊不清、难以理解”,例如“他说的话很抽象”。
计算机科学里面的抽象,指的是将关键部分从细节中分离出来,忽略不必要的细节,专注问题的关键方面。
例如面向对象编程里面,类其实就是对对象的一种抽象,类描述了对象的关键信息(有哪些属性,有哪些方法),再举一个例子,比如接口,在定义接口的时候,只会规定这个接口里面有哪些方法,不需要关心内部具体的实现。
回到我们的抽象语法树,在形成树结构的时候,同样会忽略一些不重要的,非关键的信息(比如空格、换行符),只会将关键的部分(关键字、标志符、运算符)生成到树结构里面。
理解 AST 非常重要,在开发中但凡涉及到 转换 的场景,都是基于抽象语法树来运作的。
- Typescript
- Babel
- Prettier
- ESLint
解析器
解析器的核心作用是负责将模板解析为 AST
<template><div><h1 :id="someId">Hello</h1></div>
</template>
对于解析器来讲,就是一段字符串:
'<template><div><h1 :id="someId">Hello</h1></div></template>'
接下来我们的工作重点,就是解析这段字符串。
这里涉及到了 有限状态机 的概念。
FSM
英语全称 Finite State Machine,翻译成中文就是有限状态机,它首先会定义一组状态,然后会定义状态之间进行转移的事件。
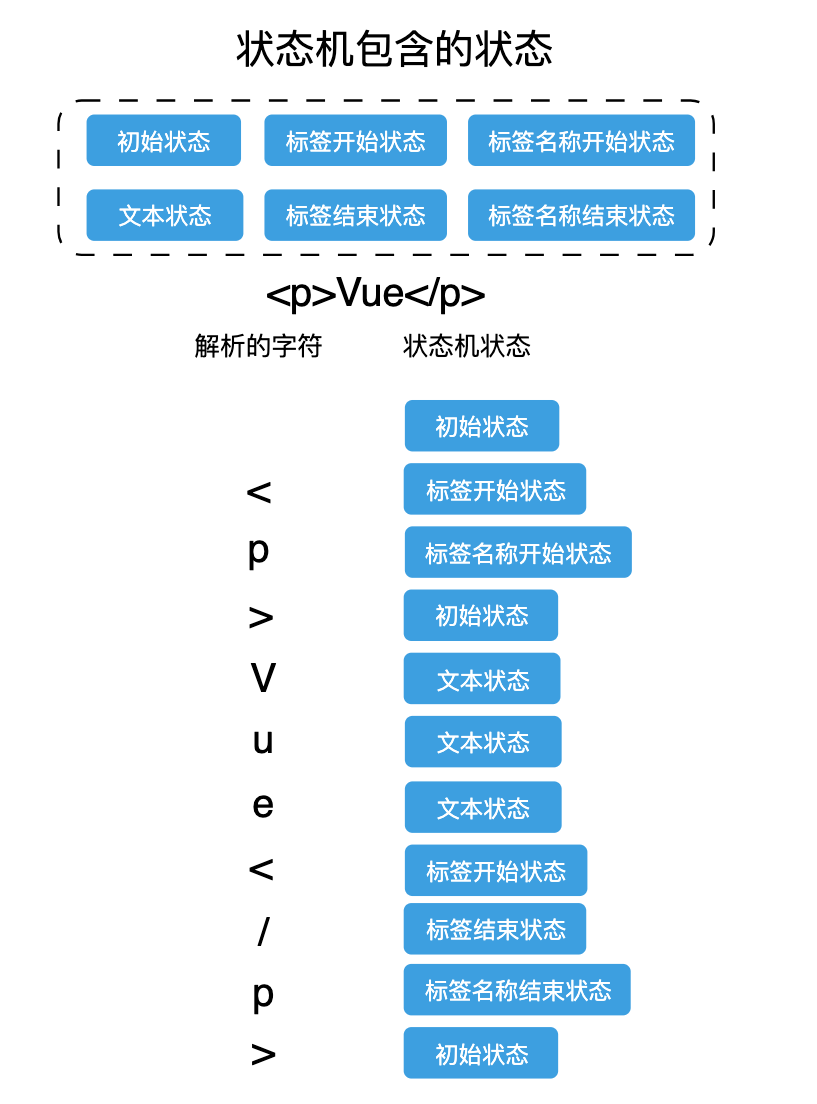
来看一个具体的例子:
'<p>Vue</p>'
那么整个状态的迁移过程如下:
- 状态机一开始处于 初始状态。
- 在初始状态下,读取字符串的第一个字符 < ,然后状态机的状态就会更新为 标签开始状态。
- 读取下一个字符 p,由于 p 是字母,那么状态机的状态就会更新为 标签名称开始状态。
- 读取下一个字符 >,状态机会回归为 初始状态。
- 读取下一个字符 V,状态机的状态为 文本状态
- 下一个字符 u,状态机的状态为 文本状态
- 下一个字符 e,状态机的状态为 文本状态
- 读取下一个字符 < ,此时状态机会进入到 标签开始状态
- 读取下一个字符 / ,状态机的状态会变为 标签结束状态
- 读取下一个字符 p,状态机的状态为 标签名称结束状态
- 最后是 > ,状态机重新回到 初始状态
具体如下图所示:
实际上,我们最熟悉的 HTML,浏览器引擎在内部进行解析的时候,也是通过有限状态机进行解析的。
接下来我们落地到代码,大致就如下:
const tempalte = '<p>Vue</p>';
// 首先需要定义一些状态
