Preface
This note only introduce the essential concepts about Static Timing Analysis, which not contains:
- Async, i.e. remove, recover
- Timing conceptions, i.e. false path, multi cycle path etc.
- Advance timing domain knowledge
- POCV, MCMM etc.
什么是 STA
由于时钟频率越快,芯片中的逻辑单元在单位时间内能够完成的操作就越多,所以频率与芯片性能成正相关。而芯片设计需要在 PPA 之间 tradeoff,那么如何才能知道一枚芯片正常工作的频率极限到底是多少呢?这就引入了 STA 静态时序分析的概念。
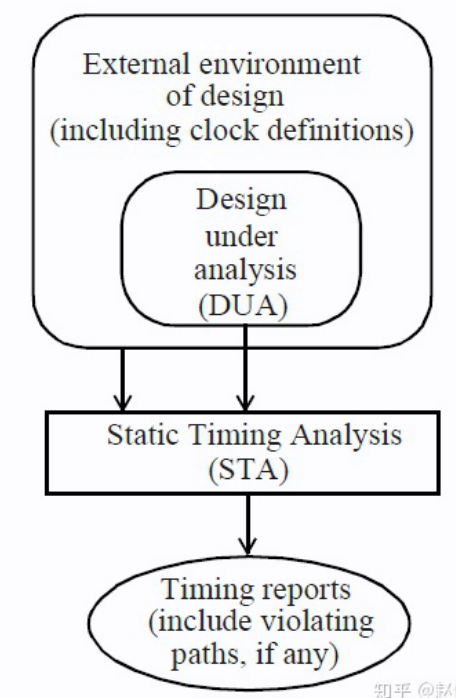
STA 用于验证设计是否能够安全运行在给定的时钟频率下且没有时序违例。STA存在以下特点:
- Pros
- 无需输入激励仿真
- 完备的时序检查
- Cons
- 无法处理异步时序
STA 应用场景
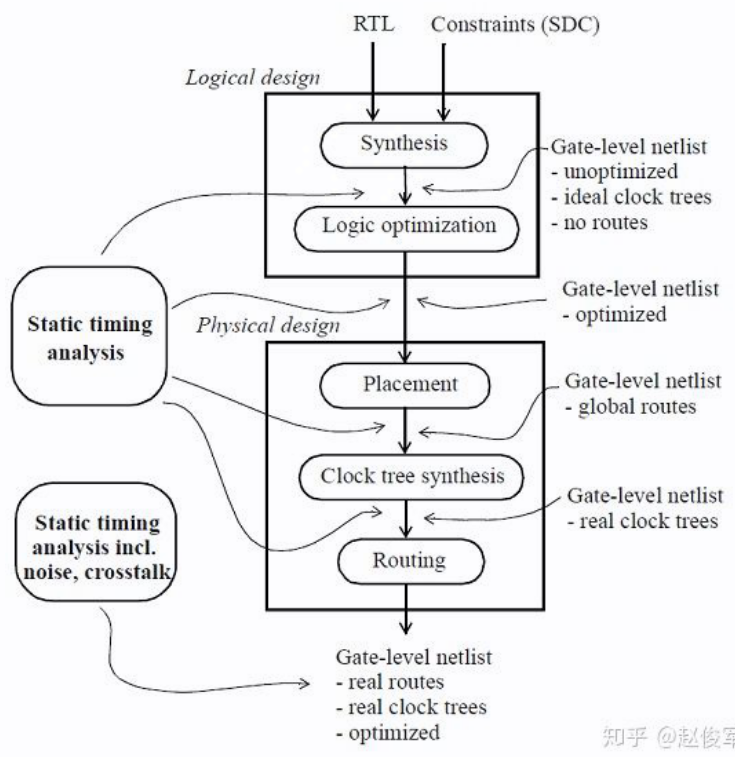
STA 可以应用于 PD 多个阶段,并且分别具有不同特点,如:
- synthesis: 在逻辑设计阶段,由于没有与布局有关的物理信息,因此可以假设互连线是理想状态的,此阶段会更关注查看导致最差路径的逻辑。在这个阶段使用的另一种技术是采用线负载模型(wireload model)来估算互连线的长度, 线负载模型会基于逻辑单元的扇出提供一个估计的RC值。
- Pre-CTS: 在物理设计的一开始,时钟树被认为是理想的,即它们具有零延迟。而在 CTS 后,时钟则具有实际的 propagate delay
- Pre-Route: 在实际布线前,STA 用于计算延迟的金属线寄生 RC 为估计值。

Cell
单元可以是标准单元、IO缓冲器或者是如USB内核这样的复杂 IP。除时序信息外,库单元描述中还包含一些其它属性,例如单元面积和功能,这些属性与时序无关,但在RTL综合(synthesis)过程中会用到。
引脚电容
单元的每个输入和输出都可以在引脚(pin)上指定电容。在大多数情况下,仅为单元输入引脚指定电容,而不为输出引脚指定电容,即大多数单元库中的输出引脚电容为0

上面的示例展示了输入INP1引脚电容值的一般规格(specification)。在最基本的格式中,引脚电容被指定为单个值(在上面的示例中为0.5个单位)。电容单位通常为皮法拉(pF),一般在库文件的开头指定。单元描述中还可以为rise_capacitance(0.5个单位)和fall_capacitance(0.45个单位)分别指定值,这些值是指引脚INP1上发生电平上升和下降跳变时的值。也可以将rise_capacitance和fall_capacitance的值指定为范围,并在描述中指定下限值和上限值。
驱动强度
输入引脚电容定义在 liberty 中,而输出引脚电容则由该单元驱动的所有下级单元所决定。当CMOS单元切换电平状态时,切换的速度取决于输出引脚上的电容被充放电的速度。
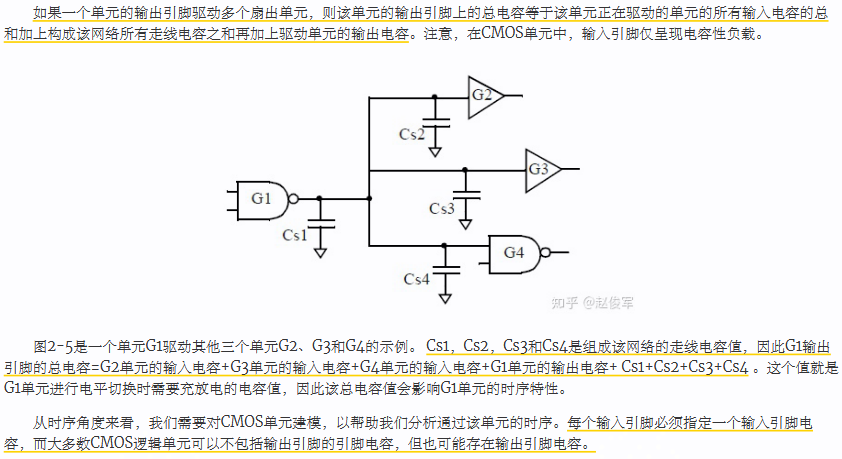
通常来说,单元驱动强度决定了可以驱动的最大电容负载,最大电容负载又决定了扇出的最大数量,即可以驱动多少个其他单元。较高的输出驱动对应较低的输出上拉/下拉电阻,这使单元可以在输出引脚上对较大的负载进行充电和放电。
- 驱动强度越大则单元面积越大,且
max_cap也越大。 - 驱动强度越大,对应的输出电阻越小,延迟也就越小。
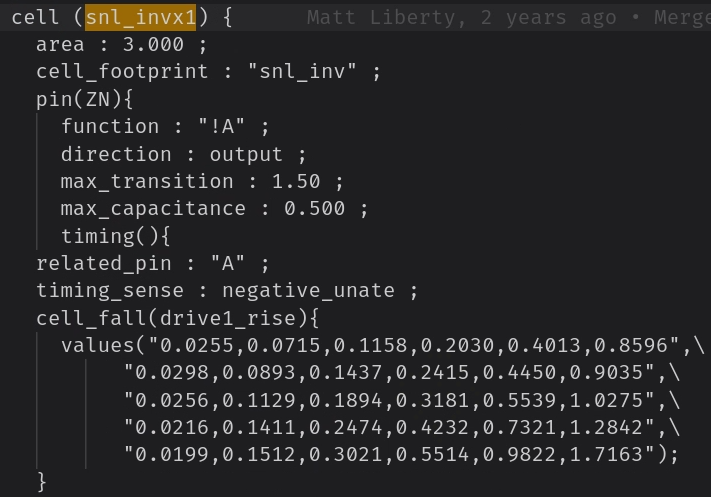
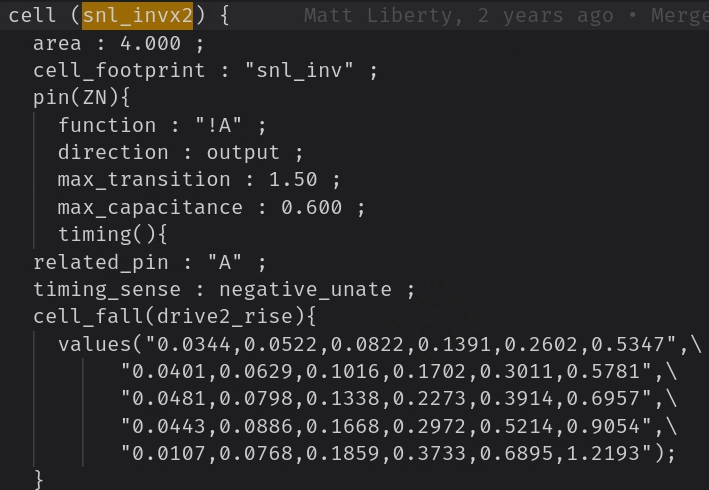
- 如果标准单元库中只有小驱动强度的标准逻辑单元,则对时序有何影响?
- 当整个库只有小驱动单元时,首先想到的是每个单元的驱动能力弱,输出电阻更大。
- 如果一个反相器的驱动强度小,那么它能够驱动的最大负载电容也较小。如果设计中某些节点必须驱动较大的电容,比如长线或高扇出网络,这时候小驱动单元可能无法满足需求,从而导致建立时间或保持时间违规。
Propagation Delay
单元的传播延时(propagation delay)是由电平切换波形上的某些测量点定义的。这些阈值的单位是Vdd或电源的百分比,对于大多数标准单元库,通常将50%阈值用于计算延时。
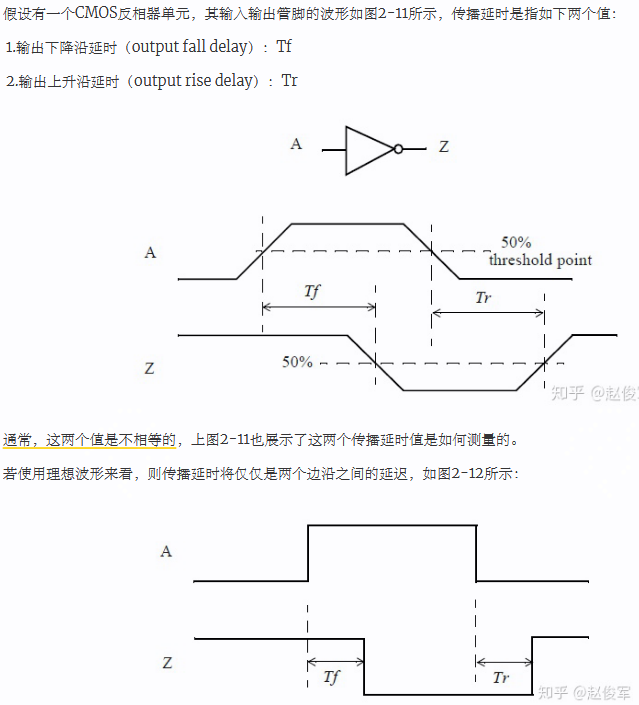
这里的传播延时按照输出信号的 rise/fall 分为两种(不相等):
- output rise delay: 从输入信号到达下降沿阈值点开始,到输出信号到达上升沿阈值点结束的这段时间延迟
- output fall delay:与 output rise delay 相反
Slew
压摆率(slew rate)的定义是电压转换速率。在 STA 中,通常会根据电平转换的快慢来衡量上升波形或下降波形。压摆(slew)通常是根据转换时间(transition time)来定义的,转换时间是指信号在两个特定电平之间转换所需要的时间。请注意,转换时间实际上就是压摆率的倒数,因此转换时间越大,压摆率就越低,反之亦然。
一般使用指定的阈值电压来规定过渡时间计算的起点和终点

Slew rate 和 Slew 非同一件事。Slew 为 transition 而 Slew rate 为其倒数。
Timing Arc
时序弧描述了信号在单元引脚之间传输的延迟以及信号的跳变情况。
- 像与门、或门、与非门、加法器这些组合逻辑单元,每个输入引脚到每个输出引脚都存在一条时序弧
- 而像触发器之类的时序逻辑单元除了有从时钟引脚到输出引脚的时序弧,还有相对于时钟引脚的数据引脚时序约束(timing constraint)
每个时序弧都具有特定的时序敏感(timing sense), 即输出如何针对输入的不同跳变类型而变化。在非单边(non-unate)时序弧中,仅仅从一个输入引脚的跳变方向是无法确定输出引脚电平将如何跳变的,还要取决于其他输入引脚的状态。
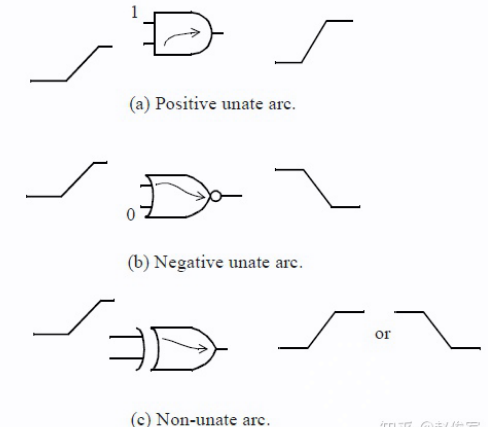
Timing Model
逻辑单元的时序模型(timing model)旨在为设计中的各种单元实例(instance)提供准确的时序信息。
- 每个时序弧都有时序模型
- 时序模型由详细电路仿真所得
对于一个 inverter 而言其存在两种延迟:分别为输出上升沿延时 $T_{r}$ 和输出下降沿延时 $T_{f}$

通过 inverter 的 delay and output transition 主要取决于:
- 输出负载,即反相器输出引脚上的电容负载
- 输入信号的过渡(transition)时间
- 晶体管版图设计:可忽略
一个逻辑单元的信号输入,如同在水槽上来了水流,水流首先推动蓝色水车运转(类似于输入变换时间),然后把水池(输出电容)灌满后,才能推动红色水车的运作(下一个逻辑单元)。
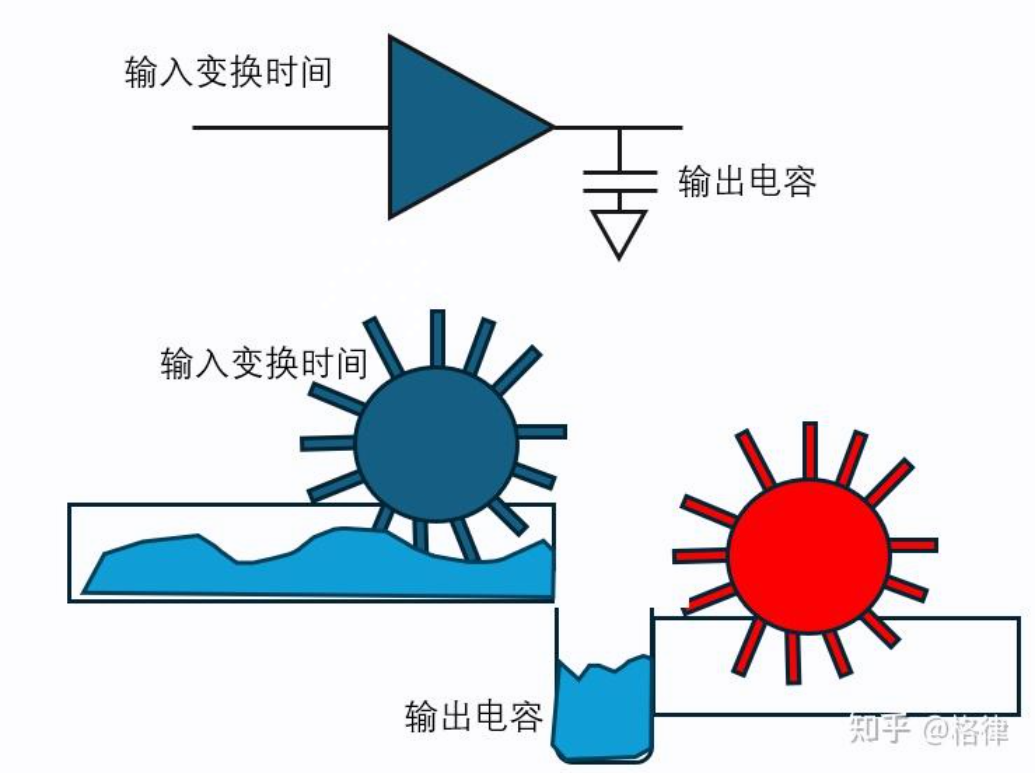
延迟值与负载电容有直接关系:负载电容越大,延迟越大。在大多数情况下,延迟也会随着输入信号过渡时间的增加而增加。PS: 非绝对
NLDM
逻辑单元的时序模型可以简单理解为以 input slew 和 output load 为参数的函数,但简单的线性时序模型在应用于亚微米技术时并不准确。因此,目前大多数单元库都使用更复杂的非线性延迟模型(non-linear delay model)
大多数单元库都包括表格模型(table model),用于为单元的各种时序弧指定延迟并进行时序检查。这些表格模型被称为 NLDM (Non-Linear Delay Model),可用于延迟、输出压摆计算或其他时序检查。表格模型中提供了:在单元输入引脚处输入过渡时间和输出引脚处输出负载电容的各种组合下通过单元的延迟。

