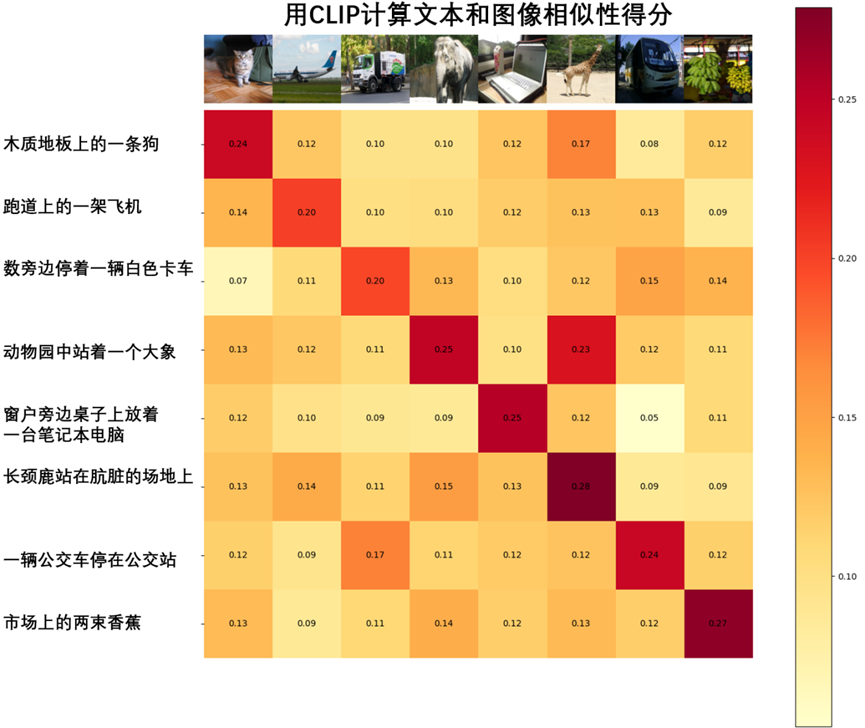
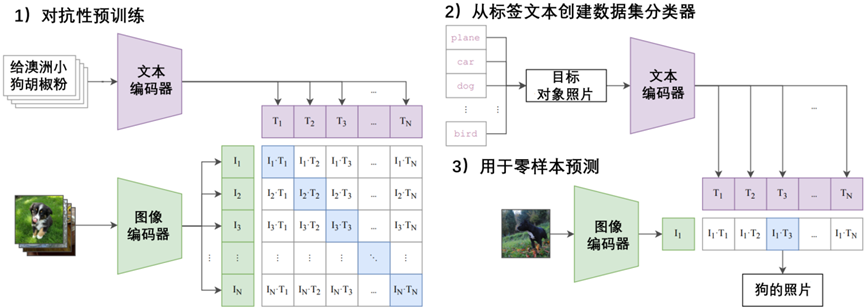
在人工智能技术快速迭代发展的背景下,大语言模型(LLMs)已成为自然语言处理与生成领域的核心技术。然而,将这些模型与人类偏好精确对齐并增强其复杂推理能力的挑战,促使研究者开发了一系列复杂的强化学习(RL)技术。DAPO(解耦裁剪和动态采样策略优化,Decoupled Clip and Dynamic Sampling Policy Optimization)作为一个突破性的开源大语言模型强化学习系统应运而生,为该领域带来了技术变革。本文将系统分析DAPO的技术架构、算法创新及其对人工智能研究发展的长期影响。
大型语言模型的推理能力随着规模扩展呈现前所未有的提升,而强化学习技术已成为引导和增强复杂推理过程的关键方法论。当前最先进的推理型大语言模型的核心技术细节往往不透明(例如OpenAI的o1技术和DeepSeek R1技术报告),导致学术社区难以复现其RL训练成果。字节跳动提出的解耦裁剪和动态采样策略优化(DAPO)算法,完整开源了一套最先进的大规模RL系统,该系统基于Qwen2.5-32B基础模型在AIME 2024测试中取得了50分的优异成绩。与之前不透明的工作不同,DAPO论文详细介绍了四种使大规模LLM RL成功的关键算法技术。此外字节跳动还开源了基于verl框架构建的训练代码及经过精心策划和处理的数据集。这些开源组件提高了技术的可复现性,并为大规模LLM RL领域的未来研究奠定了坚实基础。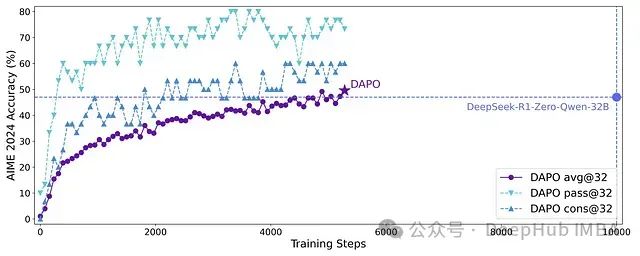
DAPO在Qwen2.5-32B基础模型上的AIME 2024评分,仅使用50%的训练步骤就超越了之前最先进的DeepSeekR1-Zero-Qwen-32B模型。
https://avoid.overfit.cn/post/ec5645f4c0844a38ae489b3b5be61db1