const state = {initial: 1, // 初始状态tagOpen: 2, // 标签开始状态tagName: 3, // 标签名称开始状态text: 4, // 文本状态tagEnd: 5, // 标签结束状态tagEndName: 6 // 标签名称结束状态
}function tokenize(str) {let currentState = state.initial; // 一开始是初始状态const chars = []; // 用于缓存字符const tokens = []; // 用于存储最终分析出来的 tokens,并且作为函数的返回值while(str){const char = str[0]; // 先取出第一个字符switch(currentState) {case state.initial: {// ...str = str.slice(1); // 消费一个字符}case state.tagOpen: {// ...}}}return tokens;
}
构造 AST
到目前为止,我们只是将模板解析为了一个一个的 token,任务只完成了一半,接下来需要根据上一步所得到的 tokens 来构造 AST 树。
构造 AST 的过程其实就是就是对 tokens 列表进行扫描的过程,从列表的第一个 token,按照顺序进行扫描,直到列表中所有 token 都被处理完毕。
在这个过程中,我们需要维护一个栈(这个也是一种数据结构),这个栈的作用主要使用用于维护元素间的父子关系,每遇到一个开始标签的节点,就会构造一个 Element 类型的 AST 节点,压入到栈里面。
来看一个具体的例子:
'<div><p>Vue</p><p>React</p></div>'
上面的字符串,对应的解析出来的 tokens 为:
[{"type": "tag","name": "div"},{"type": "tag","name": "p"},{"type": "text","content": "Vue"},{"type": "tagEnd","name": "p"},{"type": "tag","name": "p"},{"type": "text","content": "React"},{"type": "tagEnd","name": "p"},{"type": "tagEnd","name": "div"}
]
接下来我们就需要扫描这个 tokens
- 一开始会有一个栈,这个栈里面只有 Root 节点 [ Root ]
- 首先是 div tag,创建一个 Element 类型的 AST 节点,压栈,当前的栈为 [ Root, div ],div 就作为 Root 的子节点