根据延迟表,输入下降过渡时间为0.3ns且输出负载为0.16pf时,反相器的上升延迟为0.1018ns。由于输入的下降沿跳变导致反相器输出的上升沿跳变,因此当输入引脚发生下降沿跳变时,应该去查询cell_rise延迟表。注意,表格模型也可以是3维的,例如一个具有互补输出Q和QN的触发器。
NLDM模型不仅可以用于计算延迟,而且还可用于计算逻辑单元输出引脚的过渡时间,该时间同样由输入过渡时间和输出负载电容来表征。
所以通过 NLDM 模型可计算:
- Rise Delay
- Fall Delay
- Rise Slew
- Fall Slew
另外,如果没有表中对应索引,可通过插值计算结果。
Derate
skip it
压摆值(slew)基于的是在库中指定的测量阈值点,大多数上一代的库(0.25um或更旧的库)都使用10%和90%(对应波形的线性部分)作为压摆 (或称过渡时间)的测量阈值点。
随着技术的发展,实际波形最线性的部分通常在30%至70%之间。因此,大多数新一代时序库都将压摆测量阈值点指定为Vdd的30%和70%。但是,由于之前测得的过渡时间在10%至90%之间,因此在填充库时,通常将测得的30%至70%的过渡时间加倍,这由压摆降额系数(slew derate factor)指定,通常指定为0.5。压摆测量阈值点为30%和70%且压摆降额系数为0.5,等效于测量阈值点为10%和90%。
组合逻辑单元
对于两输入与门:共有四种 delay 以及四种 output transition
- 上升下降 * 两个输入引脚 = 4
- 而在 FPGA 中,每个逻辑单元的所有延时信息基本是固定的,所以每一种逻辑单元都分别拟合一个固定的延迟(例如LUT是0.1ns,DSP是1.3ns等)
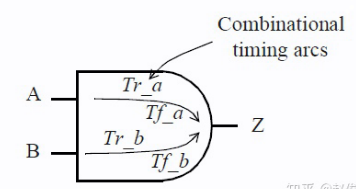
通用组合逻辑块
考虑以下这个具有三输入和两输出的通用组合逻辑块(General Combinational Block):
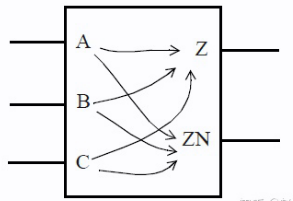
像这样的组合逻辑块可以具有多个时序弧。通常,从块的每个输入到每个输出都有一条时序弧。
时序逻辑单元
时序逻辑单元的时序弧如下:
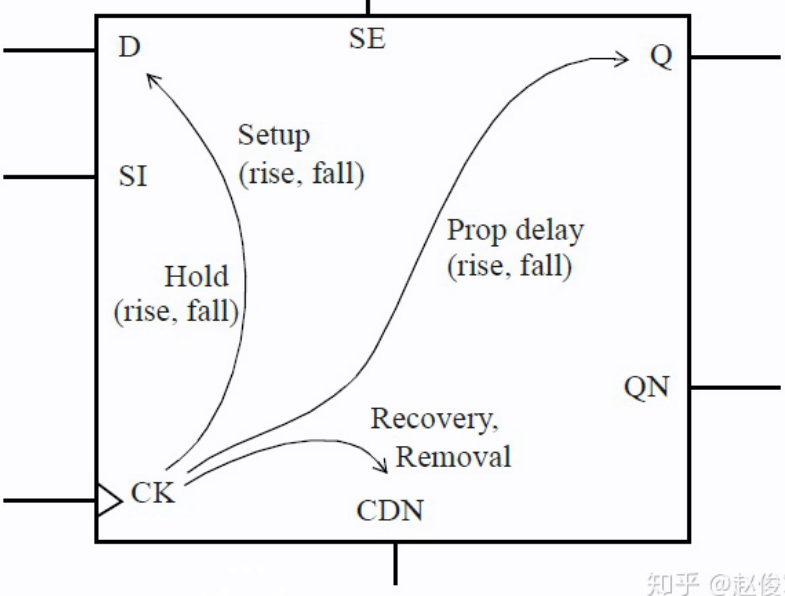
对于引脚 D, SI 和 SE 的同步输入信号,存在以下时序弧(both rise and fall):
- 建立时间检查时序弧
- 保持时间检查时序弧
对于引脚 Q 的同步输出信号,存在以下时序弧:
- CK to Q or QN Propagation delay arc
对于引脚 CDN 的异步输入信号,存在以下时序弧:
- 移除时间检查时序弧
- 恢复时间检查时序弧
此外,对于时钟引脚和异步引脚还存在
- 脉冲宽度时序检查
Setup and Hold
建立时间和保持时间的同步时序检查用于确保数据能够正确通过时序单元传播。这些时序检查可验证输入的数据在时钟有效沿上是否为确定的逻辑状态,并且在有效沿上将正确的数据锁存下来。
二维表格模型是根据约束引脚constrained_pin(D)和相关引脚related_pin(CK)处的过渡时间确定的。
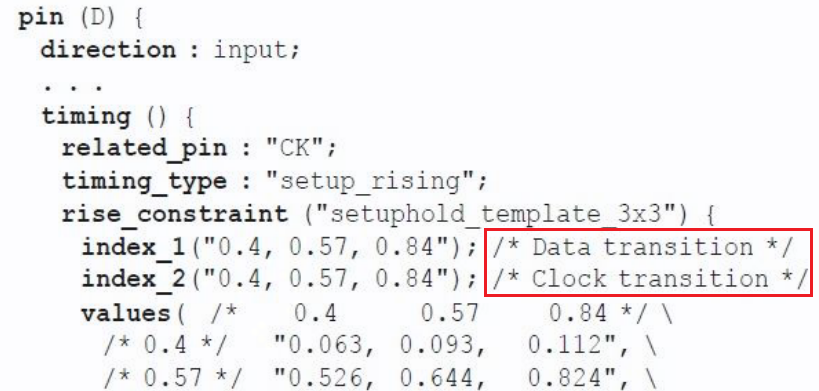
setup and hold 详细内容在后文介绍。
异步时序检查
SKIP
状态相关的时序模型
SKIP
输入和输出之间的时序弧取决于模块中其他引脚的逻辑状态
黑盒的接口时序模型
SKIP
高级时序模型
SKIP
非线性延迟模型(NLDM)这类的时序模型是基于输出负载电容和输入过渡时间来表示通过时序弧的延迟的。实际上,单元输出的负载不仅包括电容还应当包括互连电阻(interconnect resistance)。
由于NLDM方法假设输出负载为纯电容,因此互连电阻成为了一个问题。即使互连电阻不为零,但当互连电阻的影响较小时,仍使用了这些NLDM模型。在互连电阻存在的情况下,延迟的计算方法通过在单元的输出端获得等效的有效电容(effective capacitance)来改进NLDM模型。延迟计算工具中使用的“有效”电容法获得的等效电容可保证单元输出延迟与具有RC互连的单元输出延迟相同。
由于 NLDM 无法很好地处理互连电阻带来的误差,所以提出了如 CCS (Composite Current Source) 等更高级的时序模型。
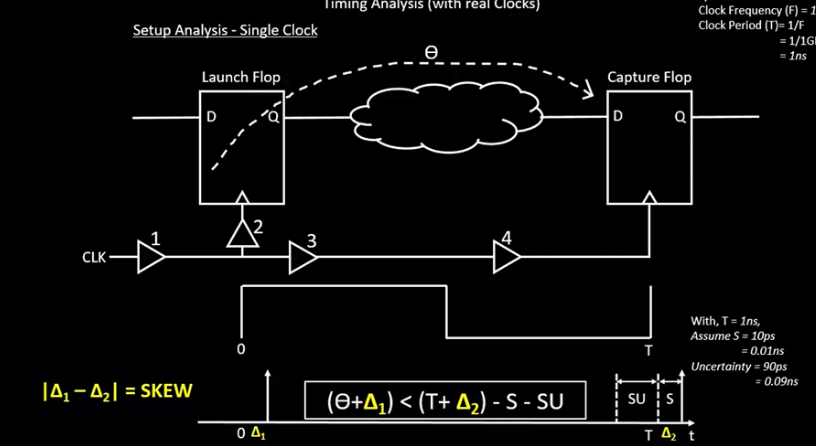
Clock
Skew
偏斜(skew)是指两个或多个信号(数据或者时钟)之间的时序之差。例如,如果一个时钟树(clock tree)有500个终点, 并且有50ps的偏斜,则意味着最长时钟路径和最短时钟路径之间的延迟差为50ps。
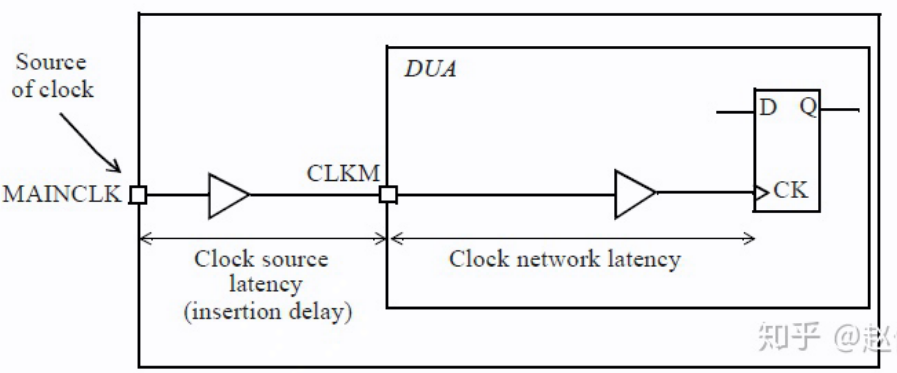
时钟树的起点通常是定义时钟的节点,时钟树的终点通常是同步元件(例如触发器)的时钟引脚。时钟延迟(clock latency: Source + Insertion)是指从时钟源到终点所花费的总时间,时钟偏斜(clock skew)是指到达不同时钟树终点的时间差。
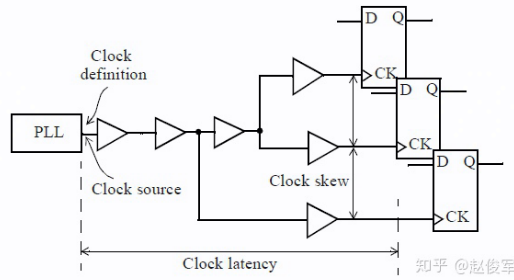
理想时钟树是假定时钟源具有无限驱动力,时钟可以无延迟地驱动无限个终点。另外,假定时钟树中存在的任何逻辑单元都具有零延迟(zero delay)。在逻辑设计的早期阶段,STA通常使用理想的时钟树来执行,因此分析的重点是数据路径 (data path)。通过 set_clock_latency 可显示指定时钟树延迟。
Uncertainty
set_clock_uncertainty 命令为时钟沿的出现指定了一个窗口。时钟边沿时序的不确定性将考虑多个因素,例如时钟周期抖动 (jitter) 和用于时序验证的额外裕量 (slack)。实际上是不存在理想时钟的,所有时钟都具有一定的抖动量,并且在指定时钟不确定度时应包括时钟周期抖动。
在时钟树被实现(implement)之前,时钟不确定度还必须包括预期的时钟偏斜。而保持时间检查不需要将时钟抖动包括在内,因此通常为保持时间检查指定较小的时钟不确定度。
实际中的时钟信号
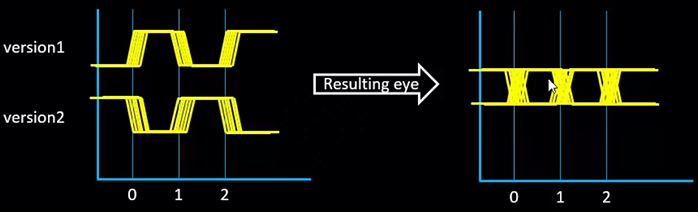
实际的时钟信号包括上升沿和下降沿:
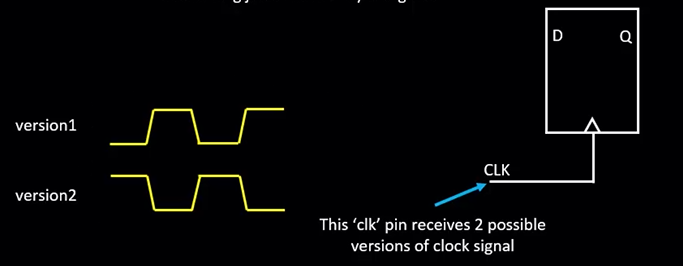
将两种时钟信号结合得到理想情况下的眼图,此时为只有 transition 的理想时钟:
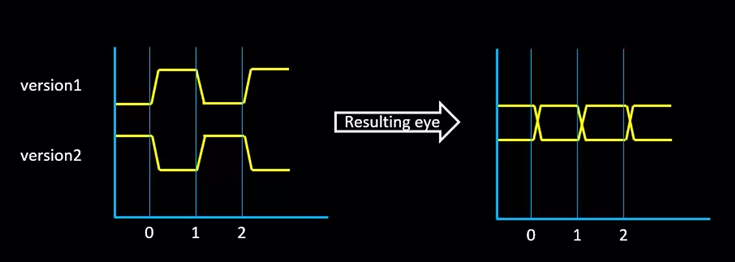
但实际上时钟信号存在不同的到达时间(jitter),此时的眼图为:
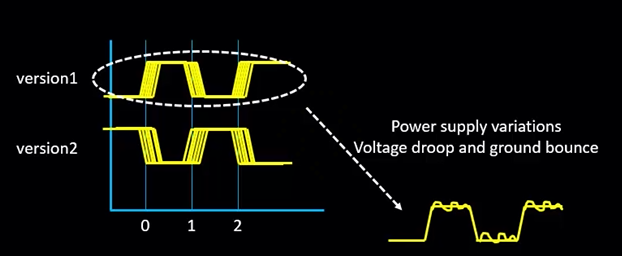
此外,时钟还会因为 Power Supply variations cause voltage drop and ground bounce.
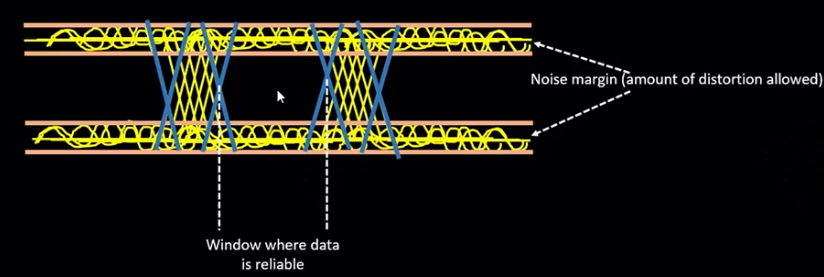
最终得到实际情况下的时钟信号:

针对电平波动,定义 noise margin, 允许一定失真:

时钟信号无抖动区域称为 window where data is reliable:
而时钟信号存在抖动的区域称为 jitter: Jitter has to be accounted for in the timing reports. We model this using one more parameter called Uncertainty.
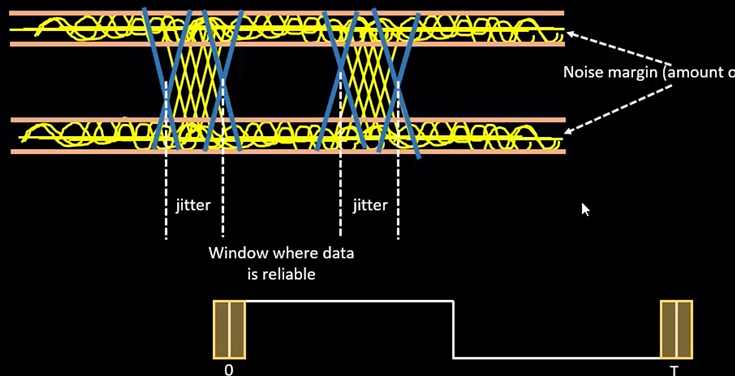
Example : Uncertainty = 90ps = 0.09ns
Clock Domain
一个时钟通常驱动许多触发器,由同一时钟驱动的一组触发器称为其时钟域(clock domain)。下图即存在两个时钟域:
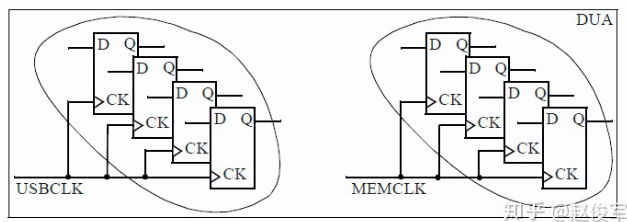
需要关注一个问题:两个时钟域是相关的还是彼此独立的?答案取决于是否存在一条从一个时钟域开始并在另一时钟域结束的数据路径,如果没有这样的路径,我们可以肯定地说这两个时钟域彼此独立,这意味着没有时序路径从一个时钟域开始而在另一时钟域结束。
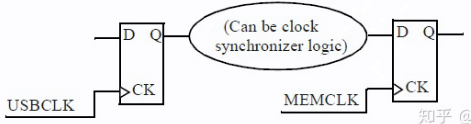
若存在跨时钟域的数据路径(如下图所示),则必须确定这些路径是否为真实(real)路径:例如一个两倍频时钟驱动的触发器发起数据,再由一倍频时钟驱动的触发器捕获数据,这条路径就是一条真实路径。
而伪路径(false path)的一个例子是设计人员将时钟同步器(clock synchronizer)逻辑明确放置在两个时钟域之间。在这种情况下,即使好像存在从一个时钟域到下一时钟域的时序路径,但这也不是真实的时序路径,因为数据没有被约束要在一个时钟周期之内通过同步器逻辑传播。这样的路径称为伪路径(不是真实的),因为是由时钟同步器来确保数据正确地从一个时钟域传递到另一个时钟域。
- false path belongs to timing exceptions, so skip it.
- 在设计中,有些路径是不可能存在的,或者不可能发生的,这种路径称为伪路径。伪路径通常发生在异步电路以及跨时钟域;或者电路内部逻辑复杂,推导后发现其实是常量,不会发生变化
实际出现跨时钟域的情况往往是双向的,即从USBCLK时钟域到MEMCLK时钟域,以及从 MEMCLK时钟域到USBCLK时钟域,这两种情况都需要在STA中正确理解和处理。
SDC
正确的约束对于分析STA结果很重要,只有准确指定设计环境,STA分析才能够识别出设计中的所有时序问题。STA的准备工作包括设置时钟、指定IO时序特性以及指定伪路径和多周期路径。
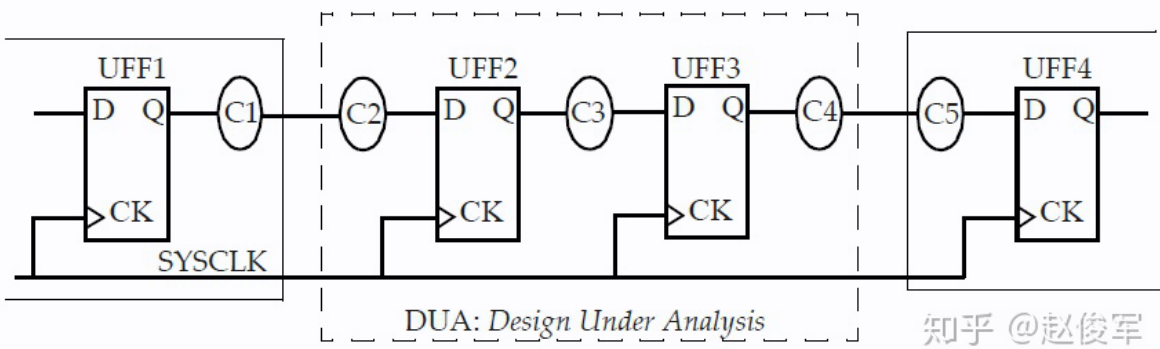
为了对这种设计执行STA,需要指定触发器的时钟、以及进入设计和退出设计的所有路径的时序约束。
指定时钟
要定义时钟,我们需要提供以下信息:
- 时钟源(Clock source):它可以是设计的端口,也可以是设计内部单元的引脚(通常是时钟生成逻辑的一部分)。
- 周期(Period):时钟的周期。
- 占空比(Duty cycle):高电平持续时间(正相位)和低电平持续时间(负相位)。
- 边沿时间(Edge times):上升沿和下降沿的时刻。
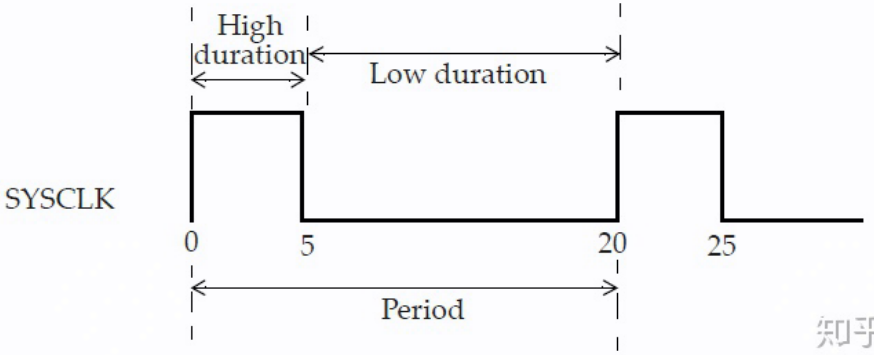
创建时钟的例子:create_clock -name SYSCLK -period 20 -waveform {0 5} [get_ports SCLK];该时钟名为SYSCLK,并在端口SCLK上定义。SYSCLK的周期指定为20个单位,如果未指定,默认时间单位为纳秒(通常,时间单位会在技术库中进行指定)。waveform中的第一个自变量指定出现上升沿的时刻,第二个自变量指定出现下降沿的时刻。
时钟不确定度
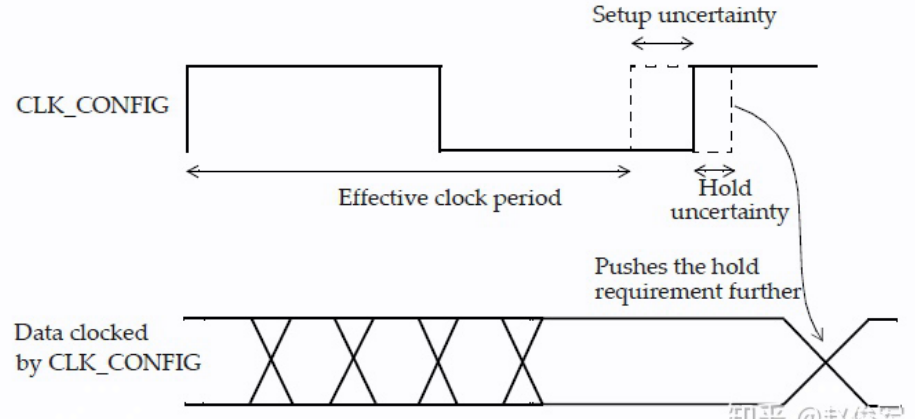
可以使用 set_clock_uncertainty 约束来指定时钟周期的时序不确定度(uncertainty),该不确定度可用于对可能会减少有效时钟周期的各种因素进行建模。这些因素可能是jitter以及可能需要在时序分析中考虑的任何其它悲观度。
set_clock_uncertainty -setup 0.2 [get_clocks CLK_CONFIG];注意,建立时间检查的时钟不确定度将减少可用的有效时钟周期。对于保持时间检查,时钟不确定度将用作需要满足的额外时序裕量。
时钟延迟
可用以下命令设置时钟延迟,如 set_clock_latency 1.8 -rise [get_clocks MAIN_CLK]
时钟延迟有两种类型:网络延迟(network latency)和源延迟(source latency):触发器时钟引脚上的总时钟延迟是源延迟和网络延迟之和。在时钟树综合完成后,从时钟源到触发器时钟引脚的总时钟延迟是源延迟加上时钟树从时钟定义点到触发器的实际延迟。
- 网络延迟是指从时钟定义点 (create_clock) 到触发器时钟引脚的延迟。
- CTS 后忽略
- 源延迟也称为插入延迟(insertion delay):是指从时钟源到时钟定义点的延迟, 源延迟可能代表片上或片外延迟
- CTS 后保留
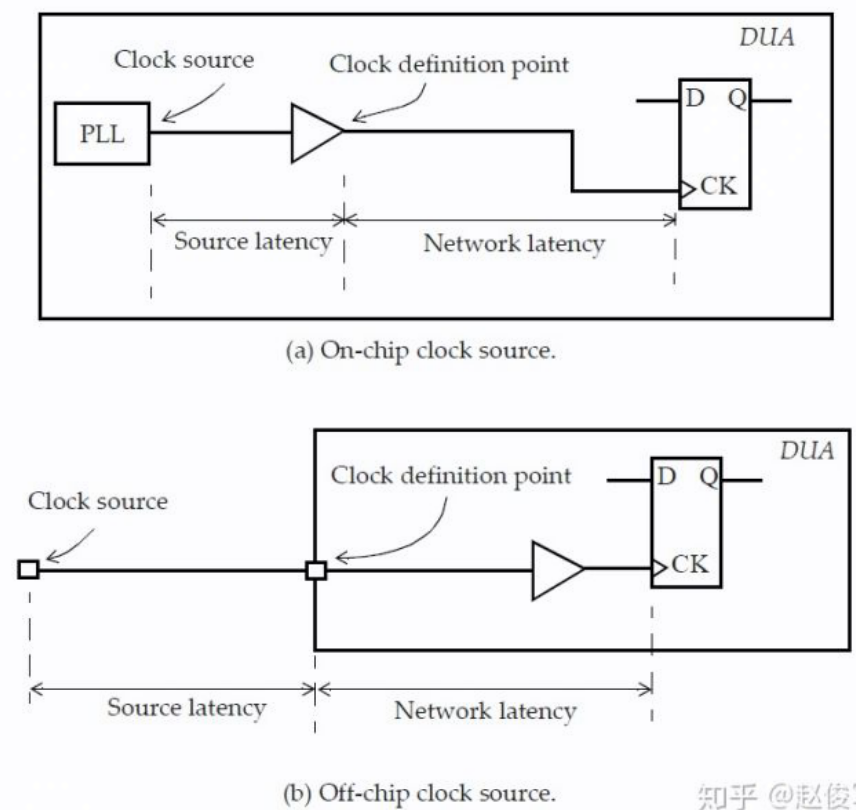
源延迟和网络延迟之间的一个重要区别是:一旦为设计建立了时钟树,就可以忽略网络延迟 (假设指定了 set_propagated_clock 命令)。
约束输入路径
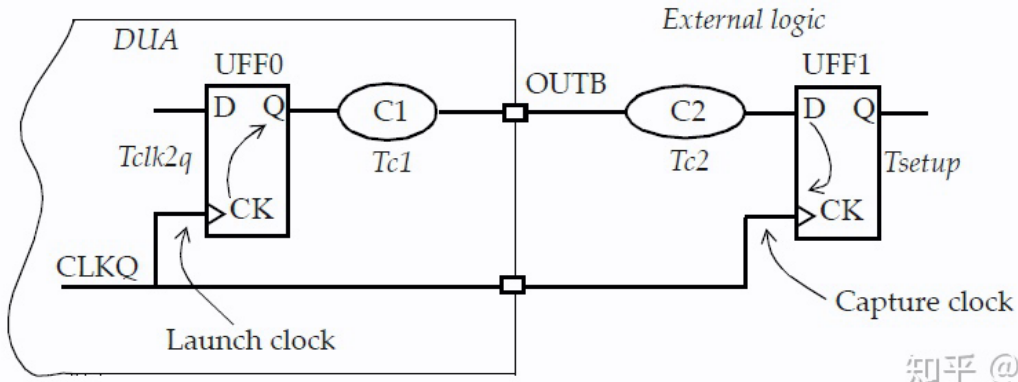
触发器UFF0在设计的外部,并向设计内部的触发器UFF1提供数据。数据通过输入端口INP1连接两个触发器。
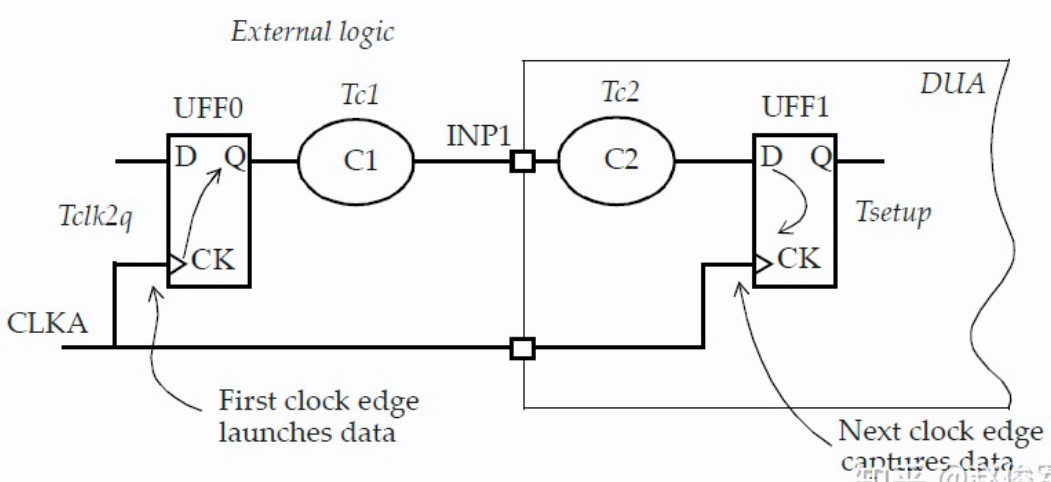
CLKA的时钟定义指定了时钟周期,这是两个触发器UFF0和UFF1之间可用的总时间。外部逻辑所需的时间为Tclk2q(数据发起触发器UFF0的CK至Q延迟)加上Tc1(通过外部组合逻辑的延迟) ,因此输入引脚INP1上的延迟定义指定了Tclk2q加上Tc1的外部延迟。
以下是输入延迟的约束 (可分别定义 minmax):
set Tclk2q 0.9set Tc1 0.6set_input_delay -clock CLKA -max [ expr Tclk2q + Tc1] [ get_ports INP1]
约束输出路径
约束输出路径与约束输入路径类似,可通过命令 set_output_delay 来指定外部延迟:
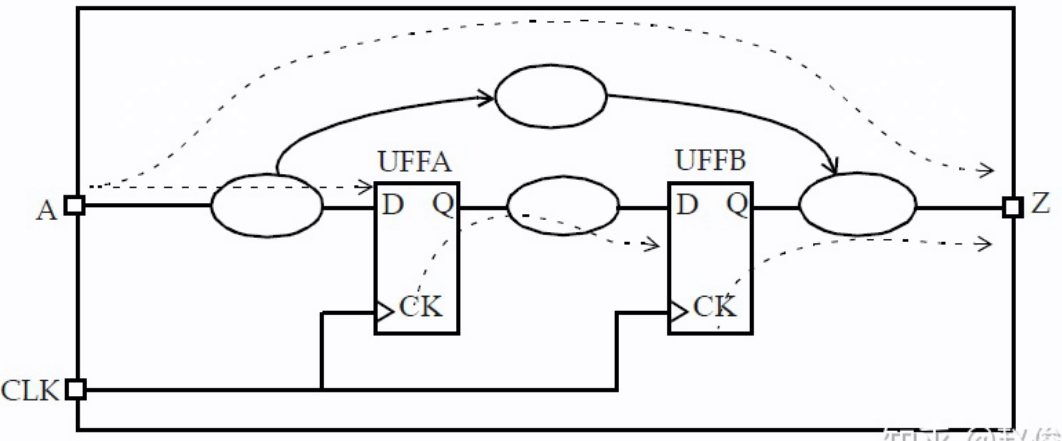
时序路径组
设计中的时序路径可以视为路径的集合,每个路径都有一个起点和一个终点。
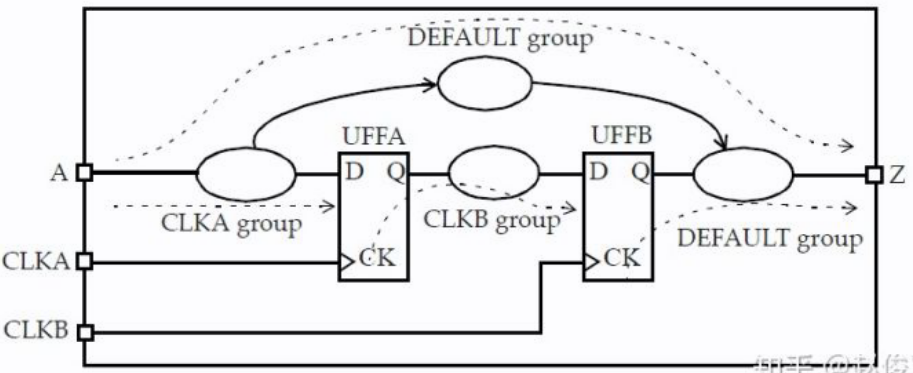
时序路径可以根据与路径终点相关的时钟分类为不同时序路径组(path groups)。因此,每个时钟都有一组与之相关的时序路径。还有一个默认时序路径组,其中包括了所有非时钟(异步)路径。
外部属性建模
尽管 create_clock 、set_input_delay 和 set_output_delay 足以约束设计中用于执行时序分析的所有路径,但这些并不足以获取该模块IO引脚上的准确时序。
对于输入,需要在输入端口处指定压摆:
set_driveset_driving_cellset_input_transition
对于输出,需要指定输出引脚的负载电容:
set_load
驱动强度建模
总之,设计人员需要指定输入端的压摆值来确定输入路径中第一个单元的延迟。在没有该约束的情况下,将假设为理想过渡值 0,这显然是不现实的。
set_drive 和 set_driving_cell 约束用于对驱动模块输入端口的外部单元的驱动强度进行建模。在没有这些约束的默认情况下,假定所有输入都具有无限的驱动强度,即输入引脚的过渡时间为0

set_drive 明确指定了DUA输入引脚上的驱动电阻值,该电阻值越小,驱动强度越高,电阻值为0表示无限的驱动强度。输入端口的驱动强度用于计算第一个单元的过渡时间。指定的驱动强度还可用于计算在任何RC互连情况下从输入端口到第一个单元的延迟值
- 延迟值 = (驱动强度 * 网络负载) + 互连线延迟
set_driving_cell 约束提供了一种更方便,更准确的方法来描述端口的驱动能力。 set_driving_cell 可用于指定驱动输入端口的单元类型。但由于输入端口上的电容性负载而导致驱动单元的增量延迟被视作为输入上的附加延迟被包括在内
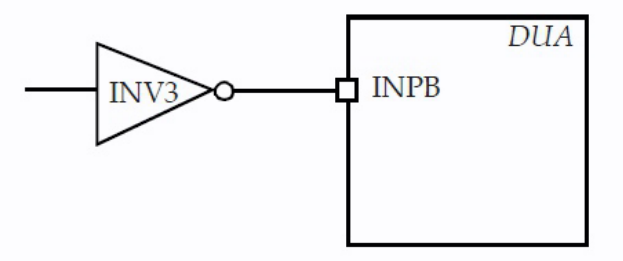
作为上述方法的替代方法, set_input_transition 约束提供了一种在输入端口表示过渡时间的便捷方法,并且可以指定参考时钟

负载电容建模
指定输出上的负载很重要,因为该值会影响驱动输出的单元的延迟。在没有该约束的情况下,将假定负载为0,这显然是不现实的。
set_load 约束在输出端口上设置了电容性负载,以模拟由输出端口驱动的外部负载。默认情况下,端口上的电容性负载为0。可以将负载显式地指定为电容值或某个单元的输入引脚电容。
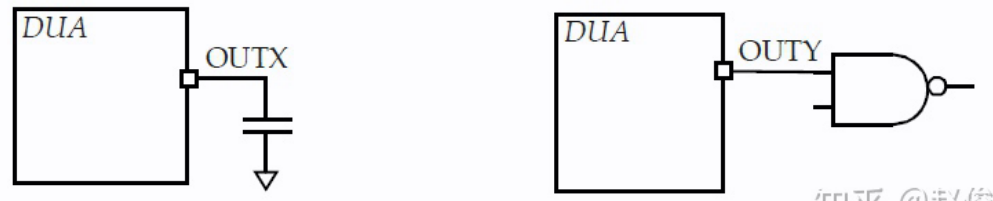
DRV
STA中两个常用的设计规则是最大过渡时间-max_transition和最大电容-max_capacitance。这些规则将会检查设计中的所有端口和引脚是否满足过渡时间和电容的规定约束。
此外,还可以为设计指定其他设计规则检查,比如: set_max_fanout (指定设计中所有引脚的扇出约束) 以及 set_max_area (用于设计)。但是,这些检查适用于综合(synthesis)而非STA。
Delay Calculation
延迟计算基本概念
由上文可知,每个单元的输入引脚都存在引脚电容,所以每条 net 都将具有容性负载,其值为所有 fanout 的引脚负载电容及互连线的寄生电容之和。
考虑如下设计:
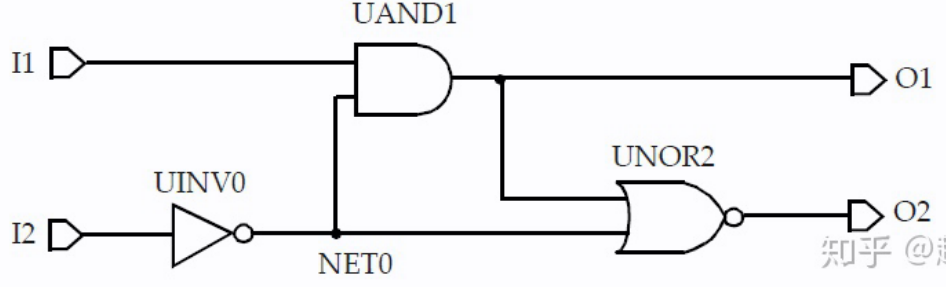
对于 NET0, 在不考虑互联寄生的情况下,其电容等于 UAND1 和 UNOR2 的输入引脚电容之和。由此,可将上图等价为:
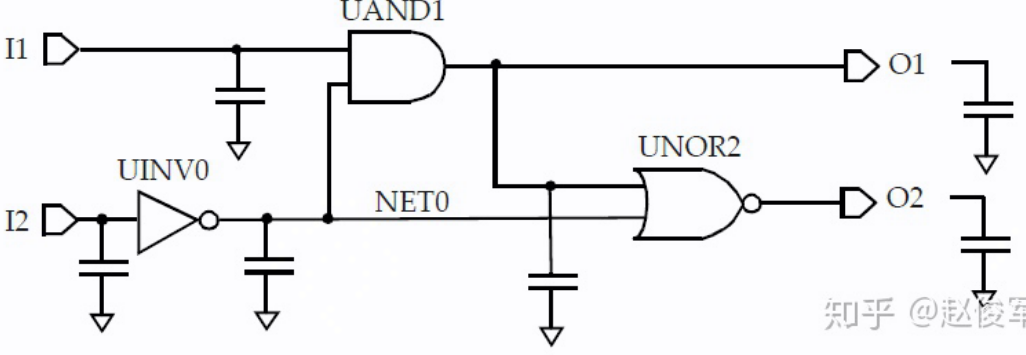
输出 O1 的负载电容等价于输出端口负载(未指定,可通过 set_load 指定)加上 UNOR2 输入引脚负载电容(已在库中指定),所以此时只要为输入 I1 指定压摆(或 set_drive),即可获得单元 UAND1 相对于该 input transition 的 propagation delay and output transition(知道了上一级的 output transition, 则又可以得到下一级单元的 input transition).
由于多输入单元存在不同输入到输出的多条 timing arc, 所以 output transition 的值由 slew merge 结果来决定。
有效电容计算单元延迟
当单元输出端的负载包含互连电阻时,NLDM模型不可直接使用。因此,采用“有效”电容法来处理电阻的影响。
有效电容法试图找到一个可以用作等效负载的电容,以使原始设计与具有等效电容负载的设计在单元输出的时序方面表现一致。这个等效电容被称为有效电容(effective capacitance)
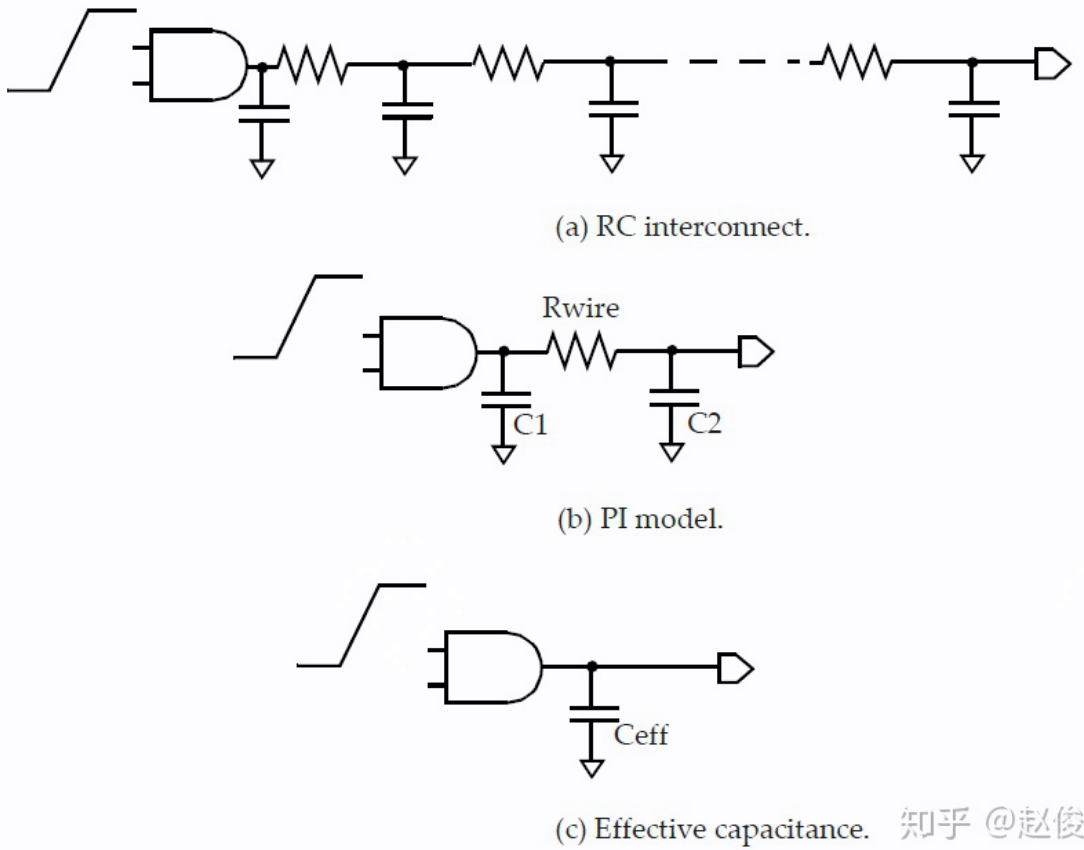
即在实际情况下,互连寄生不能忽略电阻的影响,此时可将 RC 互连建模为更精简的 PI model。由于 NLDM 只接受电容,所以将 RC 计算为一个等效的 $C_{eff}$ ,进而可以继续使用 NLDM 查表得到单元延迟。那如何计算得到这个 $C_{eff}$ 则存在不同算法:如二阶 AWE, Arnoldi 算法等。
注意:虽然能够得到近似的单元延迟,但 output slew 与单元实际输出波形并不一致。
Net Delay
对于有大学简单电路背景的同学应该很熟悉,走线延迟的本质是由于导通的电路是可以等效为电阻电容(R与C),其上信号传递的延迟可以简化为RC Delay。总体而言,走线的延迟取决于线宽、线长(Wire length)、工艺、扇出分支(Fanout)。而在不同EDA阶段,我们可以通过不同模型去预估两个引脚之间的走线延迟。
- 逻辑综合:如Synopsys的Design Compiler,是基于走线负载模型(Wire Load Model,WLM)预估两个信号引脚之间的走线延迟。在这个设计环节,芯片设计还没走到布局布线,因此没有相对位置来具体的走线路径。因此WLM是根据扇出数量来估计网络的长度,从而获得延迟的(误差可想而知,毕竟扇出少的逻辑路径也可能在布局时被扯得很远)。WLM通常是由对应的ASIC/FPGA厂商会提供,然后设计者基于自己的设计进行微调即可,在一个设计中,不同层次位置、不同的走线可以配置不同的WLM,从而逼近实际延迟。
- 布局:布局期间知道了每个逻辑单元的具体位置,因此我们可以充分利用位置信息来推测路径:我们首先估计两个相连的逻辑单元之间线长是多少,随后通过线长,预估延迟。需要留意的是,虽然理论上走线越长,延迟越长,但是并不完全是线性关系,毕竟从广州北京,走高速开始开县道还是不一样的。通常而言,以Cadence Innovus的布线前、布局后(Post-placement pre-route)的时序估计是基于所谓的TrialRoute(尝试布线)[7]或Early Global Route (前期全局布线)[8]去估计布线情况,然后基于这个粗糙的布线情况,进行RC寄生参数的提取,然后将这些寄生参数与驱动单元的输入引脚电容相加,从而获得走线延迟。其中最重要的是如何获得一个准确的布线估计,一个准确的估计可以实现很小的布线前后的时序跳跃(Timing Jump)。
- 布线:在这期间不仅知道位置,还知道了具体的金属走线。因此此时可以直接的提取RC参数,然后跑时序分析引擎即可。
Elmore 模型计算互连延迟
Elmore 是用于在特定条件的 RC 互连结构下计算 net delay 的延迟模型。
压摆合并 (TBD)
路径延迟计算
回顾几个概念:timing path, timing arc
理论上的 timing path 存在一个 start point 和一个 end point:
- start point: input port and clk pin
- end point: d pin and output port
所以,一共存在四种 timing path: r2r, i2o, i2r and r2o
而 timing arc 用于描述:
- pin to pin 之间的信号传输关系(传输延迟以及如何变化)
- timing constraints: setup/hold etc..
所以,一但使用 timing arc annotate whole design, 则计算路径延时即将所有 net arc and cell arc 相加。
I2O
第一种时序路径,即 input port to output port.
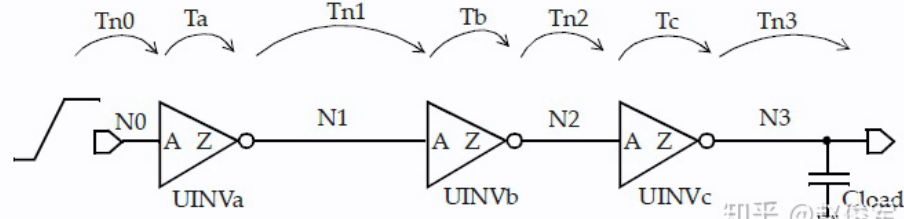
而从输入端口到第一个 load cell 需要特殊处理,即可以指定第一个反相器输入端的过渡时间(或压摆),若没有此类指定的话,就假定过渡时间为0(相当于理想情况)。
- 在 OpenSTA 中如果不指定的话第一个cell的load slew为0。在seedRootSlew时可以计算出root到第一个cell的load delay & load slew
此外,可根据第一个 cell 输出处的 RC 负载情况计算得到一个等效电容,进而查表得到第一个 cell delay 和 output slew.
当计算得到第一个 cell 的 output slew 后,又可以得到下一级单元的 input slew, 以此循环。
注意,和第一级输入类似,最后一级输出需要手动 set_load, 否则仅使用网络N3的线负载。
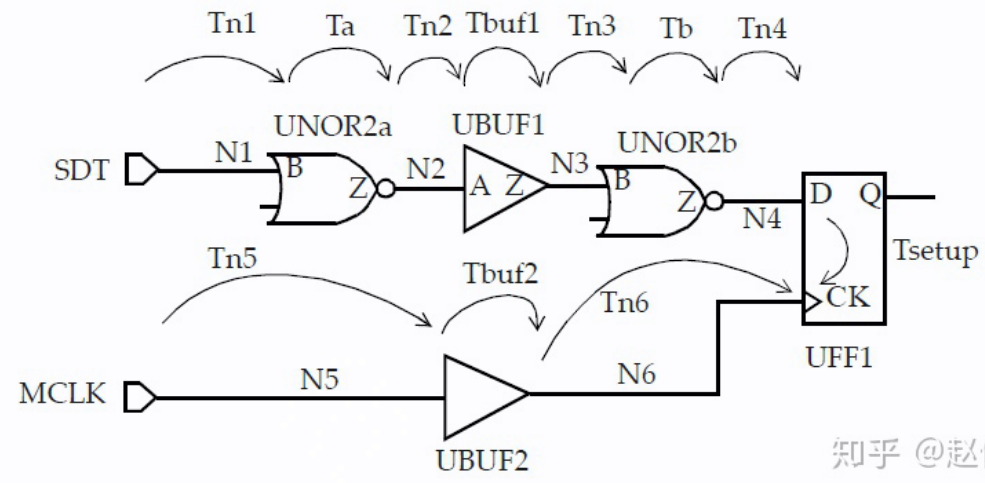
I2R
类似计算。
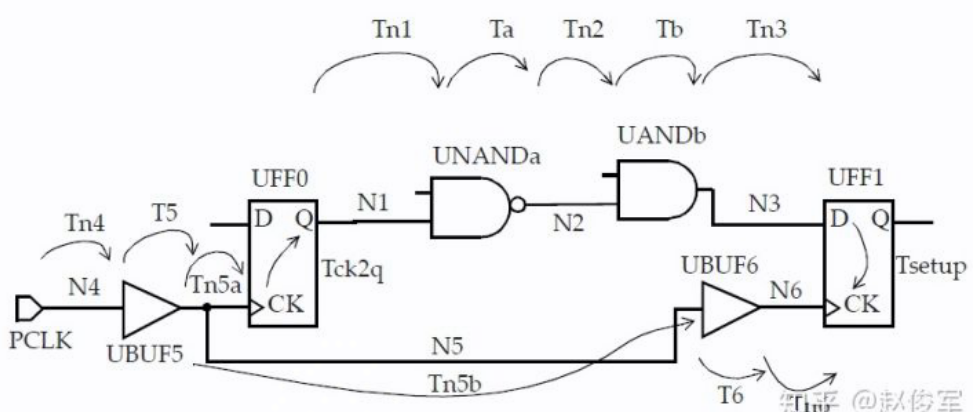
R2R
类似计算。
Timing Graph
STA breaks a design down into timing paths, calculates the signal propagation delay along each path, and checks for violations of timing constraints inside the design and at the input/output interface.
Timing Path
timing path 存在 start and end point, 定义分别如下:

根据 start point 和 endpoint 可将 timing path 分为四类:
- input port to d pin,
I2R - clk pin to output port,
R2O - clk pin to d pin,
R2R - input port to output port,
I2O
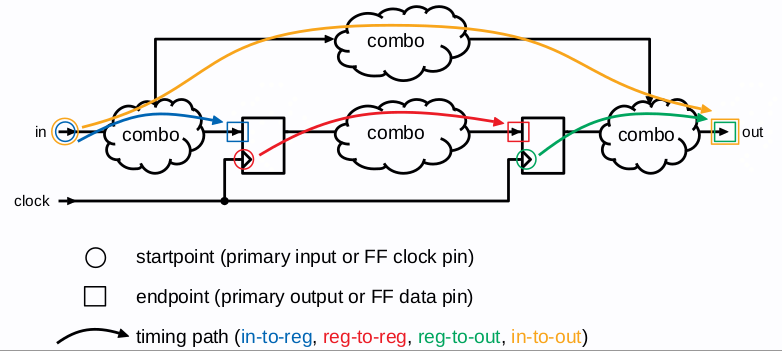
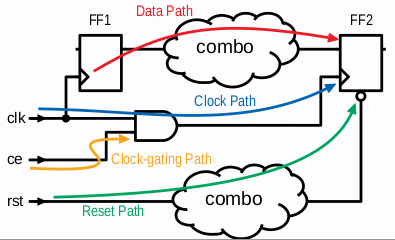
时序路径为一段段时序弧的集合,除了可以根据起点和终点分类外,还可以 By signal type or timing check: Data path, clock path, clock-gating path, asynchornous path.
Timing Graph
考虑如下网表:
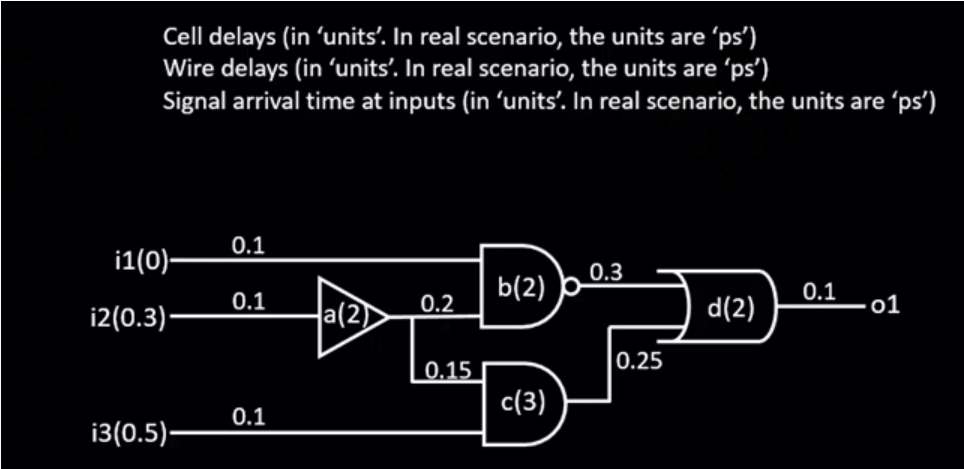
Convert the above circuit to a 'Direct Acyclic Graph (DAG)' shown below:
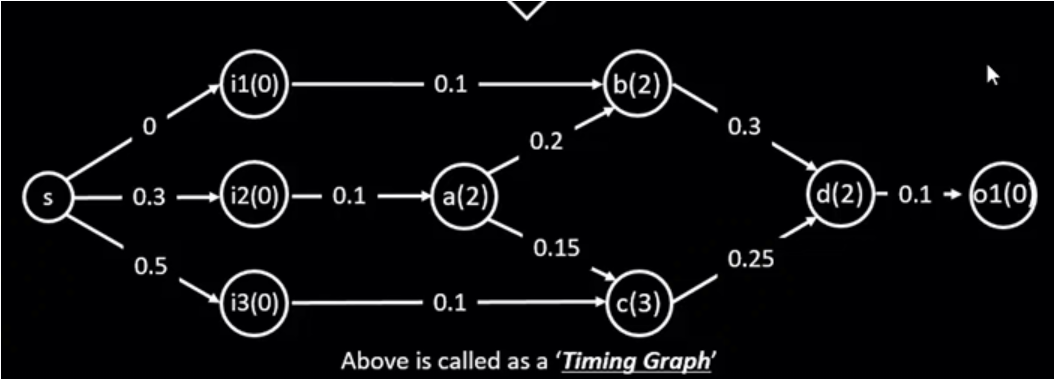
OpenSTA Timing Graph
Timing graph is a flat DAG, though OpenSTA has full hierarchical netlist.
以下网表为例:
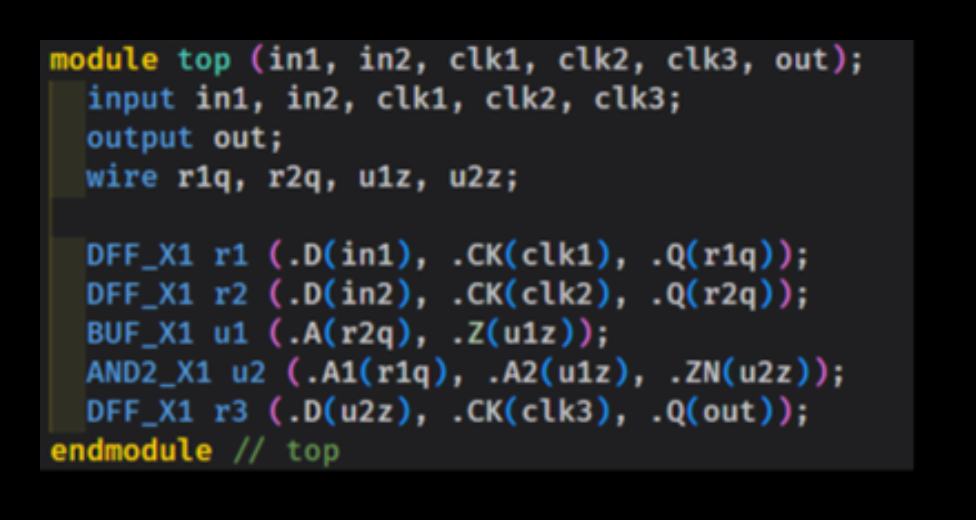
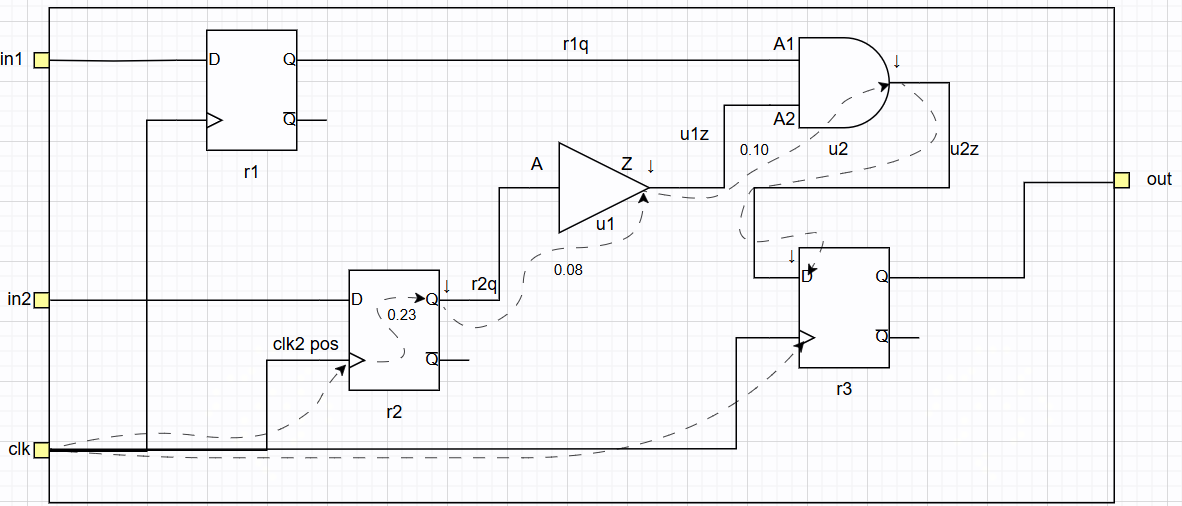
将其转换为时序图:
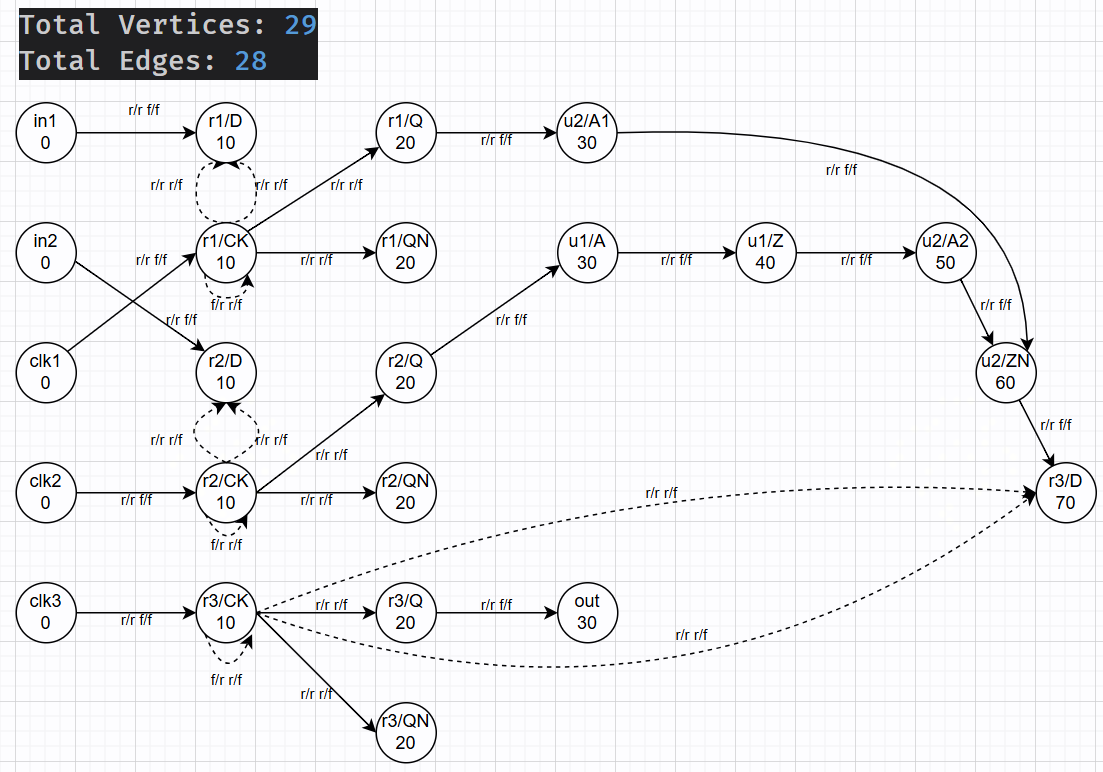
vertex 定义为:Each Vertex corresponds to one network pin.
- 包括了 internal pin (图中未画出),
edge 定义为:There is one Edge between each pair of pins that has a timing path between them.
每条 edge 有自己的 timing role: 代表这条 edge 可能是 cell delay or wire delay, 亦或是各种类型的 timing analysis
此外,一条 edge 上存储了一组 timing arc: A timing arc set is a group of related timing arcs between from/to a pair of cell ports. Wire timing arcs are a special set owned by the TimingArcSet class.
时序分析方式
以分析的方式区分,可分为 Path-Based 及 Block-Based 两种,他们的主要区别在于对特定逻辑单元的Transition Time(电平转换时间)的处理不同。
实际上,在电路工作过程中,一个逻辑单元收到的输入电平变换时间是由前级逻辑单元所影响的。
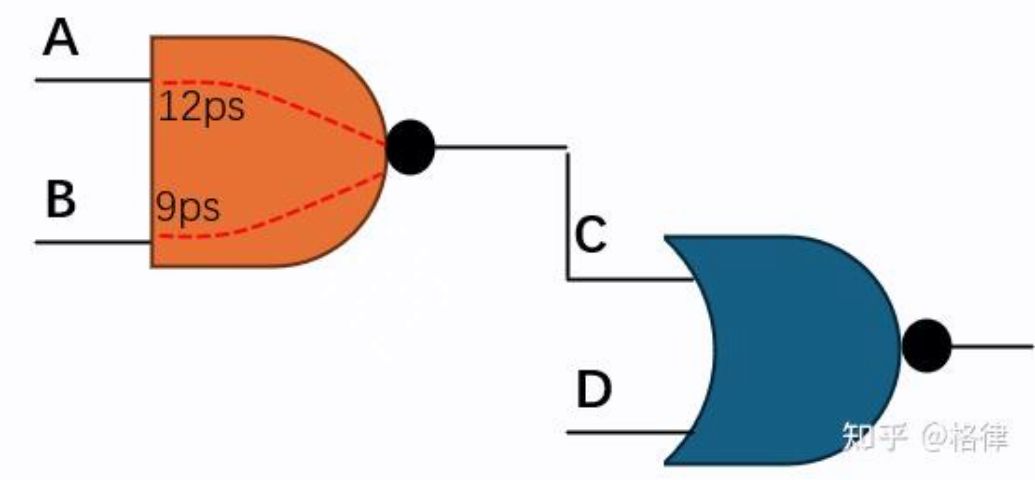
C pin 的 input transition 取决于上一级逻辑单元的 output transition, 而经不同输入引脚变换而引起的 output transition 不同,从而影响 C 的 input transition. 如何确定这个C处的电平转换时间是时序分析算法的差异。
Graph Base
基于图的静态时序分析(GBA)是大多数工具默认的分析模式,它在从标准逻辑单元库(Standard Cell Library)中读取单元延迟时基于最差情况的电平转换时间进行计算。例如在上面的例子中,不管A\B如何跳变,都会取对C处电平延迟最大的电平转换时间,例如12ps。因此即使某个时序路径下,A的信号一直不变的,变化都只发生在B引脚,后面的蓝色或非门理应用B引脚引起的9ps电平转换时间,在GBA的分析算法中,仍将使用12ps。因此,GBA模式往往比较悲观,可能导致某些路径上的时序违例,因为实际跳变很可能不会导致每个逻辑单元都恰好引脚跳变引起最差电平转换时间。为了解决这种悲观性并提高准确性,引入了基于路径的静态时序分析(Path-based Analysis, PBA)
Path Based
PT 采用 path based 时序分析方法,将分析所有 timing path.
与GBA相比,PBA则会遍历所有可能的时序路径,(理论上)枚举所有可能的输入跳变组合来进行时序评估,因此可以获得最准确的时序分析结果。在上图的示例中,如果针对在B引脚的跳变,则PBA会实实在在地用B引脚的9ps跳变来计算下一级蓝色或非门的延迟。但因为相比于GBA,遍历了更多的情况,导致算法的运行时间极其慢,在复杂用例中,可能PBA会比GBA慢上一个数量级。
GBA Vs PBA
对于同一个 combinational design, GBA vs PBA as shown below:
min_delay_in_GBA<=min_delay_in_PBAmax_delay_in_GBA>=max_delay_in_PBA