- 接下来是 p tag,创建一个 Element 类型的 AST 节点,压栈,当前的栈为 [ Root, div, p ],p 作为 div 的子节点。

- 接下来是 Vue text 文本节点,此时就会创建一个 Text 类型的 AST 节点,作为 p 的子节点

- 接下来是 p tagEnd,发现这是一个结束标签,此时就会将 p 出栈,当前的栈为 [ Root, div ]
- 接下来是 p tag,创建一个 Element 类型的 AST 节点,压栈,当前的栈为 [ Root, div, p ],p 作为 div 的子节点。

- 接下来是 React text 文本节点,此时就会创建一个 Text 类型的 AST 节点,作为 p 的子节点

- 接下来是 p tagEnd,发现这是一个结束标签,此时就会将 p 出栈,当前的栈为 [ Root, div ]
- 接下来是 div tagEnd,发现这是一个结束标签,此时就会将 div 出栈,当前的栈为 [ Root ]
最后落地到代码:
function parse(str) {// 首先对模板进行 token 解析,得到对应的 tokens 数组const tokens = tokenize(str)// 创建 Root 根 AST 节点的const root = {type: 'Root',children: []}// 创建 elementStack 栈,一开始只有 Root 根节点const elementStack = [root]// 直到 tokens 数组被全部扫描完才会推出while (tokens.length) {// 获取当前栈顶点作为父节点const parent = elementStack[elementStack.length - 1]// 当前扫描的 tokenconst t = tokens[0]// 根据 token 的不同类型,创建不同的 AST 节点switch (t.type) {case 'tag':// 创建对应的 Element 类型的 AST 节点const elementNode = {type: 'Element',tag: t.name,children: []}// 将其添加到父级节点的 children 中parent.children.push(elementNode)// 将当前节点压入栈elementStack.push(elementNode)breakcase 'text':// 创建文本类型的 AST 节点const textNode = {type: 'Text',content: t.content}// 将其添加到父级节点的 children 中parent.children.push(textNode)breakcase 'tagEnd':// 遇到结束标签,将当前栈顶的节点弹出elementStack.pop()break}// 消费已经扫描过的 tokentokens.shift()}return root
}
通过上面的代码,最终就会得到如下的 AST 树结构:
{"type": "Root","children": [{"type": "Element","tag": "div","children": [{"type": "Element","tag": "p","children": [{"type": "Text","content": "Vue"}]},{"type": "Element","tag": "p","children": [{"type": "Text","content": "Template"}]}]}]
}
Code: FSM
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8" /><meta name="viewport" content="width=device-width, initial-scale=1.0" /><title>Document</title></head><body><script>const template = `<div><p>Vue</p><p>React</p></div>`;const State = {initial: 1,tagOpen: 2,tagName: 3,text: 4,tagEnd: 5,tagEndName: 6,};function isAlpha(char) {return (char >= "a" && char <= "z") || (char >= "A" && char <= "Z");}function tokenize(str) {let currentState = State.initial;const chars = [];const tokens = [];while (str) {const char = str[0];switch (currentState) {case State.initial:if (char === "<") {currentState = State.tagOpen;str = str.slice(1);} else if (isAlpha(char)) {currentState = State.text;chars.push(char);str = str.slice(1);}break;case State.tagOpen:if (isAlpha(char)) {currentState = State.tagName;chars.push(char);str = str.slice(1);} else if (char === "/") {currentState = State.tagEnd;str = str.slice(1);}break;case State.tagName:if (isAlpha(char)) {chars.push(char);str = str.slice(1);} else if (char === ">") {currentState = State.initial;tokens.push({type: "tag",name: chars.join(""),});chars.length = 0;str = str.slice(1);}break;case State.text:if (isAlpha(char)) {chars.push(char);str = str.slice(1);} else if (char === "<") {currentState = State.tagOpen;tokens.push({type: "text",content: chars.join(""),});chars.length = 0;str = str.slice(1);}break;case State.tagEnd:if (isAlpha(char)) {currentState = State.tagEndName;chars.push(char);str = str.slice(1);}break;case State.tagEndName:if (isAlpha(char)) {chars.push(char);str = str.slice(1);} else if (char === ">") {currentState = State.initial;tokens.push({type: "tagEnd",name: chars.join(""),});chars.length = 0;str = str.slice(1);}break;}}return tokens;}console.log(tokenize(template));</script></body>
</html>
![[P] 结对项目:影蛇舞](https://img2024.cnblogs.com/blog/3613163/202503/3613163-20250329192025371-876168752.jpg)