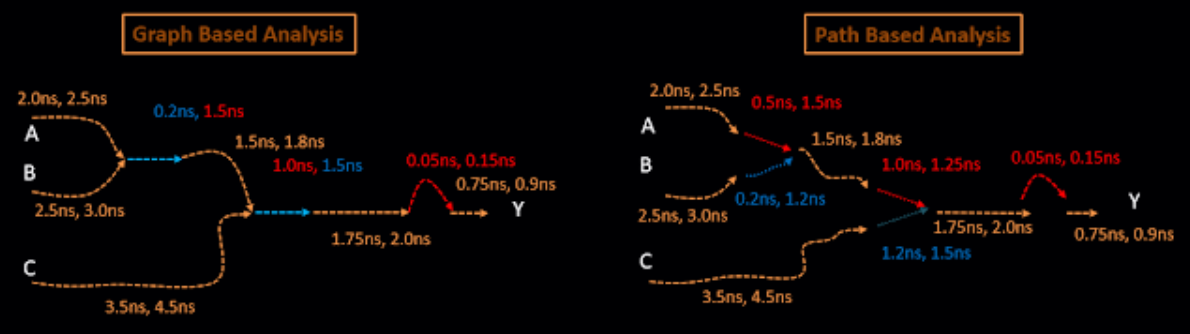
In GBA (Graph Base Analysis), in place of choosing 2 combinations of AND gate (1) delay, i.e. (Combination_1: 0.5ns, 1.5ns ; Combination_2: 0.2ns, 1.2ns) we choose extreme boundaries, i.e. min delay = 0.2ns and max delay = 1.5ns.
In case of PBA (Path base Analysis), we are using actual delay between input pin and output combination (means choosing both combination of delay).
- Combination_1: 0.5ns, 1.5ns
- Combination_2: 0.2ns, 1.2ns
You might be thinking that this is not accurate (means why in GBA we missed 2 value), we are adding unnecessary delay in our calculation. And I am glad to say that you are right. 😃 The reason we are doing this because from tool point of view - doing analysis or say calculation as per GBA is very fast compare to PBA. Runtime of tool is very low. And only difference is that we are adding pessimism in our calculation.
- GBA is more faster than PBA
- GBA is more pessimism than PBA
基于上述特性,GBA和PBA在静态时序分析中具有不同的用途。GBA可以实现快速但粗糙的分析,如果未检测到任何违规,那么因为GBA这么悲观都没有违例,PBA分析的结果则理应没有违规。如果GBA存在违规,我们则可以使用PBA,但无需再分析所有的时序路径,只需要分析GBA模式下产生违规的路径即可(当然也可以全局进行PBA)。
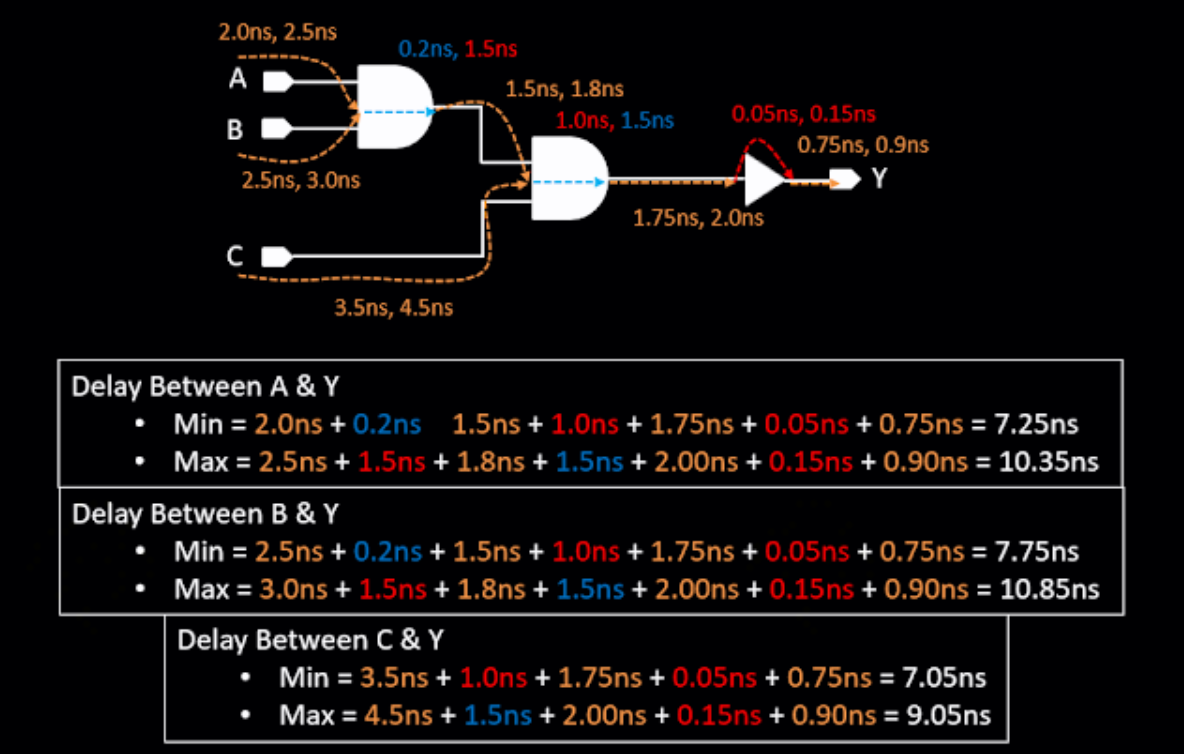
GBA Delay Calculation
每个 cell arc 不管 rise fall or min max, 都取极端值,这使得计算更加简单快速,但因更加悲观而不够准确。
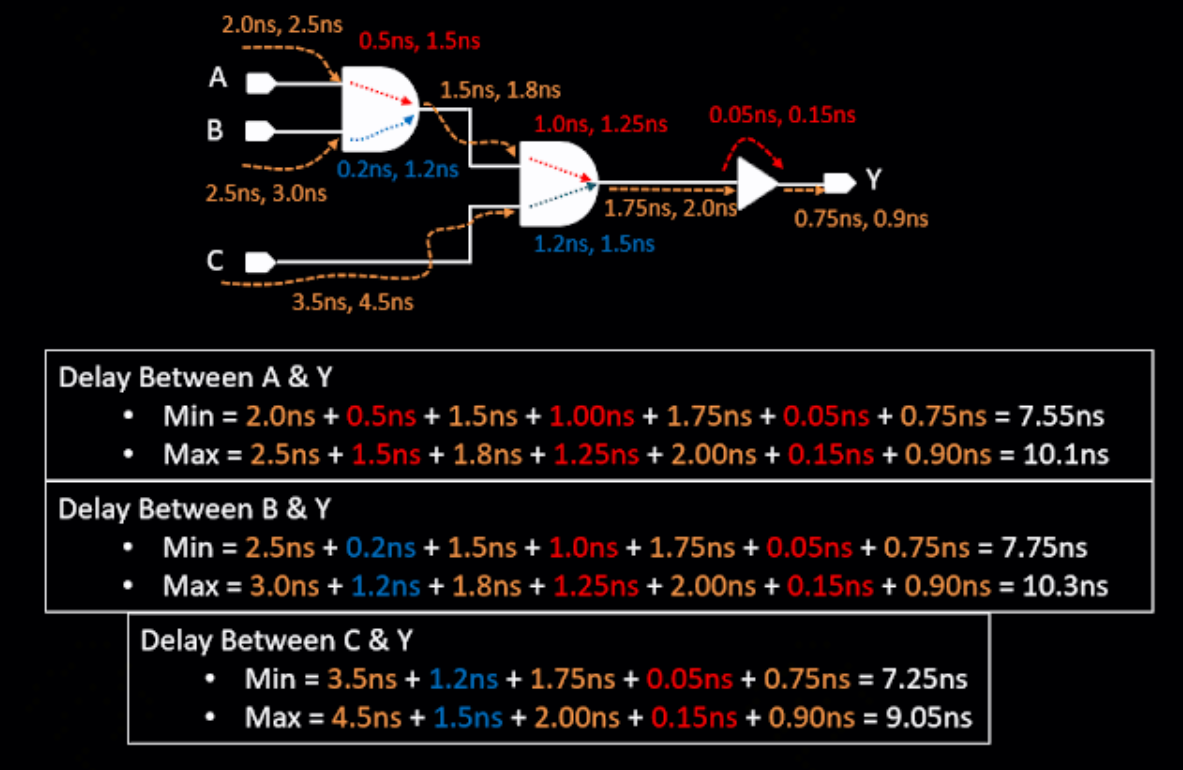
PBA Delay Calculation
PBA 会穷尽一条 timing path 上的所有 arc combination
基于图的静态时序分析原理
假设所有锁存器都是统一时间收到时钟上升沿(即忽略因布局引起的Clock Skew)。在这一系列的简化下,STA问题可以退化为:求有向图中,所有时序终点离最远的时序起点有多远(理论上讲是指Arrival Time,信号从源头到某个节点的延迟),即最长路径问题(参考:有向无环图中单源最长路径如何求?,这里解决多源多汇最长路径),如下图所示。算法的简单描述就是从所有起点开始,遍历所有节点,更新节点距离起点的最远距离:
$$
ArrivalTime[i] = max{ArrivalTime[Predessor[i, j]]+CellDelay[j]+NetDelay[i,j]}
$$
其中i为当前节点编号,$Predecessor[i, j]$是指i节点的第j个前序节点的编号,$ArrivalTime[Predecessor[i, j]]$为源头信号抵达该前序节点的时间,$CellDelay[j]$为前序节点的逻辑时延,$NetDelay[i,j]$为经过该前序节点到节点i的走线延迟,可以根据该两个节点的坐标位置获取的。
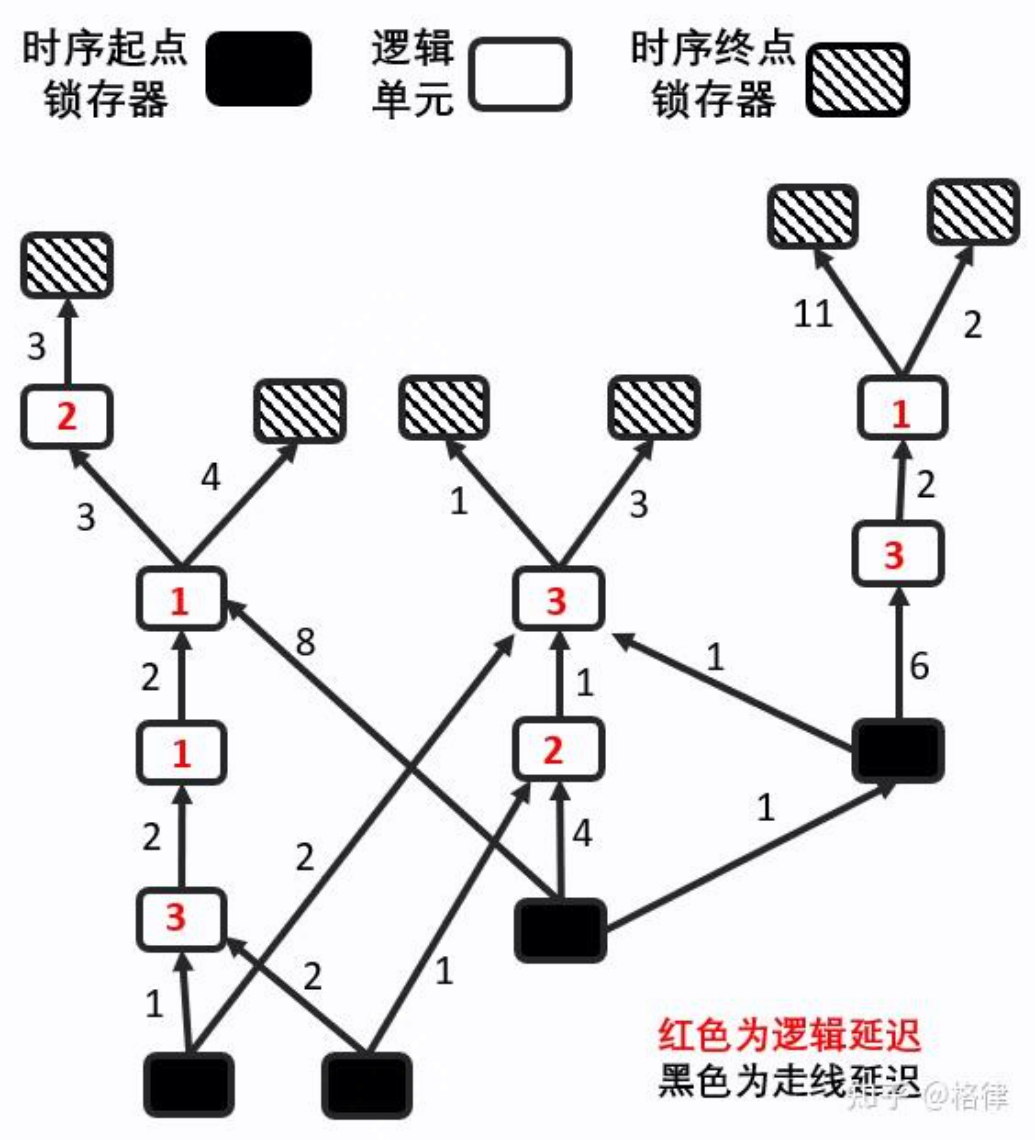
网表分级
由于布局一动就需要重新评估时序情况,所以在布局算法运行期间,针对多源多汇的最长路径算法会被频繁调用。由上面的递推公式可以知道,计算节点i的 $ArrivalTime[i]$ 之前,我们需要先已经获得它的前序节点的ArrivalTime,否则这些ArrivalTime的计算不能确保是最长的。而电路划分是为了进行并行化运算,即我们需要把电路中节点染色分块,每一块子图中的节点互不依赖(即互相之间没有连边,图不一定是联通的),对于每一块子图中的节点,我们可以并行计算。
为了实现满足这种特性的电路划分,基本的算法原理:在队列中存储所有的时序起点,并且将它标记为level=0。随后开始BFS,更新有向图中,每个节点离时序起点的最远距离,随后有向图会被标记:
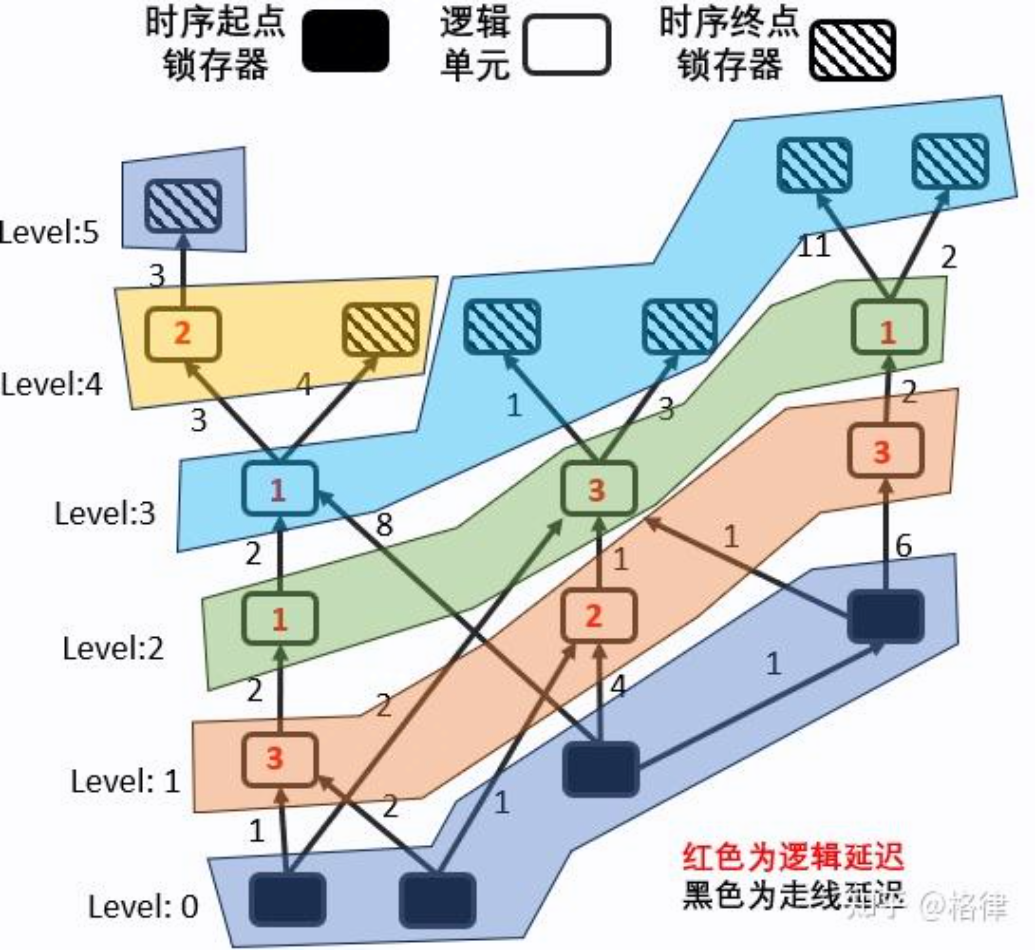
基于分层同步 BFS 的时序传递
正向 BFS 计算到达时间
可以留意到分层后level=i中的所有节点:(1)除了level=0的特例(level=0的起点单元会被强制标记为ArrivalTime=0,不进行计算),它们之间没有相互连边,即它们的时序计算之间没有依赖;(2)如果我们按照从level=0i的顺序计算ArrivalTime,当遍历直至level=i时,level=0i-1的节点都已经完成ArrivalTime的计算。即level=i的所有节点能同时进行它们的Arrival time计算,这时候我们就可以调用openmp等并行化框架进行加速。我们初始化所有的节点的Arrival time为0,然后跑上面提及的最长路径算法,即可推出下图中的时延信息:(右图中第三级最左边的节点 arrival time 应该为 10)
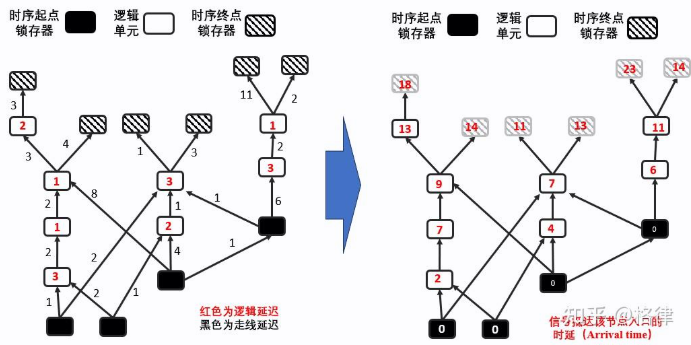
反向 BFS 计算 RAT
如上一节中的前向时延分析之后,我们就知道每一个终点离起点有多远了。但是可能设计者对于每个终点有不同的约束,它们可能希望其中某些信号早些抵达特定的时序终点,因此这时候会有时序裕量(Timing Slack)的概念:
$$Timing Slack = Required Arrival Time (用户指定的) - Arrival Time(实际抵达时间)$$
如果Timing Slack小于0,则说明信号来迟了,存在时序违例。其中 Arrival Time 是在前向时序传递完成了计算。通常对于时序终点,Required Arrival Time(RAT)为时钟周期减去建立时间(Clock Period - Setup Time)。但是对于中间每一个时序节点,设计者通常是不会设置RAT的。因此在STA中,我们需要做反向的时序传递,从而让除了终点外的每一个节点,都知道自己实际上被要求多早获得信号,就很像我们上班时候的项目管理,每个任务节点都需要自己要在什么时间前完成才不给后续大伙挖坑。
而反向时序传递的基本方法与正向传递基本一致,只是之前正向公式为:
$$ArrivalTime[i] = max{ArrivalTime[Predecessor[i, j]]+CellDelay[j]+NetDelay[i,j]}$$
而反向为:
$$RequiredArrivalTime[i] = min{RequiredArrivalTime[Successor[i, j]] - NetDelay[i,j]} - CellDelay[i]$$
其中$RequiredArrivalTime[i]$为节点i的RAT,而$RequiredArrivalTime[Successor[i, j]]$是指节点i的第j个后序节点的RAT,$NetDelay[i,j]$为两个节点之间的走线延迟,而$CellDelay[i]$是指节点i的逻辑时延。
根据上面公式的变换,我们也需要反向重新进行网表分层,如下图:
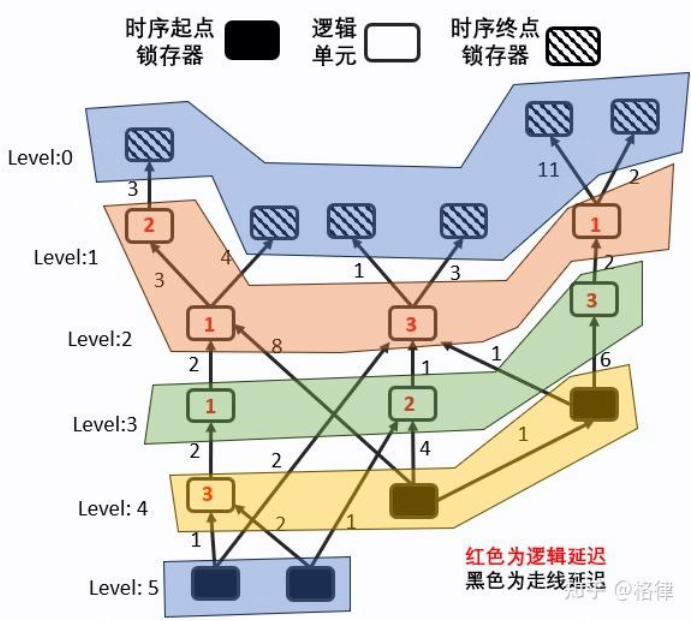
我们初始化所有的节点的RAT为无穷大,而终点节点的RAT则为设计者指定,然后跑我们上面提及的最长路算法,即可推出下图中的RAT信息,其中我们假设所有终点RAT为20:

增量式时序分析
如果在布局时进行局部调整,则没必要进行全局 STA, 因为全局分析缓慢低效,而很多节点的时序可能是没变的。这时候我们的正向、反向的分层都不需要动,我只需根据出现变化的节点,将他们的所有前序节点和后续节点重新放到上面的BFS流程中,就可以实现快速增量式时序分析。
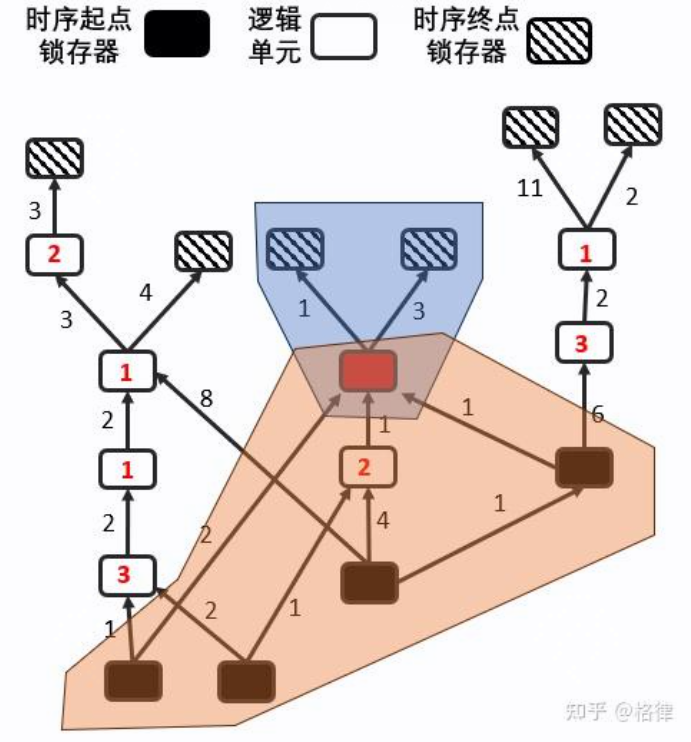
当红色节点被移动时,只有蓝色和橙色覆盖的节点需要重新进行STA
Timing Analysis
时序分析主要关注 setup and hold violation, 分别对应最差和最优情况。此外,还需掌握以下命令的使用:
set_input_delayset_output_delayset_drive,set_driving_cellandset_input_transitionset_load
Setup
输入的数据必须在有效时钟沿之前保持稳定的最短时间称为建立时间(setup time)。注意:这是根据最晚的(the latest)数据信号超过其阈值(通常为Vdd的50%)到有效时钟沿超过其阈值(通常为Vdd的50%)的时间间隔测量的。
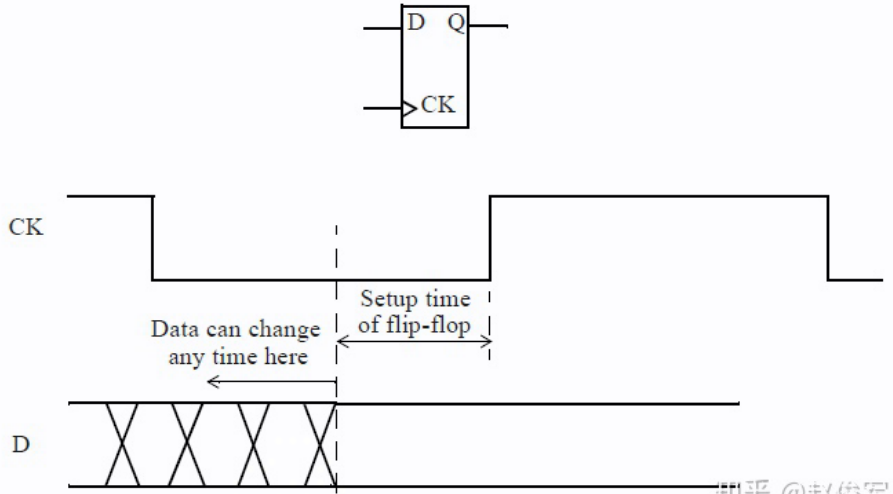
在时钟的有效沿到达触发器之前,数据应在一定时间内保持稳定,即触发器的建立时间,该要求将确保数据可靠地被捕获到触发器中。
- 注意,建立时间检查允许 launch 和 capture 归属不同时钟域。
Setup case 1
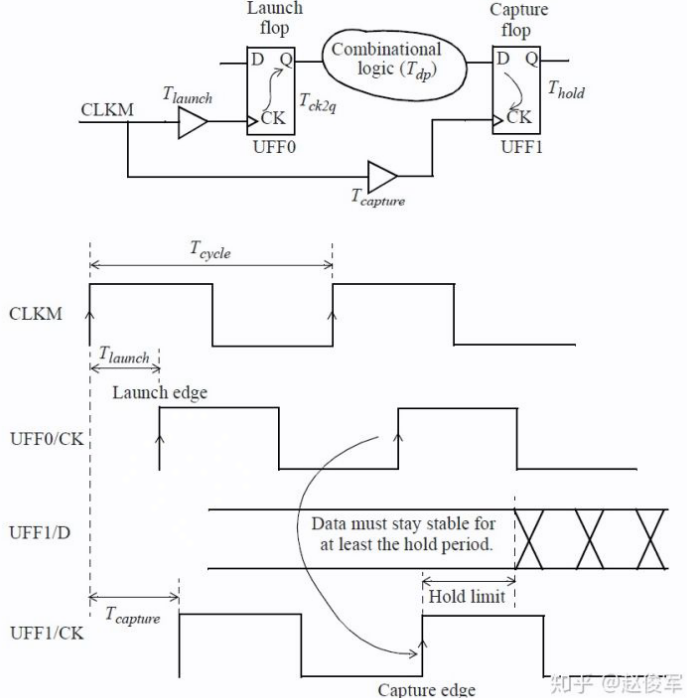
以下图为例,时钟 CLKM 周期为 $T_{cycle}$
- 对于 launch path: 时钟 CLKM 到达触发器
UFF0时钟引脚的时间 $T_{launch}$ + 触发器UFF0自身的 propagation delay ($T_{ck2q}$) + Data path delay ($T_{dp}$) - 对于 capture path: 时钟 CLKM 到达触发器
UFF1时钟引脚的时间 $T_{capture}$ + 时钟周期 $T_{cycle}$
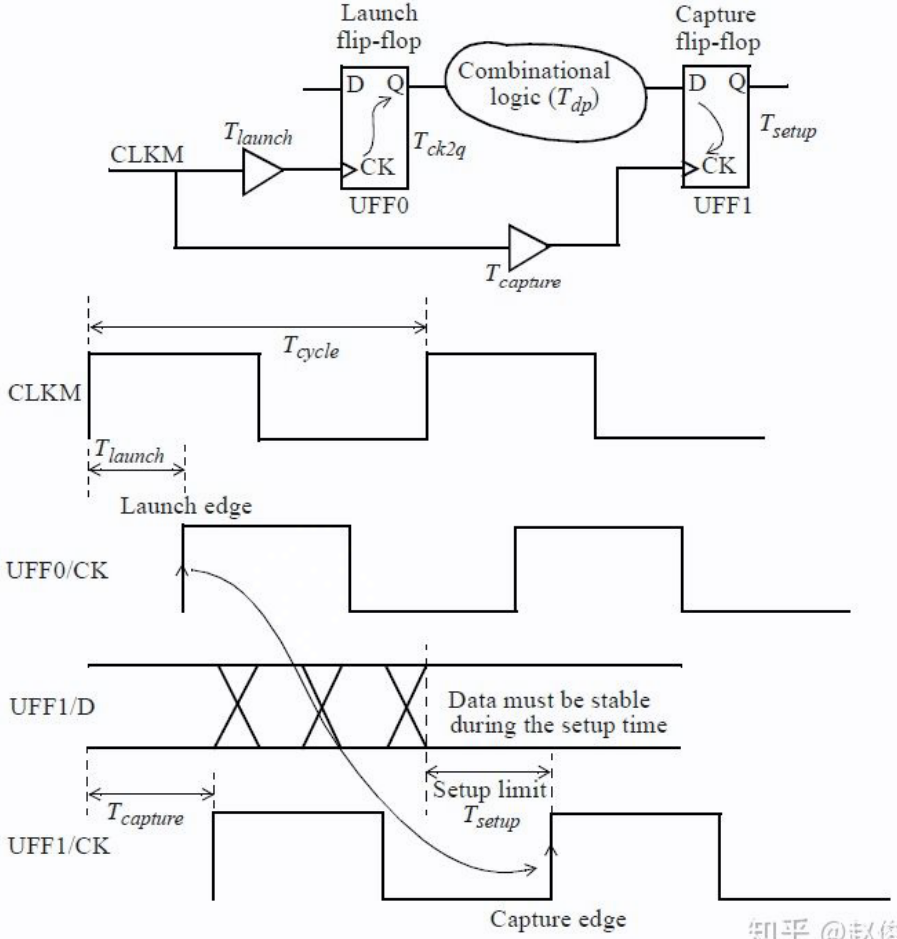
由于在 capture 建立时间约束要求数据信号相对于时钟信号需要至少提前一个建立时间保持稳定,所以需要满足公式:
$$
T_{launch} + T_{ck2q} + T_{dp} < T_{cycle} + T_{capture} - T_{setup}
$$
Arrival and Required in Setup
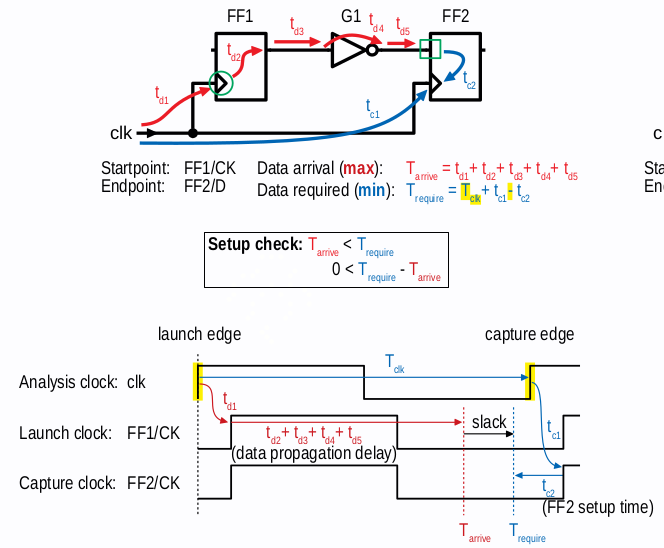
已知 setup check 需满足:(上图为具体的 case,下式为 generic 公式)
$$
T_{launch} + T_{ck2q} + T_{dp} < T_{cycle} + T_{capture} - T_{setup}
$$
则 require 和 arrival time 定义如下:
- require time: capture path delay
- arrival time: launch path delay
由于 slack 需要 >= 0, 则有如下公式:
$$
T_{cycle} + T_{capture} - T_{launch} - (T_{ck2q} + T_{dp}) - T_{setup} >= 0
$$
R2R Setup Check
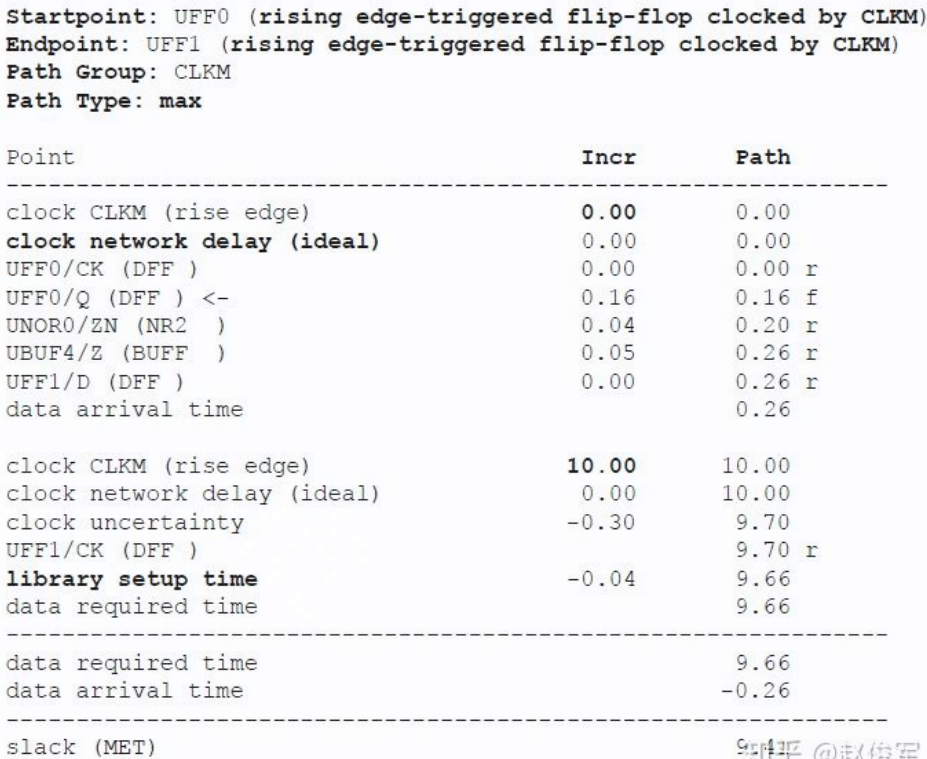
解析下述时序报告:
- start point & end point 都是触发器,且由时钟 CLKM 上升沿触发
- path group: 由 capture ff 决定
- path type: max, i.e. setup time check
- clock network delay is zero as it's ideal clock network
- i.e. $T_{launch}$ and $T_{capture}$ is zero
- clock uncertainty
- jitter
- setup time
Clock Network Delay
时序报告中的时钟网络延迟(clock network delay)是什么?为什么将其标记为理想(ideal)?时序报告中的这一行表明时钟树被认为是理想的,时钟路径中的任何缓冲器(buffer)都假定为零延迟。一旦构建了时钟树,就可以将时钟网络标记为“已传播”(propagated),从而使得时钟路径显示实际延迟值。
- 时钟网络延迟用于在建立时钟树之前(即在时钟树综合之前)对通过时钟路径的延迟进行建模。一旦建立了时钟树并标记为了 “已传播”(propagated),便会忽略此时钟网络延迟约束。
set_clock_latency命令也可用于对从主时钟到其衍生时钟的延迟进行建模

此外,如果是显示的时钟树,即插入了 clock buffer:
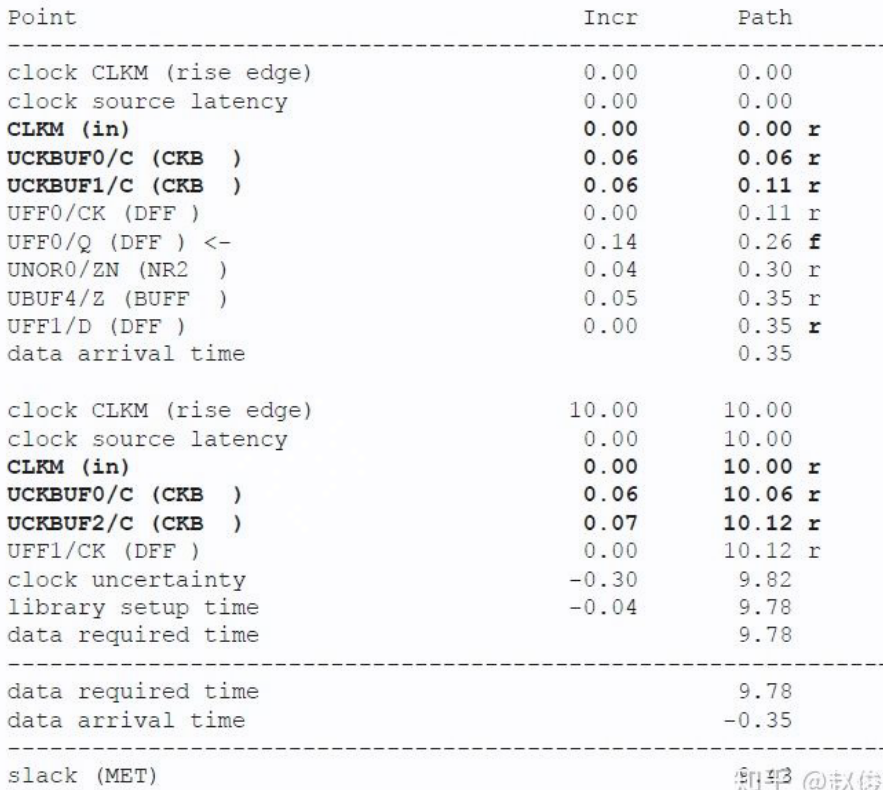
第一个 cell 的 delay 需要知道自己的 input transition,所以需要通过 set_drive, set_driving_cell or set_input_transition 来显式指定,否则认为其 input transition 为 0
此外,clock source latency, i.e. insertion delay 的定义为:时钟源端到 DUA 时钟定义点的延迟。通过命令 set_clock_latency -source
- this command will set clock network delay if w/o source option
I2R Setup Check
- 设置相对于虚拟时钟或实际时钟的外部输入延迟:
set_input_delay
从输入端口到寄存器的时序路径可由虚拟时钟或实际时钟触发,如下:
该时钟可以被认为是驱动设计输入端口INA的虚拟触发器,该虚拟触发器的时钟为 VIRTUAL_CLKM。此外,从该虚拟触发器的时钟引脚到输入端口INA的最大延迟指定为2.55ns,在报告中显示为input external delay
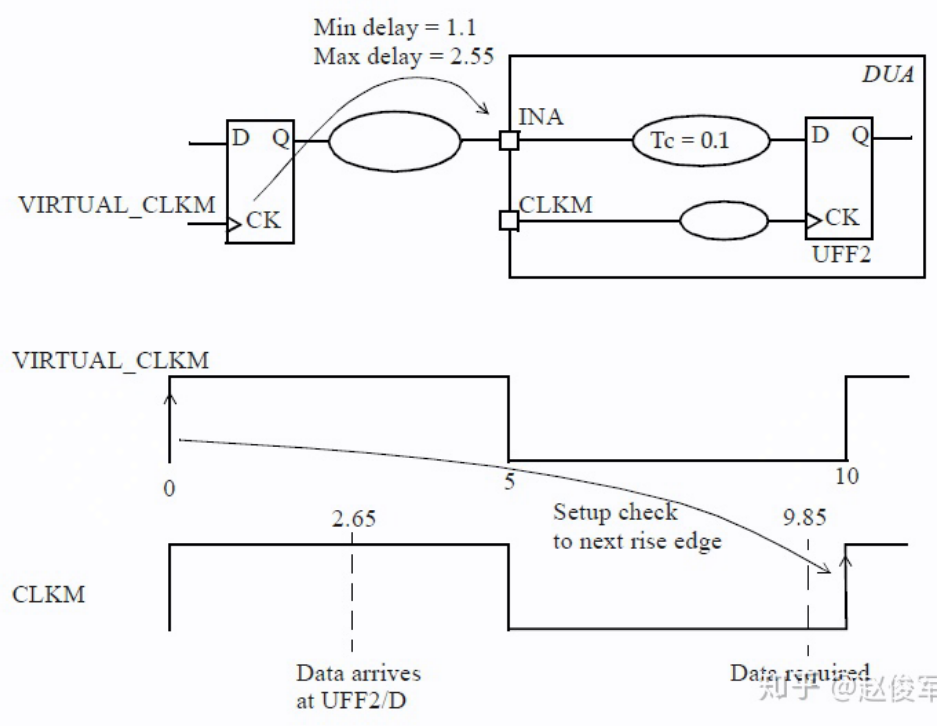
输入延迟也可以相对于实际时钟来指定,并不一定必须相对于虚拟时钟来指定。实际时钟可以是设计中的内部引脚或者输入端口上的时钟
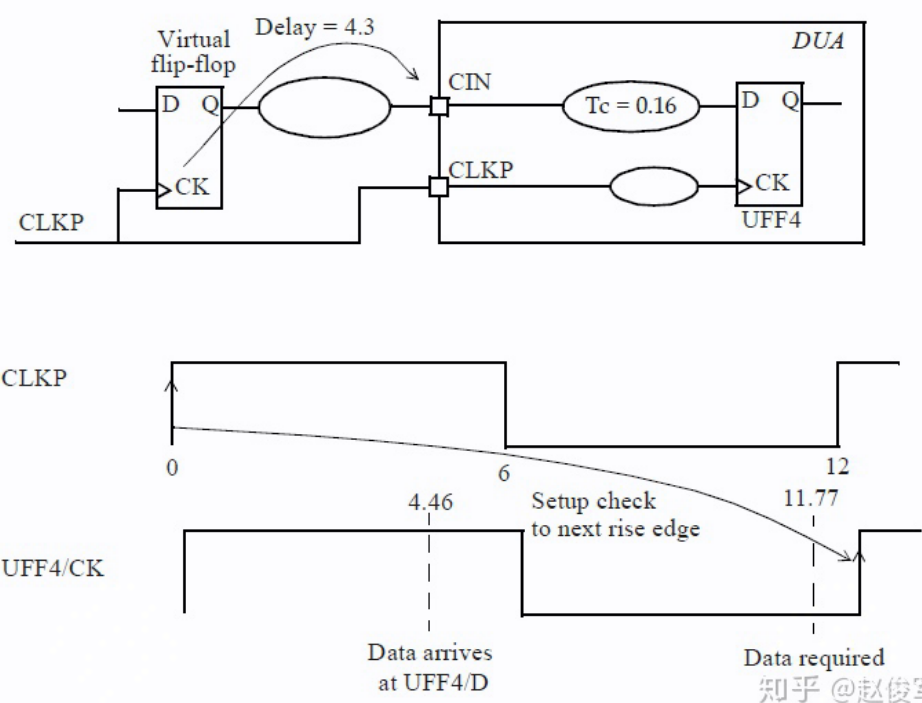
R2O Setup Check
set_output_delayset_load
与上述输入端口约束类似,可以相对于虚拟时钟或设计中的内部时钟来约束输出端口,或者可以相对于实际的输入时钟端口或输出时钟端口来约束输出端口。
为了确定最后一个单元连接到输出端口的延迟,需要指定该端口上的负载,上面使用了 set_load 命令来指定输出负载。请注意,端口ROUT可能在DUA内部具有负载,而set_load约束指定的是额外的负载,即来自DUA外部的负载。
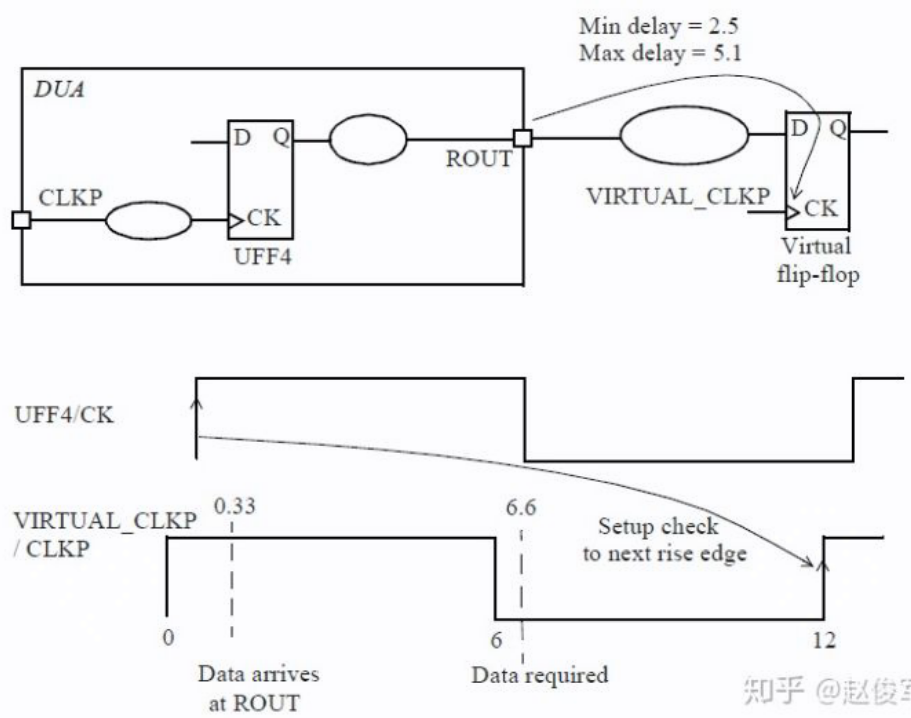
注意在 R2O 路径中,其 endpoint 的 setup check 计算为 $T_{period} - T_{output}$
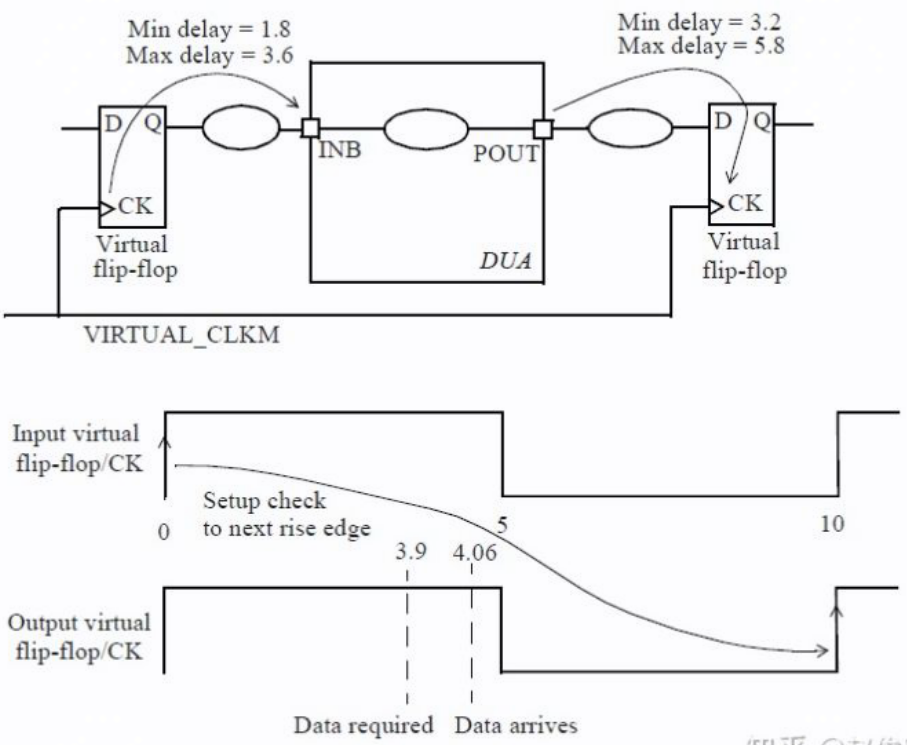
I2O Setup Check
设计也可以具有从输入端口到输出端口的纯组合逻辑路径。
Hold
保持时间(hold time)是在时钟有效沿之后输入的数据必须保持稳定的最短时间,这也是根据有效时钟沿超过其阈值到最早的(the earliest)数据信号超过其阈值的时间间隔来度量的。
保持时间检查可确保正在变化的触发器输出值不会传递到捕获触发器、并在捕获触发器有机会捕获其原始值之前重写 (overwrite)其输出。
保持时间违例针对最快的 launch path 进行分析,需要限制最快到达 D pin 的信号也能够相对于时钟信号至少保持稳定一个 hold time 的稳定状态. 所以公式为:
$$
T_{launch} + T_{ck2q} + T_{dp} > T_{capture} + T_{hold}
$$
Required and Arrival in Hold Check
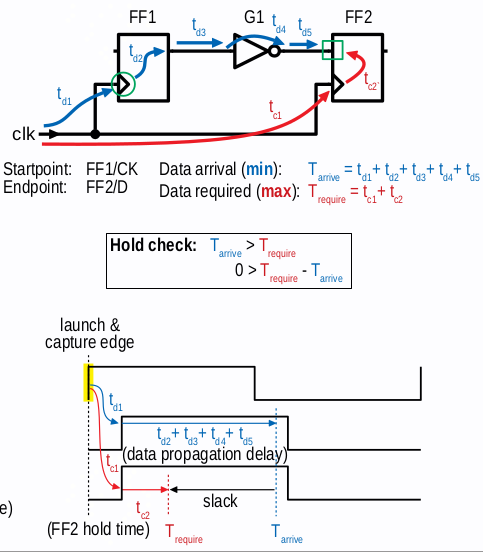
由于 launch delay 为 arrival, 而 capture 为 require time, 并且在 hold check 中要求 arrival time 需要晚于 require time, 所以
$$
T_{arrival} = T_{launch} + T_{ck2q} + T_{dp}
$$
$$
T_{require} = T_{capture} + T_{hold}
$$
$$
T_{arrival} > T_{require}
$$
Hold time Check
一般在 CTS 后才分析 hold time violation
其余分析类型
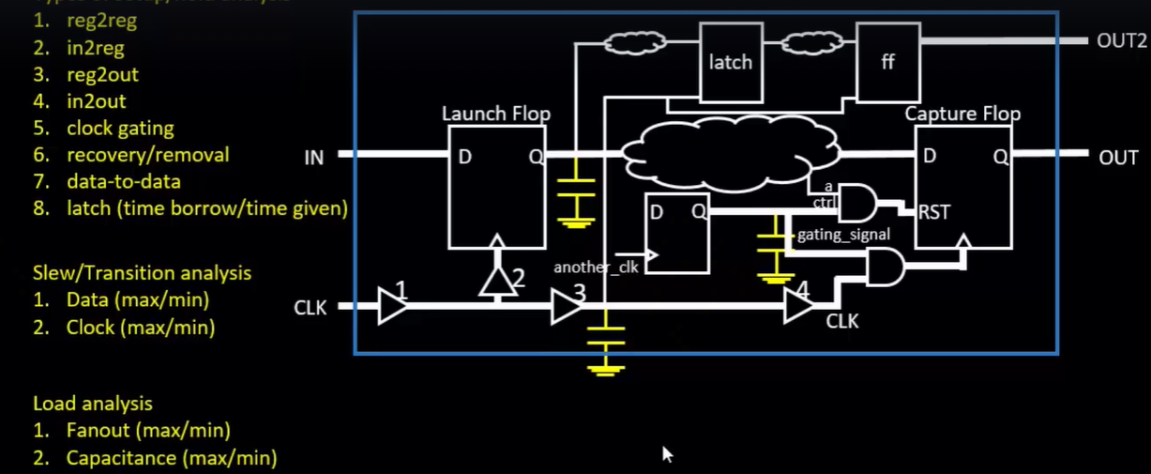
Slew Analysis
Two Types Slew/Transition Analysis.
- Data(max/min)
- clock(max/min)
Load Analysis
Two Types Of Load Analysis
- Fanout(max/main)
- Capacitance(max/min)
Clock Analysis
Two Types of Clock Analysis
- Skew : Difference between the latencies (L1,L2,L3,L4 etc.,) are referred to as skew.
- Pulse Width : This type of analysis is performed due to the clock tree network that has parasitic elements in the clock network path we need to see upto which point the pulse width gets degraded to.
Interconnect Parasitics
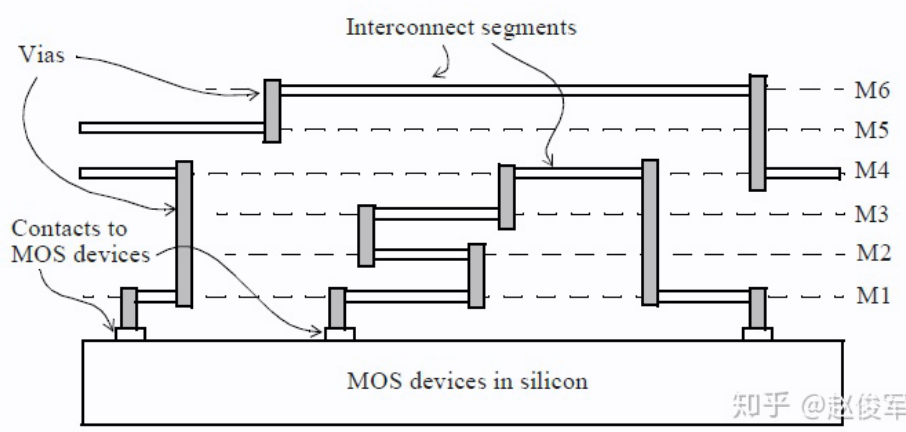
net 通常为 single driver and multi load。并且在物理实现后, net可以在芯片的多个金属层上移动,同时各种金属层可以具有不同的电阻和电容值。
对于等效的电气表示,通常将网络划分为多个段(segment),每个段均由等效的寄生参数表示。我们也将段称为互连走线(interconnect trace), 即特定金属层上网络的一部分。
互连 RLC
互连 RC 由图中穿过不同金属层的 net 造成,包括:
- 互连电阻(R)来自设计实现中各种金属层和过孔(vias)中的互连走线。我们可以将互连电阻视为单元的输出引脚与扇出单元的输入引脚之间的电阻。
- 互连电容(C)也来自金属走线,包括接地电容以及相邻信号路径之间的电容。
- 不考虑互连电感 L
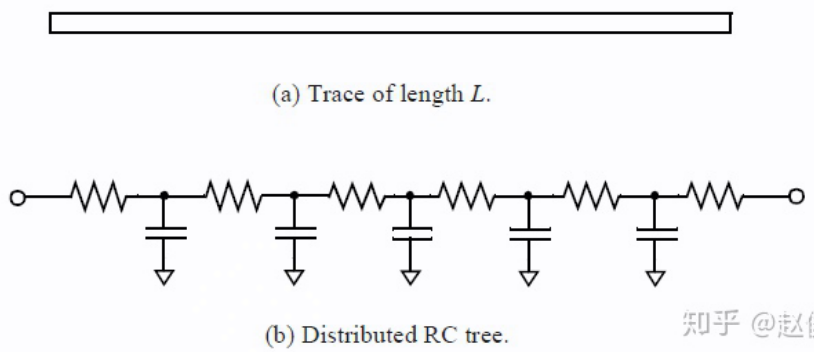
理想情况下,互连走线一部分的电阻和电容(RC)用分布式(distributed)RC树表示。
此外,还可以采用简化方式来 model RC tree
T Model

Π Model
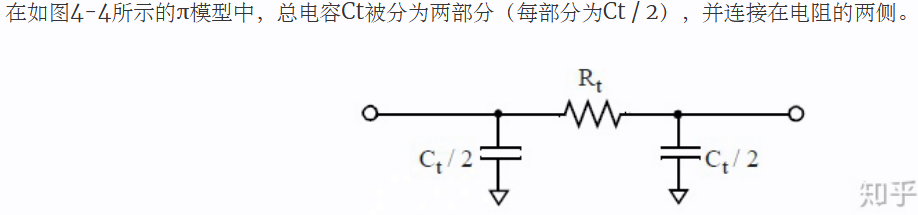
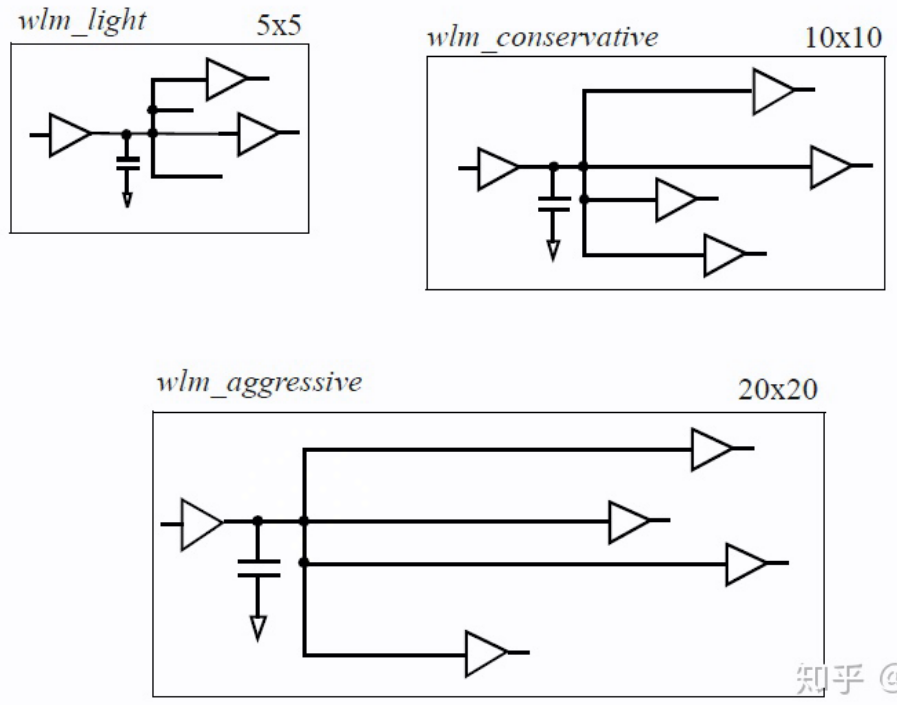
WLM
在物理实现之前,可以使用线负载模型(wireload models)来估计由互连线带来的电容、电阻以及面积开销。线负载模型可用于根据扇出数量来估计网络的长度,线负载模型取决于块(block)的面积,具有不同面积的设计可以选择不同的线负载模型。线负载模型还可以将网络的估计长度映射(map)为电阻、电容以及由于布线而产生的相应面积开销。

- 线负载模型用于根据 fanout 估算线长,并得到对应的 RC 及面积开销。
- 线负载模型由单元面积所决定。随着块的面积增大,走线也会增长。
对于不同的面积(芯片或块),通常将使用不同的线负载模型来确定寄生效应。
指定线负载模型 (TBD)
todo
通过指令 set_wire_load_model 指定线负载模型,并可通过 set_wire_load_mode 指定线负载模式
互连树 (TBD)
todo
- what is the difference between t/pi model and rc tree?
由于从驱动引脚(driver pin)到负载引脚(load pin)的互连延迟不仅需要 RC 值,也取决于互连的结构。
Refs
- 静态时序分析圣经翻译计划——汇总篇
- 如何学习数字电路中的静态时序分析?
- [静态时序分析简明教程(一)] 绪论_静态时序分析时综合的一步吗-CSDN博客
- GitHub - Gogireddyravikiran/Static-Timing-Analysis
- 集成电路静态时序分析与建模 (豆瓣)
- 数字集成电路静态时序分析基础_哔哩哔哩_bilibili
- Path Base Analysis (PBA) Vs Graph Base Analysis (GBA) - part1 |VLSI Concepts
- 设计VLSI EDA(5): 时序(Timing)分析你的电路反射弧有多长
- sta_basics_course/doc/sta_basics_course.rst at master · brabect1/sta_basics_course · GitHub